

저자 소개
간단히 말하면 Ctrip 백엔드 개발 관리자로서 기술 아키텍처, 성능 최적화, 운송 계획 및 기타 분야에 중점을 두고 있습니다.
교통 계획 및 교통 자원의 한계로 인해 사용자가 문의한 두 장소 간 직행 운송이 불가능하거나, 주요 공휴일에는 직행 운송이 매진되었습니다. 그러나 사용자는 여전히 기차, 비행기, 자동차, 선박 등 양방향 또는 다방향 환승을 통해 목적지에 도달할 수 있습니다. 또한 가격이나 시간 소모 측면에서 환승 운송이 더 유리한 경우도 있습니다. 예를 들어, 상하이에서 윈청까지 기차로 연결하는 것이 직행 열차보다 빠르고 저렴할 수 있습니다.
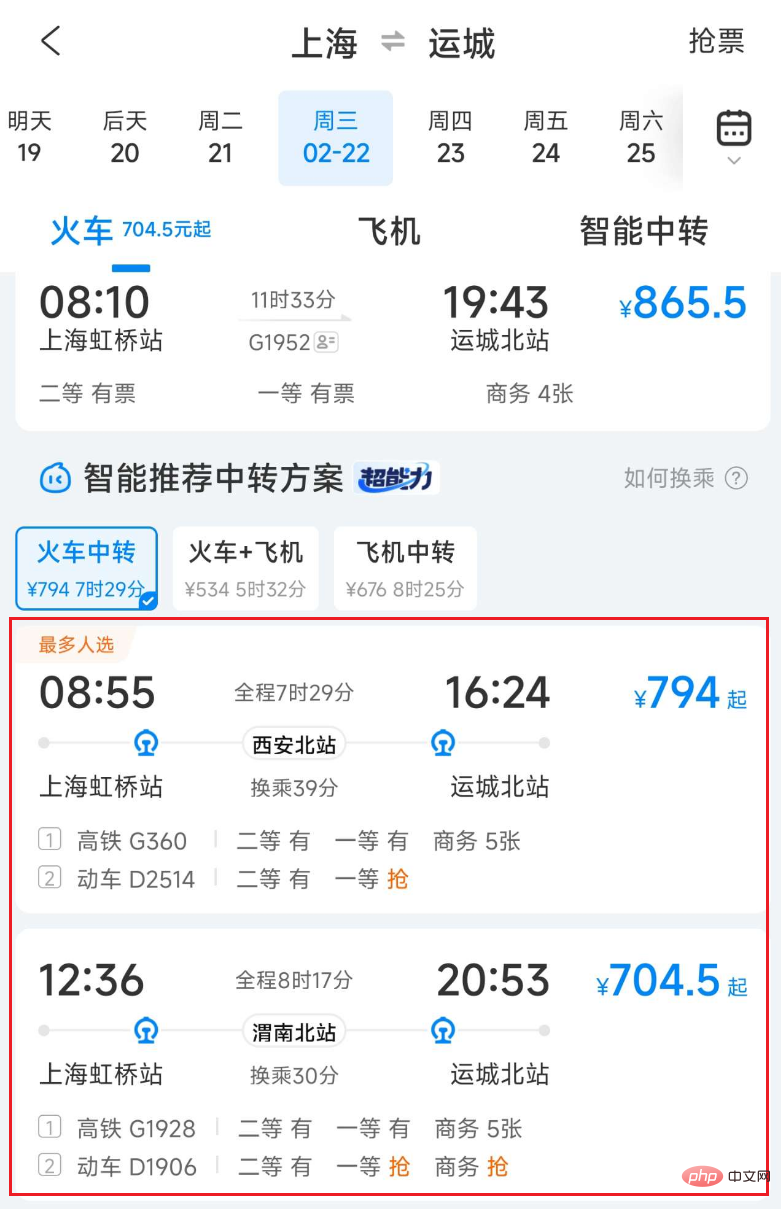
그림 1 씨트립 열차 환승 운송 목록
환승 운송 솔루션을 제공할 때 매우 중요한 링크는 기차, 비행기, 자동차, 선박 등 두 개 이상의 여행을 가능한 환승으로 결합하는 것입니다. 계획. 대중교통을 접속할 때 첫 번째 어려움은 접속 공간이 크다는 것입니다. 상하이만 대중교통 도시로 간주하면 거의 1억 개의 조합이 생성될 수 있다는 것입니다. 또 다른 어려움은 생산 라인 데이터 때문에 실시간 성능이 필요하다는 것입니다. 기차, 비행기, 자동차, 선박에 대한 데이터는 언제든지 변경되고 지속적으로 업데이트되어야 합니다. 전송 트래픽 접합에는 많은 컴퓨팅 리소스와 IO 오버헤드가 필요하므로 성능을 최적화하는 것이 특히 중요합니다.
