

그래프 최적화는 AI 모델의 훈련과 추론에 사용되는 시간과 리소스를 줄이는 데 중요한 역할을 합니다. 그래프 최적화의 중요한 기능은 모델에 융합될 수 있는 연산자를 융합함으로써 저속 메모리에서의 메모리 사용량과 데이터 전송을 줄여 컴퓨팅 효율성을 향상시키는 것입니다. 그러나 다양한 운영자 융합을 제공할 수 있는 백엔드 솔루션을 구현하는 것은 매우 어렵기 때문에 실제 하드웨어에서 AI 모델이 사용할 수 있는 운영자 융합은 매우 제한적입니다.
컴포저블 커널(CK) 라이브러리는 AMD GPU에서 운영자 융합을 위한 백엔드 솔루션 세트를 제공하는 것을 목표로 합니다. CK는 범용 프로그래밍 언어인 HIP C++를 사용하며 완전한 오픈 소스입니다. 디자인 컨셉은 다음과 같습니다:
CK는 백엔드 개발자의 생산성을 향상시키기 위한 두 가지 개념을 소개합니다:
1 . "Tensor Coordinate Transformation"을 도입하면 AI 연산자 작성의 복잡성이 줄어듭니다. 이 연구는 재사용 가능한 Tensor Coordinate Transformation 기본 모듈 세트의 정의를 개척했으며 이를 사용하여 복잡한 AI 연산자(예: 컨볼루션, 그룹 정규화 감소, Depth2Space 등)를 수학적으로 엄격한 방식으로 가장 기본적인 AI로 다시 표현했습니다. 연산자(GEMM, 2D 축소, 텐서 전송 등). 이 기술을 사용하면 기본 AI 연산자용으로 작성된 알고리즘을 알고리즘을 다시 작성할 필요 없이 해당하는 모든 복잡한 AI 연산자에 직접 사용할 수 있습니다.
2. 타일 기반 프로그래밍 패러다임: 연산자 융합을 위한 백엔드 알고리즘을 개발하는 것은 먼저 각 사전 융합 연산자(독립 연산자)를 이러한 "작은 블록"의 여러 "작은 조각"으로 분해하는 것으로 볼 수 있습니다. " 작업은 융합된 연산자로 결합됩니다. 이러한 각각의 "작은 블록" 연산은 원래의 독립 연산자에 해당하지만 연산되는 데이터는 원래 텐서의 일부(타일)일 뿐이므로 이러한 "작은 블록" 연산을 타일 텐서 연산자라고 합니다. CK 라이브러리에는 고도로 최적화된 Tile Tensor Operator 구현 세트가 포함되어 있으며, CK의 모든 AI 독립 연산자와 융합 연산자는 이를 사용하여 구현됩니다. 현재 이러한 타일 텐서 연산자에는 Tile GEMM, Tile Reduction 및 Tile Tensor Transfer가 포함됩니다. 각 타일 텐서 연산자에는 GPU 스레드 블록, 워프 및 스레드에 대한 구현이 있습니다.
Tensor Coordinate Transformation과 Tile Tensor Operator가 함께 재사용 가능한 CK의 기본 모듈을 구성합니다.
