

diff 알고리즘은 동일한 수준의 트리 노드를 비교하는 효율적인 알고리즘으로, 트리를 계층별로 검색하고 탐색할 필요가 없습니다. 그렇다면 diff 알고리즘에 대해 얼마나 알고 있나요? 다음 글은 vue2의 diff 알고리즘에 대한 심층 분석을 제공할 것입니다. 도움이 되길 바랍니다!

flow를 사용하는 것부터 TypeScript를 사용하는 것까지 오랫동안 Vue 2의 소스 코드를 살펴보고 있지만 매번 소스 코드를 열어 만 보입니다. 데이터 초기화 부분도 beforeMount 단계입니다. 저는 VNode(Visual Dom Node, 직접 vdom이라고도 함)를 생성하는 방법과 VNode(diff)를 비교하는 방법을 자세히 연구한 적이 없습니다. ) 구성 요소를 업데이트할 때 beforeMount 的阶段,对于如何生成 VNode(Visual Dom Node, 也可以直接称为 vdom) 以及组件更新时如何比较 VNode(diff)始终没有仔细研究,只知道采用了 双端 diff 算法,至于这个双端是怎么开始怎么结束的也一直没有去看过,所以这次趁写文章的机会仔细研究一下。如果内容有误,希望大家能帮我指出,非常感谢~
在我的理解中,diff 指代的是 differences,即 新旧内容之间的区别计算;Vue 中的 diff 算法,则是通过一种 简单且高效 的手段快速对比出 新旧 VNode 节点数组之间的区别 以便 以最少的 dom 操作来更新页面内容。【相关推荐:vuejs视频教程、web前端开发】
此时这里有两个必须的前提:
对比的是 VNode 数组
同时存在新旧两组 VNode 数组
所以它一般只发生在 数据更新造成页面内容需要更新时执行,即 renderWatcher.run()。
上面说了,diff 中比较的是 VNode,而不是真实的 dom 节点,相信为什么会使用 VNode 大部分人都比较清楚,笔者就简单带过吧?~
在 Vue 中使用 VNode 的原因大致有两个方面:
VNode 作为框架设计者根据框架需求设计的 JavaScript 对象,本身属性相对真实的 dom 节点要简单,并且操作时不需要进行 dom 查询,可以大幅优化计算时的性能消耗
在 VNode 到真实 dom 的这个渲染过程,可以根据不同平台(web、微信小程序)进行不同的处理,生成适配各平台的真实 dom 元素
在 diff 过程中会遍历新旧节点数据进行对比,所以使用 VNode 能带来很大的性能提升。
在网页中,真实的 dom 节点都是以 树 的形式存在的,根节点都是 ,为了保证虚拟节点能与真实 dom 节点一致,VNode 也一样采用的是树形结构。
如果在组件更新时,需要对比全部 VNode 节点的话,新旧两组节点都需要进行 深度遍历 和比较,会产生很大的性能开销;所以,Vue 中默认 同层级节点比较,即 如果新旧 VNode 树的层级不同的话,多余层级的内容会直接新建或者舍弃,只在同层级进行 diff 操作。
