

계정을 성공적으로 등록하면 아래 그림과 같이 경쟁 링크에서 타이타닉 침몰 생존 경쟁 링크를 찾을 수 있습니다.
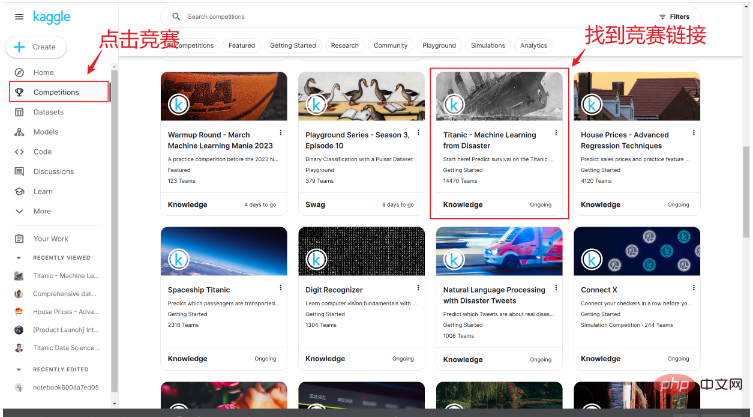
대회 페이지에 들어가면 간략한 내용을 볼 수 있습니다. 대회 소개와 다른 사람의 코드 및 기타 콘텐츠를 보려면 여기에서 데이터를 클릭합니다.
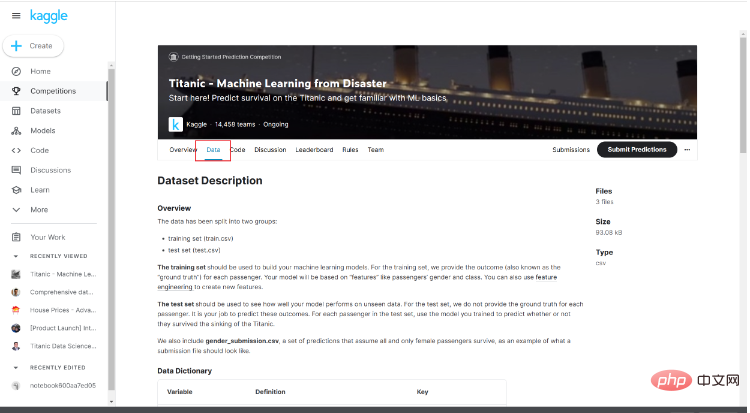
여기의 데이터 소개를 주목해 보면 데이터의 기본 상황과 그것이 무엇을 나타내는지 이해하는 데 도움이 됩니다.
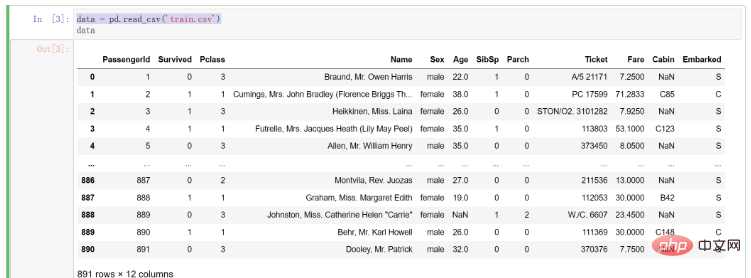
데이터를 얻은 후 컴파일 환경을 열고 데이터 분석을 시작할 준비를 합니다. 이 글에서는 데이터 분석을 위해 jupyter를 사용합니다. 물론 후속 작업에 익숙한 컴파일 환경을 선택할 수 있습니다. .
데이터를 가져온 후 먼저 컴파일 환경으로 읽어들이는 코드를 작성합니다. 코드는 다음과 같습니다.
# 导入pandas import pandas as pd # 将训练集数据导入 data = pd.read_csv('train.csv')
데이터를 가져온 후의 결과는 다음과 같습니다.
데이터를 얻은 후에는 데이터에 대한 예비 관찰 및 데이터 정리를 수행해야 합니다. 여기에서는 Kaggle 상사가 제안한 4C 데이터 정리 원칙을 소개합니다.
