

강화학습에 관해서 많은 연구자들의 아드레날린이 걷잡을 수 없이 치솟습니다! 게임 AI 시스템, 현대 로봇, 칩 설계 시스템 및 기타 애플리케이션에서 매우 중요한 역할을 합니다.
강화 학습 알고리즘에는 다양한 유형이 있지만 주로 "모델 기반"과 "모델 없는" 두 가지 범주로 나뉩니다.
신경과학자이자 '지능의 탄생' 저자인 이대열 박사는 TechTalks와의 대화에서 인간과 동물, 인공지능과 자연지능의 다양한 강화학습 모델과 향후 연구 방향에 대해 논의했습니다.

19세기 후반 심리학자 에드워드 손다이크가 제안한 '효과 법칙'이 모델 프리 강화 학습의 기초가 되었습니다. Thorndike는 특정 상황에서 긍정적인 영향을 미치는 행동은 해당 상황에서 다시 발생할 가능성이 더 큰 반면, 부정적인 영향을 미치는 행동은 다시 발생할 가능성이 낮다고 제안했습니다.
Thorndike는 실험에서 이 "효과의 법칙"을 탐구했습니다. 그는 고양이를 미로 상자에 넣고 고양이가 상자에서 탈출하는 데 걸리는 시간을 측정했습니다. 탈출하려면 고양이가 밧줄이나 레버와 같은 일련의 도구를 작동해야 합니다. Thorndike는 고양이가 퍼즐 상자와 상호작용하면서 탈출에 도움이 되는 행동을 학습한다는 것을 관찰했습니다. 시간이 지날수록 고양이는 점점 더 빠르게 상자를 탈출합니다. Thorndike는 고양이가 자신의 행동이 제공하는 보상과 처벌로부터 배울 수 있다고 결론지었습니다. "효과의 법칙"은 나중에 행동주의의 길을 열었습니다. 행동주의(Behaviorism)는 인간과 동물의 행동을 자극과 반응의 관점에서 설명하려는 심리학의 한 분야이다. "효과의 법칙"은 모델 없는 강화 학습의 기초이기도 합니다. 모델 없는 강화 학습에서는 에이전트가 세상을 인식한 다음 보상을 측정하면서 조치를 취합니다.
모델 없는 강화 학습에는 직접적인 지식이나 세계 모델이 없습니다. RL 에이전트는 시행착오를 통해 각 작업의 결과를 직접 경험해야 합니다.
Thorndike의 "효과 법칙"은 1930년대까지 인기를 끌었습니다. 당시 또 다른 심리학자인 에드워드 톨먼(Edward Tolman)은 쥐가 미로를 탐색하는 방법을 어떻게 빨리 배웠는지 탐구하면서 중요한 통찰력을 발견했습니다. 실험 중에 Tolman은 동물이 강화 없이도 환경에 대해 배울 수 있다는 것을 깨달았습니다.
예를 들어, 쥐를 미로에 풀어놓으면 자유롭게 터널을 탐험하며 점차적으로 환경의 구조를 이해하게 됩니다. 그런 다음 쥐를 동일한 환경에 다시 도입하고 먹이를 찾거나 출구를 찾는 등 강화 신호를 제공하면 미로를 탐험하지 않은 동물보다 더 빨리 목표에 도달할 수 있습니다. Tolman은 이를 "잠재 학습"이라고 부르는데, 이는 모델 기반 강화 학습의 기초가 됩니다. "잠재 학습"을 통해 동물과 인간은 자신의 세계에 대한 정신적 표현을 형성하고, 마음 속에서 가상 시나리오를 시뮬레이션하고, 결과를 예측할 수 있습니다.
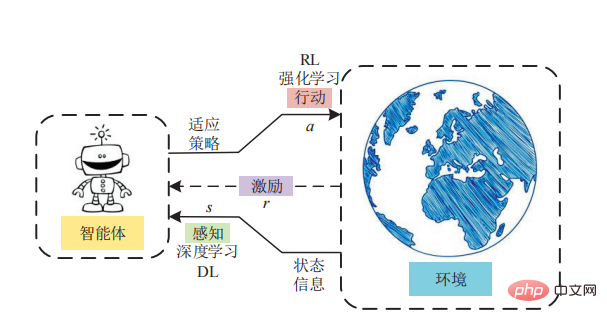
모델 기반 강화 학습의 장점은 에이전트가 환경에서 시행착오를 수행할 필요가 없다는 것입니다. 모델 기반 강화 학습이 체스나 바둑과 같은 보드 게임을 마스터할 수 있는 인공 지능 시스템을 개발하는 데 특히 성공적이라는 점을 강조할 가치가 있습니다. 아마도 이러한 게임의 환경이 결정론적이기 때문일 것입니다.