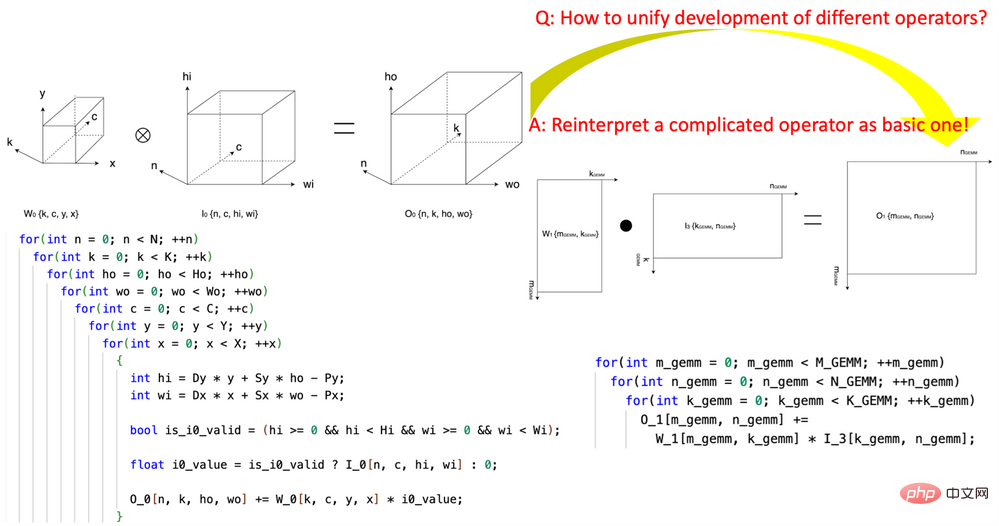
그림 1, CK의 Tensor Coordinate Transformation 기본 모듈을 사용하여 컨볼루션 연산자를 GEMM 연산자로 표현
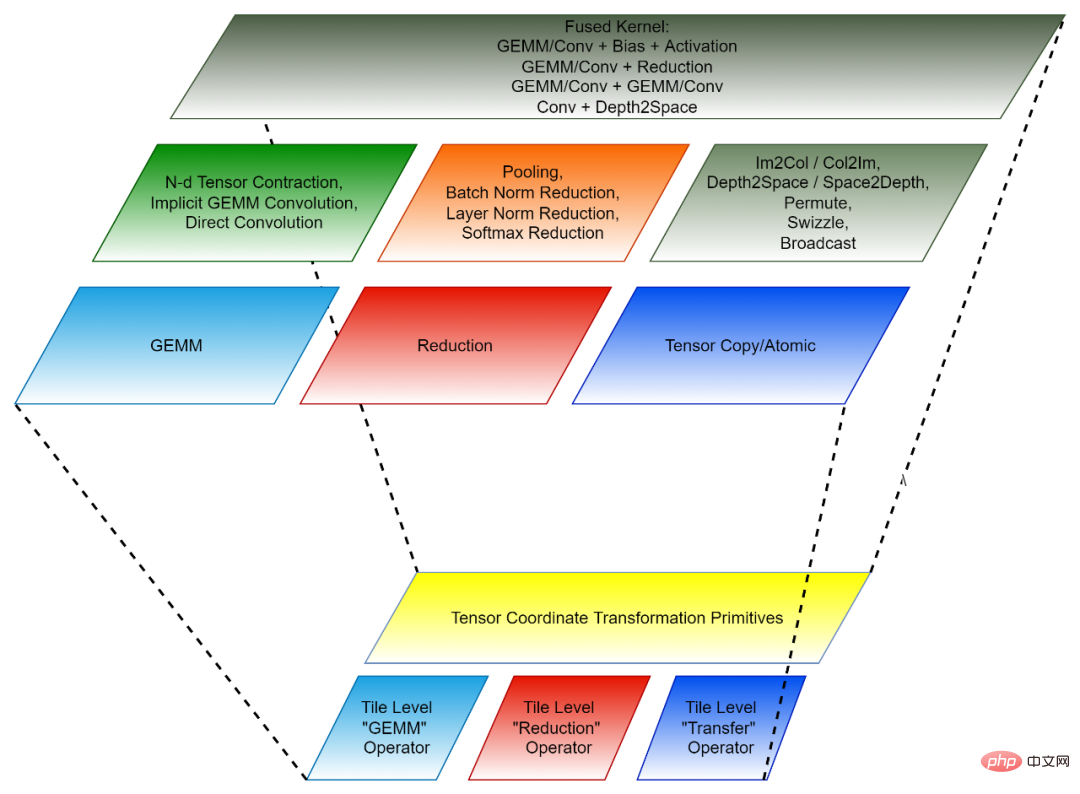
그림 2, CK의 구성(아래: 재사용 가능 기본 호출자 및 클라이언트 API 모듈 [3]. 각 계층은 서로 다른 개발자에 해당합니다.
