

많은 학자들의 견해에 따르면 구체화된 지능은 AGI에 대한 매우 유망한 방향이며, ChatGPT의 성공은 강화 학습을 기반으로 하는 RLHF 기술과 불가분의 관계입니다. DeepMind vs. OpenAI, 누가 먼저 AGI를 달성할 수 있을까? 그 답은 아직 밝혀지지 않은 것 같습니다.
우리는 일반적인 구체화된 지능(즉, 물리적 세계에서 민첩하고 능숙하게 행동하고 동물이나 인간처럼 이해하는 에이전트)을 만드는 것이 AI 연구자와 로봇공학자의 장기 목표 중 하나라는 것을 알고 있습니다. 시간적으로 볼 때, 복잡한 이동 기능을 갖춘 지능형 구체화 에이전트의 생성은 시뮬레이션과 현실 세계 모두에서 수년 전으로 거슬러 올라갑니다.
학습 기반 방법이 중요한 역할을 하면서 최근 몇 년간 발전 속도가 크게 빨라졌습니다. 예를 들어, 심층 강화 학습은 복잡한 인식 기반 전신 제어 또는 다중 에이전트 동작을 포함하여 시뮬레이션된 캐릭터의 복잡한 동작 제어 문제를 해결할 수 있는 것으로 나타났습니다. 동시에 물리적 로봇에서 심층 강화 학습의 사용이 점점 더 늘어나고 있습니다. 특히 널리 사용되는 고품질 4족 보행 로봇은 다양한 강력한 운동 동작을 생성하는 방법을 학습하기 위한 시연 대상이 되었습니다.
그러나 정적 환경에서의 움직임은 동물과 인간이 세계와 상호 작용하기 위해 몸을 배치하는 다양한 방법 중 일부일 뿐이며, 특히 전신 제어 및 운동 조작을 연구하는 많은 연구에서 검증되었습니다. 네 발 달린 로봇. 관련 동작의 예로는 클라이밍, 드리블이나 공 잡기와 같은 축구 기술, 다리를 사용한 간단한 동작 등이 있습니다.
축구의 경우 인간의 감각운동 지능의 많은 특성을 보여줍니다. 축구의 복잡성으로 인해 달리기, 회전, 회피, 발로 차기, 패스, 넘어지기, 일어서기 등 매우 민첩하고 역동적인 다양한 움직임이 필요합니다. 이러한 조치는 다양한 방식으로 결합되어야 합니다. 플레이어는 공, 팀원, 상대 선수를 예측하고 게임 환경에 따라 행동을 조정해야 합니다. 이러한 다양한 도전 과제는 로봇 공학 및 AI 커뮤니티에서 인식되어 RoboCup이 탄생했습니다.
그러나 축구를 잘하는 데 필요한 민첩성, 유연성 및 빠른 반응과 이러한 요소 간의 원활한 전환은 수동 로봇 설계에 매우 어렵고 시간이 많이 걸린다는 점에 유의해야 합니다. 최근 DeepMind(현재 Google Brain 팀과 합병되어 Google DeepMind가 됨)의 새 논문에서는 심층 강화 학습을 사용하여 이족보행 로봇의 민첩한 축구 기술을 학습하는 방법을 탐구합니다.

논문 주소: https://arxiv.org/pdf/2304.13653.pdf
프로젝트 홈페이지: https://sites.google.com/view/op3 -soccer
본 논문에서 연구자들은 동적 다중 에이전트 환경에서 소형 휴머노이드 로봇의 전신 제어 및 객체 상호 작용을 연구합니다. 그들은 전체 축구 문제의 하위 집합을 고려하여 20개의 제어 가능한 관절을 갖춘 저가형 마이크로 휴머노이드 로봇을 훈련시켜 1대1 축구 경기를 하고 고유 감각 및 게임 상태 특성을 관찰했습니다. 내장된 컨트롤러로 로봇은 느리고 어색하게 움직입니다. 그러나 연구자들은 심층 강화 학습을 사용하여 에이전트가 자연스럽고 부드러운 방식으로 결합한 역동적이고 민첩한 상황 적응형 운동 기술(예: 걷기, 달리기, 회전, 공 차기 및 넘어진 후 다시 일어나기)을 복잡한 장기로 합성했습니다. -기간 행동.