일반적으로 모델 기반 강화 학습은 시간이 많이 걸리며 시간에 매우 민감한 경우 치명적일 수 있습니다. Lee는 "계산적으로 모델 기반 강화 학습은 훨씬 더 복잡합니다. 먼저 모델을 획득하고 정신적 시뮬레이션을 수행한 다음 신경 프로세스의 궤적을 찾아 조치를 취해야 합니다. 그러나 모델 기반 강화 학습이 반드시 모델이 없는 RL보다 더 복잡한 것은 아닙니다. "환경이 매우 복잡할 때 (빠르게 얻을 수 있는) 상대적으로 간단한 모델로 모델링할 수 있다면 시뮬레이션이 훨씬 더 간단해질 것입니다. 그리고 비용 효율적입니다.
사실 모델 기반 강화 학습이나 모델 없는 강화 학습 모두 완벽한 솔루션은 아닙니다. 복잡한 문제를 해결하는 강화 학습 시스템을 볼 때마다 모델 기반 강화 학습과 모델 없는 강화 학습을 모두 사용하고 더 많은 형태의 학습을 사용할 가능성이 높습니다. 신경 과학 연구에 따르면 인간과 동물 모두 다양한 학습 방법을 가지고 있으며 뇌는 주어진 순간에 이러한 모드 사이를 지속적으로 전환하고 있습니다. 최근에는 여러 강화학습 모델을 결합한 인공지능 시스템을 만드는 데 대한 관심이 높아지고 있습니다. UC San Diego 과학자들의 최근 연구에 따르면 모델 없는 강화 학습과 모델 기반 강화 학습을 결합하면 제어 작업에서 탁월한 성능을 얻을 수 있는 것으로 나타났습니다. 이 대표는 “알파고 같은 복잡한 알고리즘을 보면 모델이 없는 RL 요소와 모델 기반 RL 요소가 모두 있다”며 “보드 구성을 기반으로 상태값을 학습한다. 기본적으로 모델이 없는 RL이고, 하지만 모델 기반 전진 검색도 수행됩니다.
괄목할 만한 성과에도 불구하고 강화 학습의 진행은 느렸습니다. RL 모델이 복잡하고 예측할 수 없는 환경에 직면하면 성능이 저하되기 시작합니다.
Lee는 다음과 같이 말했습니다. "우리 뇌는 다양한 상황을 처리하기 위해 진화한 복잡한 학습 알고리즘의 세계라고 생각합니다."
뇌는 이러한 학습 모드를 지속적으로 전환하는 것 외에도 이를 유지하고 업데이트합니다. 의사결정에 적극적으로 참여하지 않는 경우에도 마찬가지입니다.
심리학자 Daniel Kahneman은 "다양한 학습 모듈을 유지하고 동시에 업데이트하면 인공 지능 시스템의 효율성과 정확성을 향상하는 데 도움이 될 수 있습니다."
또한 AI 시스템에서 작동하는 방법을 이해해야 합니다. 올바른 귀납적 편향 적용 비용 효과적인 방법으로 올바른 내용을 배울 수 있도록 합니다. 수십억 년의 진화를 통해 인간과 동물은 가능한 한 적은 데이터를 사용하면서 효과적으로 학습하는 데 필요한 귀납적 편견을 갖게 되었습니다. 귀납적 편향은 실제 생활에서 관찰되는 현상으로부터 규칙을 요약한 후 모델 선택의 역할을 할 수 있는 특정 제약 조건을 모델에 두는 것으로 이해될 수 있습니다. 가설 공간 . "우리는 환경으로부터 아주 적은 정보를 얻습니다. 그 정보를 사용하여 일반화해야 합니다. 그 이유는 뇌가 귀납적 편견을 갖고 있고, 작은 사례 세트에서 일반화하려는 편견이 있기 때문입니다." 진화의 산물입니다.", 점점 더 많은 신경과학자들이 이에 관심을 갖고 있습니다. 그러나 귀납적 편향은 객체 인식 작업에서는 이해하기 쉽지만 사회적 관계 구축과 같은 추상적인 문제에서는 모호해집니다. 앞으로도 우리가 알아야 할 게 많아요~~~
https://thenextweb.com/news/everything-you-need-to-know-about-model-free-and -모델 기반 강화 학습
위 내용은 미로 속을 걷는 쥐부터 인간을 물리치는 알파고까지, 강화학습의 발전의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