一般来说,diff 操作一般发生在 v-for 循环或者有 v-if/v-else 、component 这类 动态生成 的节点对象上(静态节点一般不会改变,对比起来很快),并且这个过程是为了更新 dom,所以在源码中,这个过程对应的方法名是 updateChildren,位于 src/core/vdom/patch.ts 中。如下图:
이라고 부르는 방법이기도 합니다.这里回顾一下 Vue 组件实例的创建与更新过程:
首先是
beforeCreate到created阶段,主要进行数据和状态以及一些基础事件、方法的处理然后,会调用
을 사용한다는 것만 알고 있습니다. 이 이중 종료 프로세스가 어떻게 시작되고 끝나는지에 대해서는 한 번도 본 적이 없어서 기사를 작성하여 연구했습니다. 이번에는 조심스럽게. 내용이 잘못된 경우 지적해 주시면 감사하겠습니다~🎜$mount(vm.$options.el)方法进入Vnode与 dom 的创建和挂载阶段,也就是beforeMount到mounted이중 종료가 diff 알고리즘🎜diff가 무엇인가요?🎜
🎜제가 이해한 바에 따르면 diff는 🎜이전 콘텐츠와 새 콘텐츠🎜 간의 차이 계산인차이를 참조합니다. Vue의 diff 알고리즘은 🎜간단하고 효율적인🎜 방법🎜을 통해 🎜이전 VNode 노드 배열과 새 VNode 노드 배열의 차이를 빠르게 비교합니다. 최소한의 DOM 작업으로 🎜페이지 콘텐츠를 업데이트 🎜하도록 하세요. [관련 권장사항: vuejs 비디오 튜토리얼, 웹 프론트 엔드 개발]🎜🎜여기에는 두 가지 필수 전제 조건이 있습니다:🎜🎜그래서 일반적으로 데이터 업데이트로 인해 페이지 내용을 업데이트해야 하는 경우, 즉
- 🎜비교는 VNode 배열입니다🎜
- 🎜두 세트의 이전 VNode 배열과 새 VNode 배열이 동시에 있습니다🎜
renderWatcher.run()에만 발생합니다. 🎜🎜왜 VNode인가?🎜
🎜위에서 언급했듯이 diff에서 비교되는 것은 실제 DOM 노드가 아닌 VNode입니다. 대부분의 사람들이 VNode를 사용하는 이유가 전부입니다. 상대적으로 명확하므로 간단히 설명하겠습니다.~🎜🎜Vue에서 VNode를 사용하는 이유는 대략 두 가지입니다: 🎜🎜diff 프로세스에서 비교를 위해 VNode를 사용하면 성능이 크게 향상될 수 있습니다. 🎜
- 🎜VNode as 프레임워크 프레임워크 요구 사항에 따라 디자이너가 설계한 JavaScript 개체는 실제 DOM 노드보다 간단한 속성을 가져야 하며 작업 중에 DOM 쿼리가 필요하지 않아 계산 중 성능 소비를 크게 최적화할 수 있습니다🎜
- 🎜VNode에서 실제 DOM 노드까지 DOM의 렌더링 프로세스는 다양한 플랫폼(웹, WeChat 애플릿)에 따라 다르게 처리되어 각 플랫폼에 적합한 실제 DOM 요소를 생성할 수 있습니다🎜
🎜프로세스 정렬🎜
