

환경 인식은 자율주행의 첫 번째 연결고리이자 자동차와 환경의 연결고리입니다. 자율주행 시스템의 전반적인 성능은 인지 시스템의 품질에 크게 좌우됩니다. 현재 환경 감지 기술에는 두 가지 주류 기술 경로가 있습니다.
① 비전 주도 다중 센서 융합 솔루션, 대표적인 대표자는 Tesla입니다.
② LiDAR가 지배하고 다른 센서의 지원을 받는 기술 솔루션, 대표적인 대표자는 다음과 같습니다. 구글, 바이두 등
환경 인식 분야의 핵심적인 시각 인식 알고리즘을 소개하겠습니다. 해당 작업 범위와 기술 분야는 아래 그림과 같습니다. 아래에서는 2D 및 3D 시각 인식 알고리즘의 맥락과 방향을 검토합니다.
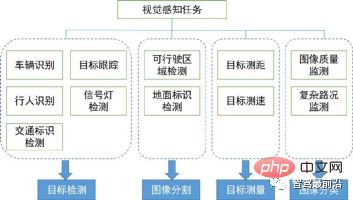
이 섹션에서는 이미지나 비디오를 기반으로 한 2D 타겟 탐지 및 추적을 포함하여 자율주행에 널리 사용되는 여러 작업을 시작으로 2D 시각 인식 알고리즘과 의미론을 먼저 소개합니다. 2D 장면 분할. 최근 몇 년 동안 딥러닝은 시각적 인식의 다양한 분야에 침투하여 좋은 결과를 얻었습니다. 따라서 우리는 몇 가지 고전적인 딥러닝 알고리즘을 정리했습니다.
1.1 2단계 탐지
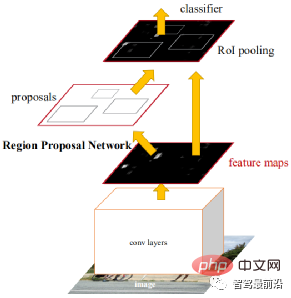
2단계 탐지 방법에는 두 가지 프로세스가 있습니다. 하나는 물체 영역을 추출하는 것입니다. 따라서 "2단계"는 지역 제안 기반 타겟 탐지라고도 합니다. 대표적인 알고리즘으로는 R-CNN 시리즈(R-CNN, Fast R-CNN, Faster R-CNN) 등이 있습니다. Faster R-CNN은 최초의 엔드투엔드 탐지 네트워크입니다. 첫 번째 단계에서는 RPN(Region Proposal Network)을 사용하여 특징 맵을 기반으로 후보 프레임을 생성하고, 두 번째 단계에서는 ROIPooling을 사용하여 후보 특징의 크기를 정렬하고 완전 연결 계층을 사용하여 개선합니다. 분류와 회귀.
여기서는 계산의 어려움을 줄이고 속도를 높이기 위해 앵커(Anchor)라는 아이디어를 제안했습니다. 기능 맵의 각 위치는 개체 프레임 회귀를 위한 참조로 사용되는 다양한 크기와 종횡비의 앵커를 생성합니다. Anchor를 도입하면 회귀 작업이 상대적으로 작은 변화만 처리할 수 있으므로 네트워크 학습이 더 쉬워집니다. 아래 그림은 Faster R-CNN의 네트워크 구조도이다.
CascadeRCNN의 첫 번째 단계는 Faster R-CNN과 완전히 동일하며 두 번째 단계에서는 계단식 연결을 위해 여러 RoiHead 레이어를 사용합니다. 후속 작업은 대부분 위에서 언급한 네트워크의 일부 개선 사항이나 이전 작업의 뒤죽박죽을 중심으로 진행되며 획기적인 개선 사항은 거의 없습니다.