실험에서 에이전트는 공의 움직임을 예측하고, 위치를 지정하고, 공격을 차단하고, 리바운드 볼을 사용하는 방법을 학습했습니다. 에이전트는 기술 재사용, 엔드 투 엔드 교육 및 간단한 보상의 조합 덕분에 다중 에이전트 환경에서 이러한 행동을 달성합니다. 연구원들은 시뮬레이션을 통해 에이전트를 교육하고 이를 물리적 로봇으로 전송하여 저가형 로봇에서도 시뮬레이션에서 실제 전송이 가능함을 입증했습니다.
데이터로 말해보세요. 로봇의 걷는 속도는 기준선에 비해 156% 증가하고, 일어나는 시간은 63% 감소했으며, 공을 차는 속도도 24% 증가했습니다.
기술적인 해석에 앞서 1대1 축구 경기에서 로봇의 하이라이트 중 일부를 살펴보겠습니다. 예를 들어 촬영:


페널티킥:

턴, 드리블, 킥을 모두 한 번에

블록:

로봇이 축구를 배우도록 하려면 먼저 몇 가지 기본 설정이 필요합니다.
환경 측면에서 DeepMind는 먼저 맞춤형 축구 환경에서 에이전트를 시뮬레이션하고 훈련한 다음 그림 1과 같이 전략을 해당 실제 환경으로 마이그레이션합니다. 환경은 길이 5m, 너비 4m의 축구장으로 구성되었으며, 각각의 개구부 폭은 0.8m인 두 개의 골이 있었습니다. 시뮬레이션 환경과 실제 환경 모두에서 코트는 경사로로 둘러싸여 공을 경계 내에 유지합니다. 실제 코트는 고무 타일로 덮여 있어 낙하로 인한 로봇 손상 위험을 줄이고 바닥과의 마찰을 증가시킵니다.
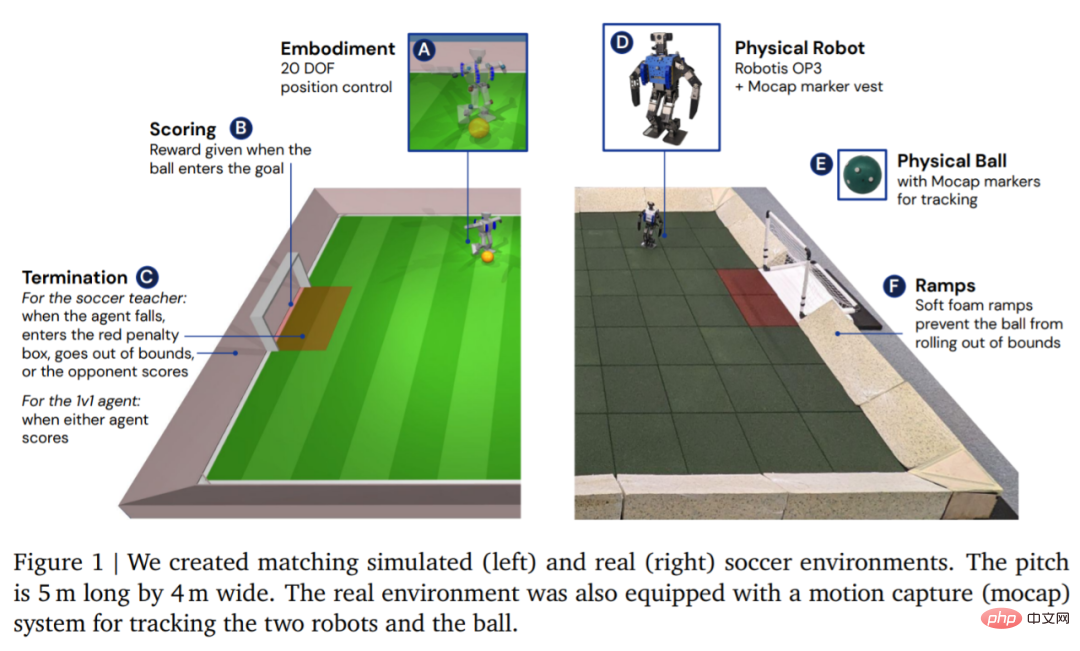
환경이 설정되면 다음 단계는 하드웨어와 모션 캡처를 설정하는 것입니다. DeepMind는 높이 51cm, 무게 3.5kg이며 20개의 서보 모터로 구동되는 Robotis OP3 로봇을 사용합니다. 로봇에는 GPU나 기타 전용 가속기가 없으므로 모든 신경망 계산은 CPU에서 실행됩니다. 로봇의 머리 부분에는 초당 30프레임의 RGB 비디오 스트림을 선택적으로 제공할 수 있는 Logitech C920 웹캠이 있습니다.