🎜웹 페이지에서 실제 DOM 노드는 🎜tree🎜 형태로 존재하며, 루트 노드는 모두<입니다. ;html>, 가상 노드가 실제 DOM 노드와 일치하는지 확인하기 위해 VNode도 트리 구조를 사용합니다. 🎜🎜구성 요소가 업데이트될 때 모든 VNode 노드를 비교해야 하는 경우 이전 노드 세트와 새 노드 세트를 모두 🎜깊이 탐색🎜하고 비교해야 하며 이로 인해 많은 성능 오버헤드가 발생하므로 Vue는 기본적으로 🎜비교로 설정됩니다. 같은 레벨의 노드🎜, 즉 🎜이전 VNode 트리와 새 VNode 트리의 레벨이 다를 경우 추가 레벨의 콘텐츠가 직접 생성되거나 폐기🎜되고 동일한 레벨에서는 diff 작업만 수행됩니다. 🎜🎜일반적으로 diff 작업은 일반적으로v-for루프나v-if/v-else,comment등에서 발생합니다🎜 동적으로 생성된 🎜 노드 객체(정적 노드는 일반적으로 변경되지 않으며 비교가 매우 빠릅니다), 이 프로세스는 dom을 업데이트하는 것이므로 소스 코드에서 이 프로세스에 해당하는 메서드 이름은updateChildren입니다. ,src/core/vdom/patch.ts에 있습니다. 아래와 같이: 🎜🎜🎜다음은 Vue 구성 요소 인스턴스의 생성 및 업데이트 프로세스에 대한 검토입니다. 🎜
- 🎜먼저,
beforeCreate를 <code>created단계에서 주로 데이터와 상태는 물론 일부 기본 이벤트와 메서드를 처리합니다🎜- 🎜그 다음
$mount(vm.$options.el ) 메소드는 <code>Vnode및 dom의 생성 및 마운트 단계, 즉beforeMount와mounted사이에 들어갑니다( 구성 요소가 업데이트되면 여기도 비슷합니다) )🎜프로토타입의
$mount는platforms/web/runtime-with-compiler.ts에 다시 작성되며 원래 구현은platforms/에 있습니다. web /runtime/index.ts; 원래 구현 방법에서는 실제로render를 실행하기 위해mountComponent메서드를 호출합니다. /code> 아래의 code>runtime-with-compiler는 한 번 구문 분석 및 컴파일된 후options.render$mount会在platforms/web/runtime-with-compiler.ts中进行一次重写,原始实现在platforms/web/runtime/index.ts中;在原始实现方法中,其实就是调用mountComponent方法执行render;而在web下的runtime-with-compiler中则是增加了 模板字符串编译 模块,会对options中的的template进行一次解析和编译,转换成一个函数绑定到options.render中
mountComponent函数内部就是 定义了渲染方法updateComponent = () => (vm._update(vm._render()),实例化一个具有before配置的watcher实例(即renderWatcher),通过定义watch观察对象为 刚刚定义的updateComponent方法来执行 首次组件渲染与触发依赖收集,其中的before配置仅仅配置了触发beforeMount/beforeUpdate钩子函数的方法;这也是为什么在beforeMount阶段取不到真实 dom 节点与beforeUpdate阶段获取的是旧 dom 节点的原因
