

최근 LMSYS Org(UC Berkeley 주도) 연구원들이 또 하나의 빅뉴스를 내놨습니다. 바로 대규모 언어 모델 버전 순위 경쟁이죠!
이름에서 알 수 있듯이 "LLM 랭킹"은 대규모 언어 모델 그룹이 무작위로 전투를 진행하고 Elo 점수에 따라 순위를 매기는 것입니다.
그러면 특정 챗봇이 '입이 가장 강한 왕'인지 '최강의 왕'인지 한눈에 알 수 있습니다.
핵심 포인트: 팀은 또한 국내외의 모든 "비공개 소스" 모델을 가져올 계획입니다. 노새인지 말인지 알 수 있습니다! (GPT-3.5는 현재 이미 익명 영역에 있습니다.)

익명 챗봇 영역은 다음과 같습니다.
분명히 모델 B가 정답을 맞췄고 모델 A는 승리하지 못했습니다. 질문까지 이해해...
프로젝트 주소: https://arena.lmsys.org/
현재 순위에서는 130억 개의 매개변수를 가진 비쿠나(Vicuna)가 1169로 1위를 차지했습니다. 2위는 역시 130억 개의 매개변수를 보유한 코알라, 3위는 라이온의 오픈어시스턴트(Open Assistant)다.
칭화대학교가 제안한 ChatGLM은 60억 개의 매개변수만 가지고 있지만 여전히 상위 5위 안에 들었고, 130억 개의 매개변수를 가진 Alpaca보다 23포인트 뒤진 것입니다.
이에 비해 Meta의 원본 LLaMa는 8위(마지막에서 두 번째)에 불과한 반면 Stability AI의 StableLM은 800점 이상을 받아 마지막부터 1위를 차지했습니다.
팀에서는 정기적으로 순위 목록을 업데이트할 뿐만 아니라 알고리즘과 메커니즘을 최적화하고 다양한 작업 유형을 기반으로 보다 자세한 순위를 제공할 것이라고 밝혔습니다.

현재 모든 평가 코드와 데이터 분석이 공개되었습니다.
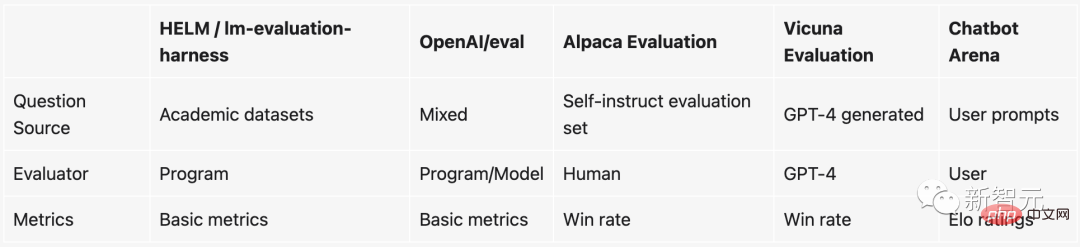
이번 평가에서 팀은 잘 알려진 오픈소스 챗봇 9개를 선정했습니다.
1v1 전투가 진행될 때마다 시스템에서 무작위로 두 명의 PK 플레이어를 선택합니다. 사용자는 두 로봇과 동시에 채팅한 후 어느 챗봇이 더 나은지 결정해야 합니다.
페이지 하단에 4가지 옵션이 있는 것을 볼 수 있습니다. 왼쪽(A)이 더 좋음, 오른쪽(B)이 더 좋음, 동등하게 좋음 또는 둘 다 나쁨.
사용자가 투표를 제출하면 시스템에 모델 이름이 표시됩니다. 이때 사용자는 채팅을 계속하거나 새로운 모델을 선택하여 전투를 다시 시작할 수 있습니다.
단, 분석 시 모델이 익명인 경우에만 투표 결과를 사용합니다. 거의 일주일 간의 데이터 수집 끝에 팀은 총 4.7,000개의 유효한 익명 투표를 수집했습니다.
팀은 시작에 앞서 먼저 벤치마크 테스트 결과를 바탕으로 각 모델의 가능한 순위를 파악했습니다.
이 순위를 바탕으로 팀은 모델이 더 적합한 상대를 우선적으로 선택하도록 할 것입니다.
