

한 문단 주면서 영상 만들어 달라고 할 텐데, 해주실 수 있나요?
메타는 "나는 할 수 있다"고 말했다.
맞게 들었습니다. AI를 사용하면 영화 제작자가 될 수도 있습니다!
최근 Meta는 새로운 AI 모델을 출시했는데 이름은 매우 간단합니다. 바로 Make-A-Video입니다.
이 모델은 얼마나 강력합니까?
한 문장만으로도 '말 세 마리 질주' 장면을 실감할 수 있습니다.

르쿤도 올 일은 반드시 올 거라고 하더군요.

더 이상 고민할 필요 없이 효과만 살펴보겠습니다.
두마리 캥거루가 주방에서 바쁘게 요리하고 있다(먹을 수 있을지는 별개의 문제)

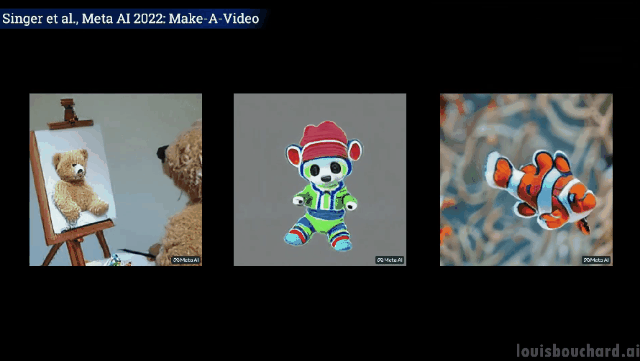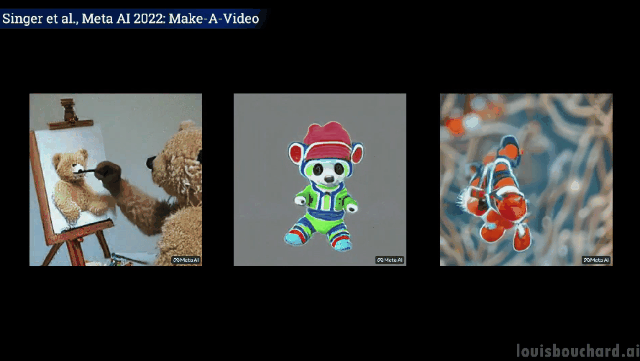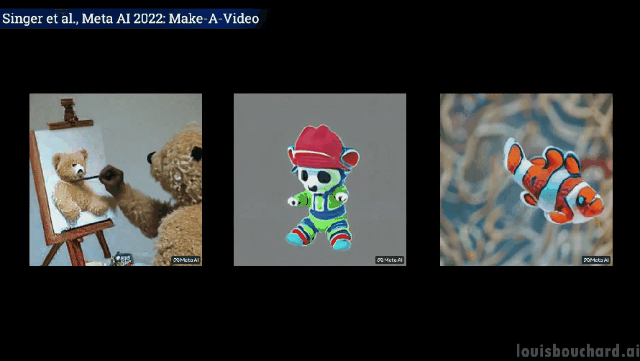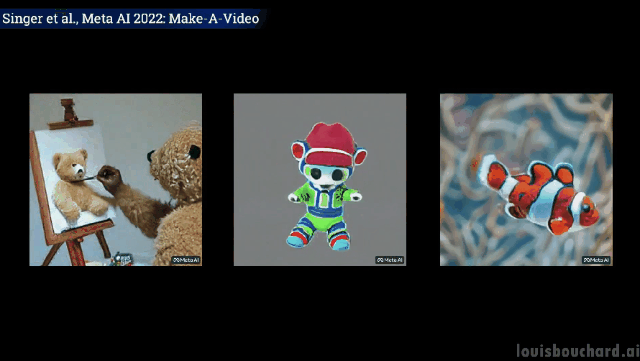
클로저 샷: 화가는 캔버스에 그림을 그리고 있다

두 사람의 세계 폭우 속을 걷는 사람들 ( 균일 한 걸음 )

말은 물을 마시고 있습니다

발레리나 소녀는 초고층 건물에서 춤을 추고 있습니다

골든 리트리버는 아름다운 여름 열대 해변에서 먹는 아이스크림(발은 진화했다)

고양이 주인은 리모콘으로 TV를 보고 있다(발은 진화했다)

곰 인형이 스스로 그림을 그린다 자신의 초상화

예상치 못한 일이지만 합리적인 것은 강아지가 아이스크림을 쥐고, 고양이가 리모콘을 쥐고, 곰 인형이 그림을 그리는 '손'이 실제로 인간처럼 '진화'했다는 것입니다! (전술적 역방향)
물론 Make-A-Video는 텍스트를 비디오로 변환하는 것 외에도 정적 이미지를 GIF로 변환할 수도 있습니다.
입력:

출력:

입력:

출력: (빛이 약간 어긋난 것 같습니다)

2개의 정적 사진을 GIF로 입력하세요. 운석 사진을 입력하세요

출력:

그리고 영상을 영상으로 바꿔볼까?
입력:

출력:

입력:

출력:

오늘 메타가 자체 최신버전을 공개했습니다. 연구 영상 제작: 텍스트 비디오 데이터 없이 텍스트를 비디오로 생성.

