

이미지 압축에 노드를 사용하는 방법은 무엇인가요? 다음 기사에서는 PNG 이미지를 예로 들어 이미지 압축 방법을 소개합니다.

최근에는 이미지 처리 서비스를 제공하고 싶은데요, 그 중 하나가 이미지 압축 기능을 구현하는 것입니다. 예전에는 프론트엔드를 개발할 때 그냥 기성화된 캔버스 API를 이용해 처리할 수 있었는데, 백엔드에서도 기성 API가 있을 수도 있는데 잘 모르겠습니다. 곰곰히 생각해 보니 영상 압축의 원리를 자세히 이해한 적이 없어서 그냥 이번 기회에 좀 연구하고 공부해서 기록하려고 이 글을 썼습니다. 언제나 그렇듯, 뭔가 잘못되면 DDDD(동생을 데리고 가세요).
먼저 이미지를 백엔드에 업로드하고 백엔드가 어떤 매개변수를 받는지 확인합니다. 여기서는 백엔드로 Node.js(Nest)를 사용하고, 예로는 PNG 이미지를 사용합니다.
인터페이스와 매개변수는 다음과 같이 인쇄됩니다.
@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> <br/> return {<br/> file<br/> }<br/>}<br/>
압축을 수행하려면 이미지 데이터를 가져와야 합니다. 보시다시피, 이미지 데이터를 숨길 수 있는 유일한 것은 이 버퍼 문자열입니다. 그러면 이 버퍼 문자열은 무엇을 설명합니까? 먼저 PNG가 무엇인지 알아야 합니다. [추천 관련 튜토리얼: nodejs 비디오 튜토리얼, 프로그래밍 교육]
PNG의 WIKI 주소입니다.
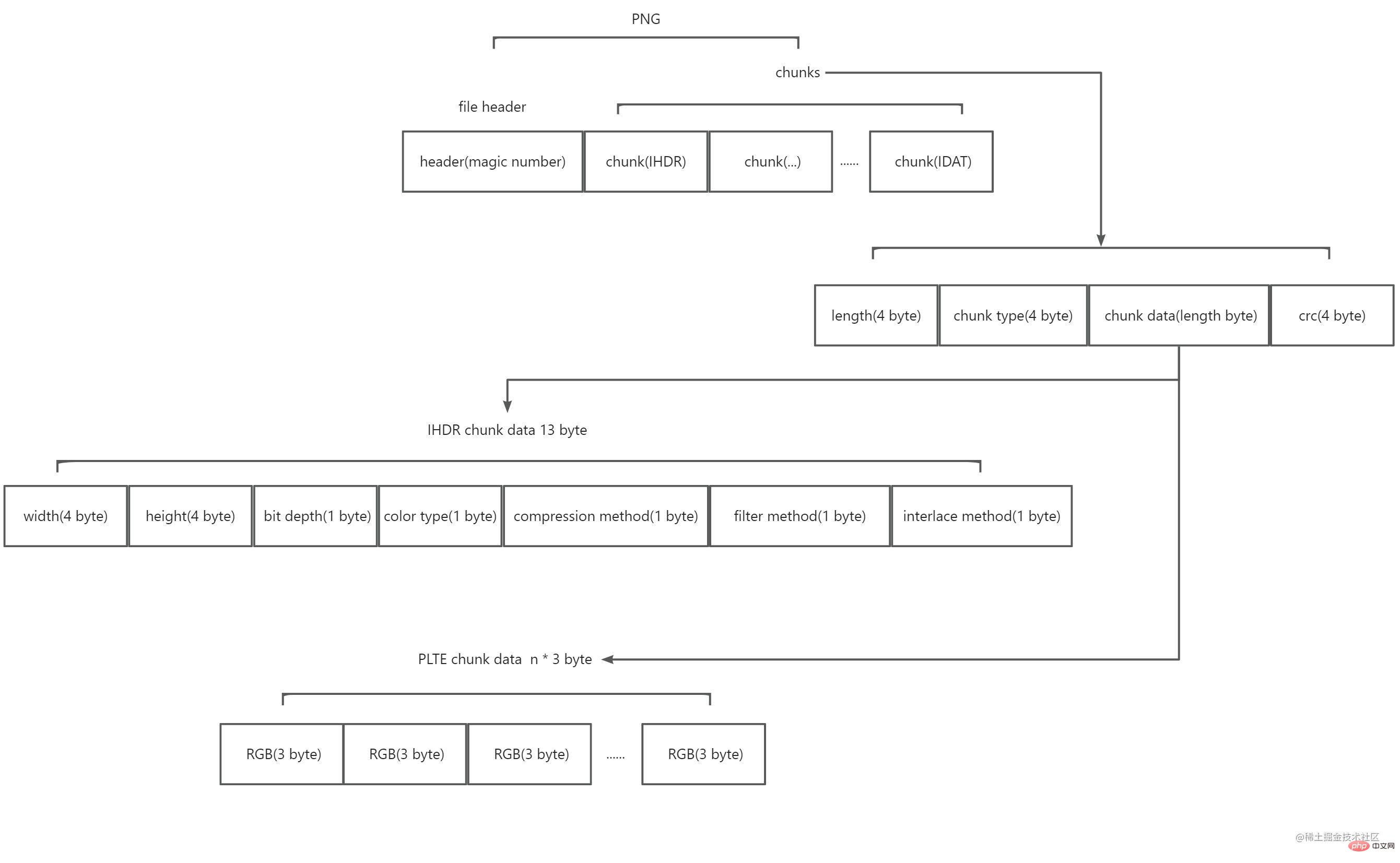
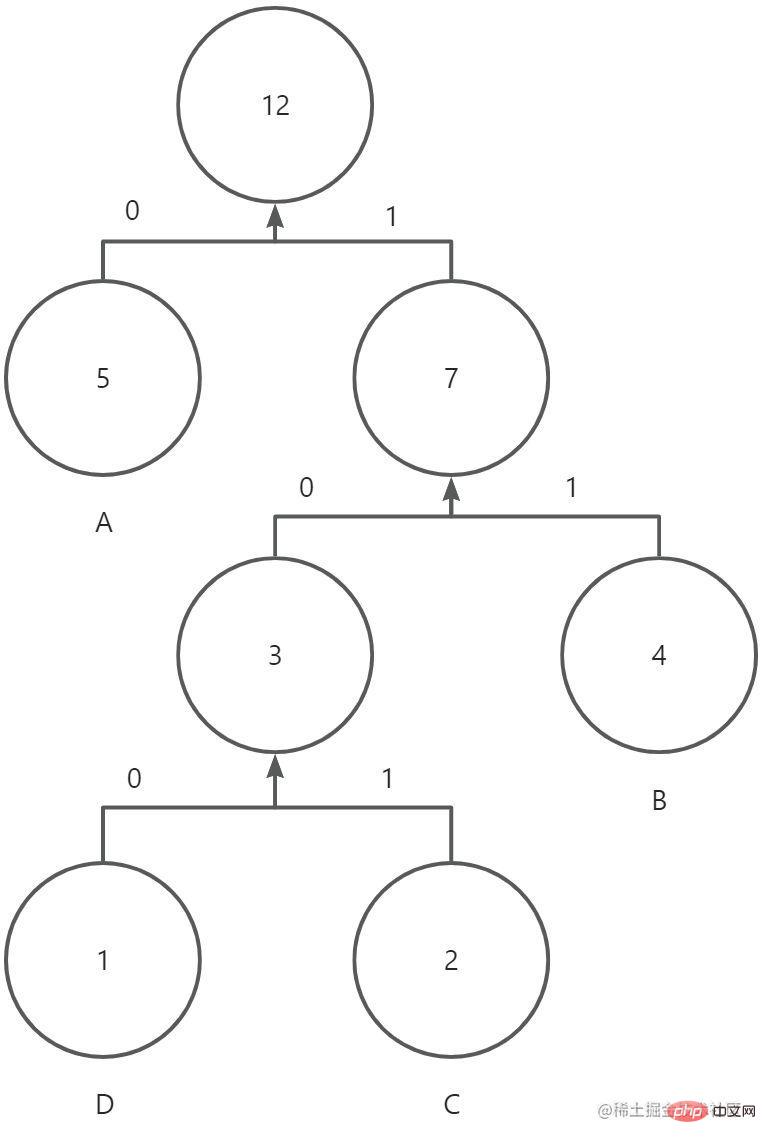
읽고 나서 PNG가 8바이트 파일 헤더와 여러 청크로 구성되어 있다는 것을 알게 되었습니다. 개략도는 다음과 같습니다.
