

본 글은 AI 뉴미디어 큐빗(공개 계정 ID: QbitAI)의 승인을 받아 재인쇄되었습니다.
2020년 6월, OpenAI는 수천억 개의 매개변수의 규모와 놀라운 언어 처리 능력으로 국내 AI 커뮤니티에 큰 충격을 안겨준 GPT-3를 출시했습니다. 하지만 GPT-3가 국내 시장에 개방되어 있지 않기 때문에 해외에서 텍스트 생성 서비스를 제공하는 상용 기업이 다수 탄생하게 되면 우리는 뒤돌아 한숨을 쉬게 될 뿐입니다.
올해 8월, 런던의 오픈소스 기업인 Stability AI는 Vincent 그래프 모델인 Stable Diffusion을 출시하고, 모델의 가중치와 코드를 자유롭게 오픈소스화하여 폭발적인 성장을 이끌었습니다. 전 세계의 AI 페인팅 애플리케이션.
올해 하반기 AIGC 붐에 오픈소스가 직접적인 촉매 역할을 했다고 할 수 있다.
그리고 대형 모델이 모두가 참여할 수 있는 게임이 되면 AIGC만이 혜택을 받는 것은 아닙니다.
4년 전, 3억 개의 매개변수로 AI 모델의 게임 규칙을 바꾸는 BERT라는 언어 모델이 나왔습니다.
오늘날 AI 모델의 양은 수조 달러로 뛰어올랐지만 대형 모델의 "독점"도 점점 두드러졌습니다.
대기업, 대규모 컴퓨팅 파워, 강력한 알고리즘 모델이 함께하면 일반 개발자와 중소기업이 뚫기 힘든 벽을 쌓는다.
대형 모델을 훈련하고 사용하는 데 필요한 컴퓨팅 리소스와 인프라뿐만 아니라 기술적 장벽으로 인해 대형 모델을 "정제"하는 것에서 대형 모델을 "사용"하는 데 방해가 됩니다. 그래서 오픈소스가 시급하다. 오픈 소스를 통해 더 많은 사람들이 대형 모델 게임에 참여할 수 있도록 하고, 신흥 AI 기술에서 대형 모델을 강력한 인프라로 전환하는 것은 많은 대형 모델 제작자의 합의가 되고 있습니다.
얼마 전 Yunqi 컨퍼런스에서 알리바바 다모 아카데미가 론칭한 중국 모델 오픈소스 커뮤니티 '모델스코프'가 AI 업계에서 큰 주목을 받기 시작한 것도 이러한 공감대 아래서다. 커뮤니티에 모델을 제공하거나 자체 오픈 소스 모델 시스템을 구축하세요.
현재 국내보다 해외 대형모델 오픈소스 생태시공이 앞서있습니다. Stability AI는 민간 기업으로 탄생했지만 자체적인 오픈소스 유전자를 보유하고 있으며 자체적으로 거대한 개발자 커뮤니티를 보유하고 있으며 오픈소스이면서 안정적인 수익 모델을 갖추고 있습니다.
올해 7월에 출시된 BLOOM은 1,760억 개의 매개변수를 보유하고 있으며 현재 최대 규모의 오픈소스 언어 모델입니다. 그 뒤에 숨은 BigScience는 오픈소스 정신과 완벽하게 부합하며 머리부터 발끝까지 기술 경쟁의 추진력을 드러냅니다. 거인. 빅사이언스(BigScience)는 허깅페이스(Huggingface)가 주도하는 개방형 협업 조직으로, 공식적으로 설립된 법인은 아니다. 블룸의 탄생은 70여 개국 1,000명 이상의 연구진이 117일 동안 슈퍼컴퓨터를 훈련한 결과이다.
또한 거대 기술 기업들이 대형 모델의 오픈 소스에 참여하지 않은 것은 아닙니다. 올해 5월 메타는 1,750억 개의 매개변수를 갖춘 대형 모델 OPT를 오픈소스화했으며, OPT를 비상업적 목적으로 사용할 수 있도록 허용한 것 외에도 훈련 과정을 기록한 100페이지의 로그도 공개했다고 할 수 있습니다. 오픈 소스가 매우 철저하다는 것입니다.
