

ChatGPT에는 "RLHF(Reinforcement Learning with Human Feedback)"라는 핵심 훈련 방법이 있습니다.
모델을 더 안전하게 만들고 출력 결과를 인간의 의도와 더 일관되게 만들 수 있습니다.
이제 Google Research와 UC Berkeley 연구진은 이 방법을 AI 페인팅에 적용하면 이미지가 입력과 정확히 일치하지 않는 상황을 "치료"할 수 있으며 효과가 놀라울 정도로 좋다는 사실을 발견했습니다. -
최대 47까지 달성 가능 % 개선하다.

이제 AIGC 분야의 인기 모델 두 사람은 일종의 '공명'을 찾은 것 같습니다.
RLHF(전체 이름은 "인간 피드백을 통한 강화 학습")는 2017년 OpenAI와 DeepMind가 공동 개발한 강화 학습 기술입니다.
이름에서 알 수 있듯이 RLHF는 모델 출력 결과에 대한 인간의 평가(즉, 피드백)를 사용하여 모델을 직접 최적화합니다. LLM에서는 "모델 값"이 인간의 가치와 더욱 일치하도록 만들 수 있습니다.
AI 이미지 생성 모델에서는 생성된 이미지를 텍스트 프롬프트와 완전히 정렬할 수 있습니다.
구체적으로는 먼저 인간의 피드백 데이터를 수집하세요.
여기에서 연구원들은 총 27,000개 이상의 "텍스트-이미지 쌍"을 생성한 다음 일부 인간에게 점수를 매기도록 요청했습니다.
간결함을 위해 텍스트 프롬프트에는 수량, 색상, 배경 및 혼합 옵션과 관련된 다음 4가지 범주만 포함됩니다. 인간의 피드백은 "좋음", "나쁨" 및 "모름(건너뛰기)으로만 구분됩니다. ".