_update方法的定义与mountComponent在同一文件下,其核心就是 读取组件实例中的$el(旧 dom 节点)与_vnode(旧 VNode)与_render()函数生成的vnode进行patch操作
patch函数首先对比 是否具有旧节点,没有的话肯定是新建的组件,直接进行创建和渲染;如果具有旧节点的话,则通过patchVnode进行新旧节点的对比,并且如果新旧节点一致并且都具有children子节点,则进入diff的核心逻辑 ——updateChildren子节点对比更新,这个方法也是我们常说的diff算法前置内容
既然是对比新旧 VNode 数组,那么首先肯定有 对比 的判断方法:
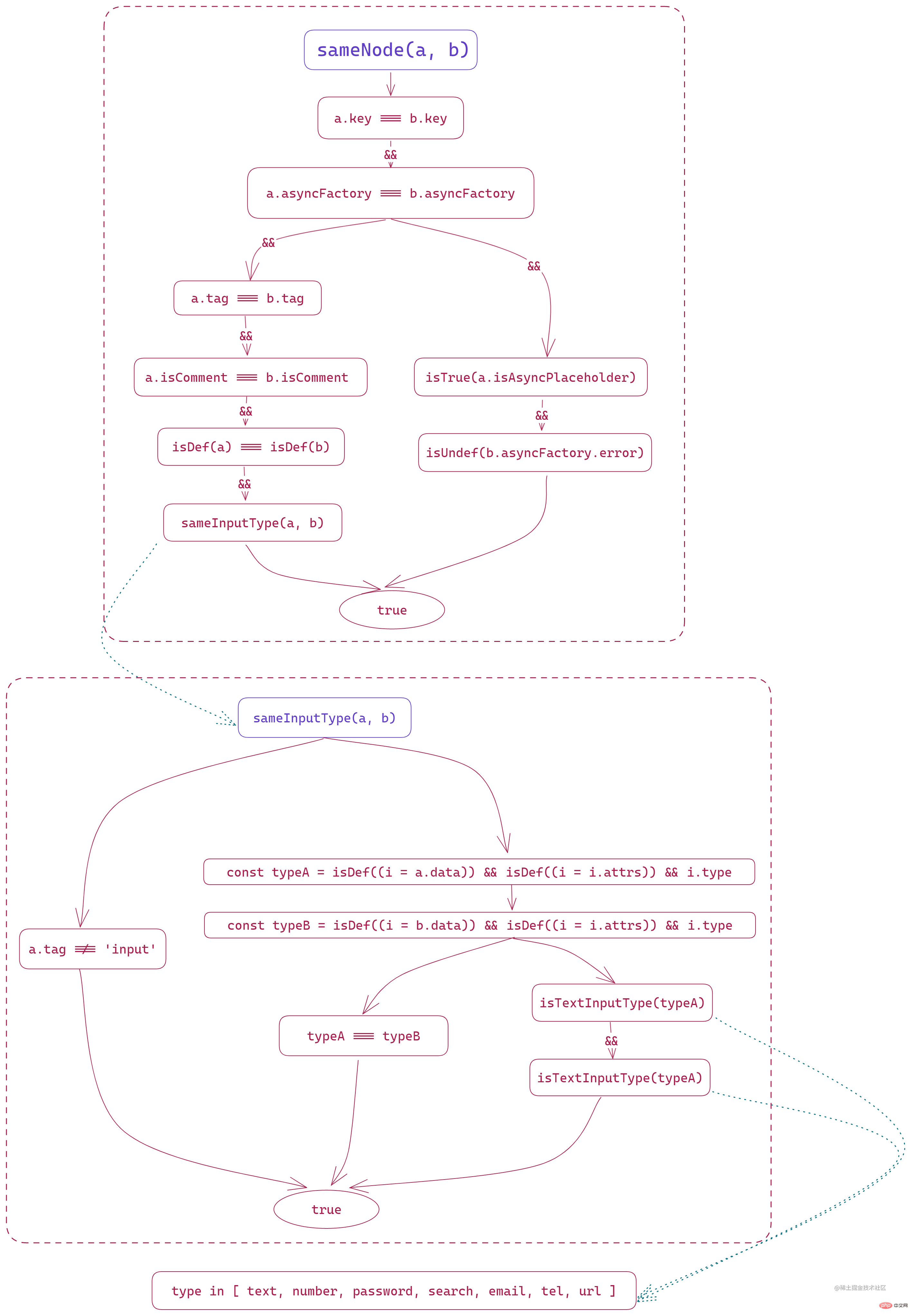
sameNode(a, b)、新增节点的方法addVnodes、移除节点的方法removeVnodes,当然,即使sameNode判断了 VNode 一致之后,依然会使用patchVnode对单个新旧 VNode 的内容进行深度比较,确认内部数据是否需要更新。sameNode(a, b)
这个方法就一个目的:比较新旧节点是否相同。
在这个方法中,首先比较的就是 a 和 b 的
key是否相同,这也是为什么 Vue 在文档中注明了v-for、v-if、v-else等动态节点必须要设置key来标识节点唯一性,如果key存在且相同,则只需要比较内部是否发生了改变,一般情况下可以减少很多 dom 操作;而如果没有设置的话,则会直接销毁重建对应的节点元素。然后会比较是不是异步组件,这里会比较他们的构造函数是不是一致。
然后会进入两种不同的情况比较:
- 非异步组件:标签一样、都不是注释节点、都有数据、同类型文本输入框
- 异步组件:旧节点占位符和新节点的错误提示都为
undefined函数整体过程如下
addVnodes
顾名思义,添加新的 VNode 节点。
该函数接收 6 个参数:
parentElm当前节点数组父元素、refElm指定位置的元素、vnodes新的虚拟节点数组、startIdx新节点数组的插入元素开始位置、endIdx新节点数组的插入元素结束索引、insertedVnodeQueue需要插入的虚拟节点队列。函数内部会 从
startIdx开始遍历vnodes数组直到endIdx位置,然后调用createElm依次在refElm之前创建和插入vnodes[idx]对应的元素。当然,在这个
🎜🎜vnodes[idx]中有可能会有Component组件,此时还会调用createComponentmountComponent 함수 내부에는 렌더링 방법이 정의되어 있습니다updateComponent = () => (vm._update(vm._render()),watcher를 인스턴스화합니다.before구성이 있는 인스턴스(예:renderWatcher),watch관찰 개체를 방금 정의된updateComponent메서드로 정의하여 첫 번째 구성요소 렌더링을 수행하고 종속성 수집을 트리거합니다. 