이 기사에서는 전송 트래픽 접합 성능을 최적화하는 과정에서 따르는 원리, 분석 및 최적화 방법을 예제를 사용하여 소개하고 독자에게 귀중한 참고 자료와 영감을 제공할 것입니다.
2. 최적화 원칙성능 최적화에는 비즈니스 요구 사항 충족을 전제로 다양한 리소스와 제약 조건 간의 균형을 맞추고 절충이 필요합니다. 이를 따르면 불확실성을 제거하고 문제에 접근할 수 있습니다. 특히, 전송 트래픽 스플라이싱 최적화 프로세스에서는 다음 세 가지 원칙을 주로 따릅니다.
2.1 성능 최적화는 목적이 아닌 수단입니다.이 문서는 성능 최적화에 관한 것이지만 여전히 처음에 강조할 필요가 있습니다. : 최적화를 위해 하지 말고 최적화하세요. 비즈니스 요구 사항을 충족하는 방법에는 여러 가지가 있으며 성능 최적화는 그 중 하나일 뿐입니다. 문제가 매우 복잡하고 제한 사항이 많은 경우도 있습니다. 사용자 경험에 크게 영향을 주지 않으면서 제한 사항을 완화하거나 다른 프로세스를 채택하여 사용자에게 미치는 영향을 줄이는 것도 성능 문제를 해결하는 좋은 방법입니다. 소프트웨어 개발에는 약간의 성능을 희생하여 상당한 비용 절감을 달성한 사례가 많이 있습니다. 예를 들어 Redis에서 카디널리티 통계(중복 제거)에 사용되는 HyperLogLog 알고리즘은 표준 오류 0.81%로 단 12K 공간에서 264개의 데이터를 계산할 수 있습니다.
문제 자체로 돌아가서, 생산 라인 데이터를 자주 쿼리하고 대규모 접합 작업을 수행해야 하기 때문에 각 사용자가 쿼리할 때 가장 최근의 전송 계획을 즉시 반환해야 한다면 비용이 매우 높을 것입니다. 비용을 줄이려면 응답 시간과 데이터 최신성 사이의 균형을 맞춰야 합니다. 신중하게 고려한 후 분 단위의 데이터 불일치를 허용하기로 결정했습니다. 일부 인기 없는 경로 및 날짜의 경우 처음 쿼리할 때 적절한 환승 계획이 없을 수 있습니다. 이 경우 사용자에게 페이지를 새로 고치도록 안내합니다.
2.2 잘못된 최적화는 모든 악의 근원입니다Donald Knuth는 "Go To 문을 사용한 구조적 프로그래밍"에서 언급했습니다. "프로그래머는 중요하지 않은 경로의 성능에 대해 생각하고 걱정하는 데 많은 시간을 낭비합니다. 성능의 이 부분을 최적화하면 전체 코드의 디버깅 및 유지 관리에 매우 심각한 부정적인 영향을 미치므로 97%의 경우 작은 최적화 사항을 잊어버려야 합니다." 즉, 실제 성능 문제가 발견되기 전에 코드 수준에서 과도하고 허식적인 최적화를 수행하면 성능이 향상될 뿐만 아니라 더 많은 오류가 발생할 수 있습니다. 하지만 저자는 “나머지 핵심 3%에 대해서는 최적화의 기회를 놓치지 말아야 한다”고 강조했다. 따라서 항상 성능 문제에 주의를 기울여야 하며 성능에 영향을 미치는 결정을 내리지 말고 필요할 경우 올바른 최적화를 수행해야 합니다.
이전 섹션에서 언급했듯이 최적화하기 전에 먼저 성능을 정량화하고 병목 현상을 식별해야 최적화가 더욱 목표화될 수 있습니다. 성능의 정량적 분석에는 시간이 많이 걸리는 모니터링, 프로파일러 성능 분석 도구, 벤치마크 벤치마크 테스트 도구 등을 사용할 수 있으며 특히 시간이 오래 걸리거나 실행 빈도가 특히 높은 영역에 중점을 둡니다. Amdahl의 법칙에 따르면 "시스템의 특정 구성 요소에 대해 더 빠른 실행 방법을 사용하여 얻을 수 있는 시스템 성능 향상 정도는 이 실행 방법이 사용되는 빈도 또는 전체 실행 시간의 비율에 따라 달라집니다. "
또한 성능 최적화는 장기간의 싸움이라는 점에 유의하는 것도 중요합니다. 비즈니스가 계속 발전함에 따라 아키텍처와 코드도 끊임없이 변화하고 있기 때문에 지속적으로 성능을 정량화하고 병목 현상을 지속적으로 분석하며 최적화 효과를 평가하는 것이 더욱 필요합니다.