그중
파일 헤더는 소위 매직 넘버로 구성됩니다. 값은 89 50 4e 47 0d 0a 1a 0a(16진수)입니다. 이 데이터 문자열을 PNG 형식으로 표시합니다.
블록은 두 가지 유형으로 나누어집니다. 하나는 중요 청크(중요 청크)이고 다른 하나는 보조 청크(보조 청크)입니다. 키 블록은 필수적입니다. 키 블록이 없으면 디코더는 그림을 올바르게 식별하고 표시할 수 없습니다. 보조 블록은 선택 사항이며 일부 소프트웨어는 이미지 처리 후 보조 블록을 전달할 수 있습니다. 각 블록은 네 부분으로 구성됩니다. 4바이트는 이 블록의 내용이 얼마나 긴지 설명하고, 4바이트는 이 블록의 유형을 설명하고, n바이트는 블록의 내용을 설명합니다(n은 이전 4바이트 값의 크기, 즉, 블록의 최대 길이는 28*4)이며, 4바이트 CRC 검사는 블록의 데이터를 확인하고 블록의 끝을 표시합니다. 그 중 블록 유형의 4바이트 값은 4개의 acsii 코드입니다. 대문자의 첫 글자 는 키 블록을 의미하고, 소문자의 는 보조 블록을 의미합니다. 대문자는 공개 를 의미하고 는 공개 를 의미합니다. 세 번째 문자 는 대문자여야 합니다. 네 번째 문자는 이후의 PNG 확장에 사용됩니다. 인식되지 않는 경우, 대문자는 키 블록이 수정되지 않은 경우에만 안전하게 복사할 수 있다는 의미이고, 소문자는 모두 복사해도 안전하다는 의미입니다. PNG는 공식적으로 정의된 다양한 블록 유형을 제공합니다. 여기서는 IHDR, PLTE, IDAT 및 IEND와 같은 주요 블록 유형만 알면 됩니다.
IHDR이어야 합니다. IHDR의 블록 콘텐츠는 13바이트로 고정되어 있으며 이미지의 다음 정보를 포함합니다: 너비(4바이트) 및 높이(4바이트)
비트 깊이(1바이트, 값은 1, 2, 4, 8 또는 16) & 색상 유형 색상 유형(1바이트, 값은 0, 2, 3, 4 또는 6)
압축 방법 압축 방법(1바이트, 값은 0) & 필터 방법 필터 방법(1바이트, 값은 0) 0) 0)
인터레이스 방식 (1바이트, 값은 0 또는 1)
너비와 높이는 이해하기 쉽고, 나머지는 낯설어 보여서 다음에 설명하겠습니다.
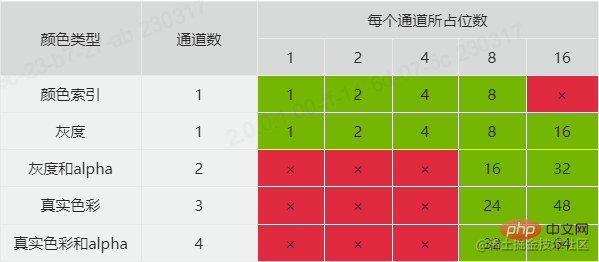
비트 심도를 설명하기 전에 먼저 색상 유형을 살펴보겠습니다. 색상 유형에는 5가지 값이 있습니다.
3은 색상 인덱스(색인)를 나타냅니다. 또한 색상의 인덱스 값을 나타내는 채널이 하나만 있습니다. 이 유형에는 색상 목록 세트가 장착되어 있는 경우가 많으며 색인 값과 색상 목록 쿼리를 기반으로 특정 색상을 얻습니다.
4는 회색조와 알파를 나타냅니다. 회색조 채널 외에도 투명도를 제어하는 추가 알파 채널이 있습니다.
6은 실제 색상과 4개의 채널이 있는 알파를 의미합니다.
채널에 대해 이야기하는 이유는 여기서 비트 심도와 관련이 있기 때문입니다. 비트 깊이 값은 각 채널이 차지하는 비트 수를 정의합니다. 비트 깊이와 색상 유형을 결합하면 이미지의 색상 형식 유형과 각 픽셀이 차지하는 메모리 크기를 알 수 있습니다. PNG에서 공식적으로 지원하는 조합은 다음과 같습니다.
