

홍콩 중문대학교(선전) Wu Baoyuan 교수 연구 그룹과 저장대학교 Qin Zhan 교수 연구 그룹이 공동으로 백도어 방어 분야에 대한 논문을 발표했으며, 이는 ICLR2022에서 성공적으로 승인되었습니다.
최근 몇 년간 백도어 문제가 널리 주목을 받았습니다. 백도어 공격이 계속 제안되면서 일반적인 백도어 공격에 대한 방어 방법을 제안하는 것이 점점 어려워지고 있다. 본 논문에서는 분할된 백도어 훈련 과정을 기반으로 한 백도어 방어 방법을 제안한다.
이 기사에서는 백도어 공격이 백도어를 기능 공간에 투영하는 엔드투엔드 지도 학습 방법임을 보여줍니다. 이를 바탕으로 이 글에서는 백도어 공격을 방지하기 위한 훈련 과정을 나눕니다. 본 방법의 유효성을 입증하기 위해 본 방법과 다른 백도어 방어 방법을 비교 실험하였다.
포괄 컨퍼런스: ICLR2022
기사 링크: https://arxiv.org/pdf/2202.03423.pdf
코드 링크: https://github.com/SCLBD/ DBD
백도어 공격의 목표는 훈련 데이터를 수정하거나 훈련 과정을 제어하여 모델이 정확하고 깨끗한 샘플을 예측하도록 만드는 것이지만, 백도어가 있는 샘플은 대상 라벨로 판단됩니다. 예를 들어, 백도어 공격자는 고정된 위치의 흰색 블록을 이미지(즉, 중독된 이미지)에 추가하고 이미지의 레이블을 대상 레이블로 변경합니다. 이러한 오염된 데이터로 모델을 훈련한 후 모델은 특정 흰색 블록이 있는 이미지가 대상 라벨이라고 판단합니다(아래 그림 참조).
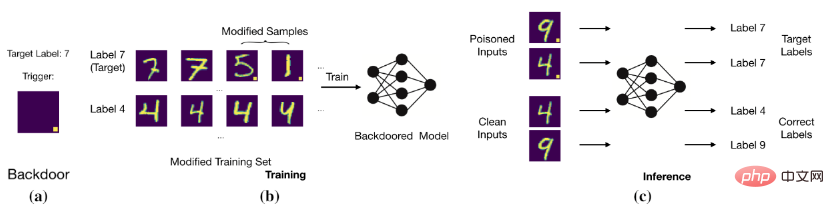 기본 백도어 공격
기본 백도어 공격
모델은 트리거와 대상 레이블 간의 관계를 설정합니다.
2. 클린 라벨 공격: 이미지-라벨 관계를 검사하여 사용자가 백도어 공격을 알아차릴 수 있는 문제를 해결하기 위해 Turner et al.(2019)은 대상 라벨이 동일한 클린 라벨 공격 패러다임을 제안했습니다. 중독된 샘플의 원래 라벨이 일치합니다. 이 아이디어는 표적-일반 적대적 교란(Moosavi-Dezfooli et al., 2017)을 트리거로 채택한(Zhao et al., 2020b)의 공격 비디오 분류로 확장되었습니다. 클린 태그 백도어 공격은 포이즌 태그 백도어 공격보다 더 미묘하지만 일반적으로 성능이 상대적으로 낮고 백도어를 생성하지 못할 수도 있습니다(Li et al., 2020c).
2.2 백도어 방어
기존 백도어 방어의 대부분은 경험적이며
2. 전처리 기반 방어(Doan et al, 2020; Li et al, 2021; Zeng et al, 2021)는 이미지를 모델에 입력하기 전에 전처리를 도입하여 공격 샘플에 포함된 트리거 패턴을 파괴하는 것을 목표로 합니다. 백도어 활성화를 방지하기 위한 처리 모듈입니다.
3. 모델 재구성 기반 방어(Zhao et al, 2020a; Li et al, 2021;)는 모델을 직접 수정하여 모델에 숨겨진 백도어를 제거하는 것입니다.
4. 포괄적인 방어를 시작하는 방법(Guo et al, 2020; Dong et al, 2021; Shen et al, 2021)은 먼저 백도어를 학습하고 두 번째로 그 영향을 억제하여 숨겨진 백도어를 제거하는 것입니다.
