

1.jieba라이브러리를 가져오고 텍스트를 정의합니다jieba库并定义文本
import jieba text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"
2.对文本进行分词
words = jieba.cut(text)
这一步会将文本分成若干个词语,并返回一个生成器对象words,可以使用for循环遍历所有的词语。
3. 统计词频
word_count = {} for word in words: if len(word) > 1: word_count[word] = word_count.get(word, 0) + 1
这一步通过遍历所有的词语,统计每个词语出现的次数,并保存到一个字典word_count中。在统计词频时,可以通过去除停用词等方式进行优化,这里只是简单地过滤了长度小于2的词语。
4. 结果输出
for word, count in word_count.items(): print(word, count)

为了更准确地统计词频,我们可以在词频统计中加入停用词,以去除一些常见但无实际意义的词语。具体步骤如下:
定义停用词列表
import jieba # 停用词列表 stopwords = ['是', '一种', '等']
对文本进行分词,并过滤停用词
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。" words = jieba.cut(text) words_filtered = [word for word in words if word not in stopwords and len(word) > 1]
统计词频并输出结果
word_count = {} for word in words_filtered: word_count[word] = word_count.get(word, 0) + 1 for word, count in word_count.items(): print(word, count)
加入停用词后,输出的结果是:

可以看到,被停用的一种这个词并没有显示出来。
与对词语进行单纯计数的词频统计不同,jieba提取关键字的原理是基于TF-IDF(Term Frequency-Inverse Document Frequency)算法。TF-IDF算法是一种常用的文本特征提取方法,可以衡量一个词语在文本中的重要程度。
具体来说,TF-IDF算法包含两个部分:
Term Frequency(词频):指一个词在文本中出现的次数,通常用一个简单的统计值表示,例如词频、二元词频等。词频反映了一个词在文本中的重要程度,但是忽略了这个词在整个语料库中的普遍程度。
Inverse Document Frequency(逆文档频率):指一个词在所有文档中出现的频率的倒数,用于衡量一个词的普遍程度。逆文档频率越大,表示一个词越普遍,重要程度越低;逆文档频率越小,表示一个词越独特,重要程度越高。
TF-IDF算法通过综合考虑词频和逆文档频率,计算出每个词在文本中的重要程度,从而提取关键字。在jieba中,关键字提取的具体实现包括以下步骤:
对文本进行分词,得到分词结果。
统计每个词在文本中出现的次数,计算出词频。
统计每个词在所有文档中出现的次数,计算出逆文档频率。
综合考虑词频和逆文档频率,计算出每个词在文本中的TF-IDF值。
对TF-IDF值进行排序,选取得分最高的若干个词作为关键字。
举个例子:
F(Term Frequency)指的是某个单词在一篇文档中出现的频率。计算公式如下:
T F = ( 单词在文档中出现的次数 ) / ( 文档中的总单词数 )
例如,在一篇包含100个单词的文档中,某个单词出现了10次,则该单词的TF为
10 / 100 = 0.1
IDF(Inverse Document Frequency)指的是在文档集合中出现某个单词的文档数的倒数。计算公式如下:
I D F = l o g ( 文档集合中的文档总数 / 包含该单词的文档数 )
例如,在一个包含1000篇文档的文档集合中,某个单词在100篇文档中出现过,则该单词的IDF为 l o g ( 1000 / 100 ) = 1.0
TFIDF是将TF和IDF相乘得到的结果,计算公式如下:
T F I D F = T F ∗ I D F
需要注意的是,TF-IDF算法只考虑了词语在文本中的出现情况,而忽略了词语之间的关联性。因此,在一些特定的应用场景中,需要使用其他的文本特征提取方法,例如词向量、主题模型等。