AI 시스템 전문가: "저는 오픈 소스 AI 프레임워크에 대한 최첨단 그래프 최적화 작업을 수행합니다. 그래프 최적화에 필요한 모든 융합 연산자에 고성능 커널을 제공할 수 있는 백엔드 솔루션이 필요합니다. 동시에, 이러한 커널은 사용자 정의해야 하므로 "받아들이거나 그대로 두는 것"과 같은 블랙박스 솔루션은 내 요구 사항을 충족하지 않습니다." 템플릿 커널 및 호출자 레이어는 이러한 유형의 개발자를 만족시킵니다. 예를 들어, 이 예제[5]에서 개발자는 템플릿 커널 및 호출자 계층을 사용하여 필요한 FP16 GEMM + Add + Add + FastGeLU 커널을 인스턴스화할 수 있습니다.
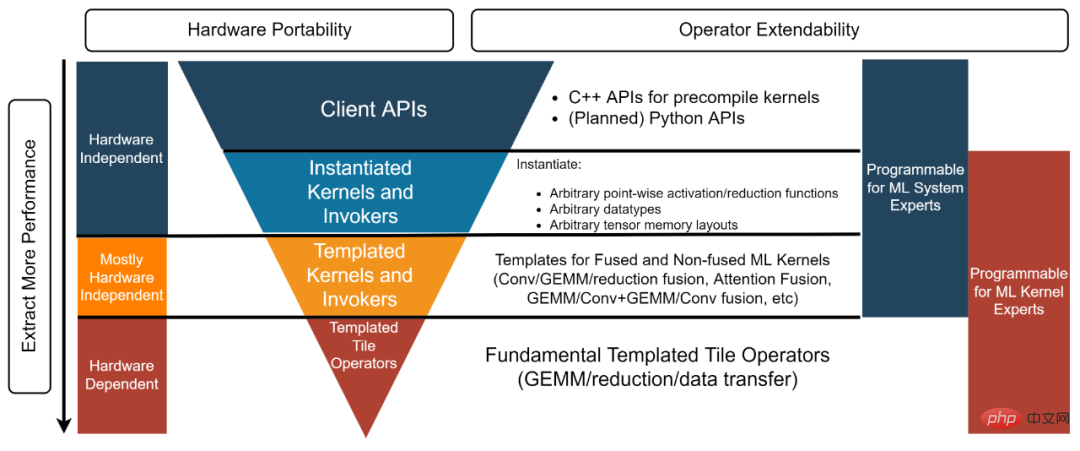
AITemplate + CK 기반의 엔드투엔드 모델 추론 Meta의 AITemplate[7](AIT)은 통합된 Nvidia GPU를 위한 AMD 및 AI 추론 시스템. AITemplate은 CK의 템플릿 커널 및 호출자 레이어를 사용하여 CK를 AMD GPU의 백엔드로 사용합니다.
AITemplate + CK는 AMD Instinct™ MI250의 여러 중요 AI 모델에서 최첨단 추론 성능을 달성합니다. CK에서 가장 진보된 융합 연산자의 정의는 AITemplate 팀의 비전에 의해 주도됩니다. 많은 융합 연산자 알고리즘도 CK 및 AITemplate 팀에서 공동으로 설계했습니다.이 기사에서는 AMD Instinct MI250 및 유사 제품[8]에서 여러 엔드투엔드 모델의 성능을 비교합니다. 이 기사에 나오는 AMD Instinct MI250 AI 모델의 모든 성능 데이터는 AITemplate[9] + CK[10]를 사용하여 얻은 것입니다. Experimentestinsnet-50
아래 이미지는 A100-PCIE-40GB 및 A100-DGX-80GB의 Tensorrt V8.5.0.12와 함께 AMD Instinct MI250의 AIT + CK를 보여줍니다. TRT) 성능 비교. 결과는 AMD Instinct MI250의 AIT + CK가 A100-PCIe-40GB의 TRT에 비해 1.08배 가속을 달성한다는 것을 보여줍니다.