그런 다음 균일한 샘플링을 통해 순위의 전체 적용 범위를 더 높이세요.
예선이 끝나고 팀은 새로운 모델인 fastchat-t5-3b를 선보였습니다.
위 작업은 결국 불균일한 모델 주파수로 이어집니다.
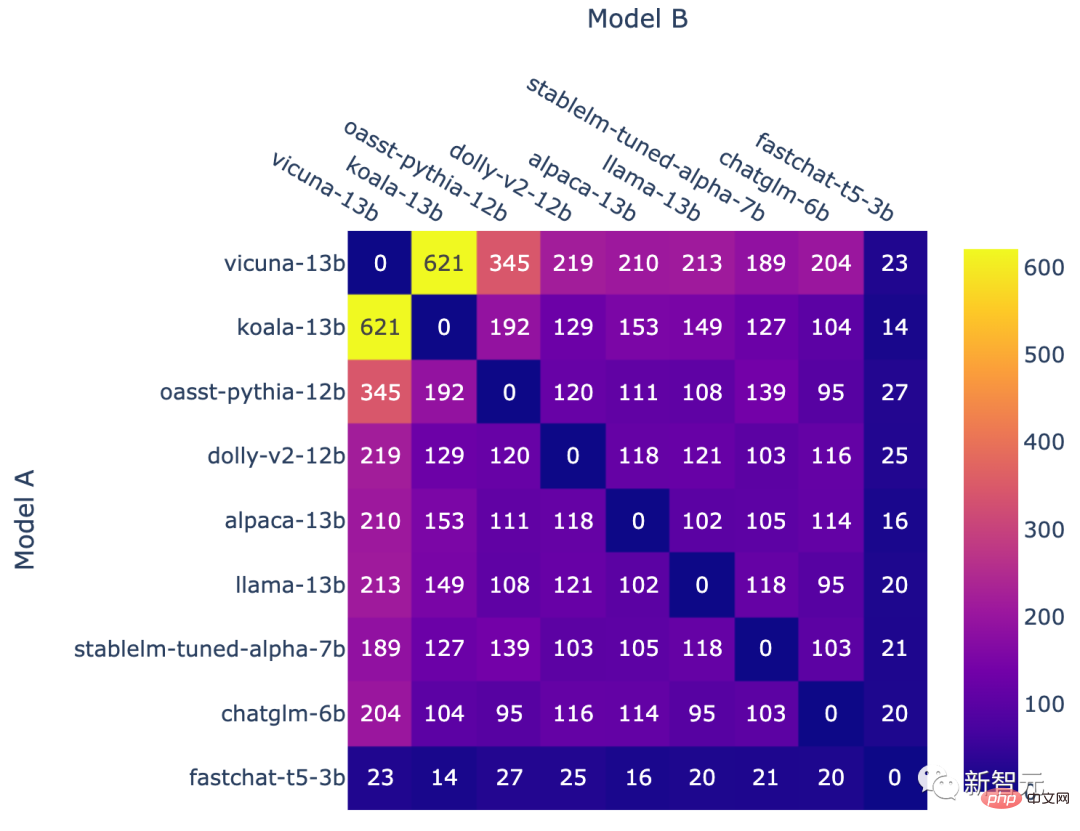
모델 조합별 전투 횟수
통계에 따르면 대부분의 사용자는 영어를 사용하며 중국어가 2위입니다.
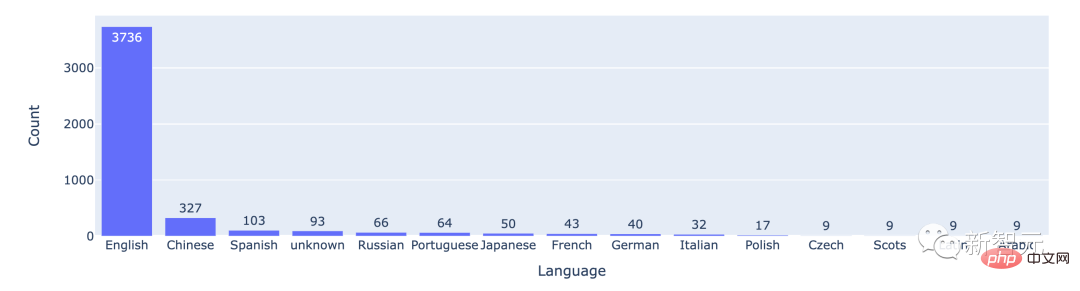
상위 15개 언어 간의 전투 횟수
ChatGPT의 인기 이후, 비가 내린 후 버섯처럼 지침이 나타났습니다. 거의 매주 새로운 오픈소스 LLM이 출시된다고 할 수 있습니다.