성과 분석에 앞서 먼저 비즈니스 프로세스를 정리해야 합니다. 환승 운송 계획의 연결에는 주로 다음 4단계가 포함됩니다.
a 난징 환승을 통해 베이징에서 상하이까지의 경로 지도를 로드하며 경로 자체의 정보만 고려되며 경로와는 아무런 관련이 없습니다. 특정 열차
b 출발 시간, 도착 시간, 출발 역, 도착 역, 가격 및 잔여 티켓 정보 등을 포함한 항공기, 자동차 및 선박의 생산 라인 데이터를 확인하세요. c. 환승을 주로 고려하여 가능한 모든 환승 운송 솔루션을 연결합니다. 환승을 완료할 수 없도록 탑승 시간이 너무 짧아서는 안 되며, 너무 오래 기다리지 않도록 너무 길어서는 안 됩니다. 실행 가능한 솔루션을 결합한 후에도 총 가격, 총 시간 소비, 전송 정보 등과 같은 비즈니스 분야를 개선해야 합니다.
d 특정 규칙에 따라 모든 실행 가능한 전송 솔루션에서 일부 사용자를 선택합니다. 관심을 가질만한 프로그램을 분리했습니다.
3.2 정량분석 성능
시간이 많이 걸리는 모니터링은 각 단계의 시간이 많이 걸리는 상황을 거시적 관점에서 관찰하는 가장 직관적인 방법입니다. 비즈니스 프로세스의 각 단계에서 시간이 소요되는 가치와 시간이 소요되는 비율을 볼 수 있을 뿐만 아니라 장기간에 걸쳐 시간이 소요되는 변화 추세를 관찰할 수도 있습니다.
시간이 많이 걸리는 모니터링은 회사의 내부 지표 모니터링 및 경보 시스템을 사용하여 운송 솔루션을 연결하는 주요 프로세스에 시간이 많이 걸리는 관리를 추가할 수 있습니다. 이러한 프로세스에는 경로 지도 로드, 교대 데이터 쿼리 및 접합, 접합 계획 필터링 및 저장 등이 포함됩니다. 각 단계의 시간이 소요되는 상황은 그림 2에 나와 있습니다. 스플라이싱(생산 라인 데이터 포함)이 시간 소모의 가장 높은 비율을 차지하는 것을 볼 수 있으므로 향후 핵심 최적화 대상이 되었습니다.
그림 2 시간이 많이 걸리는 전송 트래픽 스플라이싱 모니터링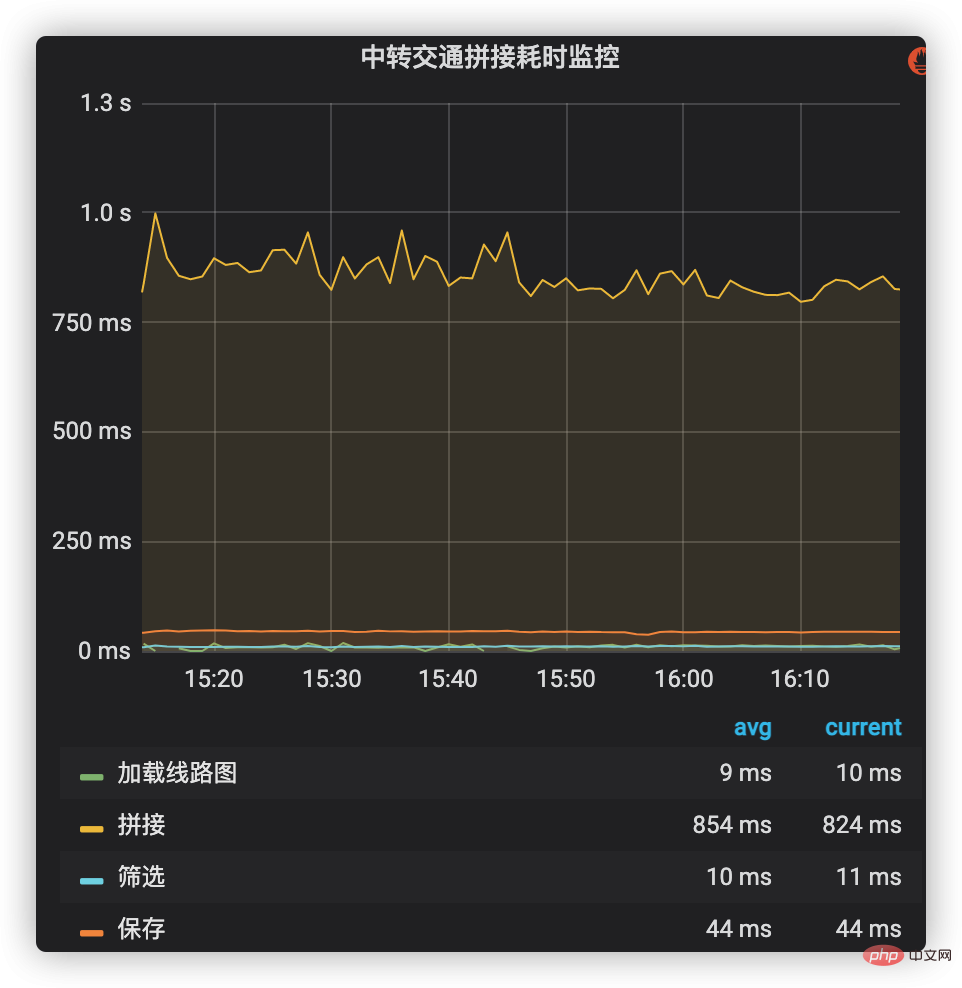
(2) 프로파일러 성능 분석
시간이 많이 걸리는 관리는 비즈니스 코드를 침해하고 성능에 영향을 미칠 수 있습니다. 따라서 이를 초과해서는 안 되며, 주요 프로세스를 모니터링하는 데 더 적합합니다. 해당 프로파일러 성능 분석 도구(예: Async-profiler)는 보다 구체적인 호출 트리와 각 기능의 CPU 사용량 비율을 생성하여 중요한 경로와 성능 병목 현상을 분석하고 찾는 데 도움을 줍니다.
그림 3 스플라이싱 호출 트리 및 CPU 비율