DeepMind의 목표는 걷고, 공을 차고, 일어나고, 방어하고, 득점하는 방법을 알고 이러한 기능을 실제 로봇에 전달할 수 있는 에이전트를 훈련시키는 것입니다. DeepMind는 그림 3과 같이 훈련을 두 단계로 나눕니다.
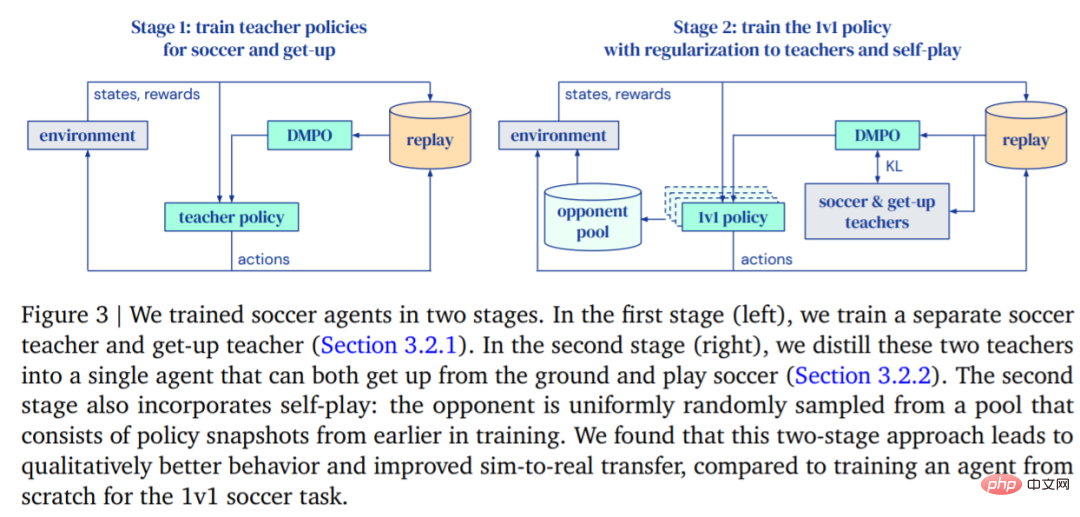
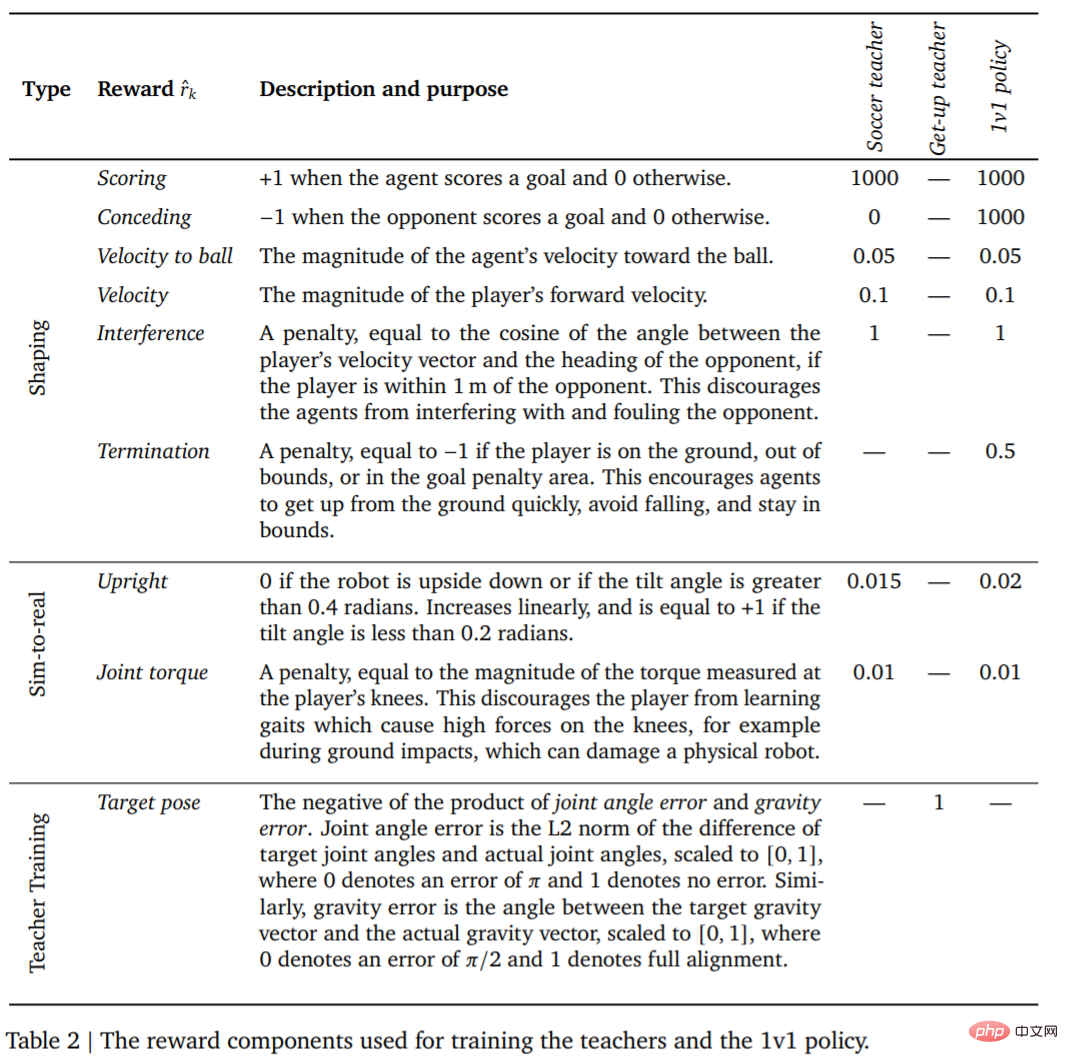
먼저 교사 연수입니다. 교사는 가능한 한 많은 목표 득점 훈련을 받아야 합니다. 이 라운드(에피소드)는 에이전트가 넘어지거나, 경계를 벗어나거나, 제한 구역(그림 1에서 빨간색으로 표시)에 들어가거나, 상대가 득점할 때 종료됩니다. 각 라운드가 시작될 때 에이전트, 상대방, 공은 코트에서 임의의 위치와 방향으로 초기화됩니다. 양측 모두 기본 스탠스로 초기화됩니다. 공격자는 훈련되지 않은 정책으로 초기화되므로 에이전트는 이 단계에서 공격자를 피하는 방법을 배우지만 더 이상 복잡한 상호 작용은 발생하지 않습니다. 또한 각 훈련 단계에 따른 보상과 그 가중치는 표 2와 같다.
