

데이터 예측 및 분석을 위한 기계 학습 모델의 인기가 높아짐에 따라 랜덤 포레스트 알고리즘의 사용이 탄력을 받고 있습니다. Random Forest는 기계 학습 분야의 회귀 및 분류 작업에 사용되는 지도 학습 알고리즘입니다. 이는 훈련 시간에 많은 수의 결정 트리를 구축하고 클래스 모드(분류) 또는 단일 트리의 평균 예측(회귀) 중 하나를 출력하는 방식으로 작동합니다.
이 기사에서는 실제 온라인 데이터 세트를 사용하여 Random Forest 알고리즘을 구현하는 방법에 대해 설명합니다. 또한 각 단계에 대한 자세한 코드 설명과 설명은 물론 모델 성능 및 시각화 평가도 제공합니다.
우리가 사용할 데이터 세트는 공개적으로 사용 가능하고 UCI 기계 학습 저장소를 통해 액세스할 수 있는 "Breast Cancer Wisconsin (Diagnostic) Dataset"입니다. 데이터세트에는 30개의 속성과 2개의 범주(악성 및 양성)가 포함된 569개의 인스턴스가 있습니다. 우리의 목표는 30가지 속성을 기반으로 이러한 인스턴스를 분류하고 양성인지 악성인지를 결정하는 것입니다. https://www.kaggle.com/datasets/uciml/breast-cancer-wisconsin-data에서 데이터 세트를 다운로드할 수 있습니다.
먼저 필요한 라이브러리를 가져옵니다.
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
다음으로 데이터세트를 로드합니다.
df = pd.read_csv(r"C:UsersUserDownloadsdatabreast_cancer_wisconsin_diagnostic_dataset.csv") df
출력:
모델을 구축하기 전에 데이터를 전처리해야 합니다. 'id' 및 'Unnamed: 32' 열은 우리 모델에 쓸모가 없으므로 이를 제거하겠습니다:
df = df.drop([ 'id' , 'Unnamed: 32' ], axis=1) df
출력:
다음으로 " 진단" 열이 대상 변수에 할당되고 기능에서 제거되었습니다.
target = df['diagnosis']
features = df.drop('diagnosis', axis=1)이제 데이터 세트를 훈련 세트와 테스트 세트로 분할하겠습니다. 데이터의 70%는 훈련용으로, 30%는 테스트용으로 사용합니다.
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.3, random_state=42)
데이터를 사전 처리하고 훈련 세트와 테스트 세트로 분할하면 이제 랜덤 포레스트 모델을 구축할 수 있습니다.
rf = RandomForestClassifier(n_estimators=100, random_state=42) rf.fit(X_train, y_train)
여기서는 포리스트의 의사결정 트리 수를 100으로 설정하고 결과의 반복성을 보장하기 위해 무작위 상태를 설정했습니다.
이제 모델의 성능을 평가할 수 있습니다. 평가를 위해 정확도 점수, 혼동 행렬 및 분류 보고서를 사용합니다.
