

apscheduler 모듈 설치
pip install apscheduler
APScheduler(고급 Python 스케줄러)는 경량 Python 예약 작업 예약 프레임워크(Python 라이브러리)입니다.
APScheduler에는 다음과 같은 세 가지 내장 예약 시스템이 있습니다.
cron 스타일 예약(선택적 시작/종료 시간)
간격 기반 실행(일정한 간격으로 작업 실행, 선택적인 시작/종료 시간 글쎄) )
일회성 지연 작업 실행(지정된 날짜/시간에 작업을 한 번 실행)
APScheduler는 예약 시스템과 작업 저장소 백엔드를 임의로 혼합하고 일치시킬 수 있습니다. 백엔드 스토리지 작업은 다음과 같습니다.
APScheduler에는 네 가지 구성 요소가 있습니다.
트리거에는 일정이 포함됩니다. 논리이며 각 작업에는 다음 실행 시간을 결정하는 자체 트리거가 있습니다. 자체 초기 구성과 별도로 트리거는 완전히 상태 비저장입니다.
작업 저장소(job store)는 예정된 작업을 저장합니다. 기본 작업 저장소는 단순히 작업을 메모리에 저장하고 다른 작업 저장소는 작업을 데이터베이스에 저장합니다. 작업이 영구 작업 저장소에 저장되면 로드 시 작업 데이터가 직렬화 및 역직렬화됩니다. 작업 저장은 스케줄러를 공유할 수 없습니다.
실행자는 일반적으로 작업의 스레드 또는 프로세스 풀에 지정된 호출 가능 개체를 제출하여 작업 실행을 처리합니다. 작업이 완료되면 실행자는 스케줄러에게 이를 알립니다.
스케줄러(schedulers) 작업 저장 및 실행기 구성은 작업 추가, 수정, 제거 등 스케줄러에서 수행할 수 있습니다. 다양한 애플리케이션 시나리오에 따라 다양한 스케줄러를 선택할 수 있습니다. BlockingScheduler, BackgroundScheduler, AsyncIOScheduler, GeventScheduler, TornadoScheduler, TwistedScheduler 및 QtScheduler의 7가지 옵션이 있습니다.
각 구성 요소 소개
날짜 세 가지 기본 제공 트리거 유형이 있습니다. : 일회성 지정 날짜;
간격: 특정 시간 범위 내에서 실행되는 빈도
cron: Linux crontab 형식과 호환되며 가장 강력합니다.
date는 가장 기본적인 종류의 스케줄링이며 작업은 한 번만 실행됩니다. 해당 매개변수는 다음과 같습니다:
(datetime.tzinfo|str) – Storage
애플리케이션이 시작될 때마다 작업을 다시 생성하므로 기본 작업 저장소(MemoryJobStore)를 사용하지만, 스케줄러가 다시 시작되거나 애플리케이션이 충돌하더라도 작업을 유지해야 하는 경우 Select를 사용해야 합니다. 귀하의 애플리케이션 환경에 따른 특정 작업 메모리. 예: Mongo 또는 SQLAlchemy JobStore 사용(대부분의 RDBMS 지원에 사용)Executor
CPU 집약적인 작업
이 포함된 경우 ProcessPoolExecutor를 사용하여 더 많은 CPU 코어를 사용하는 것이 좋습니다. ProcessPoolExecutor를 두 번째 실행기로 사용하여 두 가지를 동시에 사용할 수도 있습니다.올바른 스케줄러 선택
BackgroundScheduler: 다른 프레임워크를 실행하지 않고 스케줄러가 앱의 백그라운드에 있도록 하려는 경우 앱 실행 중에 사용됩니다.
AsyncIOScheduler: 프로그램이 asyncio(비동기 프레임워크)를 사용할 때 사용됩니다.
GeventScheduler: 프로그램이 gevent(고성능 Python 동시성 프레임워크)를 사용할 때 사용됩니다.TornadoScheduler: 프로그램이 Tornado(웹 프레임워크)를 기반으로 하는 경우 사용됩니다.