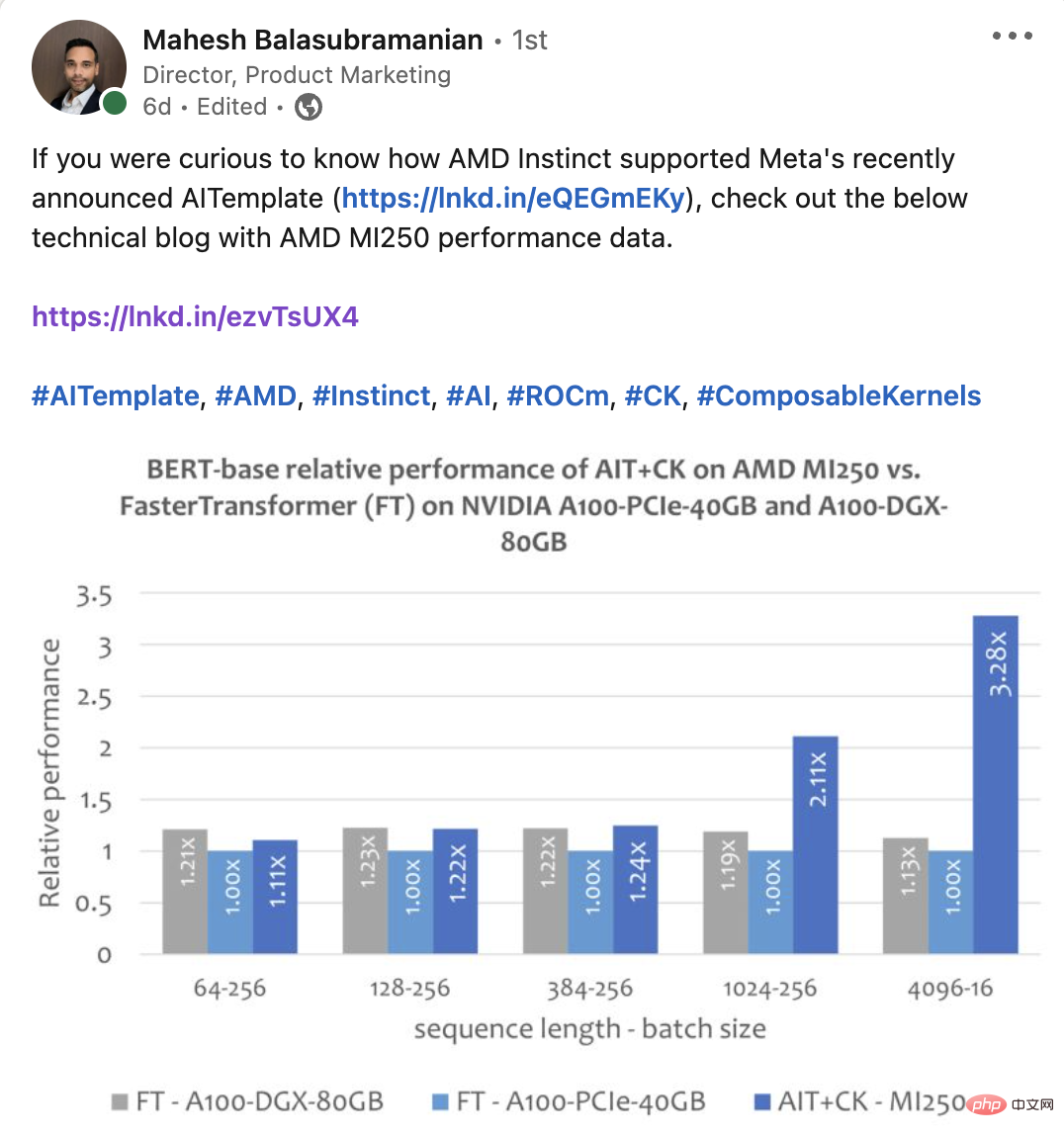
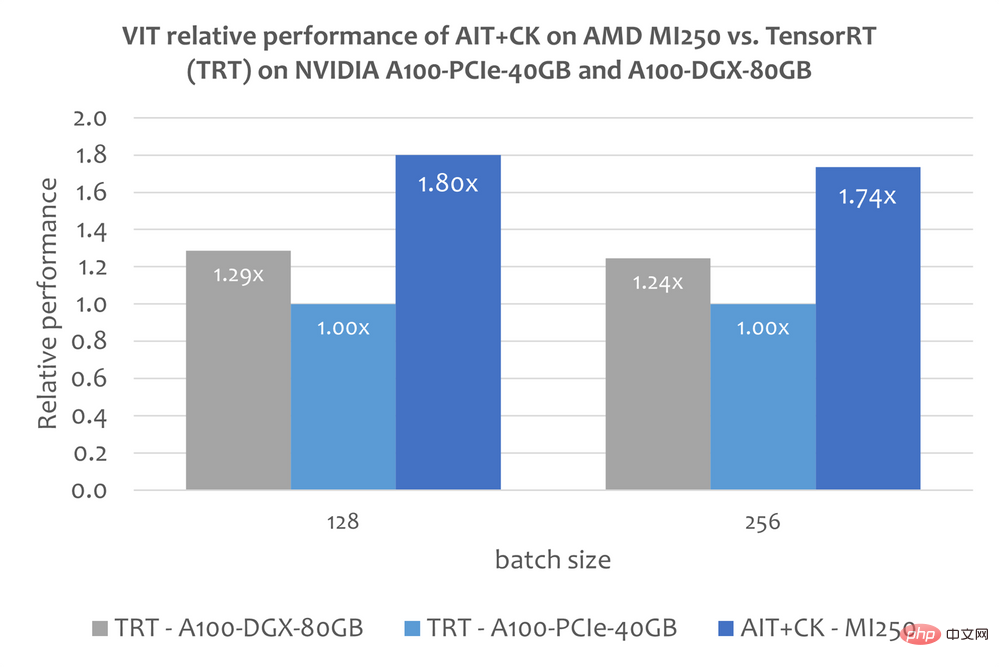
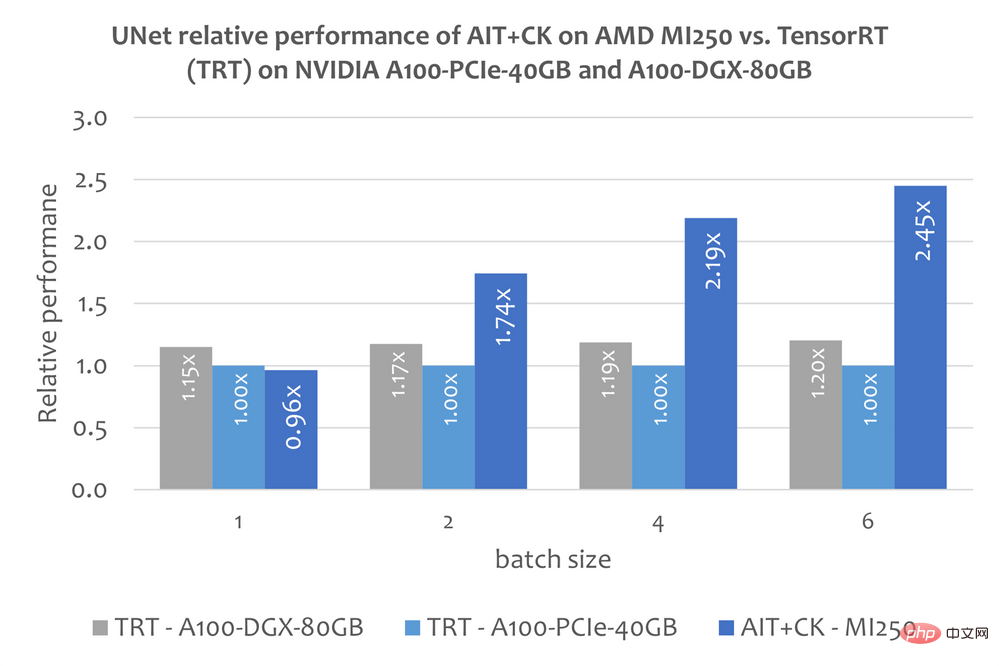
BERT CK를 기반으로 구현된 일괄 GEMM + Softmax + GEMM 융합 연산자 템플릿으로, GPU 컴퓨팅 유닛(컴퓨팅 유닛)과 HBM 간의 중간 결과 전송을 완전히 제거할 수 있습니다. 이 융합 연산자 템플릿을 사용하면 원래 대역폭에 묶여 있던 Attention 계층의 많은 문제가 컴퓨팅 병목 현상(컴퓨팅 바운드)이 되어 GPU의 컴퓨팅 성능을 더 잘 활용할 수 있습니다. 이 CK 구현은 FlashAttention[12]에서 깊은 영감을 받았으며 원래 FlashAttention 구현보다 더 많은 데이터 처리를 줄입니다. 아래 그림은 AMD Instinct MI250의 AIT + CK의 Bert Base 모델(케이스 없음)과 A100-PCIe-40GB 및 A100-DGX-80GB의 FasterTransformer v5.1.1 버그 수정[13](FT) 성능 비교를 보여줍니다. . FT는 시퀀스가 4096일 때 A100-PCIe-40GB 및 A100-DGX-80GB의 배치 32에서 GPU 메모리를 오버플로합니다. 