

저자: Zhai Helong
컴퓨터 분야에서 성능 최적화 조치에 관해 고려해야 할 첫 번째 원칙 중 하나는 캐시를 사용하는 것입니다. 다음 이점:
1. 데이터 수집 경로를 단축하고 빠른 후속 읽기를 위해 근처에 핫스팟 데이터를 캐시하여 처리 효율성을 크게 향상시킵니다.
2. -엔드 데이터 서비스, 프런트엔드와 백엔드 간 격차 감소
CPU 하드웨어의 다단계 캐시 설계부터 브라우저의 빠른 페이지 표시, CDN 및 인기 상용 제품까지 클라우드 스토리지 게이트웨이에서는 캐싱 개념이 모든 곳에 적용됩니다.
공용 네트워크 분야에서 운영 체제, 브라우저, 모바일 앱과 같은 성숙한 제품의 캐싱 메커니즘은 China Telecom, China Unicom과 같은 네트워크 공급자와 주요 포털 플랫폼과 같은 콘텐츠 공급자가 직면한 문제를 크게 제거했습니다. CDN 제조업체는 심각한 서비스 압박에 직면해 있습니다. 오직 운영자의 DNS만이 초당 수십억 개의 DNS 확인을 침착하게 처리할 수 있고, 네트워크 장비 클러스터는 초당 Tbit 수준의 인터넷 대역폭을 쉽게 감당할 수 있으며, CDN 플랫폼은 초당 수십억 개의 요청을 신속하게 처리할 수 있습니다. .
현재 회사의 거대하고 성장하는 도메인 이름 액세스 규모에 직면하여 저자 팀은 지속적으로 클러스터 아키텍처를 최적화하고 DNS 소프트웨어 성능을 개선하고 있으며 도메인 이름 확인 요청을 수행하기 위해 시급히 다양한 클라이언트 환경을 홍보해야 합니다. 메커니즘에 따라 우리는 회사, 고객 및 파트너의 프런트 엔드 개발 및 운영 담당자에게 합리적인 제안을 제공하고 전반적인 DNS 요청 프로세스를 최적화하며 비즈니스 효율성을 높이기 위해 이 가이드 기사를 연구하고 작성하도록 특별히 팀 구성원을 구성했습니다.
이 기사에서는 다양한 비즈니스 및 개발 언어 배경에서 클라이언트에서 로컬로 DNS 확인 레코드 캐싱을 구현하는 방법을 주로 설명합니다. 동시에 작성자 팀의 DNS 자체 및 회사 네트워크 환경에 대한 이해를 바탕으로 몇 가지 다른 조치를 취합니다. 클라이언트 측에서 DNS 확인 요청을 정규화합니다.
이 글에서 언급된 클라이언트는 일반적으로 서버, PC, 모바일 단말기, 운영 체제, 명령줄을 포함하되 이에 국한되지 않고 네트워크 요청을 적극적으로 시작하는 모든 개체를 의미합니다. 도구, 스크립트, 서비스 소프트웨어, 사용자 APP 등
도메인 네임 시스템(서버/서비스)은 일종의 데이터베이스 서비스로 이해될 수 있습니다.
클라이언트는 네트워크를 통해 서버와 통신합니다. , IP 주소에 의존하여 상대방을 클라이언트 사용자로 식별하므로 인간이 많은 수의 IP 주소를 기억하기 어렵기 때문에 www.jd.com과 같이 기억하기 쉬운 도메인 이름을 고안하여 매핑을 저장합니다. 클라이언트가 사용할 DNS의 도메인 이름과 IP 주소 간의 관계
클라이언트는 DNS에 대한 도메인 이름 확인 요청을 시작하여 서버의 IP 주소를 얻은 후에만 네트워크 통신 요청을 시작할 수 있습니다. IP 주소를 취득하고 도메인 이름이 제공하는 서비스나 콘텐츠를 실제로 얻으세요.