여기서before구성은beforeMount/beforeUpdate후크 기능을 트리거하는 방법만 구성합니다. 실제 dom 노드와는 <code>beforeMount단계에서 얻을 수 없습니다. code>beforeUpdate 단계에서 이전 dom 노드를 얻는 이유🎜🎜🎜🎜_update메소드는mountComponent와 동일한 파일에 정의되어 있으며 핵심은$el(이전 dom 노드) 및_vnode읽기입니다. (이전 VNode) 및_render()함수는vnode를 생성하는 구성 요소 인스턴스에서패치작업을 수행합니다🎜🎜🎜🎜patch함수는 먼저 이전 노드가 있는지를 비교하고, 없으면 새로 생성된 컴포넌트이며, 기존 노드가 있으면 직접 생성되어 렌더링됩니다. 새 노드는patchVnode를 통해 비교됩니다. 이전 노드와 새 노드가 일관되고 둘 다자식하위 노드가 있는 경우diff의 핵심 논리를 입력합니다.-updateChildren하위 노드 비교 및 업데이트, 이 방법은 우리가 종종diff code> 알고리즘🎜🎜
sameNode(a, b), 노드 추가 방법 addVnodes, 노드 제거 방법 removeVnodes, 물론 sameNode는 VNode가 일관성이 있는지 확인하고, patchVnode는 내부 데이터를 업데이트해야 하는지 확인하기 위해 단일 신규 및 기존 VNode의 콘텐츠를 심층적으로 비교하는 데 계속 사용됩니다. 🎜key가 동일한지 여부입니다. 이것이 바로 Vue가 v-for, v-if, v-else를 기록하는 이유입니다. 와 다른 동적 노드는 노드의 고유성을 식별하기 위해 key를 설정해야 합니다. key가 존재하고 동일한 경우에만 비교하면 됩니다. 내부 변경이 발생했습니다. 일반적으로 DOM 작업을 많이 줄일 수 있습니다. 설정하지 않으면 해당 노드 요소가 직접 파괴되고 다시 작성됩니다. 🎜🎜그런 다음 비동기 구성 요소인지 비교하고 여기서는 생성자가 일관성이 있는지 비교합니다. 🎜🎜그런 다음 비교를 위해 두 가지 다른 상황을 입력합니다. 🎜정의되지 않음🎜 🎜
🎜parentElm 현재 노드 배열의 상위 요소, refElm 지정된 위치의 요소, vnodes 새 가상 노드 배열, startIdx 새 노드 배열에 삽입된 요소의 시작 위치, endIdx 새 노드에 삽입된 요소의 끝 인덱스 array, insertedVnodeQueue 필수 삽입된 가상 노드 큐입니다. 🎜🎜내부적으로 이 함수는 startIdx에서 시작하여 endIdx 위치까지 vnodes 배열을 순회한 다음 호출합니다. createElm refElm 앞에 vnodes[idx]에 해당하는 요소를 차례로 생성하고 삽입합니다. 🎜🎜물론, 이 vnodes[idx]에는 Component 컴포넌트가 있을 수 있으며, createComponent도 호출되어 해당 컴포넌트를 생성합니다. . 예. 🎜전체