1.2 단일 단계 감지
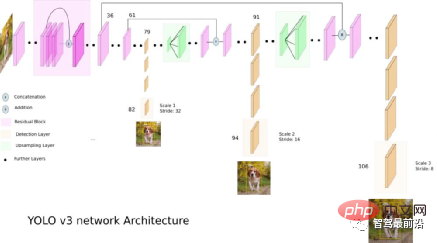
2단계 알고리즘과 비교하여 단일 단계 알고리즘은 대상 감지를 달성하기 위해 특징을 한 번만 추출하면 되며, 속도 알고리즘은 더 빠르며 일반적인 정확도는 약간 낮습니다. 이러한 유형의 알고리즘의 선구적인 작업은 SSD와 Retinanet에 의해 이후에 개선된 YOLO입니다. YOLO를 제안한 팀은 성능 향상에 도움이 되는 이러한 트릭을 YOLO 알고리즘에 통합하고 이후 4개의 개선된 버전인 YOLOv2~YOLOv5를 제안했습니다. 예측 정확도는 2단계 표적 탐지 알고리즘만큼 좋지는 않지만 YOLO는 빠른 실행 속도로 인해 업계의 주류가 되었습니다. 아래 그림은 YOLO v3의 네트워크 구조 다이어그램이다.
1.3 앵커 없는 감지(앵커 감지 없음)
이러한 유형의 방법은 일반적으로 객체를 몇 가지 키 포인트로 표현하며, 이러한 키 포인트의 위치를 반환하는 데 CNN이 사용됩니다. 키 포인트는 개체 프레임의 중심점(CenterNet), 모서리 점(CornerNet) 또는 대표점(RepPoints)이 될 수 있습니다. CenterNet은 표적 검출 문제를 중심점 예측 문제로 변환합니다. 즉, 표적의 중심점을 이용하여 표적을 표현하고, 표적 중심점의 오프셋, 너비, 높이를 예측하여 표적의 직사각형 프레임을 구합니다. Heatmap은 분류 정보를 나타내며, 각 카테고리는 별도의 Heatmap을 생성합니다. 각 히트맵에 대해 특정 좌표가 대상의 중심점을 포함하면 대상에 키 포인트가 생성됩니다. 전체 키 포인트를 표현하기 위해 가우시안 원을 사용합니다. 구체적인 내용은 다음과 같습니다.

RepPoints는 객체를 대표 점 집합으로 표현하고 변형 가능한 컨볼루션을 통해 객체의 모양 변화에 적응할 것을 제안합니다. 점 세트는 최종적으로 객체 프레임으로 변환되어 수동 주석과의 차이를 계산하는 데 사용됩니다.
1.4 변압기 감지
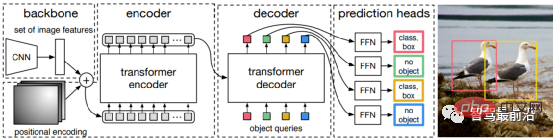
단일 단계든 2단계 표적 탐지든, 앵커 사용 여부에 관계없이 주의 메커니즘이 잘 활용되지 않습니다. 이러한 상황에 대응하여 Relation Net과 DETR은 Transformer를 사용하여 표적 탐지 분야에 주의 메커니즘을 도입합니다. Relation Net은 Transformer를 사용하여 서로 다른 대상 간의 관계를 모델링하고 관계 정보를 기능에 통합하며 기능 향상을 달성합니다. DETR은 Transformer 기반의 새로운 표적 탐지 아키텍처를 제안하여 표적 탐지의 새로운 시대를 열었습니다. 다음 그림은 DETR의 알고리즘 프로세스를 먼저 사용하여 이미지 특징을 추출한 다음 Transformer를 사용하여 전역 공간 관계를 모델링합니다. 마지막으로, 이분 그래프 매칭 알고리즘을 통해 의 출력이 수동 주석과 일치합니다.