참고: 도메인 이름 시스템도메인 이름 확인 프로세스
로컬 DNS, 로컬 도메인 이름 서버는 일반적으로 해당 위치의 네트워크 공급자에 의해 자동으로 할당됩니다( 공급자는 제어권을 가지며 DNS 하이재킹, 즉 도메인 이름 확인에서 얻은 IP를 변조하는 데에도 사용할 수 있으며 인트라넷 환경은 IT 부서 설정에 의해 자동으로 할당됩니다.
일반적으로 Unix, Unix와 유사합니다. MacOS 시스템은 /etc/resolv.conf를 통해 자신의 LDNS를 볼 수 있습니다. 나중에 네임서버에서 이 파일은 Google DNS와 같은 공용 네트워크의 일반 공용 DNS와 같은 LDNS를 지정하기 위한 사용자 자체 편집 및 수정도 지원한다고 밝혔습니다. 114DNS 등; 순수 인트라넷 환경에서는 일반적으로 IT 부서에 문의하지 않고 수정하는 것을 권장하지 않습니다. 이로 인해 서비스를 사용할 수 없게 될 수 있습니다. man resolv.conf 명령 결과를 참조하세요.
도메인 이름 확인이 비정상적인 경우 LDNS 서비스 이상 또는 확인 하이재킹 가능성도 고려해야 합니다.
참고: Windows 시스템에서 TCP/IP 설정(DNS 포함)을 수정합니다.
DNS 시스템은 호스트 파일에서 흔히 발견되는 도메인 이름과 IP 간의 매핑 관계를 동적으로 제공할 수 있습니다. 다양한 운영 체제의 도메인 이름과 IP 간의 매핑 관계에 대한 정적 기록 파일이며 일반적으로 호스트 기록이 DNS 확인보다 우선합니다. 즉, 로컬 캐시가 없거나 캐시가 누락된 경우 해당 도메인 이름이 우선합니다. 레코드는 먼저 호스트를 통해 쿼리됩니다. 호스트에 관련 매핑이 없으면 DNS가 계속해서 요청됩니다. Linux 환경에서 이 로직을 제어하는 방법은 아래 C/C++ 언어 DNS 캐시 소개 섹션을 참조하세요.
그래서 실제 작업에서는 위의 기본 기능을 사용하여 특정 도메인 이름과 특정 IP 간의 매핑 관계를 호스트 파일(흔히 "고정 호스트"라고 함)에 기록하는데, 이는 DNS 확인을 우회하는 데 사용됩니다. 대상 IP에 대한 대상 액세스를 처리하고 제공합니다(효과는 컬의 -x 옵션 또는 wget의 -e 지정된 프록시 옵션과 동일). TTL
이 글에 포함된 TTL 설명은 모두 데이터 캐싱을 위한 것으로, 이는 캐시된 데이터의 "유효 기간"으로 직접적으로 이해될 수 있습니다. 데이터가 캐시된 시점보다 오랫동안 캐시에 존재하는 데이터입니다. TTL 지정 시간이 고려됩니다. 만료된 데이터의 경우 해당 데이터가 다시 호출되면 유효성이 확인되거나 신뢰할 수 있는 데이터 원본에서 즉시 다시 가져옵니다.
캐싱 메커니즘은 일반적으로 수동적으로 트리거되고 업데이트되므로 클라이언트의 캐시 유효 기간 동안 백엔드 원본 신뢰할 수 있는 데이터가 변경되면 클라이언트는 이를 알아차리지 못하며 이는 어느 정도의 데이터 업데이트 지연으로 나타납니다. 비즈니스에 캐시된 데이터가 일시적으로 신뢰할 수 있는 데이터와 일치하지 않습니다.
클라이언트 측 DNS 레코드의 캐시 TTL의 경우 동시에 60초 값을 권장합니다. 테스트와 같이 민감도가 낮은 비즈니스이거나 도메인 이름 확인 조정이 자주 발생하지 않는 비즈니스라면 시간 또는 날짜 수준까지 적절하게 확장 가능
3. DNS 해상도 최적화 제안
1. 다양한 언어 네트워크 라이브러리의 DNS 캐싱 지원에 대한 설문조사C/C++ 언어
Linux 환경의 glibc 라이브러리는 IPv6 및 스레드 프로그래밍 모델로의 전환으로 gethostbyname 함수와 getaddrinfo 함수라는 두 가지 도메인 이름 확인 함수를 제공합니다. getaddrinfo는 IPv6 주소를 구문 분석할 뿐만 아니라 스레드로부터 안전하기 때문에 더욱 유용해집니다. getaddrinfo 함수를 사용하는 것이 좋습니다.
