


위의 개별 주식의 자본 흐름을 크롤링하는 예를 통해 자신만의 크롤링 코드를 작성하는 방법을 배울 수 있어야 합니다. 이제 그것을 통합하고 유사한 작은 운동을 하십시오. 온라인 부문의 자금 흐름을 크롤링하려면 자신만의 Python 프로그램을 작성해야 합니다. 크롤링된 URL은 http://data.eastmoney.com/bkzj/hy.html이고 디스플레이 인터페이스는 그림 1에 표시됩니다.金 그림 1 자금 흐름 웹사이트의 인터페이스
1, JS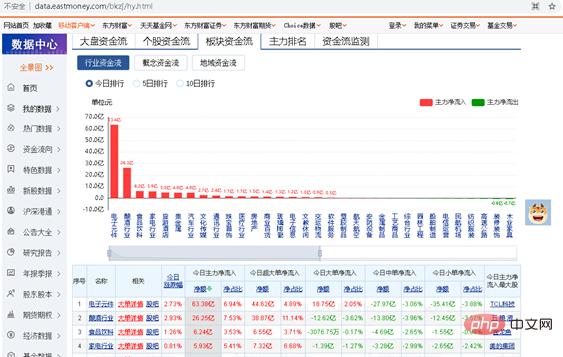
그림 2 JS에 해당하는 웹페이지 찾기
그런 다음 브라우저에 URL을 입력하면 URL이 비교적 깁니다. 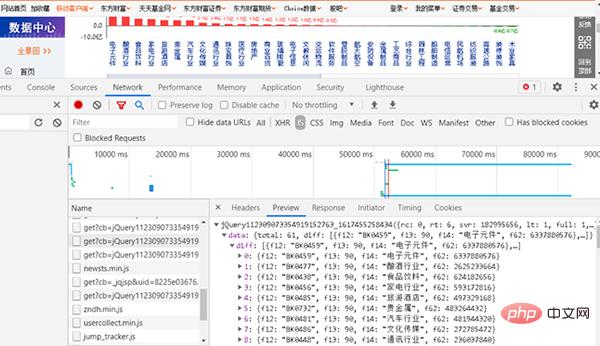
그림 3 웹사이트에서 섹션 및 자금 흐름 가져오기
이 URL에 해당하는 콘텐츠가 우리가 크롤링하려는 콘텐츠입니다. 
# coding=utf-8 import requests url=" http://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112309073354919152763_ 1617455258436&fid=f62&po=1&pz=50&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3 e90d46a5&fs=m%3A90+t%3A2&fields=f12%2Cf14%2Cf2%2Cf3%2Cf62%2Cf184%2Cf66%2Cf69%2Cf72%2 Cf75%2Cf78%2Cf81%2Cf84%2Cf87%2Cf204%2Cf205%2Cf124" r = requests.get(url)
그림 4 응답 상태
3, 문자열을 JSON 표준 형식으로 정리 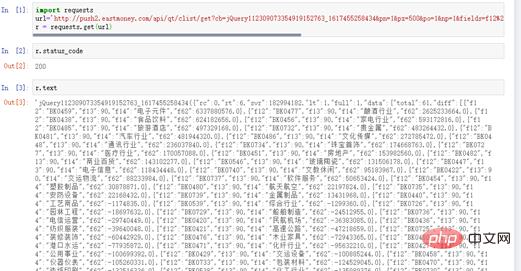
r_text=r.text.split("{}".format("jQuery112309073354919152763_1617455258436"))[1]
r_textr_text_qu=r_text.rstrip(';')
r_text_json=json.loads(r_text_qu[1:-1])['data']['diff']
dfcf_code={"f12":"code","f2":"价格","f3":"涨幅","f14":"name","f62":"主净入√","f66":"超净入","f69":"超占比", "f72":"大净入","f75":"大占比","f78":"中净入","f81":"中占比","f84":"小净入","f87":"小占比","f124":"不知道","f184":"主占比√"}
result_=pd.DataFrame(r_text_json).rename(columns=dfcf_code)
result_["主净入√"]=round(result_["主净入√"]/100000000,2)#一亿,保留2位
result_=result_[result_["主净入√"]>0]
result_["超净入"]=round(result_["超净入"]/100000000,2)#一亿,保留2位
result_["大净入"]=round(result_["大净入"]/100000000,2)#一亿,保留2位
result_["中净入"]=round(result_["中净入"]/100000000,2)#一亿,保留2位
result_["小净入"]=round(result_["小净入"]/100000000,2)#一亿,保留2位
result_ (1) 개별 주식 자본 흐름의 장점을 선택합니다.
(1) 개별 주식 자본 흐름의 장점을 선택합니다.
(2) 웹사이트 주소를 얻어 분석합니다.
(3) 크롤러를 사용하여 데이터를 얻고 데이터를 저장합니다.
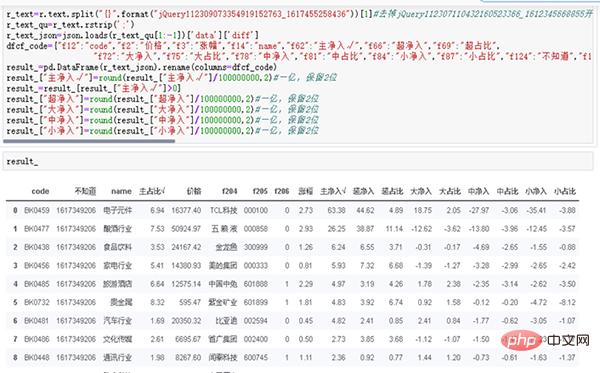 그림 6 데이터 저장
그림 6 데이터 저장
요약
사례 분석과 실제 전투를 통해 금융 데이터를 크롤링하는 자체 코드를 작성하는 방법을 배우고 이를 JSON 표준 형식으로 변환할 수 있는 능력을 갖추어야 합니다. 일일 데이터 크롤링 및 데이터 저장 작업을 완료하여 향후 데이터 기록 테스트 및 데이터 기록 분석을 위한 효과적인 데이터 지원을 제공합니다.
물론 유능한 독자라면 MySQL, MongoDB 또는 클라우드 데이터베이스 Mongo Atlas와 같은 데이터베이스에 결과를 저장할 수 있습니다. 저자는 여기서 설명에 집중하지 않을 것입니다. 우리는 전적으로 양적 학습과 전략 연구에 중점을 두고 있습니다. txt 형식을 사용하여 데이터를 저장하면 초기 데이터 저장 문제를 완전히 해결할 수 있으며 데이터도 완전하고 효과적입니다.
위 내용은 부문별 자금 흐름을 크롤링하는 Python 프로그램 작성의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