에이전트는 교사의 정책에 따라 행동을 규제하면서 점점 더 강력해지는 상대와 경쟁합니다. 이러한 방식으로 에이전트는 걷기, 발차기, 일어나기, 득점 및 수비 등 일련의 축구 기술을 익힐 수 있습니다. 에이전트가 경계를 벗어나거나 골 박스 안에 있으면 각 시간 단계에서 고정된 페널티를 받습니다.
지능 에이전트가 훈련된 후 다음 단계는 훈련된 발차기 전략을 샘플 없이 실제 로봇에 전달하는 것입니다. Zero-shot 전송 성공률을 높이기 위해 DeepMind는 간단한 시스템 식별을 통해 시뮬레이션된 에이전트와 실제 로봇 간의 격차를 줄이고, 훈련 중 도메인 무작위화 및 섭동을 통해 전략의 견고성을 향상시키며, 보상 전략을 형성하는 것을 포함합니다. 로봇에 해를 끼칠 가능성이 너무 높은 행동.
1v1 경쟁: 축구 에이전트는 땅에서 일어나기, 넘어졌을 때 빠르게 회복하기, 달리기, 회전하기 등 유연한 운동 기술을 포함하여 다양한 응급 행동을 처리할 수 있습니다. 게임 중에 에이전트는 이러한 모든 기술 사이를 유동적으로 전환합니다.