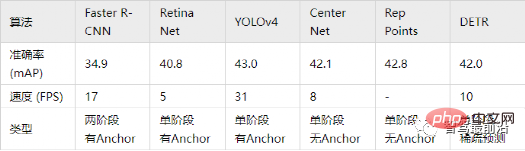
아래 표의 정확도는 MS COCO 데이터베이스의 mAP를 지표로 사용하는 반면 속도는 FPS로 측정됩니다. 위의 일부 알고리즘과 비교하면 네트워크의 구조 설계에는 다양한 선택이 있습니다. (예: 다양한 입력 크기, 다양한 백본 네트워크 등), 각 알고리즘의 구현 하드웨어 플랫폼도 다르기 때문에 정확도와 속도가 완전히 비교할 수는 없습니다. 다음은 참고용으로 대략적인 결과입니다.
자율주행 애플리케이션에서 입력은 영상 데이터이며, 차량, 보행자, 자전거 등 주의가 필요한 타겟이 많습니다. 따라서 이는 일반적인 다중 개체 추적 작업(MOT)입니다. MOT 작업의 경우 현재 가장 널리 사용되는 프레임워크는 Tracking-by-Detection이며 그 프로세스는 다음과 같습니다.
① 대상 탐지기는 단일 프레임 이미지에서 대상 프레임 출력을 얻습니다.
② 감지된 각 대상의 특징을 추출합니다. , 일반적으로 시각적 특징과 모션 특징을 포함합니다.
③ 특징을 기반으로 인접한 프레임의 타겟 감지 간의 유사성을 계산하여 동일한 타겟에서 나올 확률을 결정합니다.
④ 인접한 프레임의 타겟 감지를 일치시키고 개체를 할당합니다. 동일한 대상에서 동일한 ID.
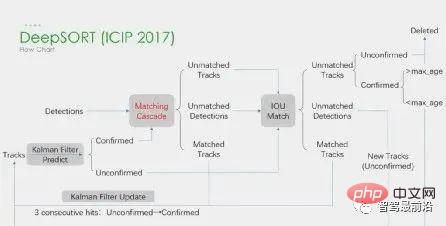
위의 4단계 모두 딥러닝이 적용되는데, 처음 2단계가 주요 단계입니다. 1단계에서는 딥러닝의 적용이 주로 고품질 물체 감지기를 제공하는 것이므로 일반적으로 정확도가 높은 방법이 선택됩니다. SORT는 Faster R-CNN 기반의 표적 탐지 방법으로, Kalman 필터 알고리즘 + 헝가리어 알고리즘을 사용하여 다중 표적 추적 속도를 크게 향상시키고 SOTA의 정확도를 달성하기도 합니다. 연산. 2단계에서 딥러닝의 적용은 주로 CNN을 사용하여 객체의 시각적 특징을 추출하는 데 의존합니다. DeepSORT의 가장 큰 특징은 모양 정보를 추가하고 ReID 모듈을 빌려 딥러닝 기능을 추출함으로써 ID 전환 횟수를 줄이는 것입니다. 전체적인 흐름도는 다음과 같습니다.
또한 동시 탐지 및 추적 프레임워크도 있습니다. 앞서 소개한 단일 스테이지 앵커리스 감지 알고리즘인 CenterNet에서 유래한 대표적인 CenterTrack 등이 있습니다. CenterNet과 비교하여 CenterTrack은 이전 프레임의 RGB 이미지와 개체 중심 Heatmap을 추가 입력으로 추가하고 이전 프레임과 다음 프레임 간의 연결을 위해 Offset 분기를 추가합니다. 다단계 탐지별 추적과 비교하여 CenterTrack은 네트워크를 사용하여 탐지 및 일치 단계를 구현하므로 MOT 속도가 향상됩니다.