그림 3에서 볼 수 있듯이 스플라이싱 솔루션(combineTransferLines)이 53.80%를 차지하고 쿼리 생성 라인 데이터(querySegmentCacheable, 캐시 사용)가 21.45%. 스플라이싱 기법에서는 스킴 점수 계산(computeTripScore, 48.22% 차지), 스킴 엔터티 생성(buildTripBO, 4.61% 차지), 스플라이싱 타당성 확인(checkCombineMatchCondition, 0.91% 차지)이 가장 큰 3대 링크이다.
그림 4 솔루션 점수 호출 트리 및 CPU 비율
계산 계획 점수(computeTripScore)를 가장 높은 비율로 분석한 결과 직접 호출(계획 점수 세부 정보를 표시하는 데 사용)을 포함하여 주로 사용자 지정 문자열 서식 지정 기능(StringUtils.format)과 관련이 있다는 사실을 발견했으며, getTripId 호출(구성표를 생성하는 데 사용되는 ID)을 통한 간접 호출. 사용자 정의된 StringUtils.format의 가장 높은 비율은 java/lang/String.replace입니다. Java 8의 기본 문자열 대체는 정규 표현식을 통해 구현되는데, 이는 상대적으로 비효율적입니다(이 문제는 Java 9 이후에 개선되었습니다).
// 计算方案评分(computeTripScore) 中调用的StringUtils.format代码示例 StringUtils.format("AAAA-{0},BBBB-{1},CCCC-{2},DDDD-{3},EEEE-{4},FFFF-{5},GGGG-{6},HHHH-{7},IIII-{8},JJJJ-{9}", aaaa, bbbb, cccc, dddd, eeee, ffff, gggg, hhhh, iiii, jjjj) // getTripId 中调用StringUtils.format代码示例 StringUtils.format("{0}_{1}_{2}_{3}_{4}_{5}_{6}", aaaa, bbbb, cccc, dddd, eeee, ffff) // 通过Java replace实现的自定义format函数 public static String format(String template, Object... parameters) { for (int i = 0; i < parameters.length; i++) { template = template.replace("{" + i + "}", parameters[i] + ""); } return template; }
(3) 벤치마크 벤치마크 테스트
벤치마크 벤치마크 도구의 도움으로 코드의 실행 시간을 보다 정확하게 측정할 수 있습니다. 표 1에서는 JMH(Java Microbenchmark Harness)를 사용하여 세 가지 문자열 형식 지정 방법과 한 가지 문자열 접합 방법에 대해 시간이 많이 걸리는 테스트를 수행합니다. 테스트 결과, Java8의 교체 메소드를 사용한 문자열 포맷팅이 가장 나쁜 성능을 보였으며, Apache의 문자열 스플라이싱 기능을 사용한 것이 가장 좋은 성능을 보였습니다.