둘째, 보상 기능을 배워보세요.
이 단계는 방금 얻은 인간 평가로 구성된 데이터 세트를 사용하여 보상 함수를 훈련한 다음 이 함수를 사용하여 모델 출력(공식의 빨간색 부분)에 대한 인간 만족도를 예측하는 것입니다.
이러한 방식으로 모델은 결과가 텍스트와 얼마나 일치하는지 알 수 있습니다.
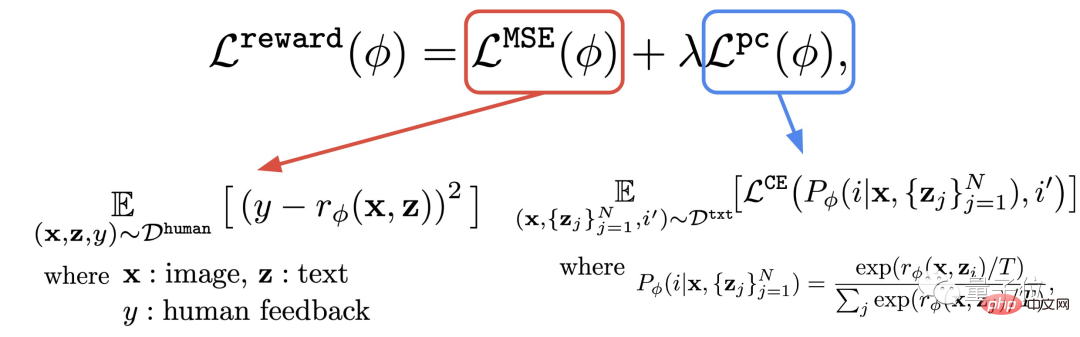
저자는 보상 기능 외에도 보조 작업(공식의 파란색 부분)도 제안합니다.
즉, 이미지 생성이 완료된 후 모델은 여러 텍스트를 제공하지만 그 중 하나만 원본 텍스트이고 보상 모델이 이미지가 텍스트와 일치하는지 "스스로 확인"하도록 합니다.
이 역연산은 "이중 보험" 효과를 만들 수 있습니다(아래 그림의 2단계에 대한 이해를 도울 수 있음).
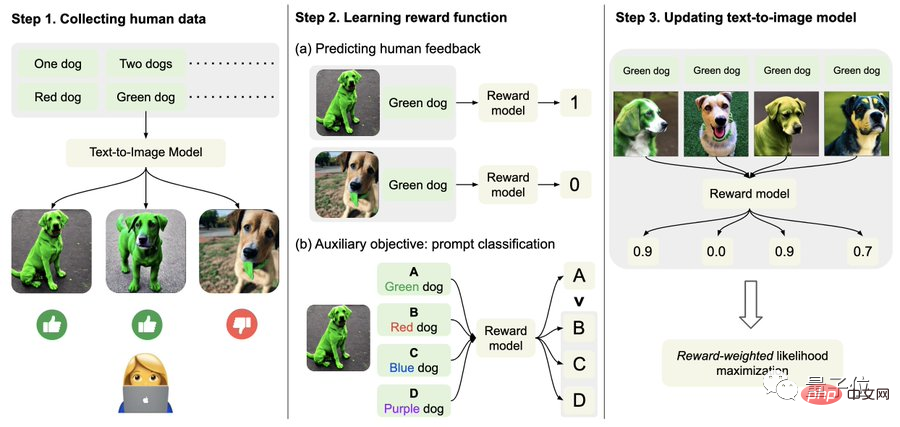
마지막으로 미세 조정이 중요합니다.
즉, 텍스트-이미지 생성 모델은 보상 가중치 우도 최대화(아래 공식의 첫 번째 항목)를 통해 업데이트됩니다.
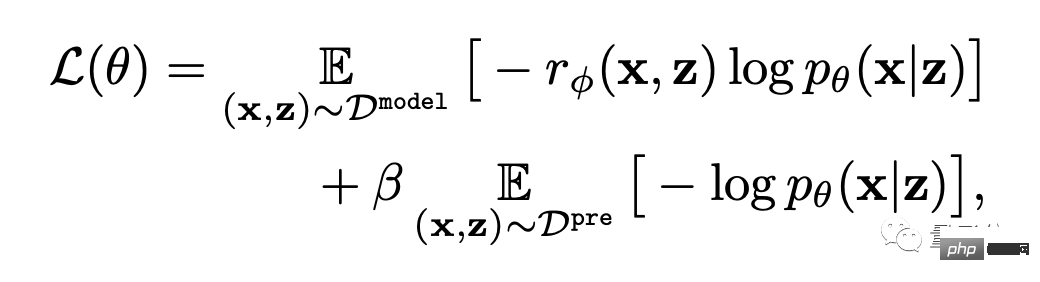
과적합을 피하기 위해 저자는 사전 훈련 데이터 세트에서 NLL 값(공식의 두 번째 항)을 최소화했습니다. 이 접근 방식은 InstructionGPT(ChatGPT의 "직접 전신")와 유사합니다.
다음 일련의 효과에서 볼 수 있듯이 원래 Stable Diffusion에 비해 RLHF로 미세 조정된 모델은 다음과 같습니다.
(1) Get the 텍스트의 ""가 더 정확합니다.