5. 중독 억제에 기반한 방어(Du et al, 2020; Borgnia et al, 2021)는 훈련 과정에서 중독된 샘플의 효율성을 줄여 숨겨진 백도어 생성을 방지합니다.
1. 준지도 학습: 많은 실제 응용 프로그램에서 레이블이 지정된 데이터를 수집하는 데 수동 레이블 지정이 필요한 경우가 많으며 이는 매우 비용이 많이 듭니다. 이에 비해 라벨이 없는 샘플을 얻는 것이 훨씬 쉽습니다. 레이블이 지정되지 않은 샘플과 레이블이 지정된 샘플의 성능을 모두 활용하기 위해 다수의 준지도 학습 방법이 제안되었습니다(Gao et al., 2017; Berthelot et al, 2019; Van Engelen & Hoos, 2020). 최근에는 적대적 훈련에서 레이블이 지정되지 않은 샘플을 사용하는 반지도 학습이 모델 보안을 향상시키는 데에도 사용되었습니다(Stanforth et al, 2019; Carmon et al, 2019). 최근(Yan et al, 2021)은 준지도 학습을 백도어하는 방법에 대해 논의했습니다. 그러나 이 방법은 훈련 샘플을 수정하는 것 외에도 다른 훈련 구성요소(예: 훈련 손실)도 제어해야 합니다.
2. 자기 지도 학습 패러다임은 비지도 학습의 하위 집합이며, 모델은 데이터 자체에서 생성된 신호를 사용하여 훈련됩니다(Chen et al, 2020a; Grill et al, 2020; Liu). 외, 2021). 이는 적대적 견고성을 높이는 데 사용됩니다(Hendrycks et al, 2019; Wu et al, 2021; Shi et al, 2021). 최근 일부 기사(Saha et al, 2021; Carlini & Terzis, 2021; Jia et al, 2021)에서는 자기 지도 학습에 백도어를 추가하는 방법을 탐구합니다. 그러나 이러한 공격은 훈련 샘플을 수정하는 것 외에도 다른 훈련 구성 요소(예: 훈련 손실)를 제어해야 합니다.
저희는 CIFAR-10 데이터 세트에 대해 BadNet 및 클린 라벨 공격을 수행했습니다(Krizhevsky, 2009). 독성 데이터 세트에 대한 지도 학습 및 레이블이 지정되지 않은 데이터 세트에 대한 자기 지도 학습 SimCLR(Chen et al., 2020a).
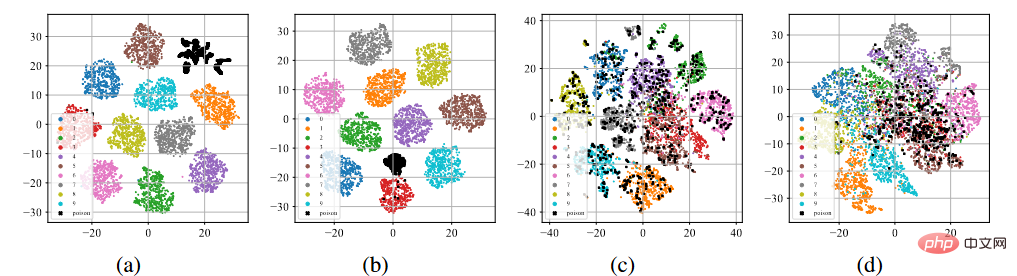
백도어 기능의 T-sne 표시
위의 그림 (a)-(b)에 표시된 것처럼 표준 감독 훈련 과정을 거친 후 포이즌 라벨 공격이나 클린 라벨 공격 아래에서 중독된 샘플(검은색 점으로 표시)은 모두 함께 모여 별도의 클러스터를 형성하는 경향이 있습니다. 이러한 현상은 기존 포이즌 기반 백도어 공격의 성공 가능성을 암시한다. 과잉 학습을 통해 모델은 백도어 트리거의 특성을 학습할 수 있습니다. 엔드투엔드 감독 훈련 패러다임과 결합된 이 모델은 특징 공간에서 오염된 샘플 사이의 거리를 줄이고 학습된 트리거 관련 특징을 대상 레이블과 연결할 수 있습니다. 반대로 위의 그림 (c)-(d)에서 볼 수 있듯이 레이블이 지정되지 않은 중독 데이터 세트에서는 자기 지도 학습 과정을 거친 후 중독된 샘플이 원래 레이블이 있는 샘플과 매우 유사합니다. 이는 자기주도학습을 통해 백도어를 예방할 수 있음을 보여준다.