따라서 Sequence가 4096인 경우 이 기사에서는 Batch 16의 결과만 표시합니다. 결과는 AMD Instinct MI250의 AIT + CK가 A100-PCIe-40GB의 FT에 비해 3.28배 FT 가속을 달성하고 A100-DGX-80GB에 비해 2.91x FT 속도 향상을 달성한 것으로 나타났습니다. Vision Transformer (VIT) 아래 이미지는 A100-PCIe-40GB 및 A100-DGX-80GB에서 TensorRT v8.5.0.12를 사용하는 AMD Instinct MI250의 AIT + CK를 보여줍니다. 성능 비교 (TRT)의 Vision Transformer Base(224x224 이미지). 결과에 따르면 AMD Instinct MI250의 AIT + CK는 A100-PCIe-40GB의 TRT에 비해 1.8배, A100-DGX-80GB의 TRT에 비해 1.4배의 속도 향상을 달성한 것으로 나타났습니다. stable stable 확산-엔드--엔드 안정 확산 UNet in Stable Diffusion 그러나 이 문서에는 TensorRT를 사용하여 Stable Diffusion 엔드투엔드 모델을 실행하는 방법에 대한 공개 정보가 없습니다. 그러나 "TensorRT를 사용하여 stable 확산을 25% 더 빠르게 만들기"[14] 기사에서는 TensorRT를 사용하여 Stable Diffusion에서 UNet 모델을 가속화하는 방법을 설명합니다. UNet은 Stable Diffusion에서 가장 중요하고 시간이 많이 소요되는 부분이므로 UNet의 성능은 Stable Diffusion의 성능을 대략적으로 반영합니다. 아래 그래프는 A100-PCIe-40GB 및 A100-DGX-80GB의 TensorRT v8.5.0.12(TRT)에서 UNet을 사용하는 AMD Instinct MI250에서 AIT + CK의 성능 비교를 보여줍니다. 결과에 따르면 AMD Instinct MI250의 AIT + CK는 A100-PCIe-40GB의 TRT에 비해 2.45배, A100-DGX-80GB의 TRT에 비해 2.03배의 속도 향상을 달성한 것으로 나타났습니다.
