

지속 학습은 이전 작업에서 얻은 지식을 잊지 않고 많은 수의 작업을 순차적으로 학습하는 모델을 말합니다. 지도 학습에서는 기계 학습 모델이 주어진 데이터 세트 또는 데이터 분포에 가장 적합한 기능이 되도록 훈련되기 때문에 이는 중요한 개념입니다. 실제 환경에서 데이터는 정적인 경우가 거의 없으며 변경될 수 있습니다. 일반적인 ML 모델은 보이지 않는 데이터에 직면할 때 성능 저하를 겪을 수 있습니다. 이러한 현상을 파국적 망각이라고 합니다.

이런 종류의 문제를 해결하는 일반적인 방법은 이전 데이터와 새 데이터가 포함된 새로운 대규모 데이터 세트에서 전체 모델을 재교육하는 것입니다. 그러나 이 접근 방식은 비용이 많이 드는 경우가 많습니다. 그래서 이 문제를 살펴보고 있는 ML 연구 분야가 있습니다. 이 분야의 연구를 바탕으로, 이 기사에서는 모델이 이전 성능을 유지하면서 새로운 데이터에 적응하고 수행할 필요를 피할 수 있는 6가지 방법을 논의할 것입니다. 재교육할 전체 데이터 세트(기존 + 신규)
Prompt 이 아이디어는 GPT 3의 힌트(짧은 단어 시퀀스)가 모델이 더 나은 추론과 답변을 유도하는 데 도움이 될 수 있다는 아이디어에서 비롯되었습니다. 따라서 이 문서에서는 Prompt가 프롬프트로 번역됩니다. 힌트 조정은 학습 가능한 작은 힌트를 사용하여 실제 입력과 함께 모델에 입력으로 제공하는 것을 의미합니다. 이를 통해 모델 가중치를 다시 학습할 필요 없이 새 데이터에 대한 힌트를 제공하는 작은 모델만 학습할 수 있습니다.
구체적으로 저는 Wang의 기사 "지속 학습을 위한 프롬프트 학습"에서 채택한 텍스트 기반 집중 검색을 위한 프롬프트를 사용하는 예를 선택했습니다.
논문의 저자는 다음 다이어그램을 사용하여 아이디어를 설명합니다.
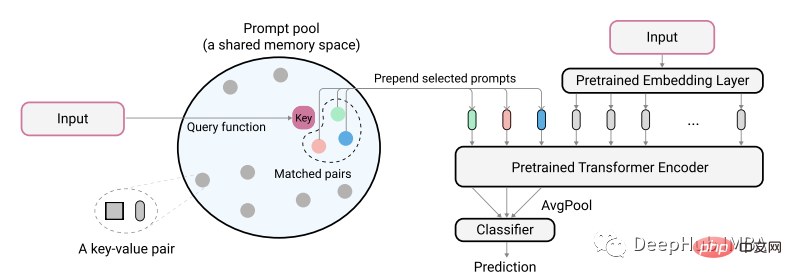
실제 인코딩된 텍스트 입력은 힌트 풀에서 가장 작은 일치 쌍을 식별하는 키로 사용됩니다. 이렇게 식별된 단서는 모델에 입력되기 전에 먼저 인코딩되지 않은 텍스트 임베딩에 추가됩니다. 이것의 목적은 이전 모델을 변경하지 않고 유지하면서 이러한 단서를 훈련하여 새로운 작업을 나타내는 것입니다. 단서는 프롬프트당 20개의 토큰으로 매우 작습니다.
class PromptPool(nn.Module):
def __init__(self, M = 100, hidden_size = 768, length = 20, N=5):
super().__init__()
self.pool = nn.Parameter(torch.rand(M, length, hidden_size), requires_grad=True).float()
self.keys = nn.Parameter(torch.rand(M, hidden_size), requires_grad=True).float()
self.length = length
self.hidden = hidden_size
self.n = N
nn.init.xavier_normal_(self.pool)
nn.init.xavier_normal_(self.keys)
def init_weights(self, embedding):
pass
# function to select from pool based on index
def concat(self, indices, input_embeds):
subset = self.pool[indices, :] # 2, 2, 20, 768
subset = subset.to("cuda:0").reshape(indices.size(0),
self.n*self.length,
self.hidden) # 2, 40, 768
return torch.cat((subset, input_embeds), 1)
# x is cls output
def query_fn(self, x):
# encode input x to same dim as key using cosine
x = x / x.norm(dim=1)[:, None]
k = self.keys / self.keys.norm(dim=1)[:, None]
scores = torch.mm(x, k.transpose(0,1).to("cuda:0"))
# get argmin
subsets = torch.topk(scores, self.n, 1, False).indices # k smallest
return subsets
pool = PromptPool()그런 다음 훈련된 기존 데이터 모델을 사용하여 새 데이터를 훈련합니다. 여기서는 프롬프트 부분의 가중치만 훈련합니다.