연구팀은 OPT 논문 요약에서 "계산 비용을 고려할 때 이러한 모델은 상당한 자금 없이 복제하기 어렵습니다. API를 통해 사용할 수 있는 소수 모델의 경우 전체 모델에 접근할 수 없습니다."라고 직설적으로 지적했습니다. 무게가 있어서 공부하기가 어렵습니다." 모델의 풀네임 'Open Pre-trained Transformers' 역시 메타의 오픈소스 태도를 보여준다. 이는 '오픈'이 아닌(API 유료 서비스만 제공) OpenAI가 출시한 GPT-3와 올해 4월 구글이 출시한 5,400억 매개변수 대형 모델 PaLM(오픈소스 아님)을 암시하는 것이라고 할 수 있다. .
독점의식이 강한 대기업들 사이에서 메타의 오픈소스 움직임은 신선한 바람이다. 당시 스탠포드 대학의 기본 모델 연구 센터 소장인 Percy Liang은 다음과 같이 말했습니다. "이것은 연구를 위한 새로운 기회를 여는 흥미로운 단계입니다. 일반적으로 우리는 더 큰 개방성이 연구자들이 문제를 해결할 수 있게 해준다고 생각할 수 있습니다. 더 깊은 질문 . "
Percy Liang의 말은 왜 대형 모델이 오픈 소스여야 하는지에 대한 학문적 차원의 질문이기도 합니다.
독창적인 성과의 탄생에는 토양을 제공하는 오픈 소스가 필요합니다.
A R&D 팀이 주요 컨퍼런스에서 논문을 발표하는 것을 중단하면 다른 모든 연구자들은 자세한 내용을 보지 않고도 논문의 다양한 "근육을 보여주는" 수치를 얻게 됩니다. 모델 훈련 기술은 시간을 들여서만 재현할 수 있으며 성공하지 못할 수도 있습니다. 재현성은 과학적 연구 결과의 신뢰성과 신뢰성을 보장합니다. 개방형 모델, 코드 및 데이터 세트를 통해 과학 연구자는 보다 시기적절하게 최첨단 연구를 따라갈 수 있으며 거대 기업의 어깨에 올라 새로운 혁신을 이룰 수 있습니다. 높은 곳의 열매는 많은 시간과 비용을 절약하고 기술 혁신을 가속화할 수 있습니다.
중국 대형 모델 작업의 독창성 부족은 주로 모델 크기에 대한 맹목적인 추구에 반영되지만 기본 아키텍처에는 혁신이 거의 없습니다. 이것은 업계 전문가들 사이에서 흔히 나타나는 현상입니다. 대규모 모델 연구 합의에서.
칭화대학교 컴퓨터과학과 Liu Zhiyuan 부교수는 AI Technology Review에서 다음과 같이 지적했습니다. 중국의 대형 모델 아키텍처에 대한 비교적 혁신적인 작품이 있지만 기본적으로 Transformer를 기반으로 하고 있습니다. 중국에는 여전히 유사한 Transformer가 부족합니다. BERT 및 GPT-3과 같은 모델뿐만 아니라 이 기본 아키텍처는 현장에서 큰 변화를 일으킬 수 있습니다.
IDEA 연구소(광둥-홍콩-마카오 Greater Bay Area Digital Economy Research Institute)의 수석 과학자인 Zhang Jiaxing 박사도 AI Technology Review에 다음과 같이 말했습니다. 우리는 다양한 시스템과 엔지니어링 분야에서 획기적인 발전을 이루었습니다. 도전에 직면한 후에는 단순히 모델을 더 크게 만드는 것이 아니라 새로운 모델 구조를 생각해야 합니다.
한편, 대형 모델이 기술적 진보를 이루기 위해서는 일련의 모델 평가 기준이 필요하고, 그 기준을 만드는 데에는 개방성과 투명성이 필요합니다. 최근 일부 연구에서는 많은 대형 모델에 대한 다양한 평가 지표를 제안하려고 시도하고 있지만 접근성이 좋지 않아 우수한 모델 중 일부가 제외되었습니다. 예를 들어 Pathways 아키텍처로 훈련된 Google의 대형 모델 PaLM은 슈퍼 언어 이해 기능을 쉽게 설명할 수 있습니다. 농담이며 DeepMind의 대규모 언어 모델 Chinchilla는 오픈 소스가 아닙니다.