표 1 문자열 서식 지정 및 접합 성능 비교
通过以上的性能分析,我们发现拼接和查询产线数据是性能瓶颈,字符串格式化影响尤其大。因此,我们将致力于优化这些部分,以提高性能表现。
优化代码逻辑是最简单且性价比最高的方法,可以是修正有问题的代码或替换为更好的实现。不同的实现,哪怕减上几纳秒,累加起来也是很可观的。借助一些经典算法或数据结构(如快速排序、红黑树等)可以在时间和空间复杂度方面带来显著优势。回到中转交通方案拼接性能优化本身,优化的代码逻辑主要包括:
(1)优化字符串拼接性能
如前面的JMH的结果所示,自定义的字符串格式化函数性能最差,因此作为重点优化目标。优化前后的对比如下所示:
// 优化前,通过Java replace实现的format函数 public static String format(String template, Object... parameters) { for (int i = 0; i < parameters.length; i++) { template = template.replace("{" + i + "}", parameters[i] + ""); } return template; } // 优化后,通过Apache replace实现的format函数 public static String format(String template, Object... parameters) { for (int i = 0; i < parameters.length; i++) { String temp = new StringBuilder().append('{').append(i).append('}').toString(); template = org.apache.commons.lang3.StringUtils.replace(template, temp, String.valueOf(parameters[i])); } return template; }
根据JMH的测试结果,即使是优化后的格式化函数,其性能也不是最优的。在不显著影响可读性的前提下,应尽量使用性能更优的StringUtils.join函数。
// 优化前 StringUtils.format("{0}_{1}_{2}_{3}_{4}_{5}_{6}", aaaa, bbbb, cccc, dddd, eeee, ffff) // 优化后 StringUtils.join("_", aaaa, bbbb, cccc, dddd, eeee, ffff)
为进一步提升性能,可以在computeTripScore 函数中添加一个开关,仅在调试模式下才展示评分细节,这将确保该字符串格式化函数仅在需要时才被调用。
if (Config.getBoolean("enable.score.detail", false)) { scoreDetail = StringUtils.format("AAAA-{0},BBBB-{1},CCCC-{2},DDDD-{3},EEEE-{4},FFFF-{5},GGGG-{6},HHHH-{7},IIII-{8},JJJJ-{9}", aaaa, bbbb, cccc, dddd, eeee, ffff, gggg, hhhh, iiii, jjjj); }
优化后的CPU占比如图5所示,此时字符串格式化已经不再是性能瓶颈。

图5 优化后的拼接调用树和CPU占比
(2)增加索引降低拼接时间复杂度

图6 增加索引降低拼接时间复杂度
在中转拼接过程中,我们需要将第一程每个班次的到达时间与第二程每个班次的出发时间进行比较,以判断中转时间是否过短或过长。为简化说明,假设换乘时间间隔需要满足大于30分钟且小于6小时。以北京到上海经南京中转的两程火车为例,3月9日北京到南京有66个班次,南京到上海有275个班次,考虑到隔夜车,还需要算上3月10日南京到上海的275个班次,那么最多需要比较36300(66*275*2)次。
为避免频繁比较,参考了MySQL B+树索引的思想,将第二程南京到上海的所有火车班次数据构建成红黑树。其中,树的键为秒级时间戳,例如2023-03-09 11:29出发的G367键为1677247680,值为G367的班次数据。有了索引树,最多只需要10次比较,就可以找到最近的满足最小换乘时间要求的班次。同理,最多需要10次比较,就能找到满足最大换乘时间要求的最晚班次。两者之间的所有班次都满足耗时要求,直接进行拼接即可。改进后最多需要比较1320(66*(10+10))次,约为原来的1/27.5。
(3)使用多路归并求Top-K算法
在筛选方案时,会存在以下场景:有多个中转点,每个中转点都有数百个得分较高的方案(内部已按得分由高到低排序,通过小根堆实现)。最终需要将这些方案合并,并从中筛选出得分最高的K个方案。
最简单的方法是使用快速排序将所有的方案排序,然后选取前K个,时间复杂度约为O(nlog2n)。然而,这并没有利用到每个队列自身有序的特点。通过多路归并算法时间复杂度可降为O(nlog2k),具体步骤为:
a. 从每个队列中拿出第一个元素(得分最高的方案),放入大根堆中;
b. 큰 루트 힙의 맨 위에서 가장 큰 요소를 가져와서 결과 집합에 넣습니다.
c. 요소가 있는 대기열에 남은 요소가 있으면 다음 요소를 추가합니다. heap;
d. 결과 집합에 K개의 요소가 포함되거나 모든 대기열이 비어 있을 때까지 2단계와 3단계를 반복합니다.