(2) 배경으로 "바다" 요구 사항을 무시하지 않습니다.
(3) 붉은 호랑이를 원한다면, "더 붉은색" 결과를 얻을 수 있습니다.
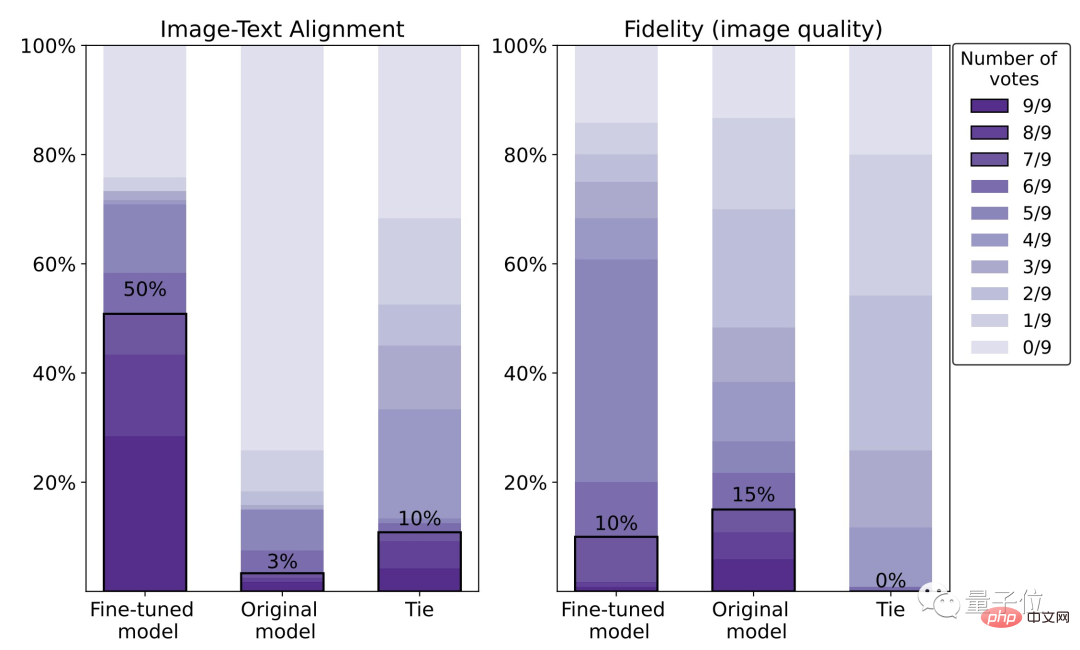
구체적인 데이터에 따르면 미세 조정된 모델의 인간 만족도는 50%로, 이는 원래 모델(3%)에 비해 47% 향상된 수치입니다.
단, 그 대가는 영상 선명도 5% 손실입니다.
아래 그림에서도 오른쪽의 늑대가 왼쪽의 늑대보다 확실히 더 흐릿하다는 것을 확실히 알 수 있습니다.
이와 관련하여 저자는 더 큰 인간 평가 데이터 세트를 사용하여 더 나은 최적화(RL) 방법을 사용하면 이러한 상황을 개선할 수 있습니다.
이 글의 저자는 총 9명입니다.

한국과학기술연구원(KIST) 구글 AI 연구과학자 이기민 박사로 UC 버클리에서 박사후 연구를 진행했다.

세 명의 중국 작가가 있습니다:
Liu Hao는 UC Berkeley의 박사 과정 학생으로 피드백 신경망에 주요 연구 관심이 있습니다.
Du Yuqing은 UC Berkeley의 박사 과정 학생입니다. 그의 주요 연구 방향은 비지도 강화 학습 방법입니다.
교신저자인 Shixiang Shane Gu(구시샹)은 3대 거인 중 하나인 Hinton 밑에서 학사 학위를 취득하고, 케임브리지 대학교에서 박사 학위를 취득했습니다.

이 글을 작성할 당시 그는 여전히 Google 직원이었지만 이제는 OpenAI로 전환하여 ChatGPT 담당자에게 직접 보고한다는 점을 언급할 가치가 있습니다.
논문 주소:
https://arxiv.org/abs/2302.12192
참조 링크: [1]//m.sbmmt.com/link/4d42d2f5010c1c13f23492a35645d6a7
[2 ] https://openai.com/blog/instruction-following/
위 내용은 ChatGPT의 핵심 방법을 AI 페인팅에 사용할 수 있으며 효과가 47% 치솟습니다. 교신저자: OpenAI로 전환했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