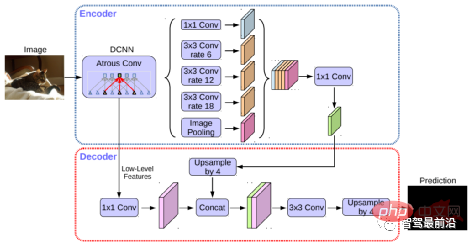
의미론적 분할은 자율주행의 차선 검출과 주행 가능 영역 검출 작업 모두에 사용됩니다. 대표적인 알고리즘으로는 FCN, U-Net, DeepLab 시리즈 등이 있습니다. DeepLab은 Dilated Convolution과 ASPP(Atrous Spatial Pyramid Pooling) 구조를 사용하여 입력 이미지에 대해 다중 규모 처리를 수행합니다. 마지막으로 전통적인 의미 분할 방법에서 일반적으로 사용되는 조건부 무작위 필드(CRF)를 사용하여 분할 결과를 최적화합니다. 아래 그림은 DeepLab v3+의 네트워크 구조입니다.
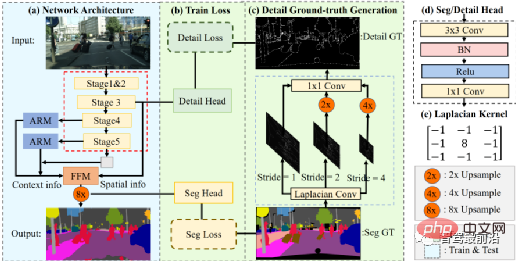
최근 STDC 알고리즘은 FCN 알고리즘과 유사한 구조를 채택하여 U-Net 알고리즘의 복잡한 디코더 구조를 제거했습니다. 그러나 동시에 네트워크 다운샘플링 과정에서 ARM 모듈은 서로 다른 레이어 특징 맵의 정보를 지속적으로 융합하는 데 사용되므로 단일 픽셀 관계만 고려하는 FCN 알고리즘의 단점을 피할 수 있습니다. STDC 알고리즘은 속도와 정확성 사이의 적절한 균형을 달성하고 자율 주행 시스템의 실시간 요구 사항을 충족할 수 있다고 말할 수 있습니다. 알고리즘 흐름은 아래 그림과 같습니다.
이번 섹션에서는 자율주행에 필수적인 3D 장면 인식에 대해 소개하겠습니다. 2차원 인식으로는 깊이 정보, 목표물의 3차원 크기 등을 얻을 수 없기 때문에 이 정보는 자율주행 시스템이 주변 환경을 정확하게 판단하는 데 핵심이 된다. 3D 정보를 얻는 가장 직접적인 방법은 LiDAR를 사용하는 것입니다. 그러나 LiDAR에는 높은 비용, 자동차급 제품의 대량 생산이 어렵고 날씨의 영향이 더 크다는 등의 단점도 있습니다. 따라서 카메라만을 기반으로 한 3D 인식은 여전히 매우 의미 있고 가치 있는 연구 방향이다. 다음으로 단안 및 쌍안 기반의 3D 인식 알고리즘을 정리한다.
단일 카메라 이미지를 기반으로 3D 환경을 인식하는 것은 잘못된 문제이지만 기하학적 가정(예: 지상의 픽셀), 사전 지식 또는 일부 추가 정보를 통해 해결할 수 있습니다. (깊이 추정 등) 문제 해결에 도움이 됩니다. 이번에는 자율주행을 구현하는 두 가지 기본 작업(3D 타겟 탐지 및 깊이 추정)부터 시작하여 관련 알고리즘을 소개하겠습니다.