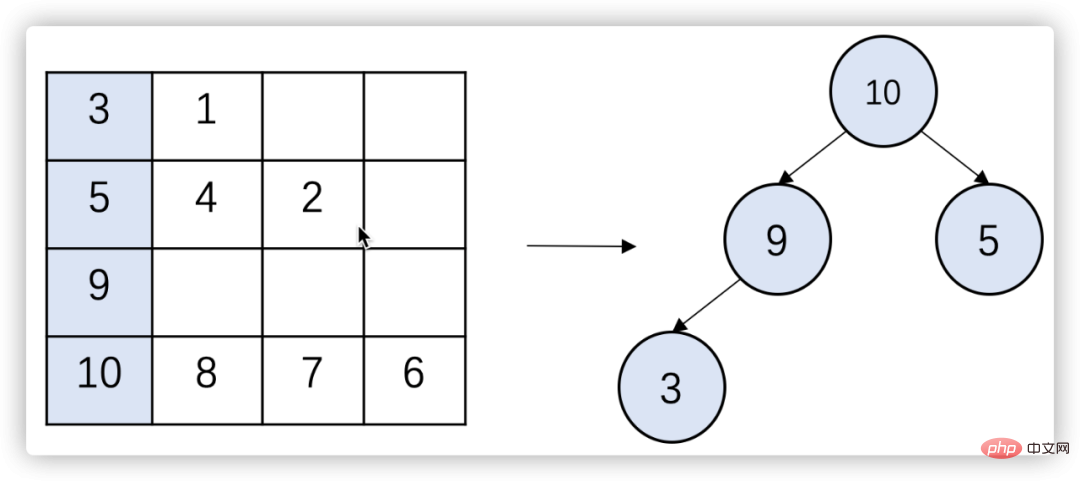
그림 7 다중 방향 병합 Top-K 알고리즘
캐시는 데이터와 계산 결과를 캐시할 수 있는 일반적인 시공간 전략입니다. 반복 계산을 피하기 위해 액세스 효율성을 높이고 결과를 캐시합니다. 캐싱은 성능 향상을 가져오지만 새로운 문제도 발생합니다.
환승 운송 솔루션을 접합하는 과정에서는 대량의 기본 데이터(역, 행정 구역 등)와 대규모 동적 데이터(교대 데이터 등)를 사용해야 합니다. 위의 요소들을 바탕으로 대중교통 트래픽 스플라이싱의 비즈니스 특성과 결합하여 다음과 같이 캐시 아키텍처를 설계합니다.
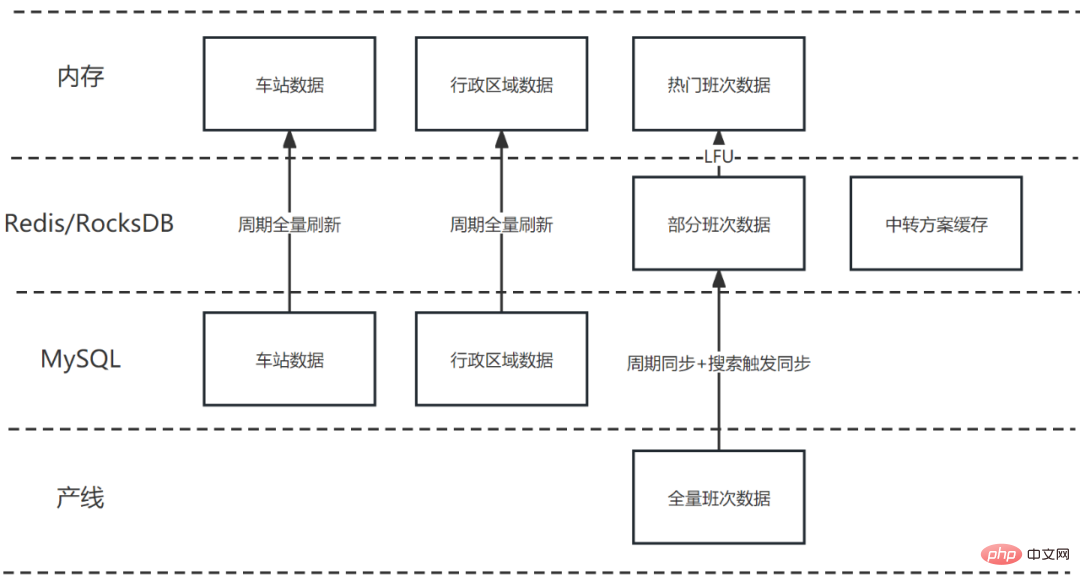
그림 8 다단계 캐시 구조
이론적으로는 두 장소 사이의 환승 지점으로 모든 도시를 선택할 수 있지만 실제로 대부분의 환승 도시는 고품질을 연결할 수 없습니다. 계획. 따라서 일부 고품질 전송 지점은 오프라인 전처리를 통해 먼저 선별되어 솔루션 공간을 수천에서 수십으로 줄입니다. 동적으로 변화하는 교대조에 비해 라인 데이터는 상대적으로 고정되어 있으며 하루에 한 번 계산할 수 있습니다. 또한 오프라인 전처리는 빅데이터 기술을 활용해 대용량 데이터를 처리할 수 있어 시간 소모에 상대적으로 둔감하다.