논문 주소: https://makeavideo.studio/Make-A-Video.pdf
이 모델이 등장하기 전에 우리는 이미 Stable Diffusion을 갖고 있었습니다.
똑똑한 과학자들은 이미 AI에게 단 한 문장으로 이미지를 생성하도록 요청했습니다.
분명히 영상을 생성하는 것입니다.

빨간 망토를 입고 하늘을 나는 슈퍼 히어로 개
동영상을 생성하는 것은 이미지를 생성하는 것보다 훨씬 어렵습니다. 동일한 피사체와 장면에 대한 여러 프레임을 생성해야 할 뿐만 아니라 시기적절하고 일관되게 만들어야 합니다.
이로 인해 이미지 생성 작업이 더 복잡해집니다. 단순히 DALLE를 사용하여 60개의 이미지를 생성한 다음 이를 비디오로 연결할 수는 없습니다. 효과는 매우 열악하고 비현실적입니다.
따라서 우리는 세상을 보다 강력한 방식으로 이해하고 이러한 이해 수준을 바탕으로 일관된 이미지 시리즈를 생성할 수 있는 모델이 필요합니다. 그래야만 이미지가 원활하게 혼합될 수 있습니다.
즉, 우리의 목표는 세계를 시뮬레이션하고 그 기록을 시뮬레이션하는 것입니다. 어떻게 하나요?

이전 아이디어에 따르면 연구자들은 모델을 훈련하기 위해 많은 수의 텍스트-비디오 쌍을 사용할 것이지만 현재 상황에서는 이 처리 방법이 현실적이지 않습니다. 왜냐하면 이러한 데이터는 얻기 어렵고 훈련 비용이 매우 비싸기 때문입니다.
그래서 연구자들은 마음을 열고 완전히 새로운 접근 방식을 채택했습니다.
그들은 텍스트-이미지 모델을 개발한 다음 이를 비디오에 적용하기로 결정했습니다.
공교롭게도 얼마 전 메타는 텍스트를 이미지로 변환하는 모델인 Make-A-Scene을 개발했습니다.
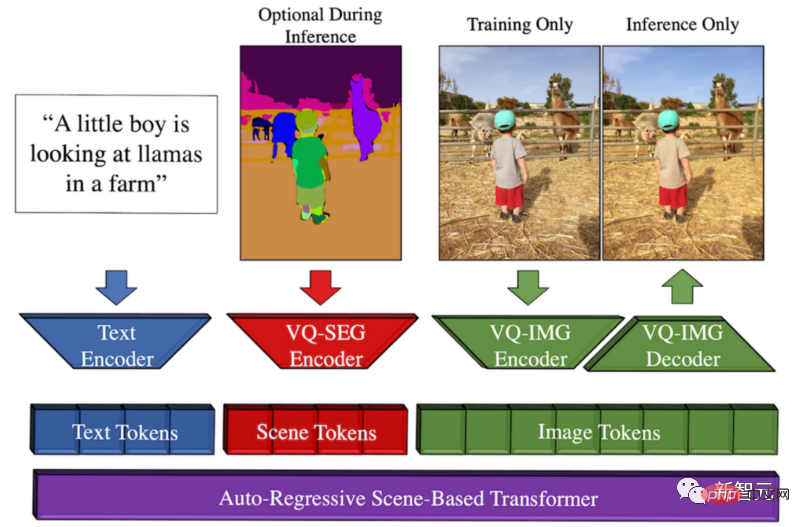
Make-A-Scene 방법 개요
이 모델의 기회는 Meta가 창의적인 표현을 촉진하고 이러한 텍스트-이미지 추세를 이전 스케치-투와 비교하기를 희망한다는 것입니다. -이미지 모델이 결합되어 텍스트와 스케치 조건 이미지 생성이 환상적인 융합을 이룹니다.
즉, 고양이를 빠르게 스케치하고 원하는 이미지를 작성할 수 있다는 뜻입니다. 스케치와 텍스트의 안내에 따라 이 모델은 몇 초 안에 우리가 원하는 완벽한 일러스트레이션을 생성합니다.