추가 정보 ROCm 웹페이지: AMD ROCm™ 개방형 소프트웨어 플랫폼 | AMD AMD Instinct Accel 이레이터: AMD Instinct™ Jing Zhang은 AMD의 SMTS 소프트웨어 개발 엔지니어입니다. 그들의 게시물은 자신의 의견이며 AMD의 입장, 전략 또는 의견을 나타내지 않을 수 있습니다. 제3자 사이트에 대한 링크는 편의를 위해 제공되며 명시적으로 명시하지 않는 한 AMD는 해당 내용에 대해 책임을 지지 않습니다. 그러한 링크된 사이트는 GD -5 을 암시하지 않습니다. 2.CK CPU용은 초기 개발 단계입니다. 3.C++ API는 현재 Python API는 계획 중입니다. 4.CK 예시 " GEMM + Add + Add + FastGeLU 융합 연산자용 클라이언트 API”입니다. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491... 5.GEMM의 CK "템플릿 커널 및 호출자" 예 + 추가 + 추가 + GeLU 퓨즈 연산자. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491... 6.GEMM 파이프라인을 작성하기 위해 CK "템플릿 타일 연산자" 프리미티브를 사용하는 예. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491... 7.Meta의 AITemplate GitHub 저장소. https://github.com/facebookincubator/AITemplate 8.MI200-71: 테스트는 AITemplate을 사용하여 AMD MLSE 10.23.22에서 수행되었습니다. https://github.com/ROCmSoftwarePlatform/AITemplate, 커밋 f940d9b) + 컴포저블 커널 https://github.com/ROCmSoftwarePlatform/composable_kernel, 커밋 40942b9), ROCm™5.3, 2x AMD EPYC 7713 64코어 프로세서 서버, 4x AMD Instinct MI250 OAM(128GB HBM2e) 560W GPU, AMD Infinity Fabric에서 실행 ™ 기술과 4x Nvidia A100-PCIe-40GB(250W) GPU 및 TensorRT v8을 갖춘 2x AMD EPYC 7742 64코어 프로세서 서버에서 실행되는 CUDA® 11.8을 사용하는 TensorRT v8.5.0.12 및 FasterTransformer(v5.1.1 버그 수정). 