VNode와 dom은VNode和 dom 都是一个 树结构,所以在 同层级的比较之后,还需要处理当前层级下更深层次的 VNode 和 dom 处理。
与 addVnodes 相反,该方法就是用来移除 VNode 节点的。
由于这个方法只是移除,所以只需要三个参数:vnodes 旧虚拟节点数组、startIdx 开始索引、endIdx 结束索引。
函数内部会 从 startIdx 开始遍历 vnodes 数组直到 endIdx 位置,如果 vnodes[idx] 不为 undefined 的话,则会根据 tag 属性来区分处理:
tag,说明是一个元素或者组件,需要 递归处理 vnodes[idx] 的内容, 触发 remove hooks 与 destroy hooks
tag,说明是一个 纯文本节点,直接从 dom 中移除该节点即可节点对比的 实际完整对比和 dom 更新 方法。
在这个方法中,主要包含 九个 主要的参数判断,并对应不同的处理逻辑:
新旧 VNode 全等,则说明没有变化,直接退出
如果新的 VNode 具有真实的 dom 绑定,并且需要更新的节点集合是一个数组的话,则拷贝当前的 VNode 到集合的指定位置
如果旧节点是一个 异步组件并且还没有加载结束的话就直接退出,否则通过 hydrate 函数将新的 VNode 转化为真实的 dom 进行渲染;两种情况都会 退出该函数
如果新旧节点都是 静态节点 并且 key 相等,或者是 isOnce 指定的不更新节点,也会直接 复用旧节点的组件实例 并 退出函数
如果新的 VNode 节点具有 data 属性并且有配置 prepatch 钩子函数,则执行 prepatch(oldVnode, vnode) 通知进入节点的对比阶段,一般这一步会配置性能优化
如果新的 VNode 具有 data 属性并且递归改节点的子组件实例的 vnode,依然是可用标签的话,cbs 回调函数对象中配置的 update 钩子函数以及 data 中配置的 update 钩子函数
如果新的 VNode 不是文本节点的话,会进入核心对比阶段:
children 子节点,则进入 updateChildren 方法对比子节点text 文本如果新的 VNode 具有 text 文本(是文本节点),则比较新旧节点的文本内容是否一致,否则进行文本内容的更新
最后调用新节点的 data 中配置的 postpatch 钩子函数,通知节点更新完毕
简单来说,patchVnode 就是在 同一个节点 更新阶段 进行新内容与旧内容的对比,如果发生改变则更新对应的内容;如果有子节点,则“递归”执行每个子节点的比较和更新。
而 子节点数组的比较和更新,则是 diff 的核心逻辑,也是面试时经常被提及的问题之一。
下面,就进入 updateChildren 方法的解析吧~
updateChildren트리 구조이므로 . removeVnodes
addVnodes와 달리 이 메서드는 VNode 노드를 제거하는 데 사용됩니다. 이 메서드는 제거만 하기 때문에 세 가지 매개변수만 필요합니다: vnodes 이전 가상 노드 배열, startIdx 시작 인덱스, endIdx 끝 인덱스 .