하지만 모델 자체의 뛰어난 성능 때문이든, 이들 메이저 제조사의 위상 때문이든, 이런 공정한 경쟁의 장에서 빠질 수는 없습니다.
안타까운 사실은 Percy Liang과 그의 동료들의 최근 연구에 따르면 비 오픈 소스 모델과 비교할 때 많은 핵심 시나리오에서 현재 오픈 소스 모델의 성능에 일정한 차이가 있다는 것입니다. Tsinghua University의 OPT-175B, BLOOM-176B 및 GLM-130B와 같은 오픈 소스 대형 모델은 OpenAI의 InstructGPT, Microsoft/NVIDIA의 TNLG-530B 등을 포함한 다양한 작업에서 비오픈 소스 대형 모델에 거의 완전히 패했습니다(그림 참조). 아래에).
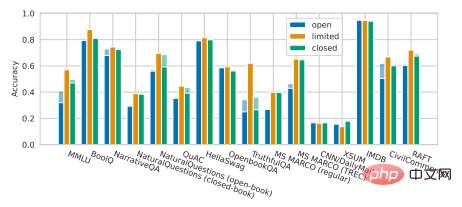
그림: Percy Liang et al. 언어 모델의 전체적인 평가
이 당황스러운 상황을 해결하려면 각 리더는 대규모 모델과 같은 고품질 대형 모델을 오픈 소스로 제공해야 합니다. 모델링 분야의 전반적인 발전이 있어야만 다음 단계로 더 빨리 나아갈 수 있습니다.
대형 모델의 산업적 구현 측면에서는 오픈 소스가 유일한 방법입니다.
GPT-3 출시를 기점으로 2년여 간의 추격 끝에 대형 모델들은 연구개발 기술 측면에서 더욱 성숙해졌습니다. , 전 세계적으로 대형 모델 개발은 아직 초기 단계입니다. 국내 주요 제조업체가 개발한 대형 모델에는 내부 비즈니스 구현 시나리오가 있지만 아직 전체적으로 성숙한 상용화 모델이 없습니다.
대규모 모델 구현이 탄력을 받을 때 오픈 소스를 잘 활용하면 향후 대규모 구현 생태계의 기반을 마련할 수 있습니다.
대형 모델의 특성에 따라 구현을 위한 오픈 소스의 필요성이 결정됩니다. Alibaba Damo Academy 부국장 Zhou Jingren은 AI Technology Review에 "대형 모델은 인간 지식 시스템의 추상화 및 개선이므로 적용할 수 있는 시나리오와 생성되는 가치는 엄청납니다. 그리고 오픈 소스를 통해서만 가능합니다."라고 말했습니다. 많은 창의적인 개발자가 응용 가능성을 극대화할 수 있습니다.
이것은 대형 모델의 내부 기술적인 세부 사항을 닫는 API 모델이 할 수 없는 일입니다. 우선 이 모델은 개발 능력이 낮은 모델 사용자에게 적합합니다. 이들에게 대형 모델 구현의 성공 여부는 전적으로 R&D 기관의 손에 달려 있는 것과 같습니다.
대형 모델 API 유료 서비스를 제공하는 최대 승자 OpenAI를 예로 들면, OpenAI 통계에 따르면 현재 전 세계적으로 GPT-3 기술을 사용하는 애플리케이션이 300개 이상 있지만 이는 전제입니다. OpenAI의 연구 개발 역량은 충분히 강력하고 GPT-3도 충분히 강력합니다. 모델 자체의 성능이 좋지 않으면 그러한 개발자는 무력합니다.
더 중요한 것은 대형 모델이 개방형 API를 통해 제공할 수 있는 기능이 제한되어 복잡하고 다양한 애플리케이션 요구 사항을 처리하기 어렵다는 것입니다. 현재 시장에는 몇 가지 창의적인 앱만 있지만 전체적으로는 아직 '장난감' 단계에 있으며 대규모 산업화 단계에 도달하기에는 거리가 멀습니다.
"창출되는 가치는 그다지 크지 않고 비용도 회수할 수 없기 때문에 GPT-3 API를 기반으로 한 적용 시나리오는 매우 제한적입니다. 업계의 많은 사람들은 실제로 이러한 접근 방식을 인식하지 못합니다." 가흥이 말했다. 실제로 copy.ai, Jasper 등 외국 기업은 AI 기반 글쓰기 사업을 선택하고 있습니다. 사용자 시장이 상대적으로 크기 때문에 상대적으로 큰 상업적 가치를 창출할 수 있는 반면, 소규모 애플리케이션이 더 많습니다.