접합 프로세스에서는 전송 지점이 다른 수십 개의 라인을 처리해야 합니다. 각 라인의 접합은 서로 독립적이므로 멀티스레딩을 사용할 수 있어 처리 시간이 최소화됩니다. 그러나 라인 이동 횟수와 캐시 적중률의 영향으로 인해 서로 다른 라인의 스플라이싱 시간을 일정하게 유지하기가 어렵습니다. 두 스레드에 동일한 수의 작업이 할당되면 한 스레드가 빠르게 실행을 완료하더라도 다음 단계로 진행하기 전에 다른 스레드의 실행이 완료될 때까지 기다려야 하는 경우가 많습니다. 이러한 상황을 방지하기 위해 ForkJoinPool의 작업 훔치기 메커니즘이 사용됩니다. 이 메커니즘은 각 스레드가 자체 작업을 완료한 후 다른 스레드의 완료되지 않은 작업을 공유하고 동시성 효율성을 향상시키며 유휴 시간을 줄이도록 보장합니다.
그러나 멀티스레딩은 전능하지 않습니다. 사용 시 다음 사항에 주의해야 합니다.
필요한 순간까지 계산을 연기함으로써 많은 중복 오버헤드를 피할 수 있습니다. 예를 들어 편입 계획을 엮은 후에는 계획 개체를 구축하고 사업 분야를 개선해야 하는 부분도 리소스를 소모합니다. 그리고 접합된 솔루션이 모두 선별되지는 않습니다. 이는 선별되지 않은 솔루션이 여전히 컴퓨팅 리소스를 소비해야 함을 의미합니다. 따라서, 접합 과정에서 수만 개의 솔루션이 먼저 경량 중간 개체로 저장되고, 선별 후에는 수백 개의 중간 개체에 대해서만 완전한 솔루션 개체가 구축됩니다.
전송 트래픽 접합 프로젝트는 Java 8을 기반으로 하며 G1(Garbage-First) 가비지 수집기를 사용하며 8C8G 시스템에 배포됩니다. G1은 일시 중지 시간 요구 사항을 최대한 충족하면서 높은 처리량을 달성합니다. 시스템 아키텍처 부서에서 설정한 기본 매개 변수는 이미 대부분의 시나리오에 적합하며 일반적으로 특별한 최적화가 필요하지 않습니다.
그러나 회선 전송 방식이 너무 많아 패킷이 너무 커서 Region 크기(8G, 기본 Region 크기는 2M)의 절반을 초과하여 젊은 세대에 들어가야 하는 대형 객체가 많이 발생합니다. 이를 방지하려면 Region 크기를 16M로 변경하세요.
위의 분석과 최적화를 통해 접합 시간 소비의 변화는 그림 9에 표시됩니다.