필터링 및 압축은 PNG가 이미지의 원본 데이터가 아니라 처리된 데이터를 저장하기 때문에 PNG 이미지가 메모리를 덜 차지합니다. PNG는 두 단계를 사용하여 이미지 데이터를 압축하고 변환합니다.
첫 번째 단계는 필터링입니다. 필터링의 목적은 규칙을 통과한 후 원본 이미지 데이터가 더 높은 압축률을 달성할 수 있도록 하는 것입니다. 예를 들어 그라데이션 그림이 있는 경우 왼쪽에서 오른쪽으로 색상은 [#000000, #000001, #000002, ..., #ffffff]이며 오른쪽의 픽셀은 다음과 같다는 규칙에 동의할 수 있습니다. 항상 이전 왼쪽 픽셀과 비교하면 처리된 데이터가 [1, 1, 1, ..., 1]이 됩니다. 이렇게 하면 더 나은 압축이 가능합니까? 현재 PNG에는 하나의 필터링 방법만 있는데, 이는 인접 픽셀을 예측 값으로 기반으로 하고 현재 픽셀에서 예측 값을 빼는 것입니다. 필터링에는 5가지 종류가 있습니다. (현재 이런 종류의 값이 어디에 저장되어 있는지 모르겠습니다. IDAT에 있을 수도 있습니다. 찾으면 이 괄호 안의 를 삭제하세요. 이런 종류의 값인 것으로 판단됩니다. ) 다음과 같습니다. 표에 표시된 대로
| 바이트를 입력하세요. | 필터 이름 | 예측 값 |
|---|---|---|
| 0 | None | 처리 없음 |
| 1 | Sub | 왼쪽의 이웃 픽셀 |
| 2 | Up | 위의 인접 픽셀 |
| 3 | Average | Math.floor((왼쪽의 인접 픽셀 + 위의 픽셀) / 2) |
| 4 | Paeth | (왼쪽 인접 픽셀 + 상단 인접 픽셀 - 왼쪽 상단 픽셀)에 가장 가까운 값 |
第二步,压缩。PNG也只有一种压缩算法,使用的是DEFLATE算法。这里不细说,具体看下面的章节。
交错方式,有两种值。0表示不处理,1表示使用Adam7 算法进行处理。我没有去详细了解该算法,简单来说,当值为0时,图片需要所有数据都加载完毕时,图片才会显示。而值为1时,Adam7会把图片划分多个区域,每个区域逐级加载,显示效果会有所优化,但通常会降低压缩效率。加载过程可以看下面这张gif图。

PLTE的块内容为一组颜色列表,当颜色类型为颜色索引时需要配置。值得注意的是,颜色列表中的颜色一定是每个通道8bit,每个像素24bit的真实色彩列表。列表的长度,可以比位深约定的少,但不能多。比如位深是2,那么22,最多4种颜色,列表长度可以为3,但不能为5。
IDAT的块内容是图片原始数据经过PNG压缩转换后的数据,它可能有多个重复的块,但必须是连续的,并且只有当上一个块填充满时,才会有下一个块。
IEND的块内容为0 byte,它表示图片的结束。
阅读到这里,我们把上面的接口改造一下,解析这串buffer。
@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> const buffer = file.buffer;<br/><br/> const result = {<br/> header: buffer.subarray(0, 8).toString('hex'),<br/> chunks: [],<br/> size: file.size,<br/> };<br/><br/> let pointer = 8;<br/> while (pointer < buffer.length) {<br/> let chunk = {};<br/> const length = parseInt(buffer.subarray(pointer, pointer + 4).toString('hex'), 16);<br/> const chunkType = buffer.subarray(pointer + 4, pointer + 8).toString('ascii');<br/> const crc = buffer.subarray(pointer + length, pointer + length + 4).toString('hex');<br/> chunk = {<br/> ...chunk,<br/> length,<br/> chunkType,<br/> crc,<br/> };<br/><br/> switch (chunkType) {<br/> case 'IHDR':<br/> const width = parseInt(buffer.subarray(pointer + 8, pointer + 