백도어 특성 분석을 바탕으로 분할 훈련 단계에서 백도어 방어를 제안합니다. 아래 그림과 같이 (1) 자기 지도 학습을 통해 정제된 특징 추출기를 학습하는 단계, (2) 라벨 노이즈 학습을 통해 신뢰도가 높은 샘플을 필터링하는 단계, (3) 준지도 미세 지도 단계의 세 가지 주요 단계로 구성됩니다. 동조.
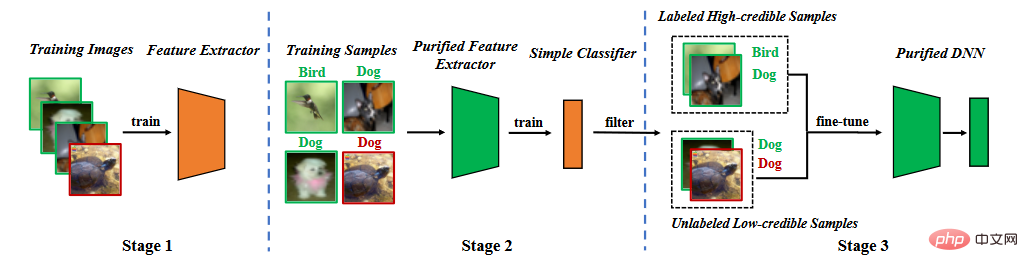 방법 흐름도
방법 흐름도
훈련 데이터 세트를 사용하여 모델을 학습합니다. 모델의 매개변수는 두 부분으로 구성됩니다. 하나는 백본 모델의 매개변수이고 다른 하나는 완전 연결 계층의 매개변수입니다. 우리는 백본 모델의 매개변수를 최적화하기 위해 자기 지도 학습을 활용합니다.
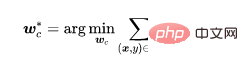
자기 감독 손실은 어디에 있습니까(예: SimCLR의 NT-Xent(Chen et al, 2020)). 이전 분석을 통해 특징 추출기가 학습하기 어렵다는 것을 알 수 있습니다. 백도어 기능.
특징 추출기가 학습되면 특징 추출기의 매개변수를 수정하고 학습 데이터 세트를 사용하여 완전 연결 레이어 매개변수를 추가로 학습합니다.
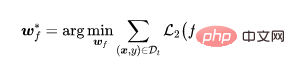
지도 학습 손실(예: 교차 엔트로피 손실)은 어디에 있습니까?
이 분할 프로세스로 인해 모델이 백도어를 학습하기가 어려워지지만 두 가지 문제가 있습니다. 첫째, 지도 학습을 통해 훈련된 방법과 비교할 때, 학습된 특징 추출기는 두 번째 단계에서 동결되므로 깨끗한 샘플을 예측하는 정확도가 어느 정도 감소합니다. 둘째, 오염된 라벨 공격이 발생하면 오염된 샘플은 "이상치"로 작용하여 학습의 두 번째 단계를 더욱 방해합니다. 이 두 가지 문제는 오염된 샘플을 제거하고 전체 모델을 재교육하거나 미세 조정해야 함을 나타냅니다.
샘플에 백도어가 있는지 확인해야 합니다. 우리는 모델이 백도어 샘플에서 학습하기 어렵다고 생각하므로 신뢰도를 구별 지표로 사용합니다. 신뢰도가 높은 샘플은 깨끗한 샘플이고 신뢰도가 낮은 샘플은 오염된 샘플입니다. 실험을 통해 대칭 교차 엔트로피 손실을 이용하여 훈련된 모델은 아래 그림과 같이 두 샘플 사이의 손실 격차가 크기 때문에 차별 정도가 높다는 것을 알 수 있습니다.