반면 오픈소스는 "사람들에게 낚시하는 방법을 가르치는 것"에 관한 것입니다.
오픈 소스 모델에서 기업은 오픈 소스 코드를 사용하여 기존 기본 프레임워크를 기반으로 자체 비즈니스 요구 사항을 충족하는 교육 및 2차 개발을 수행합니다. 이를 통해 대규모의 다양성 이점을 최대한 활용할 수 있습니다. 현재 수준을 뛰어넘는 생산성은 결국 업계에서 진정한 대형 모델 기술의 구현으로 이어질 것입니다.
현재 대형 모델 상용화의 가장 뚜렷한 경로로 AIGC의 도약은 대형 모델의 오픈 소스 모델의 성공을 확인했습니다. 그러나 다른 추가 응용 시나리오에서는 공개가 가능합니다. 대형 모델의 원천 개방성은 국내외를 막론하고 여전히 소수이다. West Lake University의 Deep Learning Laboratory 소장인 Lan Zhenzhong은 AI Technology Review에 대형 모델에 대한 결과는 많지만 오픈 소스가 거의 없고 일반 연구자에 대한 접근이 제한되어 있어 매우 유감스럽다고 말했습니다.
기여, 참여 및 협업 이러한 키워드를 핵심으로 하는 오픈 소스는 많은 열정적인 개발자를 모아 잠재적으로 혁신적인 대형 모델 프로젝트를 공동으로 만들 수 있으며 대형 모델이 실험에서 실험으로 더 빠르게 전환될 수 있습니다. .산업으로의 공간.
대형 모델에 있어서 오픈 소스의 중요성은 모두가 공감하지만 오픈 소스로 가는 길에는 여전히 큰 장애물이 있습니다: 컴퓨팅 파워.
이것은 현재 대형 모델 구현이 직면한 가장 큰 과제이기도 합니다. Meta가 OPT를 오픈소스로 공개했음에도 아직까지는 애플리케이션 시장에서 큰 파급력을 일으키지 못한 것 같습니다. 결국, 대규모 모델의 미세 조정, 2차 개발은커녕 소규모 개발자가 감당할 수 없는 컴퓨팅 파워 비용이 여전히 발생하고 있습니다. , 추론만으로는 매우 어렵습니다.
이 때문에 많은 R&D 기관에서는 매개 변수에 대한 반성의 물결 속에서 수억에서 수십억 사이에서 모델의 매개 변수를 제어하면서 경량 모델을 만드는 아이디어로 전환했습니다. Lanzhou Technology에서 출시한 'Mencius' 모델과 IDEA 연구소에서 오픈소스로 공개한 'Fengshen Bang' 시리즈 모델은 모두 이 노선의 국내 대표 모델입니다. 그들은 매우 큰 모델의 다양한 기능을 상대적으로 더 작은 매개변수를 가진 모델로 분할하고 일부 단일 작업에서 수천억 개의 모델을 능가하는 능력을 입증했습니다.
그러나 대형 모델로의 길이 여기서 끝나지 않을 것이라는 데는 의심의 여지가 없습니다. 많은 업계 전문가들은 AI Technology Review에 대형 모델의 매개변수에는 여전히 개선의 여지가 있으며 누군가는 계속해서 탐구해야 한다고 말했습니다. 더 큰 규모의 모델. 그렇다면 우리는 오픈소스 대형 모델의 딜레마에 직면해야 합니다. 그렇다면 해결책은 무엇입니까?
먼저 컴퓨팅 파워 자체의 관점에서 생각해 보겠습니다. 대규모 컴퓨터 클러스터와 컴퓨팅 파워 센터의 건설은 결국 미래의 추세가 될 것입니다. 결국 컴퓨팅 자원은 수요를 충족시킬 수 없습니다. 하지만 이제 무어의 법칙은 둔화되었고 업계에서는 무어의 법칙이 종말을 고하고 있다는 주장이 끊이지 않습니다. 단순히 컴퓨팅 성능 향상에만 희망을 걸면 당장의 불만은 식힐 수 없을 것입니다. 갈증.