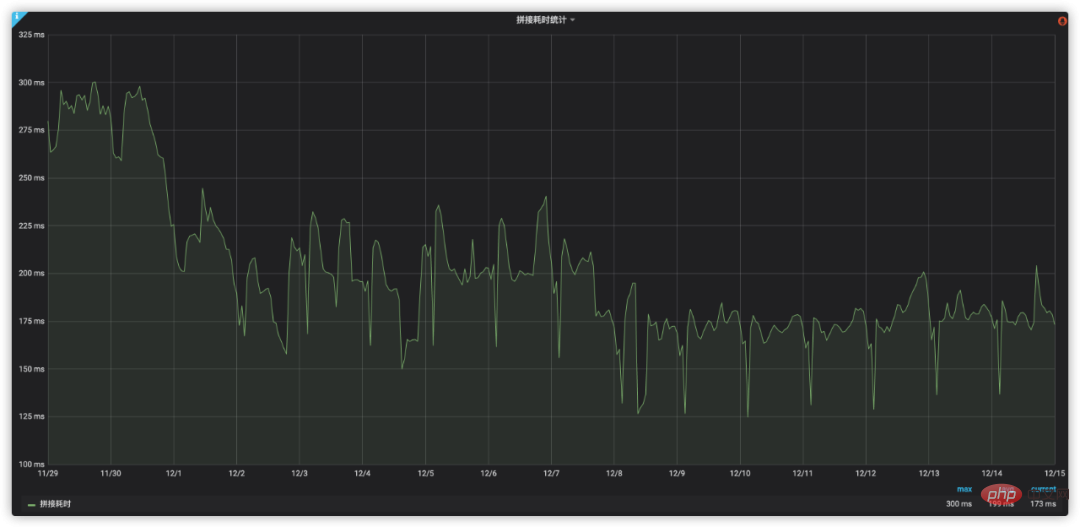
그림 9 이송 이송 방식의 접합 성능 최적화 효과
각 비즈니스에는 각 시나리오마다 고유한 특성이 있으며 성능 최적화에도 구체적인 분석이 필요합니다. 그러나 원칙은 동일하며 이 기사에 설명된 분석 및 최적화 방법을 계속 참조할 수 있습니다. 이 기사의 모든 분석 및 최적화 방법이 그림 10에 요약되어 있습니다.
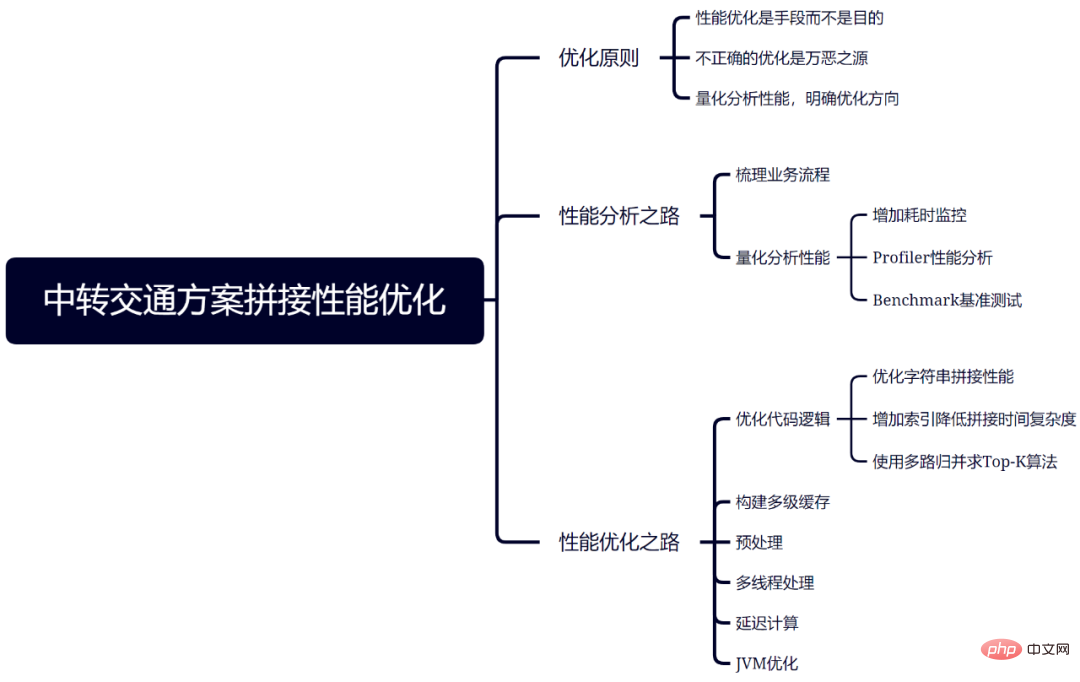
그림 10 환승 운송 계획의 접합 최적화 요약
위 내용은 Ctrip 환승 운송 계획의 접합 성능 최적화의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
implementation |
평균 시간(us) 소모 1000회 실행 |
StringUtils .format은 Java8의 교체 |
1988.982 |
StringUtils.format이 Apache 교체 |
656을 사용하여 구현되었습니다. |
Java8에는 문자열이 함께 제공됩니다. 형식 |
1417.474 |
Apache의 StringUtils.join |
116.812 |






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