함수 프로토타입:
int getaddrinfo( const char *node, const char *service, const struct addrinfo *hints, struct addrinfo **res);
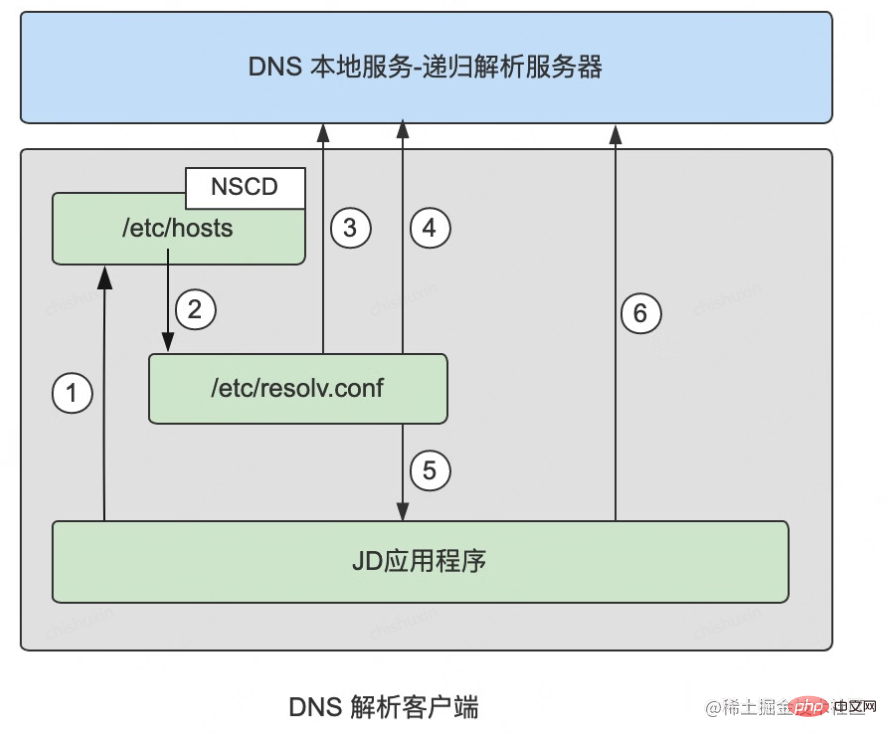 1) nscd 캐시 찾기(nscd에 대한 소개는 아래 참조)
1) nscd 캐시 찾기(nscd에 대한 소개는 아래 참조)
Linux 환경에서 strace 명령을 통해 다음 시스템 호출을 볼 수 있습니다
//连接nscd
socket(PF_LOCAL, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, 0) = 3
connect(3, {sa_family=AF_LOCAL, sun_path="/var/run/nscd/socket"}, 110) = -1 ENOENT (No such file or directory)
close(3)2) /etc/hosts 파일을 쿼리합니다.
nscd 서비스가 시작되지 않거나 캐시가 누락된 경우 계속해서 호스트 파일을 쿼리하면 다음 시스템 호출이 표시됩니다
//读取 hosts 文件
open("/etc/host.conf", O_RDONLY)= 3
fstat(3, {st_mode=S_IFREG|0644, st_size=9, ...}) = 0
...
open("/etc/hosts", O_RDONLY|O_CLOEXEC)= 3
fcntl(3, F_GETFD) = 0x1 (flags FD_CLOEXEC)
fstat(3, {st_mode=S_IFREG|0644, st_size=178, ...}) = 0/etc/resolv.conf 구성에서 DNS 서버(네임서버)의 IP 주소를 쿼리한 후 DNS 쿼리를 수행하여 확인 결과를 얻습니다. 다음 시스템 호출을 볼 수 있습니다.