def train():
count = 0
print("*********** Started Training *************")
start = time.time()
for epoch in range(40):
model.eval()
pool.train()
optimizer.zero_grad(set_to_none=True)
lap = time.time()
for batch in iter(train_dataloader):
count += 1
q, p, train_labels = batch
queries_emb = model(input_ids=q['input_ids'].to("cuda:0"),
attention_mask=q['attention_mask'].to("cuda:0"))
passage_emb = model(input_ids=p['input_ids'].to("cuda:0"),
attention_mask=p['attention_mask'].to("cuda:0"))
# pool
q_idx = pool.query_fn(queries_emb)
raw_qembedding = model.model.embeddings(input_ids=q['input_ids'].to("cuda:0"))
q = pool.concat(indices=q_idx, input_embeds=raw_qembedding)
p_idx = pool.query_fn(passage_emb)
raw_pembedding = model.model.embeddings(input_ids=p['input_ids'].to("cuda:0"))
p = pool.concat(indices=p_idx, input_embeds=raw_pembedding)
qattention_mask = torch.ones(batch_size, q.size(1))
pattention_mask = torch.ones(batch_size, p.size(1))
queries_emb = model.model(inputs_embeds=q,
attention_mask=qattention_mask.to("cuda:0")).last_hidden_state
passage_emb = model.model(inputs_embeds=p,
attention_mask=pattention_mask.to("cuda:0")).last_hidden_state
q_cls = queries_emb[:, pool.n*pool.length+1, :]
p_cls = passage_emb[:, pool.n*pool.length+1, :]
loss, ql, pl = calc_loss(q_cls, p_cls)
loss.backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
if count % 10 == 0:
print("Model Loss:", round(loss.item(),4),
"| QL:", round(ql.item(),4), "| PL:", round(pl.item(),4),
"| Took:", round(time.time() - lap), "secondsn")
lap = time.time()
if count % 40 == 0 and count > 0:
print("model saved")
torch.save(model.state_dict(), model_PATH)
torch.save(pool.state_dict(), pool_PATH)
if count == 4600: return
print("Training Took:", round(time.time() - start), "seconds")
print("n*********** Training Complete *************")훈련이 완료된 후 후속 추론 프로세스에서는 입력을 검색된 힌트와 결합해야 합니다. 예를 들어, 이 예에서는 새 데이터 힌트 풀의 경우 93%, 전체(이전 + 새) 교육의 경우 94%의 성능을 얻었습니다. 이는 원문에서 언급한 성능과 유사하다. 하지만 주의할 점은 작업에 따라 결과가 달라질 수 있으므로 실험을 통해 무엇이 가장 효과적인지 알아내야 한다는 것입니다.
이 방법을 고려해 볼 가치가 있으려면 이전 데이터에서 이전 모델의 성능을 80% 이상 보존할 수 있어야 하며, 힌트는 모델이 새 데이터에서 좋은 성능을 달성하는 데도 도움이 되어야 합니다.
이 방법의 단점은 힌트 풀을 사용해야 하므로 시간이 더 걸린다는 것입니다. 이는 영구적인 해결책은 아니지만 현재로서는 가능하며 아마도 미래에는 새로운 방법이 등장할 수도 있습니다.
지식 증류라는 용어를 들어보셨을 것입니다. 이는 교사 모델의 가중치를 사용하여 소규모 모델을 안내하고 훈련시키는 기술입니다. 데이터 증류(Data Distillation)도 유사하게 작동합니다. 실제 데이터의 가중치를 사용하여 데이터의 더 작은 하위 집합을 훈련합니다. 데이터 세트의 주요 신호는 더 작은 데이터 세트로 정제되고 압축되므로 새로운 데이터에 대한 교육에는 이전 성능을 유지하기 위해 일부 정제된 데이터만 제공하면 됩니다.
이 예에서는 밀도가 높은 검색(텍스트) 작업에 데이터 증류를 적용합니다. 현재 이 분야에서는 이 방법을 사용하는 사람이 없기 때문에 결과가 가장 좋지 않을 수 있지만 텍스트 분류에 이 방법을 사용하면 좋은 결과를 얻을 수 있습니다.