12).toString('hex'), 16);<br/> const height = parseInt(buffer.subarray(pointer + 12, pointer + 16).toString('hex'), 16);<br/> const bitDepth = parseInt(<br/> buffer.subarray(pointer + 16, pointer + 17).toString('hex'),<br/> 16,<br/> );<br/> const colorType = parseInt(<br/> buffer.subarray(pointer + 17, pointer + 18).toString('hex'),<br/> 16,<br/> );<br/> const compressionMethod = parseInt(<br/> buffer.subarray(pointer + 18, pointer + 19).toString('hex'),<br/> 16,<br/> );<br/> const filterMethod = parseInt(<br/> buffer.subarray(pointer + 19, pointer + 20).toString('hex'),<br/> 16,<br/> );<br/> const interlaceMethod = parseInt(<br/> buffer.subarray(pointer + 20, pointer + 21).toString('hex'),<br/> 16,<br/> );<br/><br/> chunk = {<br/> ...chunk,<br/> width,<br/> height,<br/> bitDepth,<br/> colorType,<br/> compressionMethod,<br/> filterMethod,<br/> interlaceMethod,<br/> };<br/> break;<br/> case 'PLTE':<br/> const colorList = [];<br/> const colorListStr = buffer.subarray(pointer + 8, pointer + 8 + length).toString('hex');<br/> for (let i = 0; i < colorListStr.length; i += 6) {<br/> colorList.push(colorListStr.slice(i, i + 6));<br/> }<br/> chunk = {<br/> ...chunk,<br/> colorList,<br/> };<br/> break;<br/> default:<br/> break;<br/> }<br/> result.chunks.push(chunk);<br/> pointer = pointer + 4 + 4 + length + 4;<br/> }<br/><br/> return result;<br/>}<br/>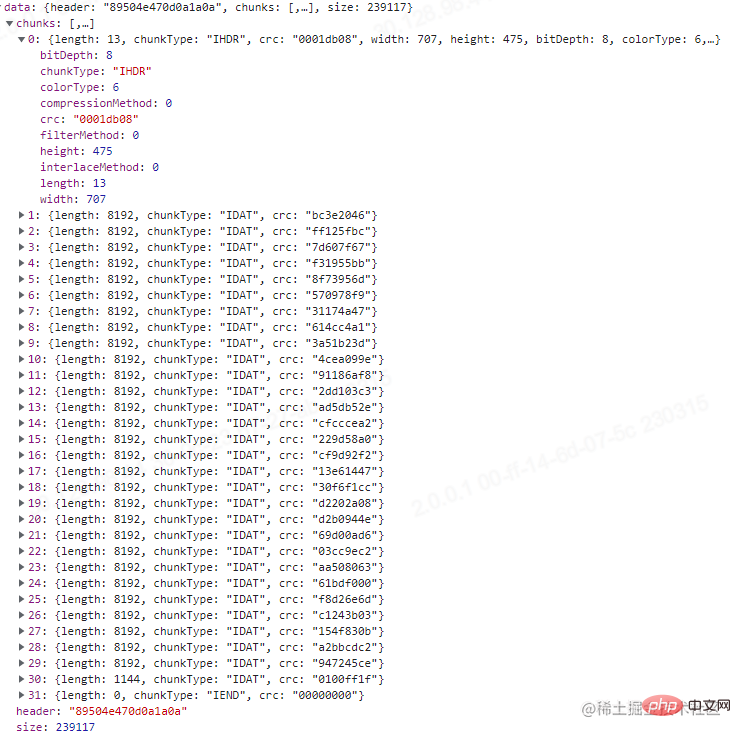
这里我测试用的图没有PLTE,刚好我去TinyPNG压缩我那张测试图之后进行上传,发现有PLTE块,可以看一下,结果如下图。
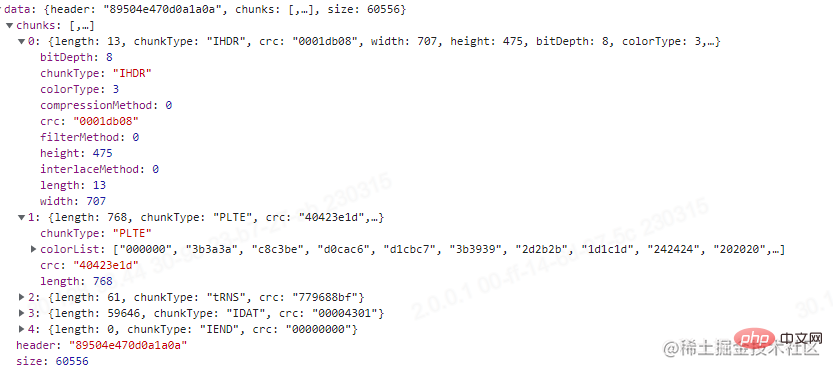
通过比对这两张图,压缩图片的方式我们也能窥探一二。
前面说过,PNG使用的是一种叫DEFLATE的无损压缩算法,它是Huffman Coding跟LZ77的结合。除了PNG,我们经常使用的压缩文件,.zip,.gzip也是使用的这种算法(7zip算法有更高的压缩比,也可以了解下)。要了解DEFLATE,我们首先要了解Huffman Coding和LZ77。
哈夫曼编码忘记在大学的哪门课接触过了,它是一种根据字符出现频率,用最少的字符替换出现频率最高的字符,最终降低平均字符长度的算法。
举个例子,有字符串"ABCBCABABADA",如果按照正常空间存储,所占内存大小为12 * 8bit = 96bit,现对它进行哈夫曼编码。
1.统计每个字符出现的频率,得到A 5次 B 4次 C 2次 D 1次
2.对字符按照频率从小到大排序,将得到一个队列D1,C2,B4,A5
3.按顺序构造哈夫曼树,先构造一个空节点,最小频率的字符分给该节点的左侧,倒数第二频率的字符分给右侧,然后将频率相加的值赋值给该节点。接着用赋值后节点的值和倒数第三频率的字符进行比较,较小的值总是分配在左侧,较大的值总是分配在右侧,依次类推,直到队列结束,最后把最大频率和前面的所有值相加赋值给根节点,得到一棵完整的哈夫曼树。