하지만 문제는 이러한 대규모 언어 모델을 평가하는 것이 매우 어렵다는 것입니다.
구체적으로 말하면 현재 모델의 품질을 측정하는 데 사용되는 것들은 기본적으로 특정 NLP 작업에 대한 테스트 데이터 세트를 구축한 후 테스트 데이터의 정확도를 확인하는 등 일부 학문적 벤치마크를 기반으로 합니다. 세트. .
그러나 이러한 학술적 벤치마크(예: HELM)는 대형 모델 및 챗봇에서 사용하기 쉽지 않습니다. 그 이유는 다음과 같습니다.
1. 챗봇이 좋은지 아닌지를 판단하는 것은 매우 주관적이므로 기존 방법으로는 측정하기 어렵습니다.
2. 이러한 대형 모델은 훈련 중에 인터넷에 있는 거의 모든 데이터를 스캔하므로 테스트 데이터 세트가 표시되지 않았는지 확인하기가 어렵습니다. 한 단계 더 나아가 테스트 세트를 사용하여 모델을 직접 "특별히 훈련"하면 성능이 향상됩니다.
3. 이론상으로는 무엇이든 챗봇과 대화할 수 있지만 기존 벤치마크에는 많은 주제나 작업이 존재하지 않습니다.
이 벤치마크를 사용하고 싶지 않다면 실제로 다른 방법이 있습니다. 누군가에게 비용을 지불하여 모델 점수를 매기는 것입니다.
사실 이것이 OpenAI가 하는 일입니다. 하지만 이 방법은 분명히 매우 느리고, 더 중요하게는 비용이 너무 많이 듭니다...
이 까다로운 문제를 해결하기 위해 UC Berkeley, UCSD 및 CMU 팀은 재미 있고 실용적인 새로운 메커니즘을 발명했습니다. — — 챗봇 아레나.
이에 비해 전투 기반 벤치마크 시스템은 다음과 같은 장점이 있습니다.
모든 잠재적 모델 쌍에 대해 충분한 데이터를 수집할 수 없는 경우 시스템을 최대한 많이 확장할 수 있습니다. 가능한 모델.
시스템은 상대적으로 적은 수의 시도를 사용하여 새 모델을 평가할 수 있어야 합니다.
시스템은 모든 모델에 고유한 주문을 제공해야 합니다. 두 모델이 주어지면 어느 모델의 순위가 더 높은지, 아니면 동률인지 알 수 있어야 합니다.
Elo 등급 시스템은 플레이어의 상대적인 기술 수준을 계산하는 방법으로 경쟁 게임 및 다양한 스포츠에서 널리 사용됩니다. 그 중 Elo 점수가 높을수록 플레이어가 더 강력해집니다.
예를 들어 League of Legends, Dota 2, Chicken Fighting 등에서는 이것이 시스템이 플레이어 순위를 매기는 메커니즘입니다.
예를 들어 리그 오브 레전드에서 순위 게임을 많이 플레이하면 숨겨진 점수가 나타납니다. 이 숨겨진 점수는 당신의 순위를 결정할 뿐만 아니라, 순위 게임을 할 때 만나는 상대가 기본적으로 비슷한 수준인지 결정합니다.
게다가 이 엘로 점수의 가치는 절대적입니다. 즉, 향후 새로운 챗봇이 추가되더라도 Elo의 점수를 통해 어떤 챗봇이 더 강력한지 직접적으로 판단할 수 있다는 것입니다.
구체적으로 플레이어 A의 등급이 Ra이고 플레이어 B의 등급이 Rb인 경우 플레이어 A의 승리 확률에 대한 정확한 공식(기본 10 로지스틱 곡선 사용)은 다음과 같습니다. 각 경기가 끝난 후 선형적으로 업데이트됩니다.