//获取 resolv.conf 中 DNS 服务 IP
open("/etc/resolv.conf", O_RDONLY)= 3
fstat(3, {st_mode=S_IFREG|0644, st_size=25, ...}) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fef2abee000
read(3, "nameserver 114.114.114.114nn", 4096) = 25
...
//连到 DNS 服务,开始 DNS 查询
connect(3, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("114.114.114.114")}, 16) = 0
poll([{fd=3, events=POLLOUT}], 1, 0)= 1 ([{fd=3, revents=POLLOUT}])#/etc/nsswitch.conf 部分配置 ... #hosts: db files nisplus nis dns hosts:files dns ...
newfstatat(AT_FDCWD, "/etc/nsswitch.conf", {st_mode=S_IFREG|0644, st_size=510, ...}, 0) = 0
...
openat(AT_FDCWD, "/etc/nsswitch.conf", O_RDONLY|O_CLOEXEC) = 3#include <sys/socket.h>
#include <netdb.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <arpa/inet.h>
#include <unistd.h>
int gethostaddr(char * name);
int main(int argc, char *argv[]){
if (argc != 2)
{
fprintf(stderr, "%s $host", argv[0]);
return -1;
}
int i = 0;
for(i = 0; i < 5; i++)
{
int ret = -1;
ret = gethostaddr(argv[1]);
if (ret < 0)
{
fprintf(stderr, "%s $host", argv[0]);
return -1;
}
//sleep(5);
}
return 0;
}
int gethostaddr(char* name){
struct addrinfo hints;
struct addrinfo *result;
struct addrinfo *curr;
int ret = -1;
char ipstr[INET_ADDRSTRLEN];
struct sockaddr_in*ipv4;
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_family = AF_INET;
hints.ai_socktype = SOCK_STREAM;
ret = getaddrinfo(name, NULL, &hints, &result);
if (ret != 0)
{
fprintf(stderr, "getaddrinfo: %sn", gai_strerror(ret));
return ret;
}
for (curr = result; curr != NULL; curr = curr->ai_next)
{
ipv4 = (struct sockaddr_in *)curr->ai_addr;
inet_ntop(curr->ai_family, &ipv4->sin_addr, ipstr, INET_ADDRSTRLEN);
printf("ipaddr:%sn", ipstr);
}
freeaddrinfo(result);
return 0;
}(2) libcurl 라이브러리의 도메인 이름 확인 기능
libcurl 라이브러리는 c/C++ 언어에서 클라이언트가 일반적으로 사용하는 네트워크 전송 라이브러리입니다. 컬 명령은 이 라이브러리를 기반으로 구현됩니다. 이 라이브러리는 또한 getaddrinfo 라이브러리 함수를 호출하여 DNS 도메인 이름 확인을 구현하고 nscd DNS 캐싱도 지원합니다.
int
Curl_getaddrinfo_ex(const char *nodename,
const char *servname,
const struct addrinfo *hints,
Curl_addrinfo **result)
{
...
error = getaddrinfo(nodename, servname, hints, &aihead);
if(error)
return error;
...