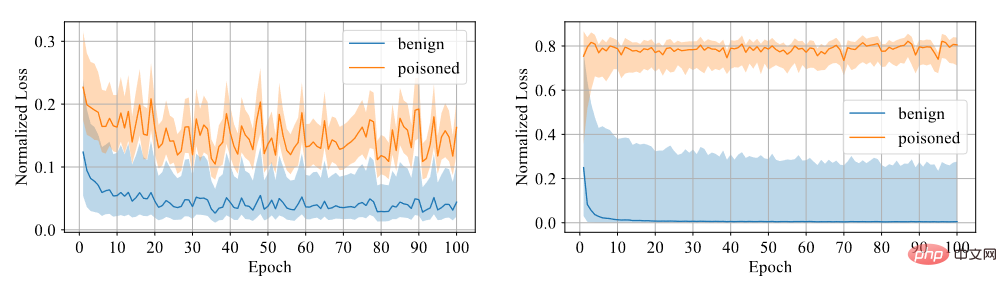
대칭 교차 엔트로피 손실과 교차 엔트로피 손실의 비교
따라서 대칭 교차 엔트로피 손실을 사용하여 완전 연결 계층을 훈련하도록 특징 추출기를 수정하고 데이터 세트를 높게 필터링했습니다. 신뢰 수준 신뢰도 데이터와 낮은 신뢰도 데이터의 크기에 따라 결정됩니다.
먼저 신뢰도가 낮은 데이터의 레이블을 제거합니다. 우리는 전체 모델을 미세 조정하기 위해 준지도 학습을 사용합니다.

준지도 손실은 어디에 있습니까(예: MixMatch의 손실 함수(Berthelot et al, 2019)).
반 감독 미세 조정은 모델이 백도어 트리거를 학습하는 것을 방지할 수 있을 뿐만 아니라 모델이 깨끗한 데이터 세트에서 잘 작동하도록 할 수도 있습니다.
백도어 공격 예시 사진
5.2 실험 결과
 실험의 판단 기준은 깨끗한 샘플인 BA의 판단 정확도와 독이 있는 샘플인 ASR의 판단 정확도입니다. .
실험의 판단 기준은 깨끗한 샘플인 BA의 판단 정확도와 독이 있는 샘플인 ASR의 판단 정확도입니다. .
위 표에서 볼 수 있듯이 DBD는 모든 공격에 대한 방어에 있어 동일한 요구 사항(예: DPSGD 및 ShrinkPad)을 가진 방어보다 훨씬 뛰어납니다. 모든 경우에 DBD는 DPSGD보다 BA가 20% 이상, ASR이 5% 더 낮습니다. DBD 모델의 ASR은 모든 경우에 2% 미만(대부분의 경우 0.5% 미만)으로, DBD가 숨겨진 백도어 생성을 성공적으로 방지할 수 있음을 확인합니다. DBD는 NC와 NAD라는 두 가지 다른 방법과 비교되는데, 둘 다 방어자가 깨끗한 로컬 데이터 세트를 보유해야 합니다.
위 표에서 볼 수 있듯이 NC와 NAD는 로컬 클린 데이터 세트의 추가 정보를 사용하기 때문에 DPSGD 및 ShrinkPad보다 성능이 뛰어납니다. 특히 NAD와 NC는 추가정보를 사용하지만 DBD가 이들보다 낫다. 특히 ImageNet 데이터세트에서 NC는 ASR 감소에 미치는 영향이 제한적입니다. 이에 비해 DBD는 가장 작은 ASR을 달성하는 반면, DBD의 BA는 거의 모든 경우에서 가장 높거나 두 번째로 높습니다. 또한, 방어 훈련을 하지 않은 모델과 비교하여 포이즌 태그 공격에 대한 방어 시 BA가 2% 미만 감소하는 것으로 나타났다. 상대적으로 큰 데이터 세트에서는 모든 기본 방법이 덜 효과적이기 때문에 DBD가 훨씬 더 좋습니다. 이러한 결과는 DBD의 효율성을 검증합니다.