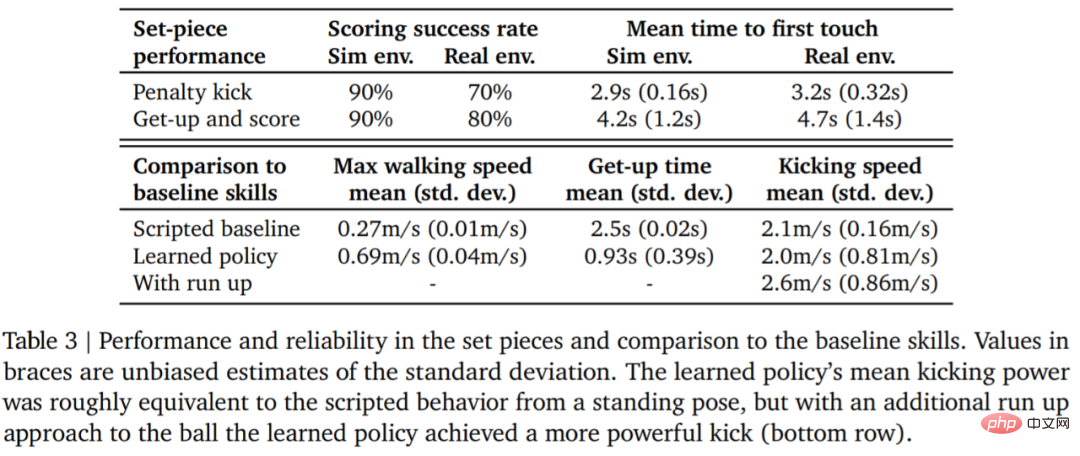
정량분석 결과는 아래 표 3과 같습니다. 강화 학습 전략은 에이전트가 156% 더 빠르게 걷고, 일어나는 데 63% 더 적은 시간이 걸리는 등 인위적으로 설계된 전문 기술보다 더 나은 성능을 발휘한다는 것을 결과에서 볼 수 있습니다.
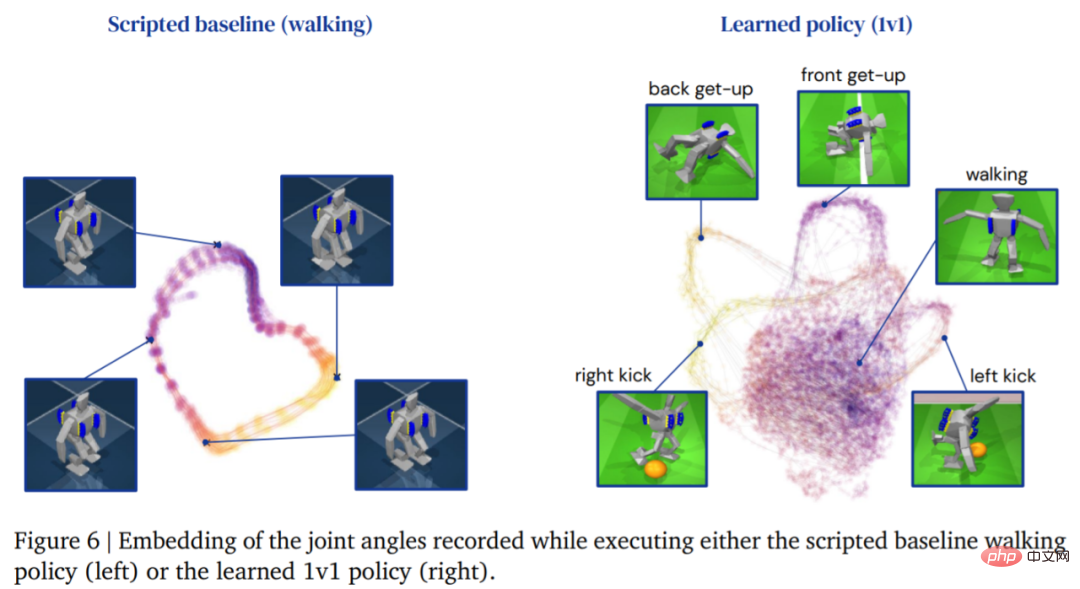
아래 그림은 에이전트의 걷기 궤적을 보여줍니다. 이에 비해 학습 전략에 의해 생성된 에이전트의 궤적 구조는 더 풍부합니다.