플레이어 A(Ra 등급)가 Ea 포인트를 받을 것으로 예상했지만 실제로는 Sa 포인트를 받았다고 가정해 보세요. 이 플레이어 등급을 업데이트하는 공식은 다음과 같습니다. 
1v1 승률
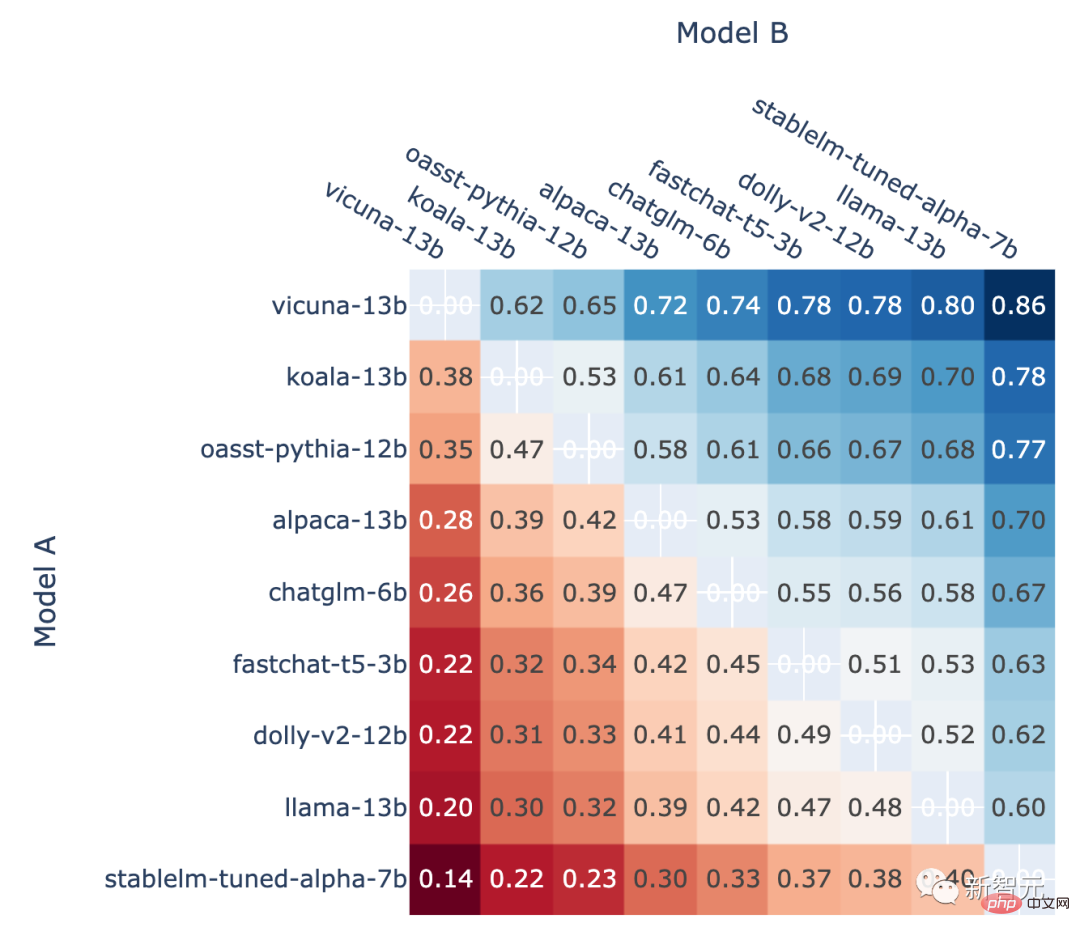
또한 저자는 순위 게임에서 각 모델의 정면 승률과 예상 정면 승률도 보여줍니다. Elo 등급을 사용하여 추정된 맞대결 승률입니다.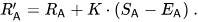
모든 비동점 A에서 모델 A가 승리하는 비율 대 B와의 전투에서 모델 A의 승률 엘로 점수를 활용한 예측
저자 소개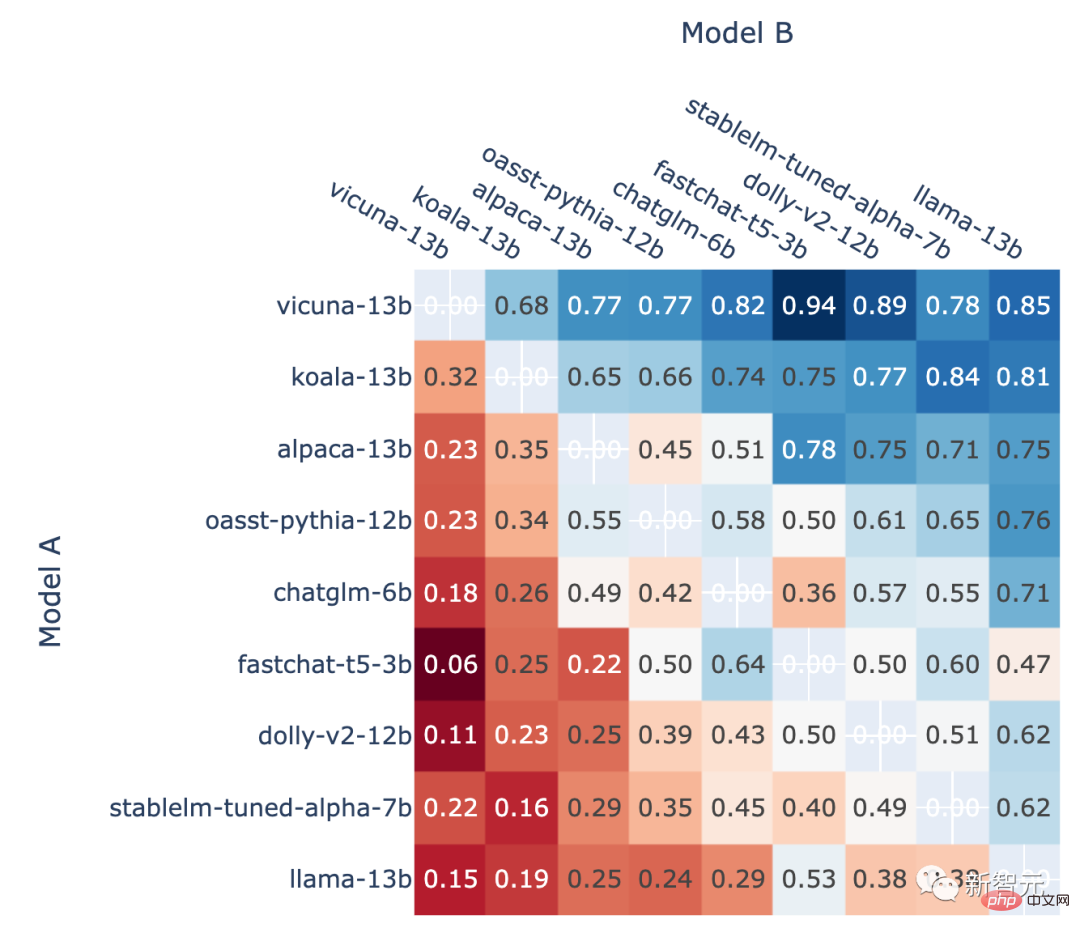
"챗봇 아레나"는 전 리틀 알파카 작가 단체인 LMSYS Org에서 출시되었습니다. 이 조직은 UC Berkeley Ph.D. Lianmin Zheng과 UCSD 부교수 Hao Zhang이 공동으로 개방형 데이터 세트, 모델, 시스템 및 평가 도구를 개발하여 모든 사람이 액세스할 수 있는 대규모 모델을 만드는 것을 목표로 설립되었습니다.
Lianmin Zheng
Hao Zhang
Hao Zhang은 현재 University of California, Berkeley에서 박사후 연구원으로 재직하고 있습니다. 그는 2023년 가을부터 UC San Diego Halıcıoğlu 데이터 과학 연구소 및 컴퓨터 과학부에서 조교수로 재직할 예정입니다.
위 내용은 UC Berkeley에서 대형 언어 모델 순위를 공개합니다! Vicuna가 우승을 차지했으며 Tsinghua ChatGLM이 상위 5위 안에 들었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