y_pred = rf.predict(X_test)
# 准确度分数
print("Accuracy Score:", accuracy_score(y_test, y_pred))
# Confusion Matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:n", conf_matrix)
# Classification Report
class_report = classification_report(y_test, y_pred)
print("Classification Report:n", class_report)출력:
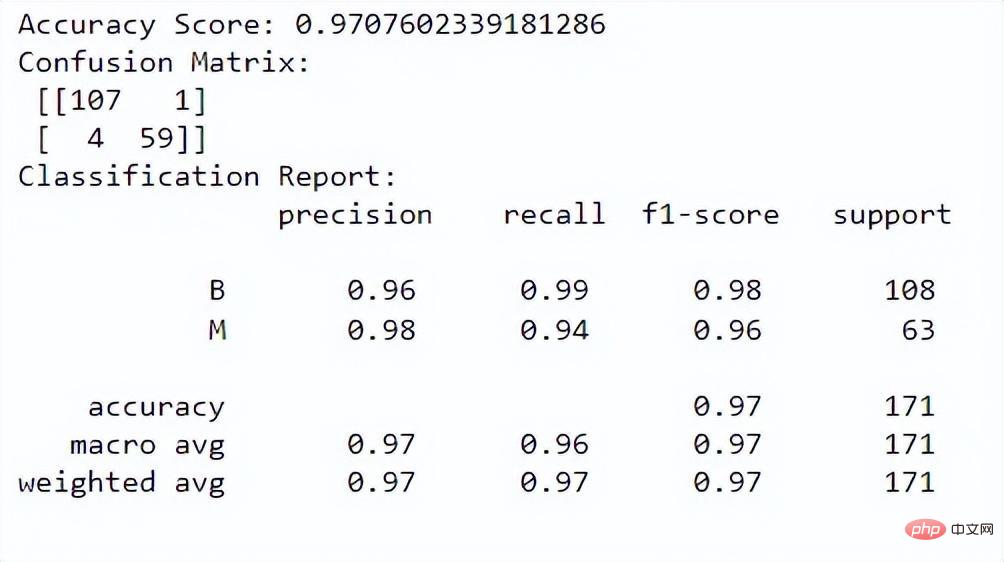
정확도 점수는 모델이 인스턴스를 올바르게 분류하는 데 얼마나 잘 작동하는지 알려줍니다. 혼동 행렬을 통해 모델의 분류 성능을 더 잘 이해할 수 있습니다. 분류 보고서는 두 클래스 모두에 대한 정밀도, 재현율, f1 점수 및 지원 값을 제공합니다.
마지막으로 모델의 각 기능의 중요성을 시각화할 수 있습니다. 기능 중요도 값을 보여주는 막대 차트를 만들어 이를 수행할 수 있습니다.
importance = rf.feature_importances_ feat_imp = pd.Series(importance, index=features.columns) feat_imp = feat_imp.sort_values(ascending=False)
plt.figure(figsize=(12,8))
feat_imp.plot(kind='bar')
plt.ylabel('Feature Importance Score')
plt.title("Feature Importance")
plt.show()출력:
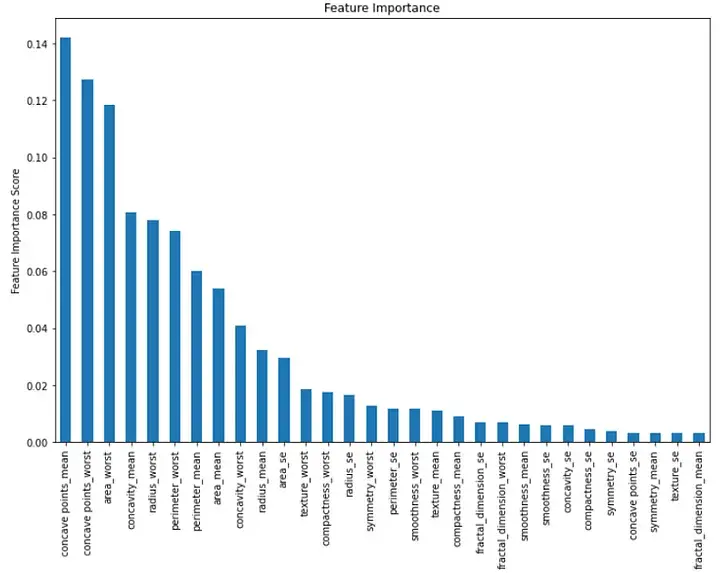
이 막대 차트는 내림차순 성별에서 각 기능의 중요성을 보여줍니다. 처음 세 가지 중요한 특징은 "평균 오목", "최악의 오목" 및 "최악의 영역"임을 알 수 있습니다.
요약하자면, 기계 학습에서 랜덤 포레스트 알고리즘을 구현하는 것은 분류 작업을 위한 강력한 도구입니다. 이를 사용하여 여러 기능을 기반으로 인스턴스를 분류하고 모델 성능을 평가할 수 있습니다. 본 논문에서는 온라인 실제 데이터 세트를 사용하고 각 단계에 대한 자세한 코드 설명과 설명은 물론 모델 성능 및 시각화 평가도 제공합니다.
위 내용은 기계 학습에서 Random Forest 알고리즘을 구현하는 방법에 대한 가이드의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