1.1 3D 타겟 감지
표현 변환(유사 라이더): 시각 센서를 통한 다른 주변 차량 감지는 일반적으로 거리 측정 불가능 및 폐쇄와 같은 문제에 직면합니다. 조감도. 여기서는 두 가지 변환 방법을 소개합니다. 첫 번째는 IPM(Inverse Perspective Mapping)으로, 모든 픽셀이 지면에 있고 카메라 외부 매개변수가 정확하다고 가정합니다. 이때 Homography 변환을 사용하여 이미지를 BEV로 변환할 수 있으며, 이후 이를 기반으로 하는 방법이 있습니다. YOLO 네트워크는 대상의 지상 프레임을 감지하는 데 사용됩니다. 두 번째는 OFT(Orthogonal Feature Transform)로, ResNet-18을 사용하여 원근 이미지 특징을 추출합니다. 그러면 투영된 복셀 영역에 걸쳐 이미지 기반 특징을 축적하여 복셀 기반 특징이 생성됩니다.
복셀 형상은 수직으로 접어서 직교 접지면 형상을 생성합니다. 마지막으로 ResNet과 유사한 또 다른 하향식 네트워크가 3D 객체 감지에 사용됩니다. 이 방법은 지면에 가까이 있는 차량과 보행자에게만 적합합니다. 교통표지판, 신호등 등 지상이 아닌 대상의 경우 3차원 탐지를 위한 깊이 추정을 통해 의사 포인트 클라우드를 생성할 수 있습니다. Pseudo-LiDAR는 먼저 깊이 추정 결과를 사용하여 포인트 클라우드를 생성한 다음 LiDAR 기반 3D 타겟 검출기를 직접 적용하여 3D 타겟 프레임을 생성합니다. 알고리즘 흐름은 아래 그림과 같습니다.

핵심 사항 및 3차원 모델 : 검출 차량, 보행자 등 대상의 크기와 형태는 상대적으로 고정되어 알려져 있어 대상의 3차원 정보를 추정하기 위한 사전 지식으로 활용될 수 있다. DeepMANTA는 이러한 방향의 선구적인 작품 중 하나입니다. 먼저 Faster RNN과 같은 일부 표적 탐지 알고리즘을 사용하여 2D 표적 프레임을 획득하고 표적의 핵심 지점도 탐지합니다. 그런 다음, 이러한 2D 타겟 프레임과 키 포인트를 데이터베이스에 있는 다양한 3D 차량 CAD 모델과 매칭하고, 유사도가 가장 높은 모델을 3D 타겟 탐지 출력으로 선택합니다. MonoGRNet은 단안 3D 타겟 탐지를 2D 타겟 탐지, 인스턴스 수준 깊이 추정, 투영된 3D 중심 추정 및 로컬 코너 회귀의 네 단계로 나눌 것을 제안합니다. 알고리즘 흐름은 아래 그림에 나와 있습니다. 이 유형의 방법은 대상이 상대적으로 고정된 형상 모델을 가지고 있다고 가정하므로 일반적으로 차량에는 적합하지만 보행자에게는 상대적으로 어렵습니다.
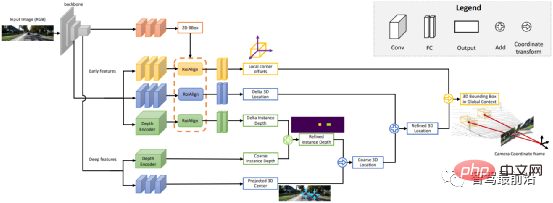
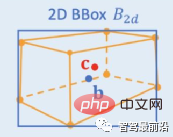
2D/3D 기하학적 제약 조건: 3D 중심의 투영과 거친 인스턴스 깊이를 회귀하고 두 가지를 모두 사용하여 거친 3D 위치를 추정합니다. 선구적인 작업은 Deep3DBox로, 먼저 2D 대상 상자 내의 이미지 기능을 사용하여 대상 크기와 방향을 추정합니다. 그런 다음 중심점의 3D 위치는 2D/3D 기하학적 구속조건을 통해 해결됩니다. 이러한 제약은 이미지 상의 3D 타겟 프레임의 투영이 2D 타겟 프레임에 의해 밀접하게 둘러싸여 있다는 것입니다. 즉, 3D 타겟 프레임의 적어도 하나의 꼭지점이 2D 타겟 프레임의 각 측면에서 발견될 수 있습니다. 이전에 예측된 크기와 방향을 카메라의 보정 매개변수와 결합하여 중심점의 3D 위치를 계산할 수 있습니다. 2D 및 3D 대상 상자 사이의 기하학적 구속조건은 아래 그림에 표시됩니다. Deep3DBox를 기반으로 Shift R-CNN은 이전에 얻은 2D 타겟 상자, 3D 타겟 상자 및 카메라 매개변수를 입력으로 결합하고 완전히 연결된 네트워크를 사용하여 보다 정확한 3D 위치를 예측합니다.
