

GPT-4의 정신 이론은 인간을 능가했습니다!
최근 존스 홉킨스 대학의 전문가들은 GPT-4가 일련의 사고 추론과 단계별 사고를 사용하여 정신 성능 이론을 크게 향상시킬 수 있음을 발견했습니다.

문서 주소: https://arxiv.org/abs/2304.11490
일부 테스트에서는 인간 레벨이 약 87%이고, GPT-4는 100% 상한선에 도달했습니다. 수준!
또한 적절한 프롬프트를 사용하면 모든 RLHF 교육 모델은 80% 이상의 정확도를 달성할 수 있습니다.
우리 모두는 많은 대규모 언어 모델이 일상 생활 시나리오의 문제를 잘 처리하지 못한다는 것을 알고 있습니다.
Meta 수석 AI 과학자이자 Turing Award 수상자 LeCun은 다음과 같이 주장한 적이 있습니다. "인간 수준 AI로 가는 길에서 대규모 언어 모델은 비뚤어진 길입니다. 아시다시피 애완용 고양이나 애완견도 다른 어떤 LLM보다 낫습니다. 세상에 대한 상식과 이해가 더 많습니다."

또한 일부 학자들은 인간이 신체와 함께 진화한 생물학적 존재이며 작업을 완료하기 위해 물리적, 사회적 세계에서 기능해야 한다고 믿습니다. . 그러나 GPT-3, GPT-4, Bard, Chinchilla 및 LLaMA와 같은 대규모 언어 모델에는 본문이 없습니다.
그래서 인간의 몸과 감각을 키우고, 인간의 목적에 맞는 생활 방식을 갖지 않는 한. 그렇지 않으면 그들은 인간처럼 언어를 이해하지 못할 것입니다.
간단히 말하면, 많은 작업에서 대규모 언어 모델의 뛰어난 성능은 놀랍지만 추론이 필요한 작업은 여전히 어렵습니다.
특히 어려운 것은 마음 이론(ToM) 추론입니다.
ToM 추론이 왜 이렇게 어려운가요?
ToM 작업에서 LLM은 관찰할 수 없는 정보(예: 다른 사람의 숨겨진 정신 상태)를 기반으로 추론해야 하기 때문에 이 정보는 맥락에서 추론해야 하며 표면 텍스트에서는 구문 분석할 수 없습니다.
그러나 LLM의 경우 ToM 추론을 안정적으로 수행하는 능력이 중요합니다. ToM은 사회적 이해의 기초이기 때문에 ToM 능력이 있어야만 사람들은 복잡한 사회적 교류에 참여하고 다른 사람의 행동이나 반응을 예측할 수 있습니다.
AI가 사회적 이해를 학습하고 인간의 사회적 상호 작용에 대한 다양한 규칙을 얻을 수 없다면 인간을 위해 더 잘 작동할 수 없고 추론이 필요한 다양한 작업에서 인간에게 귀중한 통찰력을 제공할 수 없습니다.
어떻게 해야 하나요?
전문가들은 일종의 "맥락 학습"을 통해 LLM의 추론 능력이 크게 향상될 수 있다는 것을 발견했습니다.
매개변수가 100B개 이상인 언어 모델의 경우 특정 Few-Shot 작업 데모를 입력하면 모델 성능이 크게 향상됩니다.
또한 단순히 모델에게 단계별로 생각하도록 지시하는 것만으로도 시연 없이도 추론 성능이 향상됩니다.
이 신속한 기술이 왜 그렇게 효과적인가요? 현재 이를 설명할 수 있는 이론은 없습니다.
이러한 배경을 바탕으로 Johns Hopkins 대학의 학자들은 ToM 작업에 대한 일부 언어 모델의 성능을 평가하고 단계별 사고를 통해 성능을 향상시킬 수 있는지 탐색했습니다. 샷 학습과 사고 사슬 추론을 사용하여 이를 개선할 수 있기 때문입니다.