TwistedScheduler: 프로그램이 Twisted(비동기 프레임워크)를 사용할 때 사용합니다.
QtScheduler: 응용 프로그램이 Qt 응용 프로그램인 경우 사용할 수 있습니다.
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job1():
print('my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
def my_job2():
print('my_job2 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
# 每隔5秒运行一次my_job1
sched.add_job(my_job1, 'interval', seconds=5, id='my_job1')
# 每隔5秒运行一次my_job2
sched.add_job(my_job2, 'cron', second='*/5', id='my_job2')
sched.start()# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
sched = BlockingScheduler()
# 每隔5秒运行一次my_job1
@sched.scheduled_job('interval', seconds=5, id='my_job1')
def my_job1():
print('my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
# 每隔5秒运行一次my_job2
@sched.scheduled_job('cron', second='*/5', id='my_job2')
def my_job2():
print('my_job2 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched.start()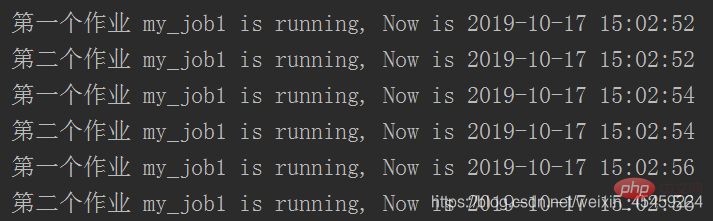
使用remove() 移除作业
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job(text=""):
print(text, 'my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
job = sched.add_job(my_job, 'interval', seconds=2, args=['第一个作业'])
job.remove()
# #如果有多个任务序列的话可以给每个任务设置ID号,可以根据ID号选择清除对象,且remove放到start前才有效
sched.add_job(my_job, 'interval', seconds=2, id='my_job_id', args=['第二个作业'])
sched.start()代码执行结果:

使用remove_job()移除作业
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job(text=""):
print(text, 'my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
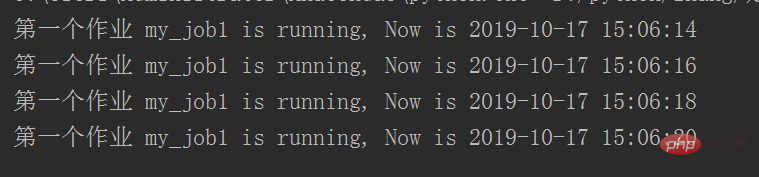
job = sched.add_job(my_job, 'interval', seconds=2, args=['第一个作业'])
# #如果有多个任务序列的话可以给每个任务设置ID号,可以根据ID号选择清除对象,且remove放到start前才有效
sched.add_job(my_job, 'interval', seconds=2, id='my_job_id', args=['第二个作业'])
sched.remove_job('my_job_id')
sched.start()代码执行结果:
APScheduler有3中内置的触发器类型:
新建一个调度器(scheduler);
添加一个调度任务(job store);
运行调度任务。
代码实现
# -*- coding:utf-8 -*-
import time
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
def my_job(text="默认值"):
print(text, time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
sched = BlockingScheduler()
sched.add_job(my_job, 'interval', seconds=3, args=['3秒定时'])
# 2018-3-17 00:00:00 执行一次,args传递一个text参数
sched.add_job(my_job, 'date', run_date=datetime.date(2019, 10, 17), args=['根据年月日定时执行'])
# 2018-3-17 13:46:00 执行一次,args传递一个text参数
sched.add_job(my_job, 'date', run_date=datetime.datetime(2019, 10, 17, 14, 10, 0), args=['根据年月日时分秒定时执行'])
# sched.start()
"""
interval 间隔调度,参数如下:
weeks (int) – 间隔几周
days (int) – 间隔几天
hours (int) – 间隔几小时
minutes (int) – 间隔几分钟
seconds (int) – 间隔多少秒
start_date (datetime|str) – 开始日期
end_date (datetime|str) – 结束日期
timezone (datetime.tzinfo|str) – 时区
"""
"""
cron参数如下:
year (int|str) – 年,4位数字
month (int|str) – 月 (范围1-12)
day (int|str) – 日 (范围1-31)
week (int|str) – 周 (范围1-53)
day_of_week (int|str) – 周内第几天或者星期几 (范围0-6 或者 mon,tue,wed,thu,fri,sat,sun)
hour (int|str) – 时 (范围0-23)
minute (int|str) – 分 (范围0-59)
second (int|str) – 秒 (范围0-59)
start_date (datetime|str) – 最早开始日期(包含)
end_date (datetime|str) – 最晚结束时间(包含)