"이제 카드는 (추론 측면에서) 10억 개의 모델을 실행할 수 있습니다. 현재 컴퓨팅 파워의 성장률에 따르면, 카드가 1000억 개의 모델을 실행할 수 있다면, 즉 컴퓨팅 파워는 100배 더 높아질 수 있습니다. 개선하는 데 10년이 걸릴 수 있습니다."라고 Zhang Jiaxing은 설명했습니다.
대형 모델이 출시되는 걸 너무 기대하고 있어요.
또 다른 방향은 대형 모델의 추론 속도를 높이고, 컴퓨팅 전력 비용을 줄이고, 에너지 소비를 줄여 대형 모델의 유용성을 향상시키는 훈련 기술에 대해 소란을 피우는 것입니다.
예를 들어 Meta의 OPT(GPT-3와 비교)는 전체 모델 코드 베이스를 훈련하고 배포하는 데 16개의 NVIDIA v100 GPU만 필요하며 이는 GPT-3의 7분의 1입니다. 최근 Tsinghua University와 Zhipu AI는 빠른 추론 방법을 통해 이중 언어 대형 모델 GLM-130B를 공동으로 공개했으며 이 모델은 A100(40G*8) 또는 독립형 추론에 사용할 수 있을 정도로 압축되었습니다. V100(32G*8) 서버.
물론 주요 제조업체가 대형 모델을 오픈소스로 꺼리는 이유는 바로 높은 교육 비용 때문입니다. 전문가들은 이전에 GPT-3을 훈련하는 데 수만 개의 Nvidia v100 GPU가 사용되었으며, 개인이 PaLM을 훈련하려는 경우 총 비용은 900만 달러에서 1700만 달러에 달할 것으로 추정했습니다. 대형 모델의 학습 비용을 줄일 수 있다면 자연스럽게 오픈 소스에 대한 의지가 높아질 것입니다.
그러나 최종 분석에서 이는 엔지니어링 관점에서 컴퓨팅 리소스의 제약을 완화할 수 있을 뿐 궁극적인 해결책은 아닙니다. 수천억, 수조 단계의 많은 대형 모델이 "낮은 에너지 소비" 이점을 홍보하기 시작했지만 컴퓨팅 성능의 벽은 여전히 너무 높습니다.
결국 돌파점을 찾으려면 대형 모델 자체로 돌아가야 합니다. 매우 유망한 방향은 희소 동적 대형 모델입니다.
희소 대형 모델은 용량이 매우 큰 것이 특징이지만 주어진 작업, 샘플 또는 라벨에 대한 특정 부품만 활성화됩니다. 즉, 이 희박한 동적 구조를 통해 대형 모델은 막대한 계산 비용을 지불하지 않고도 매개변수 수량을 몇 단계 높일 수 있어 일석이조입니다. 이는 가장 간단한 작업도 완료하기 위해 전체 신경망을 활성화해야 하여 막대한 리소스 낭비를 초래하는 GPT-3과 같은 조밀하고 대규모 모델에 비해 큰 이점입니다.
Google은 희소 동적 구조의 선구자입니다. 그들은 2017년에 MoE(Sparsely-Gated Mixture-of-Experts Layer, Sparsely Gated Expert Mixing Layer)를 처음 제안했고 작년에 1조 6천억 매개변수의 대형 모델 Switch Transformer를 출시했습니다. MoE 스타일 아키텍처를 통합하여 이전 밀도 모델인 T5-Base Transformer에 비해 훈련 효율성이 7배 증가했습니다.
올해 PaLM의 기반이 되는 Pathways 통합 아키텍처는 희소 동적 구조의 모델입니다. 모델은 네트워크의 특정 부분이 어떤 작업을 잘하는지 동적으로 학습할 수 있으며, 우리는 네트워크를 통해 작은 경로를 다음과 같이 호출합니다. 작업을 완료하기 위해 전체 신경망을 활성화하지 않고도 사용할 수 있습니다.

그림: 통로 아키텍처
이는 인간의 뇌가 작동하는 방식과 본질적으로 유사합니다. 인간의 뇌에는 수백억 개의 뉴런이 있지만 특정 뉴런만 활성화되어 수행됩니다. 그렇지 않으면 엄청난 에너지 소비가 견딜 수 없을 것입니다.
크고 다재다능하며 효율적인 이 대형 모델 루트는 의심할 여지 없이 매우 매력적입니다.