수정: 이름에서 알 수 있듯이 데이터 수정은 데이터의 이상값을 처리하는 것입니다. 예를 들어 100개 이상의 연령 데이터가 있는 경우 이는 비정상적인 값이어야 합니다. 우리는 이상치가 정상적이고 유효한지 확인하기 위해 다양한 데이터를 검사할 것입니다. 하지만 정확한 모델을 구축하는 초석은 데이터이고, 데이터가 모델의 품질을 결정하기 때문에 원본 데이터에서 데이터를 수정할 때는 주의해야 합니다.
완성(보완): 결측값 완성 그리고 우리가 발견한 이상값이 필요했습니다. 일부 모델에서는 처리 없이 결측값을 자동으로 처리하는 데 도움이 될 수 있습니다(예: 의사결정 트리). 이 부분에서는 일반적으로 결측값의 비율이 작은 결측값을 선택하여 삭제합니다. 상대적으로 비율이 크거나 비율이 매우 큰 결측값에 대해서는 원본에서 어떤 종류의 패턴을 탐색하는 것을 고려해 보겠습니다. 데이터를 채워야 합니다.
Creating: 기능 엔지니어링에서는 원래 기능을 이해하고 새로운 기능을 추출할지 여부를 결정해야 합니다. 예를 들어, 이 문제에서는 연령 분할을 새로운 기능으로 고려할 수 있습니다. 물론 여기서의 전제는 문제에 대해 깊이 이해하고 추출한 특징이 최종 모델 구성에 실제로 도움이 될 수 있는지 탐구하는 것입니다. 이를 위해서는 반복적으로 검증하고, 특징 추출에 대해 생각하고, 다양한 문제에 실제로 도움이 되는 특징을 찾아야 합니다.
Converting: 특정 데이터 형식을 타겟팅할 때 데이터 변환을 수행해야 할 수도 있습니다. 이는 물론 매우 중요합니다. 예를 들어 일부 문자열 유형의 데이터는 이를 나타내기 위해 숫자 형식으로 변환되어야 합니다.
이 단계에서는 Pandas의 기본 기능을 호출하여 데이터에 대한 예비 관찰을 수행합니다. 먼저 info()를 호출하여 데이터의 종류와 기본 상황을 살펴봅니다.
data.info()
결과는 다음과 같습니다.
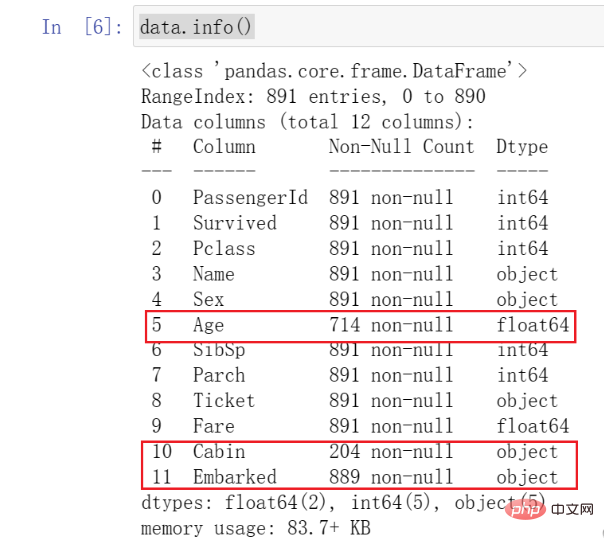
이 함수를 호출하면 데이터의 종류와 기본 상황을 알 수 있습니다. 모든 데이터의 상황.
여기에 표시한 데이터에 주의해야 합니다. Age 데이터가 다른 데이터보다 훨씬 작은 것을 발견했는데, 이를 결측값이라고 합니다. 동시에 Cabin 및 Embarked도 누락되었음을 확인할 수 있습니다 .
이 모든 것에는 우리의 주의가 필요하며 향후 일부 처리가 필요합니다. 그런 다음, 데이터 분포를 더 자세히 관찰하기 위해 explain() 함수를 호출합니다. 이 함수는 데이터의 각 열의 분포와 평균을 계산하는 데 도움이 될 수 있습니다. 코드는 다음과 같습니다.data.describe()
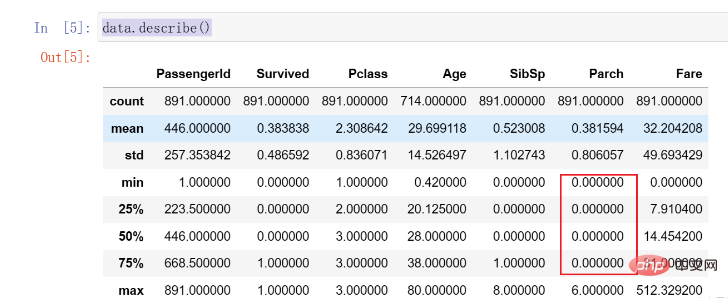
Parch데이터의 75%는 0입니다. 명백히 고르지 않은 분포가 있으며 나중에 처리해야 할 수도 있습니다.
