

이번에 처리할 엑셀은 시트가 2개인데, 시트 하나의 데이터를 바탕으로 다른 시트의 값을 계산해야 합니다. 문제는 계산할 시트에 숫자 값뿐만 아니라 수식도 포함되어 있다는 것입니다. 살펴보겠습니다.
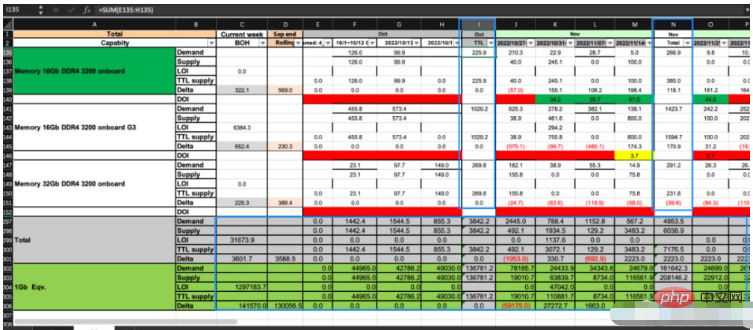
위 그림과 같이 이 엑셀에는 CP와 DS라는 두 개의 시트가 있습니다. 특정 비즈니스 규칙을 따르고 CP의 데이터를 기반으로 DS에 해당하는 셀의 데이터를 계산해야 합니다. . 그림의 파란색 상자에는 수식이 포함되어 있고 다른 영역에는 숫자 값이 포함되어 있습니다.
앞서 언급한 처리 로직을 따르면서 Excel을 일괄적으로 데이터프레임에 한 번에 읽은 다음 다시 일괄적으로 다시 작성하면 어떤 문제가 있나요? 코드의 이 부분은 다음과 같습니다.
import pandas as pd
import xlwings as xw
#要处理的文件路径
fpath = "data/DS_format.xlsm"
#把CP和DS两个sheet的数据分别读入pandas的dataframe
cp_df = pd.read_excel(fpath,sheet_name="CP",header=[0])
ds_df = pd.read_excel(fpath,sheet_name="DS",header=[0,1])
#计算过程省略......
#保存结果到excel
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()위 코드의 문제점은 pd.read_excel() 메서드가 Excel에서 데이터 프레임으로 데이터를 읽을 때 수식이 있는 셀의 경우 수식 계산 결과를 직접 읽게 된다는 것입니다. (그렇지 않으면 결과는 Nan으로 반환됩니다) 그리고 Excel에 쓸 때 데이터 프레임을 일괄적으로 일괄 다시 쓰기 때문에 이전에 수식이 있는 셀은 계산된 값이나 Nan으로 다시 쓰여지고 수식은 다음과 같습니다. 잃어버린.
알겠습니다. 문제가 발생했습니다. 어떻게 해결해야 할까요? 여기서는 두 가지 아이디어가 떠오릅니다.
데이터프레임을 Excel에 다시 작성할 때 일괄적으로 다시 작성하지 말고 행과 열의 반복을 통해 계산된 데이터만 다시 작성하고 수식이 있는 셀은 변경하지 않고 그대로 둡니다.
#根据ds_df来写excel,只写该写的单元格
for row_idx,row in ds_df.iterrows():
total_capabity_val = row[('Total','Capabity')].strip()
total_capabity1_val = row[('Total','Capabity.1')].strip()
#Total和1Gb Eqv.所在的行不写
if total_capabity_val!= 'Total' and total_capabity_val != '1Gb Eqv.':
#给Delta和LOI赋值
if total_capabity1_val == 'LOI' or total_capabity1_val == 'Delta':
ds_worksheet.range((row_idx + 3 ,3)).value = row[('Current week','BOH')]
print(f"ds_sheet的第{row_idx + 3}行第3列被设置为{row[('Current week','BOH')]}")
#给Demand和Supply赋值
if total_capabity1_val == 'Demand' or total_capabity1_val == 'Supply':
cp_datetime_columns = cp_df.columns[53:]
for col_idx in range(4,len(ds_df.columns)):
ds_datetime = ds_df.columns.get_level_values(1)[col_idx]
ds_month = ds_df.columns.get_level_values(0)[col_idx]
if type(ds_datetime) == str and ds_datetime != 'TTL' and ds_datetime != 'Total' and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',f'{ds_datetime}')]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',f'{ds_datetime}')]}")
elif type(ds_datetime) == datetime.datetime and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',ds_datetime)]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',ds_datetime)]}")import openpyxl ds_format_workbook = openpyxl.load_workbook(fpath,data_only=False) ds_wooksheet = ds_format_workbook['DS'] ds_df = pd.DataFrame(ds_wooksheet.values)
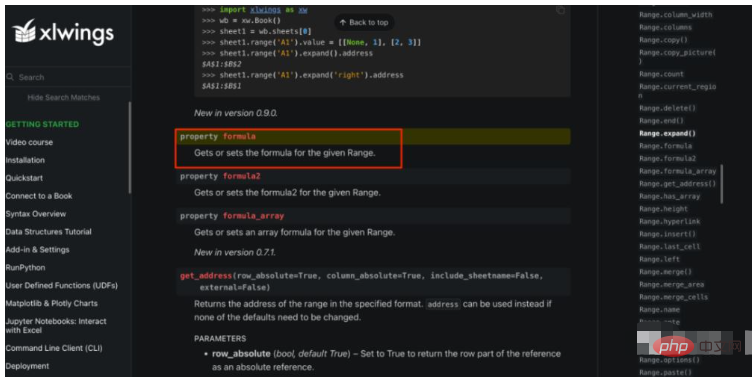
#使用xlwings来读取formula app = xw.App(visible=False,add_book=False) ds_format_workbook = app.books.open(fpath) ds_worksheet = ds_format_workbook.sheets["DS"] #先把所有公式一次性读取并保存下来 formulas = ds_worksheet.used_range.formula #中间计算过程省略... #一次性把所有公式写回去 ds_worksheet.used_range.formula = formulas
#使用xlwings来读取formula
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
#保留excel中的formula
#找到DS中Total所在的行,Total之后的行都是formula
row = ds_df.loc[ds_df[('Total','Capabity')]=='Total ']
total_row_index = row.index.values[0]
#获取对应excel的行号(dataframe把两层表头当做索引,从数据行开始计数,而且从0开始计数。excel从表头就开始计数,而且从1开始计数)
excel_total_row_idx = int(total_row_index+2)
#获取excel最后一行的索引
excel_last_row_idx = ds_worksheet.used_range.rows.count
#保留按日期计算的各列的formula
I_col_formula = ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula
N_col_formula = ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula
T_col_formula = ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula
U_col_formula = ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula
Z_col_formula = ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula
AE_col_formula = ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula
AK_col_formula = ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula
AL_col_formula = ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula
#保留Total行开始一直到末尾所有行的formula
total_to_last_formula = ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula
#中间计算过程省略...
#保存结果到excel
#直接把ds_df完整赋值给excel,会导致excel原有的公式被值覆盖
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
#用之前保留的formulas,重置公式
ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula = I_col_formula
ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula = N_col_formula
ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula = T_col_formula
ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula = U_col_formula
ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula = Z_col_formula
ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula = AE_col_formula
ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula = AK_col_formula
ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula = AL_col_formula
ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula = total_to_last_formula
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()위 내용은 Python은 Excel 파일을 어떻게 처리합니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