본질적으로 텍스트 데이터 증류의 아이디어는 Li의 Data Distillation for Text Classification이라는 제목의 논문에서 시작되었습니다. 이 논문은 Wang의 Dataset Distillation에서 영감을 받아 이미지 데이터를 증류했습니다. Li는 다음 다이어그램을 사용하여 텍스트 데이터 증류 작업을 설명합니다.
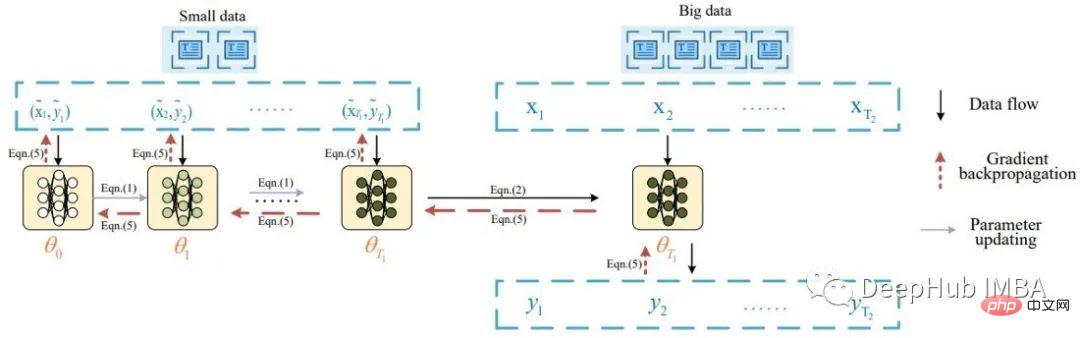
논문에 따르면 증류된 데이터 배치가 먼저 모델에 공급되어 가중치를 업데이트합니다. 그런 다음 업데이트된 모델은 실제 데이터를 사용하여 평가되고 신호는 증류된 데이터 세트로 역전파됩니다. 이 논문은 8개의 공개 벤치마크 데이터 세트에 대한 우수한 분류 결과(>80% 정확도)를 보고합니다.
제안된 아이디어에 따라 약간의 변경을 가하고 일련의 증류된 데이터와 여러 개의 실제 데이터를 사용했습니다. 다음은 집중 검색 훈련을 위한 증류 데이터를 생성하는 코드입니다.
class DistilledData(nn.Module):
def __init__(self, num_labels, M, q_len=64, hidden_size=768):
super().__init__()
self.num_samples = M
self.q_len = q_len
self.num_labels = num_labels
self.data = nn.Parameter(torch.rand(num_labels, M, q_len, hidden_size), requires_grad=True) # i.e. shape: 1000, 4, 64, 768
# init using model embedding, xavier, or load from state dict
def init_weights(self, model, path=None):
if model:
self.data.requires_grad = False
print("Init weights using model embedding")
raw_embedding = model.model.get_input_embeddings()
soft_embeds = raw_embedding.weight[:, :].clone().detach()
nums = soft_embeds.size(0)
for i1 in range(self.num_labels):
for i2 in range(self.num_samples):
for i3 in range(self.q_len):
random_idx = random.randint(0, nums-1)
self.data[i1, i2, i3, :] = soft_embeds[random_idx, :]
print(self.data.shape)
self.data.requires_grad = True
if not path:
nn.init.xavier_normal_(self.data)
else:
distilled_data.load_state_dict(torch.load(path), strict=False)
# function to sample a passage and positive sample as in the article, i am doing dense retrieval
def get_sample(self, label):
q_idx = random.randint(0, self.num_samples-1)
sampled_dist_q = self.data[label, q_idx, :, :]
p_idx = random.randint(0, self.num_samples-1)
while q_idx == p_idx:
p_idx = random.randint(0, self.num_samples-1)
sampled_dist_p = self.data[label, p_idx, :, :]
return sampled_dist_q, sampled_dist_p, q_idx, p_idx이것은 증류 데이터에 신호를 추출하는 코드입니다.