직접 3DBox 생성: 이 방법은 조밀한 3D 대상 후보 상자에서 시작하여 2D 이미지의 특징을 기반으로 모든 후보 상자에 점수를 매깁니다. 점수가 가장 높은 후보 상자가 최종 출력입니다. 표적 탐지의 전통적인 슬라이딩 윈도우 방법과 다소 유사합니다. 대표적인 Mono3D 알고리즘은 먼저 대상의 이전 위치(z 좌표가 지상에 있음)와 크기를 기반으로 조밀한 3D 후보 상자를 생성합니다. 이러한 3D 후보 프레임을 이미지 좌표에 투영한 후 2D 이미지의 특징을 통합하여 점수를 매긴 후 CNN을 통해 2차 점수 매기기를 수행하여 최종 3D 대상 프레임을 얻습니다.
M3D-RPN은 2D 및 3D 앵커를 정의하는 앵커 기반 방법입니다. 2D Anchor는 영상에 대한 Dense Sampling을 통해 얻어지고, 3D Anchor는 트레이닝 세트 데이터(타겟의 실제 크기의 평균 등)에 대한 사전 지식을 통해 결정됩니다. M3D-RPN은 또한 표준 컨볼루션과 깊이 인식 컨볼루션을 모두 사용합니다. 전자는 공간 불변성을 가지며 후자는 이미지의 행(Y 좌표)을 여러 그룹으로 나눕니다. 각 그룹은 서로 다른 장면 깊이에 해당하며 서로 다른 컨볼루션 커널에 의해 처리됩니다. 위의 조밀한 샘플링 방법은 계산 집약적입니다. SS3D는 이미지의 각 관련 객체에 대한 중복 표현과 해당 불확실성 추정치를 출력하기 위한 CNN과 3D 경계 상자 최적화 기능을 포함하여 보다 효율적인 단일 단계 감지를 사용합니다. FCOS3D 역시 단일 단계 검출 방법으로, 회귀 대상은 3D 대상 프레임의 중심을 2D 이미지에 투영하여 얻은 추가 2.5D 중심(X, Y, 깊이)을 추가합니다.
1.2 깊이 추정
위에서 언급한 3D 타겟 탐지 또는 2D에서 3D로 확장되는 자율 주행 인식-의미론적 세분화의 또 다른 중요한 작업이든 둘 다 희박하거나 조밀한 깊이 정보에 어느 정도 적용됩니다. . 단안 깊이 추정의 중요성은 자명합니다. 입력은 이미지이고 출력은 각 픽셀에 해당하는 장면 깊이 값으로 구성된 동일한 크기의 이미지입니다. 입력은 깊이 추정의 정확성을 향상시키기 위해 카메라나 물체 움직임으로 가져온 추가 정보를 사용하는 비디오 시퀀스일 수도 있습니다. 지도 학습과 비교하여 비지도 단안 깊이 추정 방법은 까다로운 실측 데이터 세트를 구성할 필요가 없으며 구현하기가 덜 어렵습니다. 단안 깊이 추정을 위한 비지도 방법은 단안 비디오 시퀀스 기반과 동기화된 스테레오 이미지 쌍 기반의 두 가지 유형으로 나눌 수 있습니다.