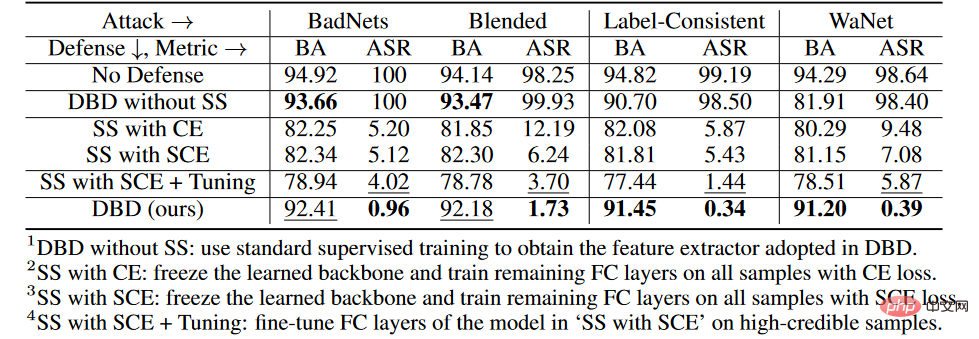
다양한 단계의 Ablation 실험
CIFAR-10 데이터 세트에서 제안된 DBD와
1을 포함한 4가지 변형을 비교했습니다. , 자기 지도 학습으로 생성된 백본을 지도 방식으로 훈련된 백본으로 대체하고 다른 부분은 변경하지 않습니다
2. SS를 CE로 고정하고 자기 지도 학습을 통해 학습한 백본을 동결하며 교차 엔트로피 손실 나머지 완전히 연결된 레이어는 SCE를 사용하여 모든 훈련 샘플
3.SS에 대해 훈련되었습니다. 두 번째 변형과 유사하지만 대칭 교차 엔트로피 손실을 사용하여 훈련되었습니다.
4.SS(SCE + Tuning 포함)는 세 번째 변형으로 필터링된 신뢰도가 높은 샘플의 완전 연결 레이어를 더욱 미세 조정합니다.
위 표에서 볼 수 있듯이 원래의 엔드투엔드 지도 학습 프로세스를 분리하는 것은 숨겨진 백도어 생성을 방지하는 데 효과적입니다. 또한 두 번째와 세 번째 DBD 변종을 비교하여 포이즌 태그 백도어 공격에 대한 방어에 있어 SCE 손실의 효율성을 검증합니다. 또한, 네 번째 DBD 돌연변이의 ASR 및 BA는 세 번째 DBD 돌연변이의 ASR 및 BA보다 낮습니다. 이 현상은 신뢰도가 낮은 샘플을 제거했기 때문에 발생합니다. 이는 신뢰도가 낮은 샘플에서 유용한 정보를 사용하는 동시에 부작용을 줄이는 것이 방어에 중요하다는 것을 의미합니다.
공격자가 DBD의 존재를 알면 적응형 공격을 설계할 수 있습니다. 공격자가 방어자가 사용하는 모델 구조를 알 수 있으면 아래와 같이 독이 있는 샘플이 자기 지도 학습 후 새 클러스터에 남아 있도록 트리거 패턴을 최적화하여 적응형 공격을 설계할 수 있습니다.
공격 설정
-분류 문제의 경우 독이 필요한 깨끗한 샘플을 표현하고, 원래 라벨이 있는 샘플을 표현하고, 훈련된 백본이 되도록 합니다. 공격자가 미리 결정한 중독 이미지 생성기가 주어지면 적응형 공격은 중독 이미지의 중심과 서로 다른 레이블이 있는 양성 이미지 클러스터의 중심 사이의 거리를 최대화하면서 중독 이미지 사이의 거리를 최소화하여 트리거 패턴을 최적화하는 것을 목표로 합니다. 거리, 즉.
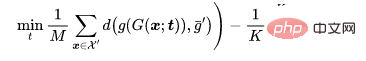
여기서 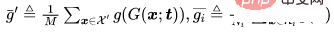 은 거리 결정입니다.
은 거리 결정입니다.
실험 결과
방어 없는 적응형 공격의 BA는 94.96%, ASR은 99.70%입니다. 그러나 DBD의 방어 성적은 BA93.21%, ASR1.02%였다. 즉, DBD는 이러한 적응형 공격에 저항력이 있습니다.
중독 기반 백도어 공격의 메커니즘은 훈련 과정에서 트리거 패턴과 대상 레이블 사이의 잠재적인 연결을 설정하는 것입니다. 이 논문에서는 이러한 연결이 주로 엔드투엔드 지도 교육 패러다임 학습에 기인함을 보여줍니다. 이러한 이해를 바탕으로 본 논문에서는 디커플링 기반의 백도어 방어 방법을 제안한다. DBD 방어는 양성 샘플 예측 시 높은 정확도를 유지하면서 백도어 위협을 줄일 수 있다는 것이 다수의 실험을 통해 검증되었습니다.
위 내용은 분할된 백도어 훈련의 백도어 방어 방법: DBD의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