이 다중 모드 생성 AI 접근 방식은 빠른 스케치를 입력으로 사용할 수도 있으므로 생성을 더 효과적으로 제어할 수 있는 Dall-E 모델로 생각할 수 있습니다.
멀티모달이라고 불리는 이유는 텍스트, 이미지 등 다양한 형식을 입력으로 받을 수 있기 때문입니다. 반면 Dall-E는 텍스트에서만 이미지를 생성할 수 있습니다.
영상을 생성하려면 시간의 차원을 추가해야 하기 때문에 연구진은 Make-A-Scene 모델에 시공간 파이프라인을 추가했습니다.
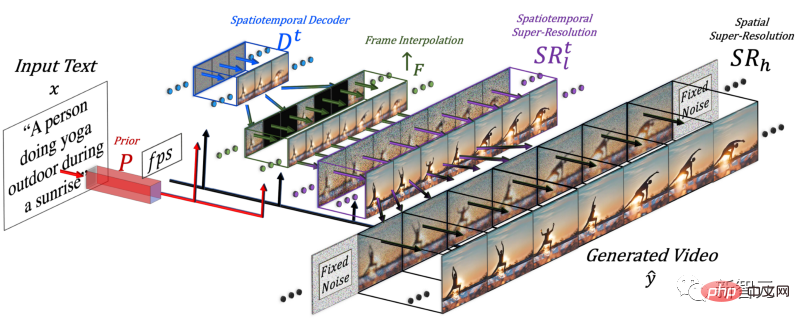
이 모델은 시간 차원을 추가한 후 단 한 장의 사진이 아닌 16장의 저해상도 사진을 생성하여 일관성 있는 짧은 동영상을 생성합니다.
이 방법은 실제로는 text-to-image 모델과 유사하지만, 차이점은 기존의 2차원 컨볼루션을 기반으로 1차원 컨볼루션을 추가한다는 점입니다.
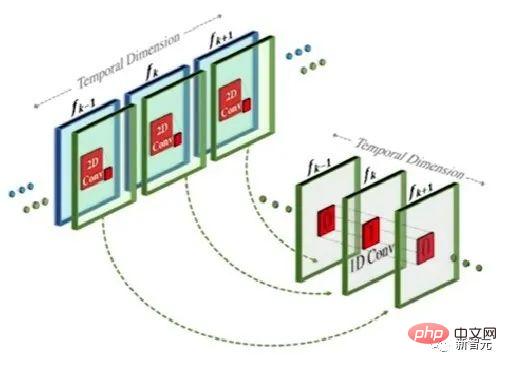
단순히 1차원 컨볼루션을 추가함으로써 연구원들은 시간적 차원을 추가하면서 미리 훈련된 2차원 컨볼루션을 변경하지 않고 유지할 수 있었습니다. 그런 다음 연구원들은 Make-A-Scene 이미지 모델의 코드와 매개변수 대부분을 재사용하여 처음부터 훈련할 수 있습니다.
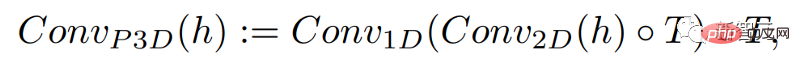
동시에 연구원들은 텍스트 입력을 사용하여 이 모델을 안내하려고 하며 이는 CLIP 임베딩을 사용하는 이미지 모델과 매우 유사합니다.
이 경우 연구원들은 텍스트 특징과 이미지 특징을 혼합할 때 공간 차원을 늘렸습니다. 방법은 위와 동일합니다. 즉, Make-A-Scene 모델에서 주의 모듈을 유지하고 1차원 차원을 추가합니다. 주의 모듈 - 이미지 생성기 모델을 복사하여 붙여넣고 한 차원 더 생성 모듈을 반복하여 16개의 초기 프레임을 얻습니다.
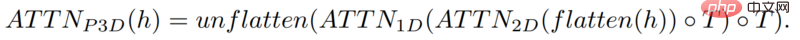
하지만 이 16개의 초기 프레임만으로는 영상을 생성할 수 없습니다.
연구원들은 이 16개의 메인 프레임으로 고화질 영상을 제작해야 합니다. 그들의 접근 방식은 이전 및 미래 프레임에 액세스하고 시간적 차원과 공간적 차원 모두에서 동시에 반복적으로 보간하는 것입니다.
이렇게 해서 이 16개의 초기 프레임 사이에 이전과 이후의 프레임을 기반으로 새롭고 더 큰 프레임을 생성하여 모션이 일관되게 되고 전체적인 영상이 매끄러워졌습니다.
이 작업은 기존 이미지를 가져와 공백을 메우고 중간 정보를 생성할 수 있는 프레임 보간 네트워크를 통해 수행됩니다. 공간 차원에서도 동일한 작업을 수행합니다. 즉, 이미지를 확대하고, 픽셀 단위의 간격을 채우고, 이미지를 더욱 고화질로 만듭니다.