}(1) 자바 표준 라이브러리 HttpURLConnection
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
public class HttpUrlConnectionDemo {
public static void main(String[] args) throws Exception {
String urlString = "http://example.my.com/";
int num = 0;
while (num < 5) {
URL url = new URL(urlString);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.setDoOutput(true);
OutputStream os = conn.getOutputStream();
os.flush();
os.close();
if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
InputStream is = conn.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
StringBuilder sb = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
sb.append(line);
}
System.out.println("rsp:" + sb.toString());
} else {
System.out.println("rsp code:" + conn.getResponseCode());
}
num++;
}
}
}测试结果显示 Java 标准库 HttpURLConnection 是支持 DNS 缓存,5 次请求中只有一次 DNS 请求。
(2)Apache httpcomponents-client
import java.util.ArrayList;
import java.util.List;
import org.apache.hc.client5.http.classic.methods.HttpGet;
import org.apache.hc.client5.http.entity.UrlEncodedFormEntity;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.CloseableHttpResponse;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.http.NameValuePair;
import org.apache.hc.core5.http.io.entity.EntityUtils;
import org.apache.hc.core5.http.message.BasicNameValuePair;
public class QuickStart {
public static void main(final String[] args) throws Exception {
int num = 0;
while (num < 5) {
try (final CloseableHttpClient httpclient = HttpClients.createDefault()) {
final HttpGet httpGet = new HttpGet("http://example.my.com/");
try (final CloseableHttpResponse response1 = httpclient.execute(httpGet)) {
System.out.println(response1.getCode() + " " + response1.getReasonPhrase());
final HttpEntity entity1 = response1.getEntity();
EntityUtils.consume(entity1);
}
}
num++;
}
}
}测试结果显示 Apache httpcomponents-client 支持 DNS 缓存,5 次请求中只有一次 DNS 请求。
从测试中发现 Java 的虚拟机实现一套 DNS 缓存,即实现在 java.net.InetAddress 的一个简单的 DNS 缓存机制,默认为缓存 30 秒,可以通过 networkaddress.cache.ttl 修改默认值,缓存范围为 JVM 虚拟机进程,也就是说同一个 JVM 进程中,30秒内一个域名只会请求DNS服务器一次。同时 Java 也是支持 nscd 的 DNS 缓存,估计底层调用 getaddrinfo 函数,并且 nscd 的缓存级别比 Java 虚拟机的 DNS 缓存高。
# 默认缓存 ttl 在 jre/lib/security/java.security 修改,其中 0 是不缓存,-1 是永久缓存 networkaddress.cache.ttl=10 # 这个参数 sun.net.inetaddr.ttl 是以前默认值,目前已经被 networkaddress.cache.ttl 取代
随着云原生技术的发展,Go 语言逐渐成为云原生的第一语言,很有必要验证一下 Go 的标准库是否支持 DNS 缓存。通过我们测试验证发现 Go 的标准库 net.http 是不支持 DNS 缓存,也是不支持 nscd 缓存,应该是没有调用 glibc 的库函数,也没有实现类似 getaddrinfo 函数的功能。这个跟 Go语言的自举有关系,Go 从 1.5 开始就基本全部由 Go(.go) 和汇编 (.s) 文件写成的,以前版本的 C(.c) 文件被全部重写。不过有一些第三方 Go 版本 DNS 缓存库,可以自己在应用层实现,还可以使用 fasthttp 库的 httpclient。
(1)标准库net.http
package main
import (
"flag"
"fmt"
"io/ioutil"
"net/http"
"time"
)
var httpUrl string
func main() {
flag.StringVar(&httpUrl, "url", "", "url")
flag.Parse()
getUrl := fmt.Sprintf("http://%s/", httpUrl)
fmt.Printf("url: %sn", getUrl)
for i := 0; i < 5; i++ {
_, buf, err := httpGet(getUrl)
if err != nil {
fmt.Printf("err: %vn", err)
return
}
fmt.Printf("resp: %sn", string(buf))
time.Sleep(10 * time.Second)# 等待10s发起另一个请求
}
}
func httpGet(url string) (int, []byte, error) {
client := createHTTPCli()
resp, err := client.Get(url)
if err != nil {
return -1, nil, fmt.Errorf("%s err [%v]", url, err)
}
defer resp.Body.Close()
buf, err := ioutil.ReadAll(resp.Body)
if err != nil {
return resp.StatusCode, buf, err
}
return resp.StatusCode, buf, nil
}
func createHTTPCli() *http.Client {
readWriteTimeout := time.Duration(30) * time.Second
tr := &http.Transport{
DisableKeepAlives: true,//设置短连接
IdleConnTimeout: readWriteTimeout,
}
client := &http.Client{
Timeout: readWriteTimeout,
Transport: tr,
}
return client
}从测试结果来看,net.http 每次都去 DNS 查询,不支持 DNS 缓存。
(2)fasthttp 库
fasthttp 库是 Go 版本高性能 HTTP 库,通过极致的性能优化,性能是标准库 net.http 的 10 倍,其中一项优化就是支持 DNS 缓存,我们可以从其源码看到
//主要在fasthttp/tcpdialer.go中
type TCPDialer struct {
...