def distll_train(chunk_size=32):
count, times = 0, 0
print("*********** Started Training *************")
start = time.time()
lap = time.time()
for epoch in range(40):
distilled_data.train()
for batch in iter(train_dataloader):
count += 1
# get real query, pos, label, distilled data query, distilled data pos, ... from batch
q, p, train_labels, dq, dp, q_indexes, p_indexes = batch
for idx in range(0, dq['input_ids'].size(0), chunk_size):
model.train()
with torch.enable_grad():
# train on distiled data first
x1 = dq['input_ids'][idx:idx+chunk_size].clone().detach().requires_grad_(True)
x2 = dp['input_ids'][idx:idx+chunk_size].clone().detach().requires_grad_(True)
q_emb = model(inputs_embeds=x1.to("cuda:0"),
attention_mask=dq['attention_mask'][idx:idx+chunk_size].to("cuda:0")).cpu()
p_emb = model(inputs_embeds=x2.to("cuda:0"),
attention_mask=dp['attention_mask'][idx:idx+chunk_size].to("cuda:0"))
loss = default_loss(q_emb.to("cuda:0"), p_emb)
del q_emb, p_emb
loss.backward(retain_graph=True, create_graph=False)
state_dict = model.state_dict()
# update model weights
with torch.no_grad():
for idx, param in enumerate(model.parameters()):
if param.requires_grad and not param.grad is None:
param.data -= (param.grad*3e-5)
# real data
model.eval()
q_embs = []
p_embs = []
for k in range(0, len(q['input_ids']), chunk_size):
with torch.no_grad():
q_emb = model(input_ids=q['input_ids'][k:k+chunk_size].to("cuda:0"),).cpu()
p_emb = model(input_ids=p['input_ids'][k:k+chunk_size].to("cuda:0"),).cpu()
q_embs.append(q_emb)
p_embs.append(p_emb)
q_embs = torch.cat(q_embs, 0)
p_embs = torch.cat(p_embs, 0)
r_loss = default_loss(q_embs.to("cuda:0"), p_embs.to("cuda:0"))
del q_embs, p_embs
# distill backward
if count % 2 == 0:
d_grad = torch.autograd.grad(inputs=[x1.to("cuda:0")],#, x2.to("cuda:0")],
outputs=loss,
grad_outputs=r_loss)
indexes = q_indexes
else:
d_grad = torch.autograd.grad(inputs=[x2.to("cuda:0")],
outputs=loss,
grad_outputs=r_loss)
indexes = p_indexes
loss.detach()
r_loss.detach()
grads = torch.zeros(distilled_data.data.shape) # lbl, 10, 100, 768
for i, k in enumerate(indexes):
grads[train_labels[i], k, :, :] = grads[train_labels[i], k, :, :].to("cuda:0")
+ d_grad[0][i, :, :]
distilled_data.data.grad = grads
data_optimizer.step()
data_optimizer.zero_grad(set_to_none=True)
model.load_state_dict(state_dict)
model_optimizer.step()
model_optimizer.zero_grad(set_to_none=True)
if count % 10 == 0:
print("Count:", count ,"| Data:", round(loss.item(), 4), "| Model:",
round(r_loss.item(),4), "| Time:", round(time.time() - lap, 4))
# print()
lap = time.time()
if count % 100 == 0:
torch.save(model.state_dict(), model_PATH)
torch.save(distilled_data.state_dict(), distill_PATH)
if loss < 0.1 and r_loss < 1:
times += 1
if times > 100:
print("Training Took:", round(time.time() - start), "seconds")
print("n*********** Training Complete *************")
return
del loss, r_loss, grads, q, p, train_labels, dq, dp, x1, x2, state_dict
print("Training Took:", round(time.time() - start), "seconds")
print("n*********** Training Complete *************")여기에서는 증류 데이터를 훈련한 후 데이터 로딩과 같은 코드를 생략합니다. 이를 전달합니다. 예를 들어 새 데이터와 결합하여 새 모델을 사용하도록 교육합니다.
내 실험에 따르면 증류된 데이터(라벨당 4개의 샘플만 포함)로 훈련한 모델은 66%의 최고 성능을 얻었고, 원본 데이터로만 훈련한 모델도 66%의 최고 성능을 얻었습니다. 훈련되지 않은 일반 모델은 45%의 성능을 달성했습니다. 위에서 언급한 대로 이 숫자는 집중적인 검색 작업에는 적합하지 않을 수 있지만 범주형 데이터에는 훨씬 더 좋습니다.
모델을 새로운 데이터로 조정할 때 이 방법이 유용하려면 원본 데이터보다 훨씬 작은 데이터 세트(예: ~1%)를 추출할 수 있어야 합니다. 정제된 데이터는 능동적 학습 방법보다 약간 낮거나 같은 성능을 제공할 수도 있습니다.
이 방법의 장점은 영구적으로 사용할 수 있는 증류된 데이터를 생성할 수 있다는 것입니다. 단점은 추출된 데이터를 해석할 수 없고 추가적인 훈련 시간이 필요하다는 점입니다.