요약하자면, 비디오를 생성하기 위해 연구원들은 텍스트-이미지 모델을 미세 조정했습니다. 그들은 이미 훈련된 강력한 모델을 선택하고 비디오에 적응하기 위해 조정하고 훈련했습니다.
공간 및 시간 모듈이 추가되었기 때문에 모델을 재교육할 필요 없이 이 새로운 데이터에 맞게 모델을 간단히 조정할 수 있어 많은 비용이 절약됩니다.
이러한 종류의 재교육에서는 레이블이 지정되지 않은 비디오를 사용하며 모델에게 비디오와 비디오 프레임의 일관성을 이해하도록 교육하면 되므로 데이터 세트를 더 쉽게 구축할 수 있습니다.
마지막으로 연구진은 이미지 최적화 모델을 다시 사용하여 공간 해상도를 향상시켰고, 프레임 보간 구성요소를 사용하여 더 많은 프레임을 추가하여 영상을 매끄럽게 만들었습니다.
물론, 현재 Make-A-Video의 결과에는 텍스트-이미지 모델과 마찬가지로 여전히 단점이 있습니다. 하지만 우리 모두는 AI 분야의 발전이 얼마나 빠른지 알고 있습니다.
더 알고 싶으시면 링크의 Meta AI 논문을 참고하시면 됩니다. 커뮤니티에서는 PyTorch 구현도 개발 중이므로 직접 구현하고 싶다면 계속 지켜봐 주시기 바랍니다.
본 논문에는 Yin Xi, An Jie, Zhang Songyang, Qiyuan Hu 등 다수의 중국 연구자들이 참여했습니다.
FAIR 연구 과학자 Yin Xi. 이전에는 Microsoft 클라우드 및 AI 부문 수석 애플리케이션 과학자로 Microsoft에서 근무했습니다. 그는 2013년 미시간 주립대학교 컴퓨터 과학 및 공학과에서 박사 학위를 취득했고, 우한 대학교에서 전기 공학 학사 학위를 받았습니다. 주요 연구분야는 다중모달 이해, 대규모 표적 탐지, 얼굴 추론 등이다.
Anjie는 로체스터 대학교 컴퓨터 공학과의 박사 과정 학생입니다. Roger Bo 교수 밑에서 공부하세요. 이전에는 2016년과 2019년에 북경대학교에서 학사 및 석사 학위를 받았습니다. 연구 관심 분야에는 컴퓨터 비전, 심층 생성 모델, AI+예술이 포함됩니다. Make-A-Video 연구에 인턴으로 참여했습니다.
Zhang Songyang은 로체스터 대학교 컴퓨터 공학과의 박사 과정 학생으로 Roger Bo 교수 밑에서 공부하고 있습니다. 그는 동남대학교에서 학사 학위를, 저장대학교에서 석사 학위를 받았습니다. 연구 관심 분야에는 자연어 순간 위치 파악, 감독되지 않은 문법 유도, 뼈대 기반 동작 인식 등이 포함됩니다. Make-A-Video 연구에 인턴으로 참여했습니다.
당시 FAIR의 AI 레지던트였던 Qiyuan Hu는 인간의 창의성을 향상시키는 다중 모드 생성 모델에 대한 연구에 참여했습니다. 그녀는 시카고대학교에서 의학물리학 박사학위를 취득하고 AI를 활용한 의료영상 분석 분야에 종사했습니다. 현재 Tempus Labs에서 기계 학습 과학자로 일하고 있습니다.
얼마 전 구글을 비롯한 주요 제조사들이 Parti 등 자체적인 텍스트-이미지 변환 모델을 출시했습니다.
어떤 사람들은 텍스트-비디오 생성 모델이 아직 멀었다고 생각합니다.
이번에는 의외로 메타가 폭탄을 터뜨렸습니다.
사실 오늘 ICLR 2023에 제출된 텍스트-비디오 생성 모델인 Phenaki도 있습니다. 아직 블라인드 심사 단계이기 때문에 저자의 기관은 아직 알려지지 않았습니다.

네티즌들은 DALLE부터 Stable Diffuson, Make-A-Video까지 모든 일이 너무 빨리 진행됐다고 말했습니다.

위 내용은 Meta의 혁신적인 SOTA 모델은 한 문장을 기반으로 놀라운 비디오를 생성하여 인터넷 열풍을 일으킬 수 있습니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