import jieba.analyse # 待提取关键字的文本 text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。" # 使用jieba提取关键字 keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=True) # 输出关键字和对应的权重 for keyword, weight in keywords: print(keyword, weight)
在这个示例中,我们首先导入了jieba.analyse模块,然后定义了一个待提取关键字的文本text。接着,我们使用jieba.analyse.extract_tags()函数提取关键字,其中topK参数表示需要提取的关键字个数,withWeightrrreee
2. 텍스트를 분할합니다
이 단계에서는 텍스트를 여러 개로 나눕니다. 단어 및for를 사용하여 모든 단어를 반복하는 데 사용할 수 있는 생성기 개체words를 반환합니다.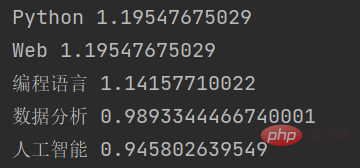
word_count에 저장하는 것입니다. 단어 빈도를 계산할 때 중지 단어를 제거하여 최적화를 수행할 수 있습니다. 여기서 길이가 2 미만인 단어는 간단히 필터링됩니다. 4. 결과 출력rrreee
1.2 중지 단어 추가단어 빈도를 더 정확하게 계산하기 위해 단어 빈도 통계에 중지 단어를 추가하여 일반적이지만 의미 없는 단어를 제거할 수 있습니다. 구체적인 단계는 다음과 같습니다. 불용어 목록 정의 rrreee 텍스트 분할 및 불용어 필터링 rrreee 단어 빈도 계산 및 결과 출력 rrreee 불용어 추가 후 출력 결과는 다음과 같습니다.
보시다시피 비활성화된 단어
a가 표시되지 않습니다. 2 키워드 추출2.1 키워드 추출 원리단순히 단어 수를 세는 단어 빈도 통계와 달리, 지에바의 키워드 추출 원리는 TF-IDF(용어 빈도-역문서 빈도) 알고리즘을 기반으로 합니다. TF-IDF 알고리즘은 텍스트에서 단어의 중요도를 측정할 수 있는 일반적으로 사용되는 텍스트 특징 추출 방법입니다. 특히 TF-IDF 알고리즘은 두 부분으로 구성됩니다.
예: F(용어 빈도)는 문서에 단어가 나타나는 빈도를 나타냅니다. 계산식은 다음과 같습니다. T F = (문서에 단어가 나타나는 횟수) / (문서에 나오는 총 단어 수) 예를 들어 100 단어가 포함된 문서에서 특정 단어가 10 나온다면 TF라는 단어는 10/100 = 0.1입니다. IDF(Inverse Document Frequency)는 문서 모음에서 특정 단어가 나타나는 문서 수의 역수를 말합니다. 계산식은 다음과 같습니다. I DF = 로그(문서 모음의 전체 문서 수 / 해당 단어가 포함된 문서 수) 예를 들어 1,000개의 문서가 포함된 문서 모음에서 특정 단어가 100개의 문서에 나타난 다음, 단어의 IDF는 log (1000/100) = 1.0입니다.TFIDF는 TF와 IDF를 곱한 결과입니다. 계산식은 다음과 같습니다. T F I D F = T F ∗ I D FTF-IDF 알고리즘은 텍스트에서 단어의 발생만 고려하고 단어 간의 상관 관계는 무시합니다. 따라서 일부 특정 애플리케이션 시나리오에서는 단어 벡터, 주제 모델 등과 같은 다른 텍스트 특징 추출 방법을 사용해야 합니다. 2.2 키워드 추출 코드rrreee이 예제에서는 먼저
jieba.analyse모듈을 가져온 후 추출할 키워드에 대한 텍스트
text를 정의했습니다. 다음으로,
jieba.analyse.extract_tags()함수를 사용하여 키워드를 추출합니다. 여기서
topK매개변수는 추출할 키워드 수,
withWeight를 나타냅니다. code> 매개변수는 키워드의 가중치 값을 반환할지 여부를 나타냅니다. 마지막으로 키워드 목록을 반복하고 각 키워드와 해당 가중치 값을 출력합니다. 이 함수의 출력 결과는 다음과 같습니다. 보시다시피 jieba는 TF-IDF 알고리즘을 기반으로 입력 텍스트에서 여러 키워드를 추출하고 각 키워드의 가중치 값을 반환했습니다.
위 내용은 Python에서 단어 빈도 통계 및 키워드 추출에 Jieba를 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