결측값 처리(완료)이전 섹션에서는 데이터에 특정 결측 조건이 있음을 먼저 시각화하여 데이터를 보다 직관적으로 관찰할 수 있었습니다. 여기에서는 누락된 데이터를 시각화하기 위해 Missingno 라이브러리를 사용합니다. 이는 누락된 데이터의 시각화를 더욱 직관적으로 만듭니다.使用之前,请确保自己已经安装该库。
使用该库进行可视化的代码如下:
# 在数据中抽样100个单位 data_sample = data.sample(100) msno.matrix(data_sample)
结果如下:
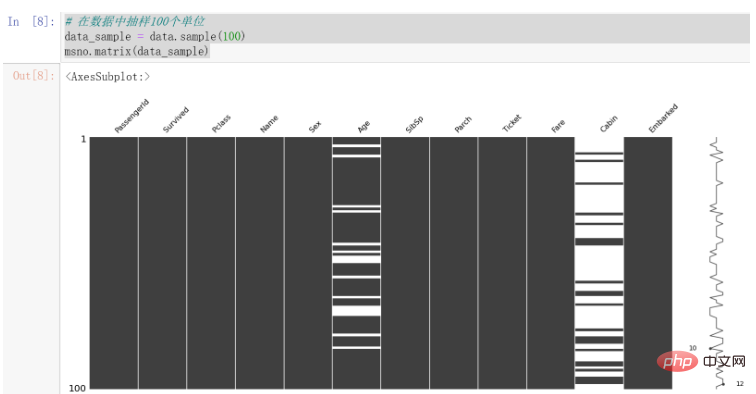
可以发现,Cabin的缺失值较为明显,Age也存在一些缺失值。
因为数据中每列代表的情况不尽相同,所以我们将针对数据进行不同的处理方法。
我们再通过代码来观察一下缺失的数据情况,代码与结果如下:
missing_data = data.isnull().sum() missing_data = missing_data [missing_data >0] missing_data
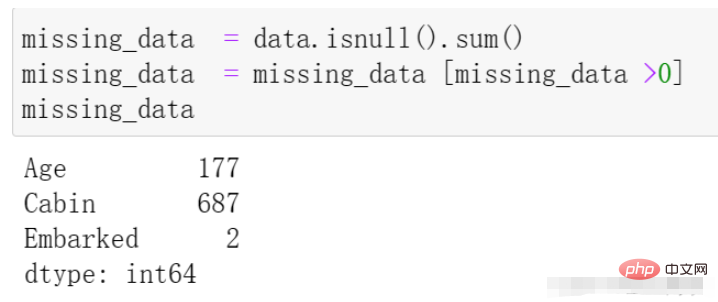
我们首先处理Embarked列,在上边的数据观察中发现其拥有两个缺失值,因为相对于全部的一千条数据来说其量级较小,所以我们在这里直接选择该列缺失的两条数据进行删除处理,代码如下:
# 在data中寻找Embarked的缺失值 找到后在原表中将其行删除 data.dropna(axis=0, how='any',subset=['Embarked'], inplace=True)
dropna 参数介绍:
axis: default 0指行,1为列
how: {‘any’, ‘all’}, default ‘any’指带缺失值的所有行;'all’指清除全是缺失值的
thresh: int,保留含有int个非空值的行
subset: 对特定的列进行缺失值删除处理
inplace: 这个很常见,True表示直接在原数据上更改
在上述观察中,我们发现Age存在一定的缺失情况,接下来我们对其进行处理。
我们由Kaggle中的数据介绍中了解到,其表示乘客的年龄,且缺失值相对来说较多,不能够直接采用删除的方式。
我们首先观察Age的分布情况,绘制年龄的直方图,代码如下:
data.hist(column='Age')
结果如下:
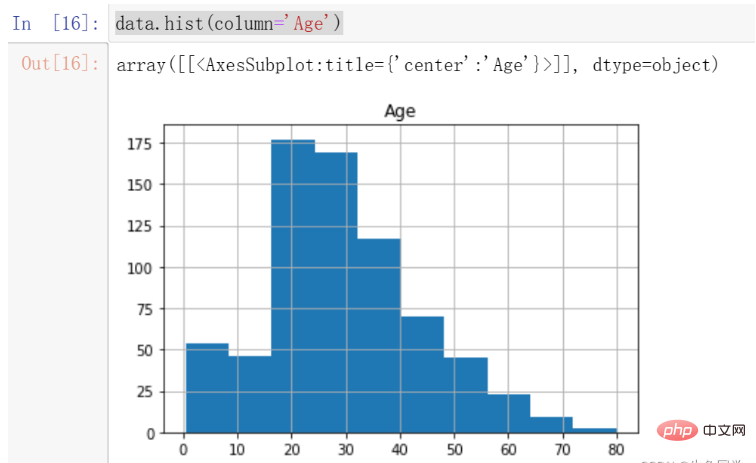
我们注意到,年龄的分布存在一定的偏态,这时候更适合采用中位数进行填充。
注意:偏态分布的大部分值都聚集在变量分布的一侧,中位数可以很好的表示中心趋势。
所以,我们对年龄的缺失值进行中位数的填充。代码如下:
data['Age'].fillna(data['Age'].median(), inplace=True)