// This may be used to override DNS resolving policy, like this:
// var dialer = &fasthttp.TCPDialer{
//Resolver: &net.Resolver{
//PreferGo: true,
//StrictErrors: false,
//Dial: func (ctx context.Context, network, address string) (net.Conn, error) {
//d := net.Dialer{}
//return d.DialContext(ctx, "udp", "8.8.8.8:53")
//},
//},
// }
Resolver Resolver
// DNSCacheDuration may be used to override the default DNS cache duration (DefaultDNSCacheDuration)
DNSCacheDuration time.Duration
...
}可以参考如下方法使用 fasthttp client 端
func main() {
// You may read the timeouts from some config
readTimeout, _ := time.ParseDuration("500ms")
writeTimeout, _ := time.ParseDuration("500ms")
maxIdleConnDuration, _ := time.ParseDuration("1h")
client = &fasthttp.Client{
ReadTimeout: readTimeout,
WriteTimeout:writeTimeout,
MaxIdleConnDuration: maxIdleConnDuration,
NoDefaultUserAgentHeader:true, // Don't send: User-Agent: fasthttp
DisableHeaderNamesNormalizing: true, // If you set the case on your headers correctly you can enable this
DisablePathNormalizing:true,
// increase DNS cache time to an hour instead of default minute
Dial: (&fasthttp.TCPDialer{
Concurrency:4096,
DNSCacheDuration: time.Hour,
}).Dial,
}
sendGetRequest()
sendPostRequest()
}(3)第三方DNS缓存库
这个是 github 中的一个 Go 版本 DNS 缓存库
可以参考如下代码,在HTTP库中支持DNS缓存
r := &dnscache.Resolver{}
t := &http.Transport{
DialContext: func(ctx context.Context, network string, addr string) (conn net.Conn, err error) {
host, port, err := net.SplitHostPort(addr)
if err != nil {
return nil, err
}
ips, err := r.LookupHost(ctx, host)
if err != nil {
return nil, err
}
for _, ip := range ips {
var dialer net.Dialer
conn, err = dialer.DialContext(ctx, network, net.JoinHostPort(ip, port))
if err == nil {
break
}
}
return
},
}(1)requests 库
#!/bin/python
import requests
url = 'http://example.my.com/'
num = 0
while num < 5:
headers={"Connection":"close"} # 开启短连接
r = requests.get(url,headers = headers)
print(r.text)
num +=1(2)httplib2 库
#!/usr/bin/env python
import httplib2
http = httplib2.Http()
url = 'http://example.my.com/'
num = 0
while num < 5:
loginHeaders={
'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.0 Chrome/30.0.1599.101 Safari/537.36',
'Connection': 'close'# 开启短连接
}
response, content = http.request(url, 'GET', headers=loginHeaders)
print(response)
print(content)
num +=1(3)urllib2 库
#!/bin/python
import urllib2
import cookielib
httpHandler = urllib2.HTTPHandler(debuglevel=1)
httpsHandler = urllib2.HTTPSHandler(debuglevel=1)
opener = urllib2.build_opener(httpHandler, httpsHandler)
urllib2.install_opener(opener)
loginHeaders={