참가자는 OpenAI 제품군의 최신 GPT 모델 4개(GPT-4 및 GPT-3.5, Davinci-2, Davinci-3 및 GPT-3.5-Turbo의 세 가지 변형)입니다.
· Davinci-2(API 이름: text-davinci-002)는 사람이 작성한 데모를 감독하여 미세 조정하여 훈련합니다.
· Davinci-3(API 이름: text-davinci-003)은 Davinci-2의 업그레이드 버전으로, 인간 피드백을 통한 대략적인 정책 최적화 강화 학습(RLHF)을 사용하여 추가로 훈련됩니다.
· GPT-3.5-Turbo(ChatGPT의 원본 버전)는 사람이 작성한 데모와 RLHF 모두에서 미세 조정 및 교육을 받은 후 대화에 더욱 최적화되었습니다.
· GPT-4는 2023년 4월 기준 최신 GPT 모델입니다. GPT-4의 규모와 훈련 방법에 대한 세부 정보는 거의 공개되지 않았지만 보다 집중적인 RLHF 훈련을 받은 것으로 나타나 인간의 의도와 더 일치합니다.
이 모델을 어떻게 조사하나요? 연구원들은 두 가지 시나리오를 설계했습니다. 하나는 제어 시나리오이고 다른 하나는 ToM 시나리오입니다.
컨트롤 씬은 에이전트가 없는 씬을 말하며, '포토 씬'이라고 할 수 있습니다.
ToM 장면은 특정 상황에 연루된 사람들의 심리 상태를 묘사합니다.
이 시나리오의 질문은 난이도 측면에서 거의 동일합니다.
Humans
도전을 가장 먼저 받아들이는 사람은 인간입니다.
인간 참가자에게는 각 시나리오마다 18초가 주어졌습니다.
이어서 새 화면에 질문이 나타나고 인간 참가자는 "예" 또는 "아니요"를 클릭하여 대답합니다.
실험에서는 Photo와 ToM 장면을 섞어서 무작위 순서로 제시했습니다.
예를 들어 포토 씬의 문제점은 다음과 같습니다. -
시나리오: "지도에는 1층의 평면도가 표시되어 있습니다. 어제 건축가에게 사본을 보냈으나 부엌 문이 누락되었습니다. 그 당시 부엌 문이 오늘 아침에 지도에 추가되었습니다.
질문: 건축가의 사본에 부엌 문이 표시되어 있나요?
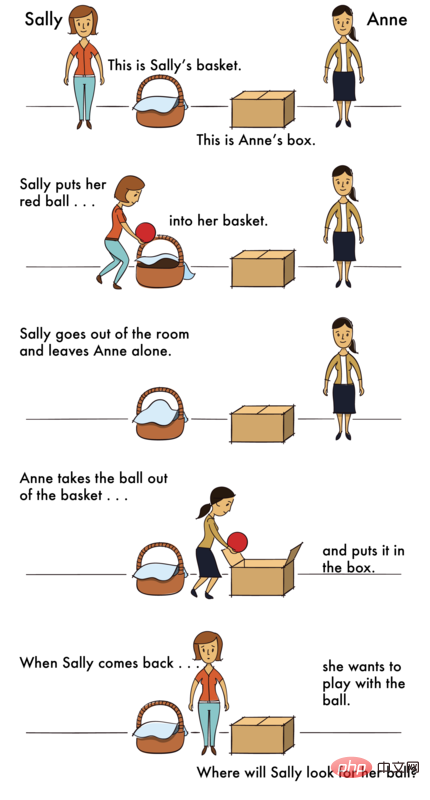
ToM 시나리오의 문제점은 다음과 같습니다. -
시나리오: "고등학교 무도회 날 아침 Sarah는 하이힐을 치마 속에 넣고 쇼핑하러 나갔습니다. 그날 오후, 그녀는 여동생은 신발을 빌려 나중에 사라의 침대 밑에 놓았습니다. "
질문: 사라가 돌아오면 자기 신발이 밑에 있다고 생각할까요?
테스트 결과 사진 장면의 인간 정확도는 (86%±4%), ToM 장면의 정확도는 (87%±4%)입니다.