4.对每条路径进行赋值,左侧路径赋值为0,右侧路径赋值为1。从根节点到叶子节点,进行遍历,遍历的结果就是该字符编码后的二进制表示,得到:A(0)B(11)C(101)D(100)。
完整的哈夫曼树如下(忽略箭头,没找到连线- -!):
压缩后的字符串,所占内存大小为5 * 1bit + 4 * 2bit + 2 * 3bit + 1 * 3bit = 22bit。当然在实际传输过程中,还需要把编码表的信息(原始字符和出现频率)带上。因此最终占比大小为 4 * 8bit + 4 * 3bit(频率最大值为5,3bit可以表示)+ 22bit = 66bit(理想状态),小于原有的96bit。
LZ77算法还是第一次知道,查了一下是一种基于字典和滑动窗的无所压缩算法。(题外话:因为Lempel和Ziv在1977年提出的算法,所以叫LZ77,哈哈哈?)
我们还是以上面这个字符串"ABCBCABABADA"为例,现假设有一个4 byte的动态窗口和一个2byte的预读缓冲区,然后对它进行LZ77算法压缩,过程顺序从上往下,示意图如下:

总结下来,就是预读缓冲区在动态窗口中找到最长相同项,然后用长度较短的标记来替代这个相同项,从而实现压缩。从上图也可以看出,压缩比跟动态窗口的大小,预读缓冲区的大小和被压缩数据的重复度有关。
DEFLATE【RFC 1951】是先使用LZ77编码,对编码后的结果在进行哈夫曼编码。我们这里不去讨论具体的实现方法,直接使用其推荐库Zlib,刚好Node.js内置了对Zlib的支持。接下来我们继续改造上面那个接口,如下:
import * as zlib from 'zlib';<br/><br/>@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> const buffer = file.buffer;<br/><br/> const result = {<br/> header: buffer.subarray(0, 8).toString('hex'),<br/> chunks: [],<br/> size: file.size,<br/> };<br/><br/> // 因为可能有多个IDAT的块 需要个数组缓存最后拼接起来<br/> const fileChunkDatas = [];<br/> let pointer = 8;<br/> while (pointer < buffer.length) {<br/> let chunk = {};<br/> const length = parseInt(buffer.subarray(pointer, pointer + 4).toString('hex'), 16);<br/> const chunkType = buffer.subarray(pointer + 4, pointer + 8).toString('ascii');<br/> const crc = buffer.subarray(pointer + length, pointer + length + 4).toString('hex');<br/> chunk = {<br/> ...chunk,<br/> length,<br/> chunkType,<br/> crc,<br/> };<br/><br/> switch (chunkType) {<br/> case 'IHDR':<br/> const width = parseInt(buffer.subarray(pointer + 8, pointer + 12).toString('hex'), 16);<br/> const height = parseInt(buffer.subarray(pointer + 12, pointer + 16).toString('hex'), 16);<br/> const bitDepth = parseInt(<br/> buffer.subarray(pointer + 16, pointer + 17).toString('hex'),<br/> 16,<br/> );<br/> const colorType = parseInt(<br/> buffer.subarray(pointer + 17, pointer + 18).toString('hex'),<br/> 16,<br/> );<br/> const compressionMethod = parseInt(<br/> buffer.subarray(pointer + 18, pointer + 19).toString('hex'),<br/> 