전자는 움직이는 카메라와 정적인 장면을 가정한 것입니다. 후자의 방법에서는 Garg et al.이 먼저 영상 재구성을 위해 입체 보정된 쌍안 영상 쌍을 사용하려고 시도했으며, 양안 판별을 통해 왼쪽 뷰와 오른쪽 뷰 간의 포즈 관계를 얻었으며 비교적 이상적인 효과를 얻었습니다. 이를 기반으로 Godard et al.은 정확도를 더욱 향상시키기 위해 왼쪽 및 오른쪽 일관성 제약 조건을 사용했습니다. 그러나 수용 필드를 높이기 위해 레이어별 다운샘플링을 통해 고급 특징을 추출하는 동안 특징 해상도도 지속적으로 감소하고 세분성도 감소합니다. 지속적으로 손실되어 깊은 디테일 처리 및 가장자리 선명도에 영향을 미칩니다.
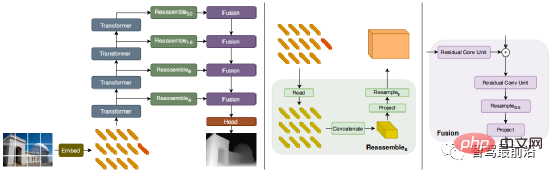
이 문제를 완화하기 위해 Godard 등은 텍스처가 낮은 영역에서 블랙홀과 텍스처 복제 아티팩트를 효과적으로 줄이는 전체 해상도 다중 스케일 손실을 도입했습니다. 그러나 이러한 정확도 향상은 여전히 제한적입니다. 최근 일부 Transformer 기반 모델이 모든 단계에서 전역 수용 필드를 획득하는 것을 목표로 끝없는 흐름으로 등장했으며 이는 집중적인 깊이 추정 작업에도 매우 적합합니다. 지도형 DPT에서는 예측의 지역적 정확성과 전역적 일관성을 동시에 보장하기 위해 Transformer와 다중 규모 구조를 사용하는 것이 제안됩니다. 다음 그림은 네트워크 구조 다이어그램입니다.
양안시는 관점 변환으로 인한 모호함을 해소할 수 있으므로 이론적으로는 3D 인식의 정확도를 향상시킬 수 있습니다. 그러나 쌍안경 시스템은 하드웨어와 소프트웨어 측면에서 상대적으로 높은 요구 사항을 가지고 있습니다. 하드웨어적인 측면에서는 정확하게 등록된 카메라 2대가 필요하며, 차량 운행 중에 등록의 정확성이 보장되어야 합니다. 소프트웨어 측면에서 알고리즘은 두 대의 카메라의 데이터를 동시에 처리해야 하며 계산 복잡성이 높고 알고리즘의 실시간 성능을 보장하기 어렵습니다. 단안에 비해 양안 작업은 상대적으로 적습니다. 다음으로 3차원 타겟 탐지와 깊이 추정의 두 가지 측면에 대해서도 간략하게 소개하겠습니다.
2.1 3D 개체 감지
3DOP는 Fast R-CNN 방식을 3D 분야로 확장한 2단계 검출 방식입니다. 먼저, 쌍안경 이미지를 사용하여 깊이 맵을 포인트 클라우드로 변환한 다음 그리드 데이터 구조로 정량화하여 3D 타겟에 대한 후보 프레임을 생성합니다. 이전에 소개된 Pseudo-LiDAR과 유사하게 조밀한 깊이 맵(단안, 쌍안 또는 심지어 적은 선 수의 LiDAR까지)이 포인트 클라우드로 변환된 다음 포인트 클라우드 표적 탐지 분야의 알고리즘이 적용됩니다. DSGN은 스테레오 매칭을 활용하여 평면 스캔 볼륨을 구성하고 3D 기하학 및 의미 정보를 인코딩하기 위해 이를 3D 기하학으로 변환합니다. 이는 스테레오 매칭 및 고급 객체 인식 기능을 위해 픽셀 수준의 특징을 추출할 수 있는 엔드투엔드 프레임워크입니다. , 장면 깊이를 추정하는 동시에 3D 개체를 감지할 수 있습니다. 스테레오 R-CNN은 스테레오 입력을 위해 Faster R-CNN을 확장하여 왼쪽 및 오른쪽 뷰에서 객체를 동시에 감지하고 상관시킵니다. 희소 키포인트, 시점 및 객체 크기를 예측하기 위해 RPN 뒤에 추가 분기가 추가되고 왼쪽 및 오른쪽 뷰의 2D 경계 상자를 결합하여 거친 3D 객체 경계 상자를 계산합니다. 그런 다음 왼쪽과 오른쪽 관심 영역의 영역 기반 측광 정렬을 사용하여 정확한 3D 경계 상자를 복구합니다. 아래 그림은 해당 네트워크 구조입니다.