8x NVIDIA A100 SXM 80GB(400W) GPU가 탑재된 2xAMD EPYC 7742 64코어 프로세서 서버에서 실행되는 CUDA® 11.8이 포함된 5.0.12 및 FasterTransformer(v5.1.1 버그 수정). 서버 제조업체는 구성을 다양하게 하여 다른 결과를 낳을 수 있습니다. 성능은 최신 드라이버 사용 및 최적화 등의 요인에 따라 달라질 수 있습니다. 9.https://github.com/ROCmSoftwarePlatform/AITemplate/tree/f940d9b7ac8b976fba127e2c269dc5b368f30e4e 10.https://github.com/ROCmSoftwarePlatform/composable_kernel/tree/40942b909801dd721769834fc61ad201b5795 ... 11.TensorRT GitHub 저장소. https://github.com/NVIDIA/TensorRT 12.FlashAttention: IO 인식을 통한 빠르고 메모리 효율적인 정확한 주의. https://arxiv.org/abs/2205.14135 13.FasterTransformer GitHub 저장소. https://github.com/NVIDIA/FasterTransformer 14.TensorRT를 사용하여 안정적인 확산을 25% 더 빠르게 만듭니다. https://www.photoroom.com/tech/stable-diffusion-25-percent-faster-and-save-seconds/ 15.AMD에 있는 동안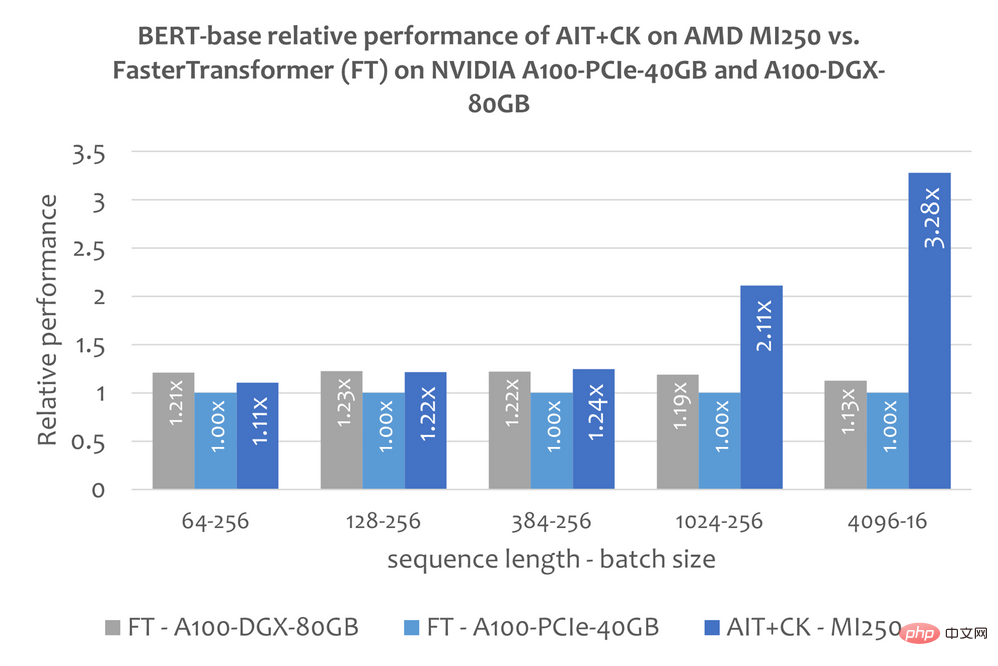
 다음 표는 AMD Instinct MI250에서 AIT + CK 안정적인 확산 엔드 투 엔드를 보여줍니다 (배치 1, 2, 4, 6) 성능 데이터. Batch가 1인 경우 MI250에서는 하나의 GCD만 사용되는 반면, Batch 2, 4, 6에서는 두 GCD가 모두 사용됩니다.
다음 표는 AMD Instinct MI250에서 AIT + CK 안정적인 확산 엔드 투 엔드를 보여줍니다 (배치 1, 2, 4, 6) 성능 데이터. Batch가 1인 경우 MI250에서는 하나의 GCD만 사용되는 반면, Batch 2, 4, 6에서는 두 GCD가 모두 사용됩니다. 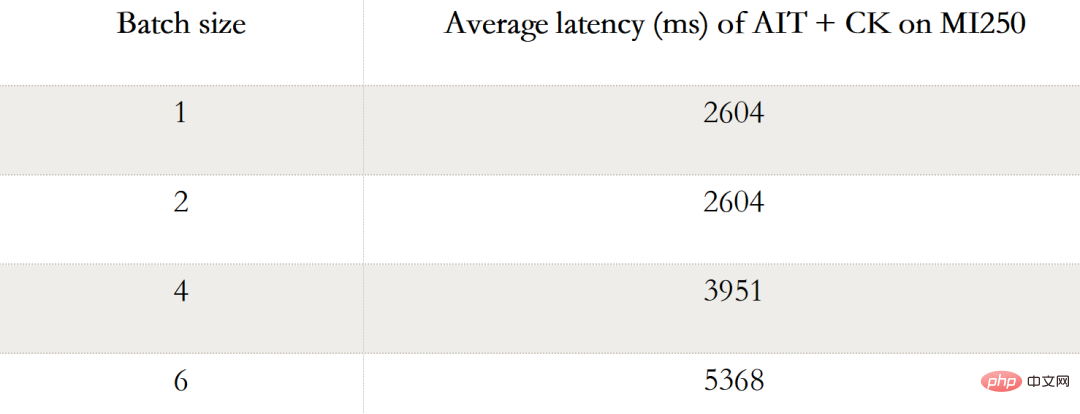
 ROCm 정보 포털: AMD 문서 - 포털
ROCm 정보 포털: AMD 문서 - 포털
위 내용은 맞춤형 운영자 융합을 통해 AI End-to-End 성능 향상의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