timezone (datetime.tzinfo|str) – 指定时区
"""
# my_job将会在6,7,8,11,12月的第3个周五的1,2,3点运行
sched.add_job(my_job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
# 截止到2018-12-30 00:00:00,每周一到周五早上五点半运行job_function
sched.add_job(my_job, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2018-12-31')
# 表示2017年3月22日17时19分07秒执行该程序
sched.add_job(my_job, 'cron', year=2017, month=3, day=22, hour=17, minute=19, second=7)
# 表示任务在6,7,8,11,12月份的第三个星期五的00:00,01:00,02:00,03:00 执行该程序
sched.add_job(my_job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
# 表示从星期一到星期五5:30(AM)直到2014-05-30 00:00:00
sched.add_job(my_job, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2014-05-30')
# 表示每5秒执行该程序一次,相当于interval 间隔调度中seconds = 5
sched.add_job(my_job, 'cron', second='*/5', args=['5秒定时'])
sched.start()| cron表达式 | 参数 | 描述 |
|---|---|---|
| * | any | Fire on every value |
| */a | any | Fire every a values, starting from the minimum |
| a-b | any | Fire on any value within the a-b range (a must be smaller than b) |
| a-b/c | any | Fire every c values within the a-b range |
| xth y | day | Fire on the x -th occurrence of weekday y within the month |
| last x | day | Fire on the last occurrence of weekday x within the month |
| last | day | Fire on the last day within the month |
| x,y,z | any | Fire on any matching expression; can combine any number of any of the above expressions |
使用SQLAlchemy作业存储器存放作业
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
import logging
sched = BlockingScheduler()
def my_job():
print('my_job is running, Now is %s' % datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
# 使用sqlalchemy作业存储器
# 根据自己电脑安装的库选择用什么连接 ,如pymysql 其中:scrapy表示数据库的名称,操作数据库之前应创建对应的数据库
url = 'mysql+pymysql://root:123456@localhost:3306/scrapy?charset=utf8'
sched.add_jobstore('sqlalchemy', url=url)
# 添加作业
sched.add_job(my_job, 'interval', id='myjob', seconds=5)
log = logging.getLogger('apscheduler.executors.default')
log.setLevel(logging.INFO) # DEBUG
# 设定日志格式
fmt = logging.Formatter('%(levelname)s:%(name)s:%(message)s')
h = logging.StreamHandler()
h.setFormatter(fmt)
log.addHandler(h)
sched.start()暂停和恢复作业
# 暂停作业: apsched.job.Job.pause() apsched.schedulers.base.BaseScheduler.pause_job() # 恢复作业: apsched.job.Job.resume() apsched.schedulers.base.BaseScheduler.resume_job()
获得job列表
get_jobs(),它会返回所有的job实例;
使用print_jobs()来输出所有格式化的作业列表;
get_job(job_id=“任务ID”)获取指定任务的作业列表。
代码实现:
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job(text=""):
print(text, 'my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
job = sched.add_job(my_job, 'interval', seconds=2, args=['第一个作业'])
sched.add_job(my_job, 'interval', seconds=2, id='my_job_id', args=['第二个作业'])
print(sched.get_jobs())
print(sched.get_job(job_id="my_job_id"))
sched.print_jobs()
sched.start()关闭调度器
默认情况下调度器会等待所有正在运行的作业完成后,关闭所有的调度器和作业存储。如果你不想等待,可以将wait选项设置为False。
sched.shutdown() sched.shutdown(wait=False)
위 내용은 Python에서 타사 모듈 apscheduler를 설치하고 사용하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