커리큘럼 훈련은 훈련 중에 모델에 훈련 샘플을 제공하는 것이 점차 어려워지는 방법입니다. 새로운 데이터를 교육할 때 이 방법을 사용하려면 작업에 수동으로 레이블을 지정하고 작업을 쉬움, 중간, 어려움으로 분류한 다음 데이터를 샘플링해야 합니다. 모델이 쉬움, 중간, 어려움의 의미를 이해하기 위해 다음 그림을 예로 듭니다.
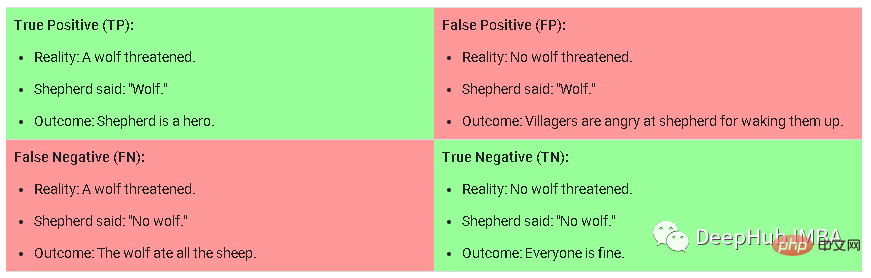
이것은 분류 작업의 혼동 행렬입니다. 이는 모델을 참조하는 거짓 긍정입니다. 예측 True일 확률은 매우 높지만 실제로는 True인 표본이 아닙니다. 중간 샘플은 정확할 확률이 중간에서 높지만 예측 임계값보다 낮은 참음성인 샘플입니다. 단순 샘플은 참양성/음성 가능성이 낮은 샘플입니다.
Rahaf가 "Online Continual Learning with Maximally Interfered Retrieval"이라는 논문(1908.04742)에서 소개한 방법입니다. 주요 아이디어는 훈련되는 각각의 새로운 데이터 배치에 대해 최신 데이터에 대한 모델 가중치를 업데이트하는 경우 손실 값 측면에서 가장 큰 영향을 받는 이전 샘플을 식별해야 한다는 것입니다. 오래된 데이터로 구성된 제한된 크기의 메모리는 유지되며 가장 방해가 되는 샘플은 각각의 새로운 데이터 배치와 함께 검색되어 함께 훈련됩니다.
이 논문은 지속적인 학습 분야에서 확립된 논문이고 인용 횟수도 많기 때문에 귀하의 사례에 적용될 수 있습니다.
검색 증강은 컬렉션에서 항목을 검색하여 입력, 샘플 등을 증강하는 기술을 말합니다. 이는 특정 기술이라기보다는 일반적인 개념이다. 지금까지 논의한 대부분의 방법은 어느 정도 검색 관련 작업입니다. 검색 증강 언어 모델을 사용한 Few-shot Learning이라는 제목의 Izacard의 논문은 더 작은 모델을 사용하여 Few-shot 학습에서 뛰어난 성능을 달성합니다. 검색 향상은 단어 생성이나 사실 질문에 대한 답변과 같은 다른 많은 상황에서도 사용됩니다.
학습 중에 추가 레이어를 사용하도록 모델을 확장하는 것이 가장 일반적이고 간단한 방법이지만 반드시 효과적인 것은 아니므로 여기서는 Lewis의 Efficient Few-Shot Learning Without Prompts를 예로 들어 자세히 설명하지 않습니다. 추가 레이어를 사용하는 것은 기존 데이터와 새 데이터에서 우수한 성능을 얻기 위한 가장 간단하지만 시도되고 테스트된 방법인 경우가 많습니다. 주요 아이디어는 모델 가중치를 고정한 상태로 유지하고 분류 손실이 있는 새 데이터에 대해 하나 이상의 레이어를 훈련하는 것입니다.
요약 이번 글에서는 새로운 데이터로 모델을 훈련할 때 사용할 수 있는 6가지 방법을 소개했습니다. 항상 그렇듯이 어떤 방법이 가장 효과적인지 실험하고 결정해야 하지만 위에서 설명한 방법 외에도 많은 방법이 있다는 점에 유의하는 것이 중요합니다. 예를 들어 데이터 증류는 컴퓨터 비전에서 활발하게 사용되는 영역이며 이에 대한 많은 내용을 논문에서 찾을 수 있습니다. . 마지막 참고 사항: 이러한 방법이 유용하려면 이전 데이터와 새 데이터 모두에서 좋은 성능을 달성해야 합니다.
위 내용은 지속적인 학습을 위한 6가지 일반적인 방법 요약: 이전 데이터의 성능을 유지하면서 ML 모델을 새로운 데이터에 적용의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