至此,我们对于年龄的缺失值处理完毕。
我们首先看一下Cabin的数据解释:Cabin number(机舱号码)
对于该特征来说,仿佛对于最终的数据帮助不大。即使其对于最后的数据是非常重要的,由于其缺失值过多且不容易探寻其中的规律,我们还是选择对其做删除的处理。
代码如下:
# 这里我直接删除了该列 del data['Cabin']
至此,所有数据的缺失值处理完毕。
在本例中,我们能够进行检测并处理的主要是Age特征,因为我们预先知道其大概的范围。在这里我们绘制箱线图观察其数据的异常情况决定是否需要进行处理,代码如下:
data['Age'].plot.box()
结果如下:
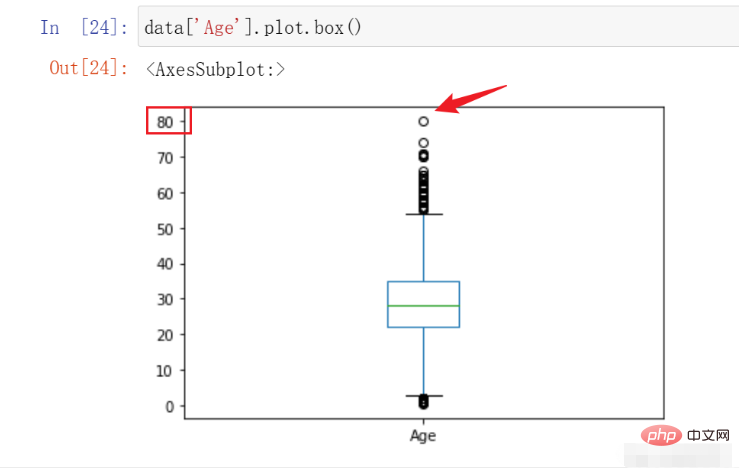
在这里,我们可以看到该数据的最高点在80,符合我们对于数据的预先认知,遂不进行处理。
在这部分中,要求我们对不同的特征有一定的了解以及认识,在这里我列出所有的特征含义。
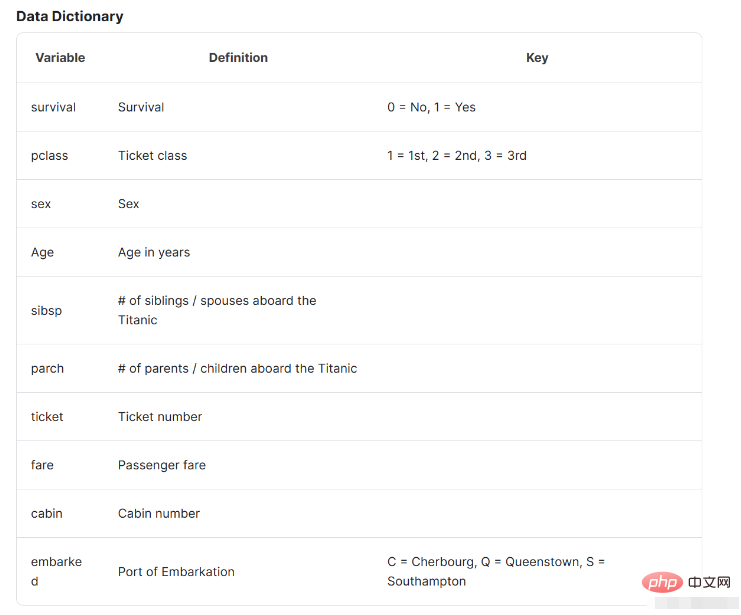
特征名称含义survival是否存活,1表示存活,0表示没有pclass表示票的种类,分别为1,2,3等sex性别Age年龄sibsp在泰坦尼克号上的兄弟姐妹/配偶的数量parch在泰坦尼克号上的父母/子女人数ticket票号fare乘客票价cabin机舱号embarked上岸港口 ,C = Cherbourg, Q = Queenstown, S = Southampton
在这里,我们提取两个特征,分别是乘客家庭规模,是否独自一人,并对票价以及年龄进行分段构造两个新的特征。
注意:针对不同的项目采取的特征提取工作并不相同,因为这需要根据具体的业务进行分析并提取。
我们首先针对家庭规模以及是否独自一人创建新的两个特征,代码如下:
data['FamilySize'] = data['SibSp'] + data['Parch'] + 1 data['IsAlone'] = 1 data['IsAlone'].loc[data['FamilySize'] > 1] = 0
然后,我们对年龄和票价进行分段,代码如下:
data['FareBin'] = pd.qcut(data['Fare'], 4) data['AgeBin'] = pd.cut(data['Age'].astype(int), 5)
这里简单介绍一下上述两个函数的区别与作用
qcut:根据传入的数值进行等频分箱,即每个箱子中含有的数的数量是相同的。
cut:根据传入的数值进行等距离分箱,即每个箱子的间距都是相同的。
特别的,在本节中特征工程的过程要根据实际业务进行不同的特征提取,这个过程需要我们对业务有足够的理解程度。几个好的特征对后续的模型精确程度有很大的积极影响。