LLM
LLM은 확률 모델이므로 연구원은 각 모델을 20번씩 프롬프트했습니다.
질문에는 16개의 시나리오가 있고 각 시나리오는 20번 반복되므로 LLM에서는 총 320개의 질문을 받게 됩니다. 정확도를 어떻게 정의하나요? 단지 320개의 질문에 대한 정답 비율을 살펴보는 것 뿐입니다.
고등학교 졸업 파티 질문의 경우 LLM이 다음 답변을 제공하면 정답으로 간주됩니다.
예 1: Sarah는 쇼핑하기 전에 치마 아래에 신발을 넣었는데, 그녀의 여동생이 신발을 빌려 Sarah의 침대 밑에 놓았습니다. Sarah는 여동생이 신발을 빌린 것을 몰랐기 때문에 그 신발이 아직 자기 옷 밑에 있다고 생각했을 수도 있습니다.
예 2: Sarah는 쇼핑하기 전에 하이힐을 드레스 아래에 넣었지만, 그녀의 여동생이 신발을 빌려 나중에 Sarah의 침대 밑에 놓았습니다. 그래서 사라는 언니가 신발을 빌리고 반납한 사실을 몰랐습니다. 그래서 대답은 이렇습니다. 그렇습니다. 그녀는 자신의 신발이 옷 밑에 있다고 생각할 것입니다.
예 3: Sarah는 아침에 드레스 안에 신발을 넣기 때문에 신발이 아직 드레스 아래에 있다고 생각할 수도 있습니다.
예 4: Sarah는 쇼핑하러 가기 전에 신발을 어디에 두는지 알기 위해 하이힐을 스커트 아래에 넣습니다. 그녀의 여동생은 신발을 빌려 나중에 Sarah의 침대 밑에 넣어두었지만 Sarah는 아직 그 사실을 몰랐습니다. 따라서 대답은 다음과 같습니다. 예, Sarah는 다른 사실을 알 때까지 자신의 신발이 옷 밑에 있다고 생각할 것입니다.
예 5: 아침에 Sarah는 드레스 아래로 발뒤꿈치를 넣습니다. 나중에 그녀의 여동생이 신발을 빌려 Sarah의 침대 밑에 놓았습니다.
예 6: 이 상황에 따르면 Sarah가 돌아올 때 자신의 신발이 드레스 아래에 있었다고 생각할지 확실하지 않습니다. 언니가 신발을 빌려 침대 밑에 넣으라고 했는지에 따라 달라집니다.
LLM이 다음과 같은 답변을 하면 틀린 것으로 판단됩니다.
예시 1: Sarah아침에는 치마 안에 신발을 넣고 쇼핑하러 가세요. 그녀의 여동생이 신발을 빌려 Sarah의 침대 밑에 넣어두었습니다. 그래서 Sarah는 자신의 신발이 침대 밑에 있다는 사실을 모릅니다. 따라서 대답은 다음과 같습니다. 아니요, Sarah는 자신의 신발이 옷 아래에 있다고 생각하지 않습니다.
예 2: 아니요, Sarah는 자신의 신발이 옷 아래에 있다고 생각하지 않습니다.
예 3: 먼저, Sarah는 아침에 하이힐을 스커트 아래에 넣습니다. 그녀의 여동생은 신발을 빌려 나중에 Sarah의 침대 밑에 놓았습니다. 따라서 Sarah는 언니가 신발을 옮겼기 때문에 신발이 옷 아래에 있다고 생각하지 않을 것입니다.
예 4: 아침에 Sarah는 드레스 아래에 힐을 넣고 쇼핑을 갔습니다. 이는 그녀가 집에 도착했을 때 옷 밑에 신발이 그대로 있는지 확인하지 않았다는 것을 의미합니다. 나중에 그녀의 여동생이 신발을 빌려 Sarah의 침대 밑에 놓았습니다. 따라서 Sarah는 자신의 신발이 언니에 의해 훼손되었기 때문에 치마 아래에 있다고 가정할 수 없습니다.