내부 함수는 startIdx에서 시작하여 endIdx 위치까지 vnodes 배열을 순회합니다(vnodes[idx] <code>undefine이 아니면 tag 속성에 따라 처리됩니다:
tag의 존재 >는 vnodes[idx]의 콘텐츠를 재귀적으로 처리하고 후크 제거 및 후크 제거를 트리거해야 하는 요소 또는 구성 요소임을 의미합니다. 태그가 존재하지 않습니다. >, 설명은 🎜일반 텍스트 노드🎜입니다. DOM에서 직접 노드를 제거하세요hydrate 함수 ; 두 경우 모두 함수는 🎜exit🎜🎜키인 경우 code>가 동일하거나 <code>isOnce가 지정되었습니다. 노드가 업데이트되지 않으면 직접 🎜이전 노드의 구성 요소 인스턴스를 재사용🎜하고 🎜함수를 종료🎜🎜
data 속성이 있고 prepatch 구성 후크 기능이 있는 경우 prepatch(oldVnode, vnode)를 실행하여 노드에 알립니다. 일반적으로 이 단계에서는 성능 최적화를 구성합니다🎜data 속성이 있으며 노드 하위 구성 요소 인스턴스의 vnode를 반복적으로 변경합니다. 레이블은 계속 사용할 수 있습니다. cbs 콜백 함수 개체 >Hook 함수에 구성된 update및 dataupdate 후크 함수 /code>🎜자식이 있는 경우 하위 노드, updateChildren 메소드를 입력하여 하위 노드를 비교text texttext Text(텍스트 노드)가 있는 경우, 이전 노드와 새 노드가 일치하는지 확인하고, 그렇지 않으면 텍스트 콘텐츠를 업데이트하세요🎜data >postpatch에 구성된 를 호출합니다. > 업데이트가 완료되었음을 노드에 알리는 후크 기능🎜
patchVnode는 동일한 노드 업데이트 단계에서 새로운 콘텐츠와 기존 콘텐츠를 처리하는 것입니다🎜 대조적으로 , 변경 사항이 있으면 해당 콘텐츠가 업데이트되고, 하위 노드가 있으면 각 하위 노드의 비교 및 업데이트가 "재귀적으로" 수행됩니다🎜. 🎜🎜그리고 🎜자식 노드 배열의 비교 및 업데이트는 diff🎜의 핵심 로직이며, 인터뷰에서 자주 언급되는 질문 중 하나이기도 합니다. 🎜🎜이제 updateChildren 메소드 분석에 들어갑니다~🎜updateChildren diff 핵심 분석🎜🎜🎜먼저, 먼저 생각해 보세요🎜새 배열🎜을 기반으로 두 객체 배열의 요소 차이를 비교하는 방법은 무엇인가요? 