某些特定的格式在很多模型中其实是不适用的,在本例中经过上述处理后的数据如下所示:
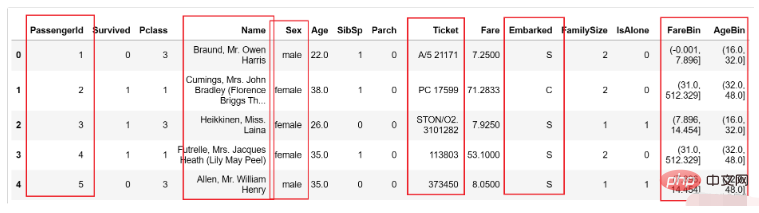
图中的性别等内容都为字符类型,这显然在模型中存在一定的不兼容情况,这就需要我们进行一定程度的格式转换。
在本部分中,我们要处理的有以下几个部分:
PassengerId:用户id的部分对后面的预测仿佛用处不大,我们对其进行删除。Name:这里的名字中有MR.MISS等信息,这可能对后续的模型有帮助,我们对其进行处理保留。Sex:需要进行编码使用,因为它是字符串类型。Ticket:仿佛用处不大,这里我们选择删除。Embarked:需要进行编码使用,因为它是字符串类型。FareBin:需要进行编码使用,因为它是一个范围。AgeBin:需要进行编码使用,因为它是一个范围。
我们首先对需要删除的两列进行删除的操作,代码如下:
del data['PassengerId'] del data['Ticket']
然后我们对Name进行处理,将其中的身份信息提取出来,代码如下:
data['Title'] = data['Name'].str.split(", ", expand=True)[1].str.split(".", expand=True)[0]结果如下:

最后,我们对需要编码的数据进行编码:
from sklearn.preprocessing import OneHotEncoder, LabelEncoder label = LabelEncoder() data['Sex_Code'] = label.fit_transform(data['Sex']) data['Embarked_Code'] = label.fit_transform(data['Embarked']) data['Title_Code'] = label.fit_transform(data['Title']) data['AgeBin_Code'] = label.fit_transform(data['AgeBin']) data['FareBin_Code'] = label.fit_transform(data['FareBin'])
编码后的结果如下:
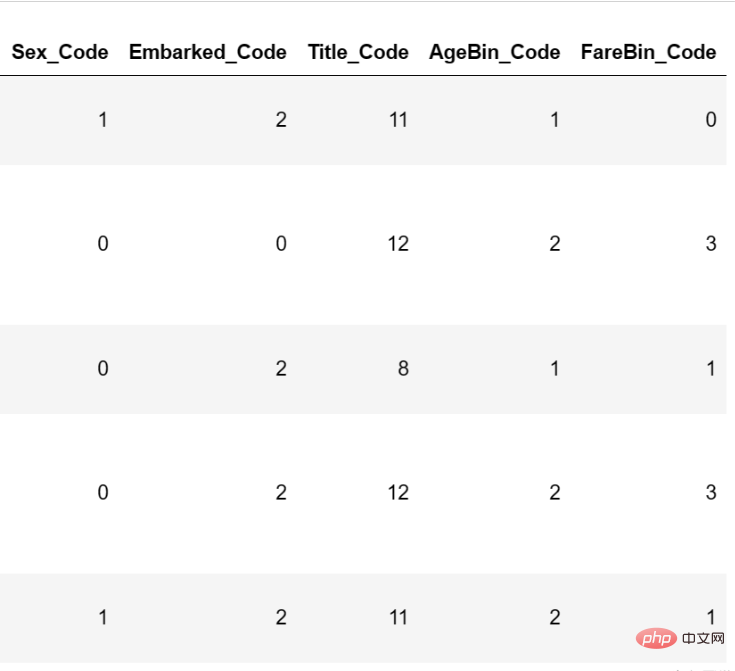
至此,数据格式转换已经完毕。
在本节中,我们将基于上述数据进行模型的构建,并且通过不同的评价指标进行构建。
在这里我将会使用基础的分类模型进行模型的构建,并挑选出初步表现最好的模型进行参数调节。代码如下:
# 处理不需要的数据列
data_x = data.copy()
del data_x['Survived']
del data_x['Name']
del data_x['Sex']
del data_x['FareBin']
del data_x['AgeBin']