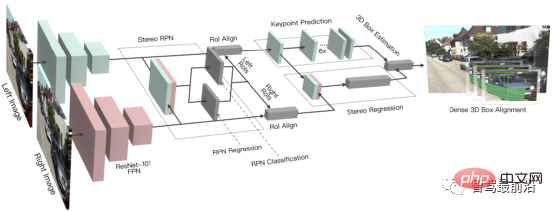
2.2 깊이 추정
양안 깊이 추정의 원리는 매우 간단합니다. 이는 왼쪽과 오른쪽 뷰에서 동일한 3D 점 사이의 픽셀 거리 d를 기반으로 합니다(두 카메라가 동일하게 유지된다는 가정). 높이이므로 가로 방향만 거리로 간주됩니다. 즉, 시차, 카메라의 초점 거리 f, 두 카메라 사이의 거리 B(기준선 길이)를 사용하여 3D 점의 깊이를 추정합니다. 시차를 추정하여 깊이를 계산할 수 있습니다. 그런 다음, 여러분이 해야 할 일은 각 픽셀에 대해 다른 이미지에서 일치하는 지점을 찾는 것뿐입니다.

가능한 각 d에 대해 각 픽셀의 매칭 오류를 계산할 수 있으므로 3차원 오류 데이터 Cost Volume을 얻을 수 있습니다. Cost Volume을 통해 각 픽셀의 시차(최소 매칭 오류에 해당하는 d)를 쉽게 얻을 수 있으며 이를 통해 깊이 값을 얻을 수 있습니다. MC-CNN은 컨볼루션 신경망을 사용하여 두 이미지 패치의 일치 정도를 예측하고 이를 사용하여 스테레오 일치 비용을 계산합니다. 교차 기반 비용 집계 및 반전역 매칭을 통해 비용을 세분화한 후 좌우 일관성 검사를 통해 폐색된 영역의 오류를 제거합니다. PSMNet은 후처리가 필요하지 않은 스테레오 매칭을 위한 엔드투엔드 학습 프레임워크를 제안하고, 글로벌 컨텍스트 정보를 이미지 특징에 통합하는 피라미드 풀링 모듈을 도입하고, 글로벌 정보를 더욱 향상시키기 위해 누적 모래시계 3D CNN을 제공합니다. 아래 그림은 네트워크 구조입니다.
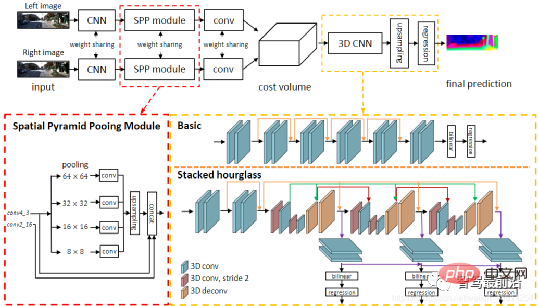
위 내용은 자율주행 분야의 2D 및 3D 시각 인식 알고리즘에 대한 심층적 논의의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