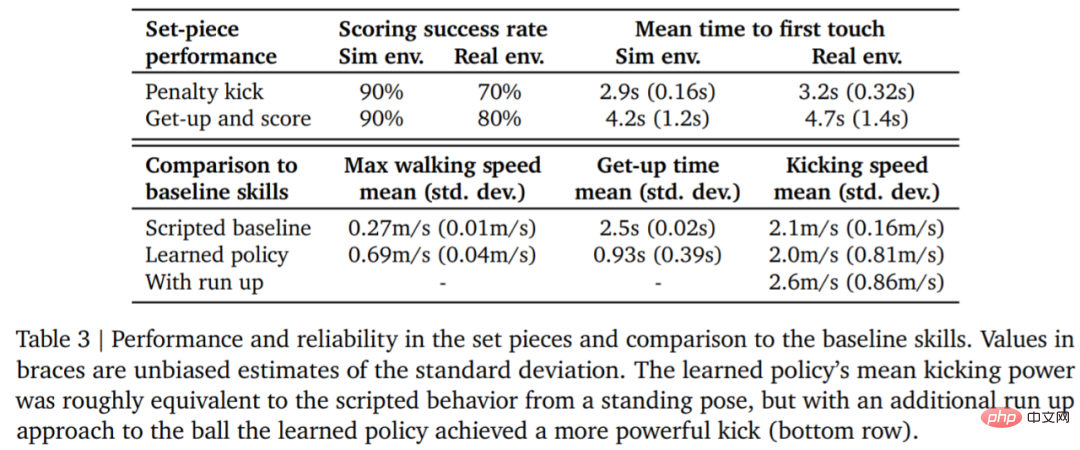
학습 전략의 신뢰성 DeepMind는 페널티킥과 점프슛 세트피스를 설계하고 이를 시뮬레이션 및 실제 환경에 구현했습니다. 초기 구성은 그림 7에 나와 있습니다.
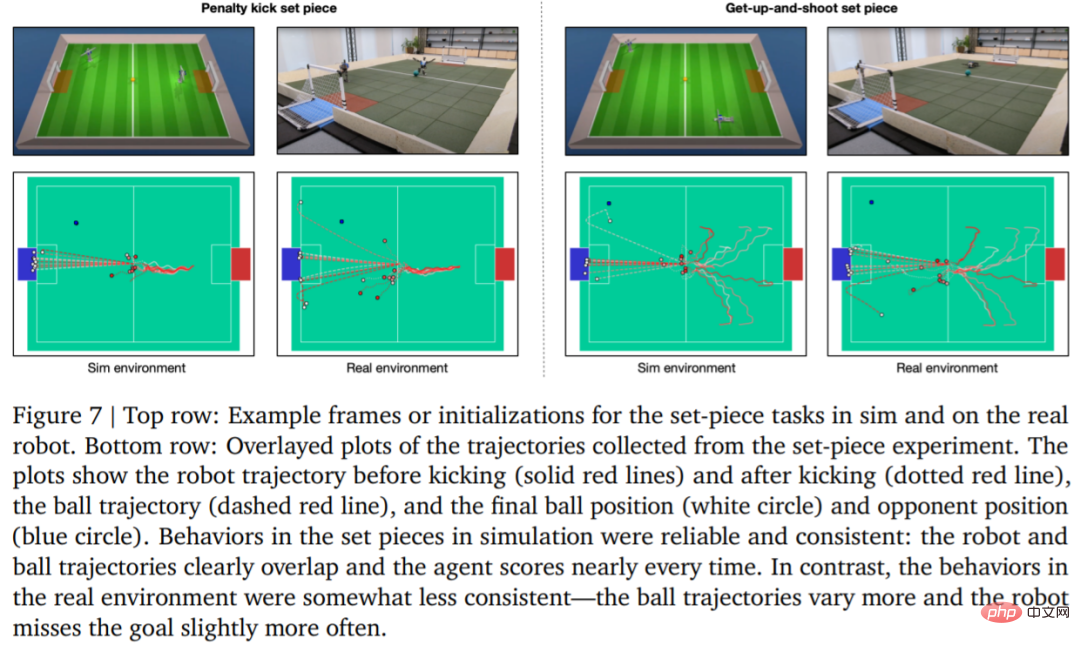
실제 환경에서 로봇은 페널티 킥 작업에서 10번 중 7번(70%), 발사 작업에서 10번 중 8번(80%)을 성공했습니다. 시뮬레이션 실험에서는 이 두 가지 작업에서 에이전트의 점수가 더 일관되게 나타났는데, 이는 에이전트의 훈련 전략이 실제 환경(실제 로봇, 공, 바닥 표면 등 포함)으로 이전되어 성능이 약간 저하되고, 행동 차이가 증가했지만 로봇은 여전히 안정적으로 일어나 공을 차고 득점할 수 있습니다. 결과를 도 7 및 표 3에 나타내었다.
위 내용은 DeepMind가 GPT 축제에 참석하지 않는 이유는 무엇입니까? 알고 보니 저는 작은 로봇에게 축구를 가르치고 있었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