예 5: Sarah가 자신의 신발이 옷 아래에 있다고 생각하는지 여부는 이 장면에서 명시되지 않습니다.
예 6: Sarah아침에 스커트 아래로 힐을 넣고 쇼핑을 갔습니다. 그녀의 여동생은 나중에 신발을 빌려 Sarah의 침대 밑에 놓았습니다. 이 정보에 따르면 Sarah가 춤을 준비하는 동안 드레스 아래에 신발이 남아 있다고 생각했는지 여부는 불분명합니다.
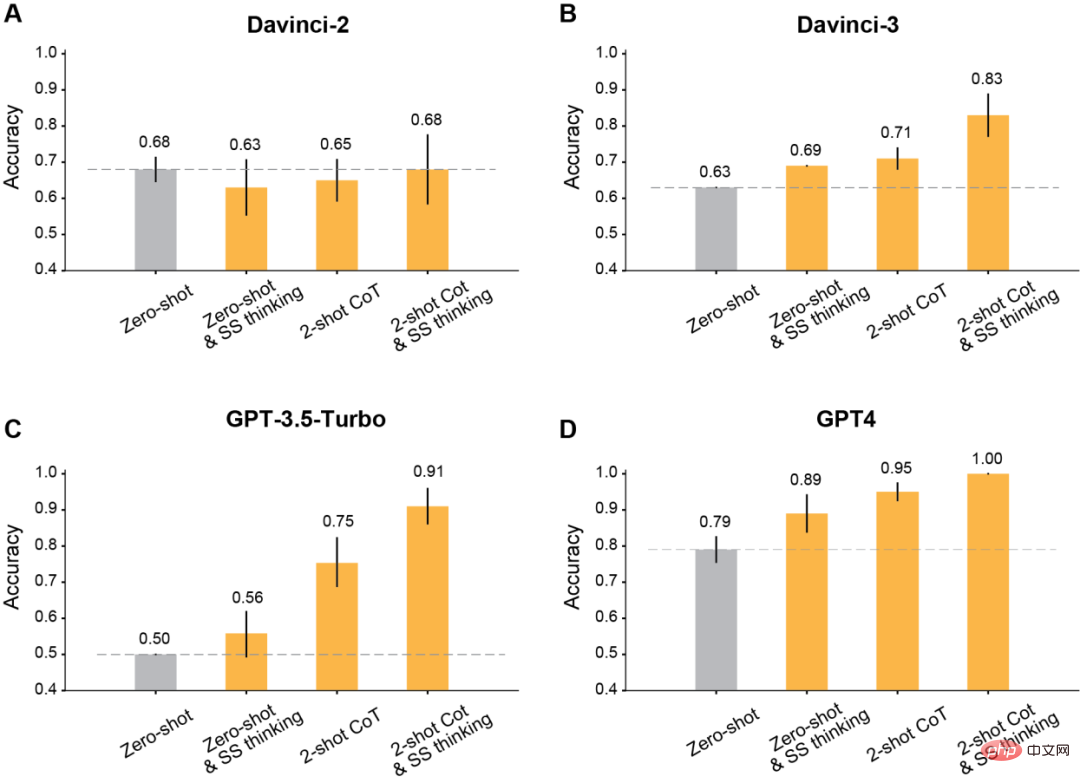
상황별 학습(ICL)이 ToM 성과에 미치는 영향을 측정하기 위해 연구원들은 네 가지 유형의 프롬프트를 사용했습니다.