'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.0 Chrome/30.0.1599.101 Safari/537.36',
'Connection': 'close' # 开启短连接
}
num = 0
while num < 5:
request=urllib2.Request('http://example.my.com/',headers=loginHeaders)
response = urllib2.urlopen(request)
page=''
page= response.read()
print response.info()
print page
num +=1Python 测试三种库都是支持 nscd 的 DNS 缓存的(推测底层也是调用 getaddrinfo 函数),以上测试时使用 HTTP 短连接,都在 python2 环境测试。
针对 HTTP 客户端来说,可以优先开启 HTTP 的 keep-alive 模式,可以复用 TCP 连接,这样可以减少 TCP 握手耗时和重复请求域名解析,然后再开启 nscd 缓存,除了 Go 外,C/C++、Java、Python 都可支持 DNS 缓存,减少 DNS查询耗时。
这里只分析了常用 C/C++、Java、Go、Python 语言,欢迎熟悉其他语言的小伙伴补充。
在由于某些特殊原因,自研或非自研客户端本身无法提供 DNS 缓存支持的情况下,建议管理人员在其所在系统环境中部署DNS缓存程序;
现介绍 Unix/类 Unix 系统适用的几款常见轻量级 DNS 缓存程序。而多数桌面操作系统如 Windows、MacOS 和几乎所有 Web 浏览器均自带 DNS 缓存功能,本文不再赘述。
P.S. DNS 缓存服务请务必确保随系统开机启动;
name service cache daemon 即装即用,通常为 linux 系统默认安装,相关介绍可参考其 manpage:man nscd;man nscd.conf
(1)安装方法:通过系统自带软件包管理程序安装,如 yum install nscd
(2)缓存管理(清除):
1.service nscd restart 重启服务清除所有缓存;
2.nscd -i hosts 清除 hosts 表中的域名缓存(hosts 为域名缓存使用的 table 名称,nscd 有多个缓存 table,可参考程序相关 manpage)
较为轻量,可选择其作为 nscd 替代,通常需单独安装
(1)安装方法:通过系统自带软件包管理程序安装,如 yum install dnsmasq
(2)核心文件介绍(基于 Dnsmasq version 2.86,较低版本略有差异,请参考对应版本文档如 manpage 等)
(3)/etc/default/dnsmasq 提供六个变量定义以支持六种控制类功能
(4)/etc/dnsmasq.d/ 此目录含 README 文件,可参考;目录内可以存放自定义配置文件
(5)/etc/dnsmasq.conf 主配置文件,如仅配置 dnsmasq 作为缓存程序,可参考以下配置
listen-address=127.0.0.1#程序监听地址,务必指定本机内网或回环地址,避免暴露到公网环境 port=53 #监听端口 resolv-file=/etc/dnsmasq.d/resolv.conf#配置dnsmasq向自定义文件内的 nameserver 转发 dns 解析请求 cache-size=150#缓存记录条数,默认 150 条,可按需调整、适当增大 no-negcache #不缓存解析失败的记录,主要是 NXDOMAIN,即域名不存在 log-queries=extra #开启日志记录,指定“=extra”则记录更详细信息,可仅在问题排查时开启,平时关闭 log-facility=/var/log/dnsmasq.log #指定日志文件 #同时需要将本机 /etc/resolv.conf 第一个 nameserver 指定为上述监听地址,这样本机系统的 dns 查询请求才会通过 dnsmasq 代为转发并缓存响应结果。 #另 /etc/resolv.conf 务必额外配置 2 个 nameserver,以便 dnsmasq 服务异常时支持系统自动重试,注意 resolv.conf 仅读取前 3 个 nameserver
(6)缓存管理(清除):
1.kill -s HUP `pidof dnsmasq` 推荐方式,无需重启服务
2.kill -s TERM `pidof dnsmasq` 或 service dnsmasq stop
3.service dnsmasq force-reload 或 service dnsmasq restart
(7)官方文档:https://thekelleys.org.uk/dnsmasq/doc.html
以 linux 操作系统为例,常用的网络请求命令行工具常常通过调用 getaddrinfo() 完成域名解析过程,如 ping、telnet、curl、wget 等,但其可能出于通用性的考虑,均被设计为对同一个域名每次解析会发起两个请求,分别查询域名 A 记录(即 IPV4 地址)和 AAAA 记录(即 IPV6 地址)。
因目前大部分公司的内网环境及云上内网环境还未使用 ipv6 网络,故通常 DNS 系统不为内网域名添加 AAAA 记录,徒劳请求域名的 AAAA 记录会造成前端应用和后端 DNS 服务不必要的资源开销。因此,仅需请求内网域名的业务,如决定自研客户端,建议开发人员视实际情况,可将其设计为仅请求内网域名 A 记录,尤其当因故无法实施本地缓存机制时。
客户端需严格规范域名/主机名的处理逻辑,避免产生大量对不存在域名的解析请求(确保域名从权威渠道获取,避免故意或意外使用随机构造的域名、主机名),因此类请求的返回结果(NXDOMAIN)通常不被缓存或缓存时长较短,且会触发客户端重试,对后端 DNS 系统造成一定影响。
위 내용은 각 개발 언어에 대한 DNS 캐시 구성 권장 사항의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