"향후 희소 역학의 지원으로 계산 비용은 그리 높지 않을 것이지만 모델 매개변수는 확실히 점점 더 커질 것입니다. 희소 역학 구조는 새로운 가능성을 열 수 있습니다. 대형 모델의 경우 10조 또는 1000억에 도달하는 것은 문제가 되지 않습니다.” Zhang Jiaxing은 희박한 동적 구조가 대형 모델 크기와 컴퓨팅 성능 비용 간의 모순을 해결하는 궁극적인 방법이 될 것이라고 믿습니다. 그러나 그는 또한 이런 종류의 모델 구조가 아직 대중적이지 않은 상황에서 계속해서 모델을 더 크게 만드는 것은 별 의미가 없다고 덧붙였습니다.
현재 이 방향으로의 국내 시도는 상대적으로 적고, 구글만큼 철저하지도 않습니다. 대형 모델 구조와 오픈 소스의 탐색과 혁신은 서로를 촉진하며, 대형 모델 기술의 변화를 촉진하려면 더 많은 오픈 소스가 필요합니다.
대형 모델의 오픈소스를 방해하는 것은 대형 모델의 컴퓨팅 파워 비용으로 인한 낮은 가용성뿐만 아니라 보안 문제도 있습니다.
특히 오픈소스 이후에 생성된 대형 모델의 남용 위험에 대해서는 해외에서 우려가 더 커지고 논란이 많은 것 같습니다. 이는 많은 기관에서 오픈소스를 선택하지 않는 근거가 되었습니다. 대형 모델이지만 아마도 관대함을 거부하는 핑계이기도 합니다.
OpenAI는 이에 대해 많은 비판을 받았습니다. 그들은 2019년 GPT-2를 출시했을 때 모델의 텍스트 생성 기능이 너무 강력하고 윤리적 해를 끼칠 수 있어 오픈소스에 적합하지 않다고 주장했습니다. 1년 후 GPT-3가 출시되었을 때 API 평가판만 제공했습니다. GPT-3의 현재 오픈 소스 버전은 실제로 오픈 소스 커뮤니티 자체에서 재현되었습니다.
실제로 대형 모델에 대한 액세스를 제한하면 견고성을 향상하고 편견과 독성을 줄이는 측면에서 대형 모델에 해로울 수 있습니다. Meta AI의 조엘 피노(Joelle Pineau) 대표는 오픈소스 OPT 결정에 대해 이야기하면서 텍스트 생성 과정에서 발생할 수 있는 윤리적 편견, 악성 언어 등 모든 문제를 자신의 팀만으로는 해결할 수 없다고 진심으로 밝혔습니다. 그들은 충분한 숙제를 하면 대형 모델을 책임감 있게 공개적으로 접근할 수 있다고 믿습니다.
남용의 위험을 방지하면서 개방적인 액세스와 충분한 투명성을 유지하는 것은 쉬운 일이 아닙니다. 스태빌리티 AI는 '판도라의 상자'를 연 장본인으로 그동안 활발한 오픈소스가 가져온 좋은 평판을 누려왔지만, 최근에는 오픈소스가 가져온 반발에 부딪혀 저작권 소유권 등 측면에서 논란을 일으키기도 했다.
오픈소스 뒤에 숨어 있는 "자유와 보안"이라는 고대 변증법적 명제는 완전히 정답이 아닐 수도 있지만, 큰 모델이 구현되기 시작하면서 분명한 사실은 다음과 같습니다. : 크다 우리는 모델을 오픈 소스로 만들기에 충분한 작업을 수행하지 않았습니다.
2년 이상이 지났고, 우리는 이미 1조 단위의 자체 대형 모델을 보유하고 있습니다. "수천 권의 책을 읽는 것"에서 "수천 마일을 여행하는" 대형 모델의 다음 변형 과정이 열립니다. 소스는 불가피한 선택입니다.
최근 GPT-4가 나올 예정이고, 그 성능의 도약에 모두가 큰 기대를 하고 있지만, 앞으로 얼마나 많은 사람들에게 얼마나 많은 생산성을 발휘하게 될지는 알 수 없겠죠?
위 내용은 대규모 AI 모델을 위한 오픈소스의 딜레마: 독점, 벽, 컴퓨팅 성능의 슬픔의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