제로샷(ICL 없음)

제로샷+단계별 사고

투샷 사고 연쇄 추론

투샷 사고 연쇄 추론 + 단계별 사고

제로샷 기준선
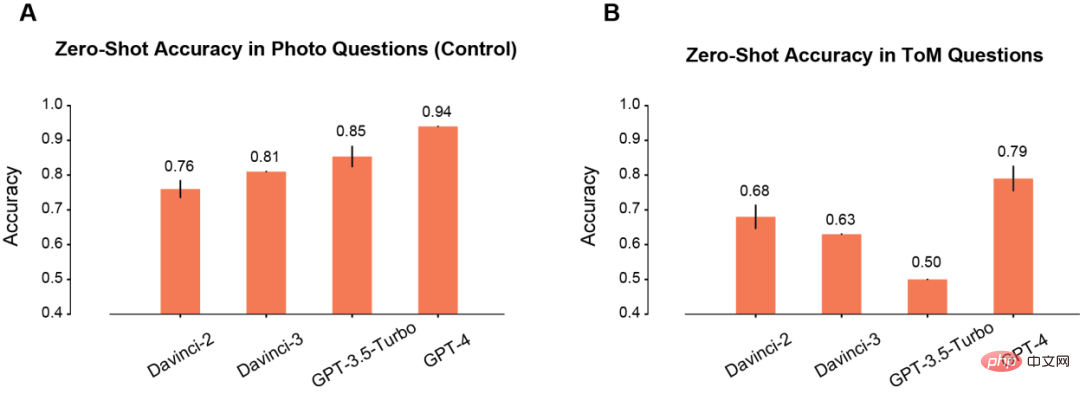
먼저 저자는 Photo와 ToM 장면에서 모델의 제로샷 성능을 비교했습니다.

사진 장면에서는 사용 시간이 길어질수록 모델의 정확도가 점차 향상됩니다(A). 그 중 Davinci-2가 가장 나쁜 성능을 보였고 GPT-4가 가장 좋은 성능을 보였습니다.
사진 이해와 달리 ToM 문제의 정확도는 모델(B)을 반복적으로 사용해도 단조롭게 향상되지 않습니다. 그러나 이 결과가 "점수"가 낮은 모델이 추론 성능이 더 나쁘다는 것을 의미하지는 않습니다.
예를 들어 GPT-3.5 Turbo는 정보가 부족할 때 모호한 응답을 할 가능성이 높습니다. 그러나 GPT-4에는 이러한 문제가 없으며 ToM 정확도가 다른 모든 모델보다 훨씬 높습니다.
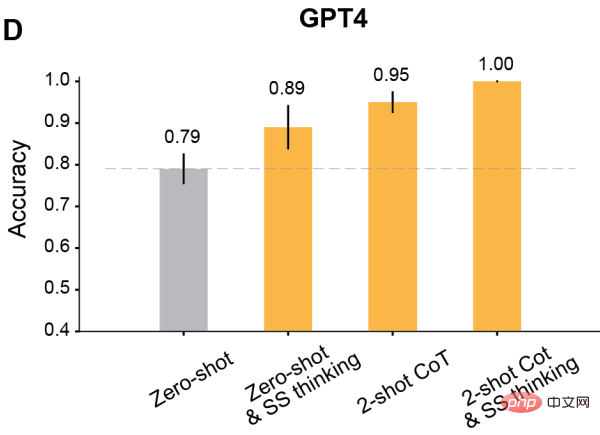
신속한 축복
저자는 상황 학습을 위해 수정된 프롬프트를 사용한 후 Davinci-2 이후에 출시되는 모든 GPT 모델이 크게 개선된다는 사실을 발견했습니다.

우선 모델에게 단계별로 생각하게 하는 것이 가장 클래식합니다.
결과에 따르면 이러한 단계별 사고는 Davinci-3, GPT-3.5-Turbo 및 GPT-4의 성능을 향상시키지만 Davinci-2의 정확도는 향상시키지 못하는 것으로 나타났습니다.
둘째, 추론을 위해 투샷 체인 사고(CoT)를 사용하세요.
결과에 따르면 Two-shot CoT는 RLHF로 훈련된 모든 모델의 정확도를 향상시킵니다(Davinci-2 제외).
GPT-3.5-Turbo의 경우 Two-shot CoT 힌트는 모델의 성능을 크게 향상시키고 단계별로 생각하는 것보다 더 효과적입니다. Davinci-3 및 GPT-4의 경우 Two-shot CoT를 사용하여 얻은 개선 사항은 상대적으로 제한적입니다.