del data_x['Title']
del data_x['Embarked']
# 构建y
data_y = data['Survived']
# 导入包
from sklearn import svm, tree, linear_model, neighbors, naive_bayes, ensemble, discriminant_analysis, gaussian_process
from sklearn.model_selection import cross_val_score
# 定义常用的几种分类模型
MLA = {
#随机森林
'随机森林':ensemble.RandomForestClassifier(),
#逻辑回归
'逻辑回归':linear_model.LogisticRegressionCV(max_iter=3000),
#SVM
'SVM':svm.SVC(probability=True),
#树模型
'树模型':tree.DecisionTreeClassifier(),
}
# 进行5折交叉验证并选择f1作为评价指标
for model_name in MLA:
scores = cross_val_score(MLA[model_name], X=data_x, y=data_y, verbose=0, cv = 5, scoring='f1')
print(f'{model_name}:',scores.mean())结果如下:

我们可以看到,目前随机森林的效果最好,所以我们选择随机森林进行参数调节。
在这里我们选择使用网格调参的方式进行参数调节,代码如下:
from sklearn.model_selection import GridSearchCV
n_estimators = [3,5,10,15,20,40, 55]
max_depth = [10,100,1000]
parameters = { 'n_estimators': n_estimators, 'max_depth': max_depth}
model = ensemble.RandomForestClassifier()
clf = GridSearchCV(model, parameters, cv=5)
clf = clf.fit(data_x, data_y)
clf.best_estimator_结果如下:

在这里,我们选择了几个简单的参数进行调节,可以根据自己的实际情况对不同的参数进行调节。我们再进行一次交叉验证求平均值看一下效果,结果如下:

可以看到与刚才的效果相比有一些提升。
위 내용은 Python을 사용한 타이타닉 생존자의 데이터 분석 및 예측의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