16,<br/> );<br/> const filterMethod = parseInt(<br/> buffer.subarray(pointer + 19, pointer + 20).toString('hex'),<br/> 16,<br/> );<br/> const interlaceMethod = parseInt(<br/> buffer.subarray(pointer + 20, pointer + 21).toString('hex'),<br/> 16,<br/> );<br/><br/> chunk = {<br/> ...chunk,<br/> width,<br/> height,<br/> bitDepth,<br/> colorType,<br/> compressionMethod,<br/> filterMethod,<br/> interlaceMethod,<br/> };<br/> break;<br/> case 'PLTE':<br/> const colorList = [];<br/> const colorListStr = buffer.subarray(pointer + 8, pointer + 8 + length).toString('hex');<br/> for (let i = 0; i < colorListStr.length; i += 6) {<br/> colorList.push(colorListStr.slice(i, i + 6));<br/> }<br/> chunk = {<br/> ...chunk,<br/> colorList,<br/> };<br/> break;<br/> case 'IDAT':<br/> fileChunkDatas.push(buffer.subarray(pointer + 8, pointer + 8 + length));<br/> break;<br/> default:<br/> break;<br/> }<br/> result.chunks.push(chunk);<br/> pointer = pointer + 4 + 4 + length + 4;<br/> }<br/><br/> const originFileData = zlib.unzipSync(Buffer.concat(fileChunkDatas));<br/><br/> // 这里原图片数据太长了 我就只打印了长度<br/> return {<br/> ...result,<br/> originFileData: originFileData.length,<br/> };<br/>}<br/>
最终打印的结果,我们需要注意红框的那几个部分。可以看到上图,位深和颜色类型决定了每个像素由4 byte组成,然后由于过滤方式的存在,会在每行的第一个字节进行标记。因此该图的原始数据所占大小为:707 * 475 * 4 byte + 475 * 1 byte = 1343775 byte。正好是我们打印的结果。
我们也可以试试之前TinyPNG压缩后的图,如下:
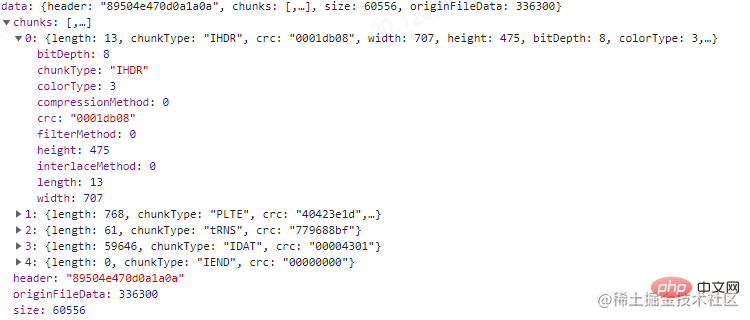
可以看到位深为8,索引颜色类型的图每像素占1 byte。计算得到:707 * 475 * 1 byte + 475 * 1 byte = 336300 byte。结果也正确。
现在再看如何进行图片压缩,你可能很容易得到下面几个结论:
1.减少不必要的辅助块信息,因为辅助块对PNG图片而言并不是必须的。
2.减少IDAT的块数,因为每多一个IDAT的块,就多余了12 byte。
3.降低每个像素所占的内存大小,比如当前是4通道8位深的图片,可以统计整个图片色域,得到色阶表,设置索引颜色类型,降低通道从而降低每个像素的内存大小。
4.等等....
至于JPEG,WEBP等等格式图片,有机会再看。溜了溜了~(还是使用现成的库处理压缩吧)。
好久没写文章,写完才发现语雀不能免费共享,发在这里吧。
更多node相关知识,请访问:nodejs 教程!
위 내용은 이미지 압축에 Node를 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



![Node.js 전체 입문 튜토리얼 [es6+npm+express+webpack+promise]](https://img.php.cn/upload/course/000/000/068/6242b4c8f1a39624.png)

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