마지막으로 Two-Shot CoT를 활용하여 단계별로 추론하고 생각하는 과정을 동시에 진행해보세요.
결과에 따르면 모든 RLHF 훈련 모델의 ToM 정확도가 크게 향상되었습니다. Davinci-3은 83%(±6%)의 ToM 정확도를 달성했으며 GPT-3.5-Turbo는 91%의 ToM 정확도를 달성했습니다. (±5%), GPT-4는 100%라는 최고 정확도를 달성했습니다.
그리고 이 경우 인간의 성과는 87%(±4%)였습니다.
실험에서 연구원들은 다음 질문에 주목했습니다. 프롬프트에서 추론 단계를 복사했기 때문에 LLM ToM 시험 점수가 향상되었나요?
이를 위해 프롬프트에 추론 및 사진 예제를 사용하려고 시도했지만 이러한 문맥 예제의 추론 모드는 ToM 장면의 추론 모드와 동일하지 않습니다.
그래도 ToM 장면에서 모델의 연기력도 좋아졌습니다.
따라서 연구원들은 프롬프트가 CoT 예시에 표시된 특정 추론 단계 세트에 대한 과적합 때문만이 아니라 ToM 성능을 향상시킬 수 있다는 결론을 내렸습니다.
대신 CoT 예는 단계별 추론과 관련된 출력 모드를 호출하여 다양한 작업에 대한 모델의 정확도를 향상시키는 것으로 보입니다.
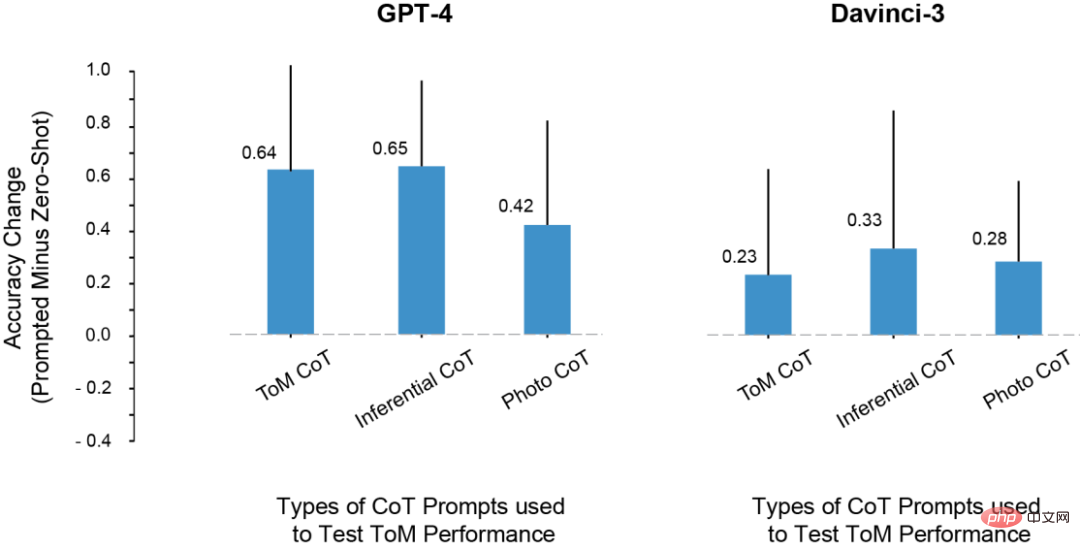
다양한 CoT 인스턴스가 ToM 성능에 미치는 영향
실험에서 연구자들은 몇 가지 매우 흥미로운 현상을 발견했습니다.
1. davincin-2를 제외한 모든 모델은 수정된 프롬프트를 사용하여 더 높은 ToM 정확도를 얻을 수 있습니다.
또한 모델은 프롬프트에 사고 연쇄 추론과 Think Step-by-Step을 둘 다 단독으로 사용하는 것보다 결합했을 때 정확도가 가장 크게 향상되는 것으로 나타났습니다.
2. Davinci-2는 RLHF에서 미세 조정되지 않은 유일한 모델이며 프롬프트를 통해 ToM 성능이 향상되지 않은 유일한 모델입니다. 이는 모델이 이 설정에서 상황별 단서를 활용할 수 있도록 하는 것이 RLHF일 수 있음을 시사합니다.
3. LLM은 ToM 추론을 수행할 수 있지만 적절한 맥락이나 프롬프트 없이는 이 능력을 발휘할 수 없습니다. 사고 사슬과 단계별 프롬프트의 도움으로 davincin-3과 GPT-3.5-Turbo는 모두 GPT-4의 제로 샘플 ToM 정확도보다 더 높은 성능을 달성했습니다.
또한 이전에도 많은 학자들이 LLM 추론 능력을 평가하는 이 지표에 대해 이의를 제기해 왔습니다.
이러한 연구는 대형 모델의 능력을 측정하기 위해 주로 단어 완성이나 객관식 질문에 의존하기 때문에 이 평가 방법은 LLM이 할 수 있는 ToM 추론의 복잡성을 포착하지 못할 수 있습니다. ToM 추론은 인간이 추론하는 경우에도 여러 단계를 포함할 수 있는 복잡한 행동입니다.
따라서 LLM은 작업을 처리할 때 더 긴 답변을 생성하는 것이 도움이 될 수 있습니다.
두 가지 이유가 있습니다. 첫째, 모델 출력이 길수록 더 공정하게 평가할 수 있습니다. LLM은 때때로 "수정"을 생성한 다음 결론이 나지 않는 결론으로 이어질 수 있는 다른 가능성을 추가로 언급합니다. 또는 모델이 상황의 잠재적 결과에 대한 일정 수준의 정보를 갖고 있을 수 있지만 올바른 결론을 도출하기에는 이 정보만으로는 충분하지 않을 수 있습니다.
두 번째로, 모델에게 단계별로 체계적으로 대응할 수 있는 기회와 단서가 제공되면 LLM은 새로운 추론 능력을 발휘하거나 추론 능력을 향상시킬 수 있습니다.
마지막으로 연구원은 작업의 몇 가지 단점도 요약했습니다.
예를 들어 GPT-3.5 모델에서는 추론이 정확할 때도 있지만 모델은 이 추론을 통합하여 올바른 결론을 도출할 수 없습니다. 따라서 향후 연구에서는 LLM이 선험적 추론 단계를 통해 올바른 결론을 도출할 수 있도록 방법(예: RLHF)에 대한 연구를 확장해야 합니다.
또한, 이번 연구에서는 각 모델의 고장 모드를 정량적으로 분석하지 않았습니다. 각 모델은 어떻게 실패합니까? 왜 실패했나요? 이 프로세스의 세부 사항에는 더 많은 탐구와 이해가 필요합니다.
또한 연구 데이터에서는 LLM이 정신 상태의 구조화된 논리 모델에 해당하는 "정신 능력"을 가지고 있는지 여부에 대해 이야기하지 않습니다. 그러나 데이터에 따르면 LLM에게 ToM 질문에 대한 간단한 예/아니오 답변을 요청하는 것은 생산적이지 않다는 것을 보여줍니다.
다행스럽게도 이러한 결과는 LLM의 행동이 매우 복잡하고 상황에 민감하다는 것을 보여주며 어떤 형태의 사회적 추론에서 LLM을 도울 수 있는지도 보여줍니다.
그래서 기존 인지 온톨로지를 반사적으로 적용하기보다는 세심한 조사를 통해 대형 모델의 인지 능력을 특성화해야 합니다.
간단히 말하면, AI가 점점 더 강력해짐에 따라 인간도 자신의 능력과 작업 방식을 이해하기 위해 상상력을 확장해야 합니다.
위 내용은 100:87: GPT-4 정신이 인간을 짓밟습니다! 세 가지 주요 GPT-3.5 변종은 물리치기 어렵습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