🎜🎜일반적으로 말하면, 🎜무차별 대입을 통해 두 배열🎜을 직접 탐색할 수 있는데, 이는 배열에 있는 각 요소의 순서와 차이를 찾는 것입니다. 이것이 바로 🎜간단한 diff 알고리즘🎜입니다. 🎜🎜즉, 🎜 새로운 노드 배열을 순회하고, 각 주기마다 다시 기존 노드 배열을 순회하여 두 노드가 일치하는지 비교하고, 비교 결과를 통해 새 노드가 추가, 제거 또는 이동되는지를 결정합니다. m*n 비교가 필요하므로 기본 시간 복잡도는 On입니다. 🎜이 비교 방법은 많은 수의 노드 업데이트 중에 성능을 많이 소모하므로 Vue 2에서는 이를 최적화하여 double-ended diffdouble-ended 비교 알고리즘으로 변경했습니다. /코드> 코드>. 双端对比算法,也就是 双端 diff。
顾名思义,双端 就是 从两端开始分别向中间进行遍历对比 的算法。
在 双端 diff 中,分为 五种比较情况:
新旧头相等
新旧尾相等
旧头等于新尾
旧尾等于新头
四者互不相等
其中,前四种属于 比较理想的情况,而第五种才是 最复杂的对比情况。
判断相等即
sameVnode(a, b)等于true
下面我们通过一种预设情况来进行分析。
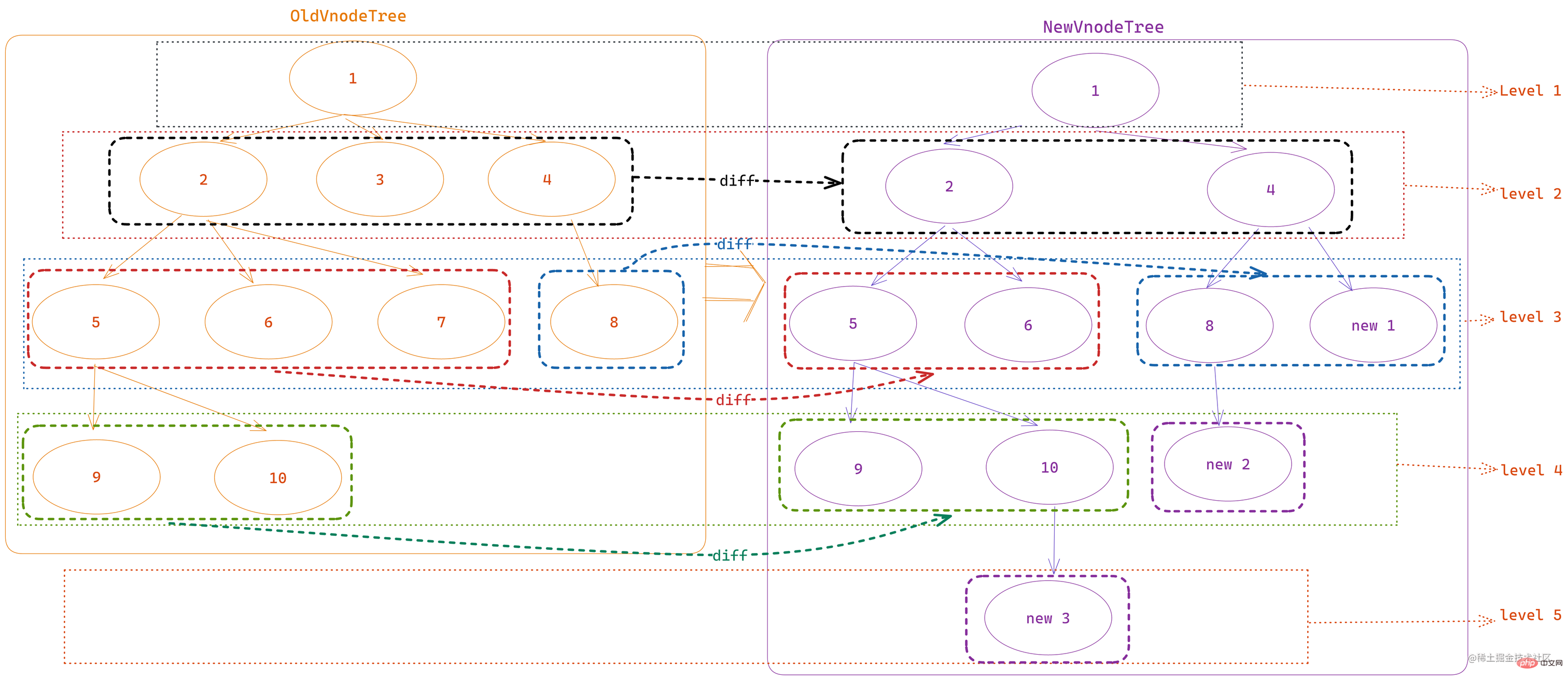
为了尽量同时演示出以上五种情况,我预设了以下的新旧节点数组:
oldChildren,包含 1 - 7 共 7 个节点newChildren,也有 7 个节点,但是相比旧节点减少了一个 vnode 3 并增加了一个 vnode 8
在进行比较之前,首先需要 定义两组节点的双端索引:
let oldStartIdx = 0 let oldEndIdx = oldCh.length - 1 let oldStartVnode = oldCh[0] let oldEndVnode = oldCh[oldEndIdx] let newStartIdx = 0 let newEndIdx = newCh.length - 1 let newStartVnode = newCh[0] let newEndVnode = newCh[newEndIdx]
复制的源代码,其中
oldCh在图中为oldChildren,newCh为newChildren
然后,我们定义 遍历对比操作的停止条件:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx)
这里的停止条件是 只要新旧节点数组任意一个遍历结束,则立即停止遍历。
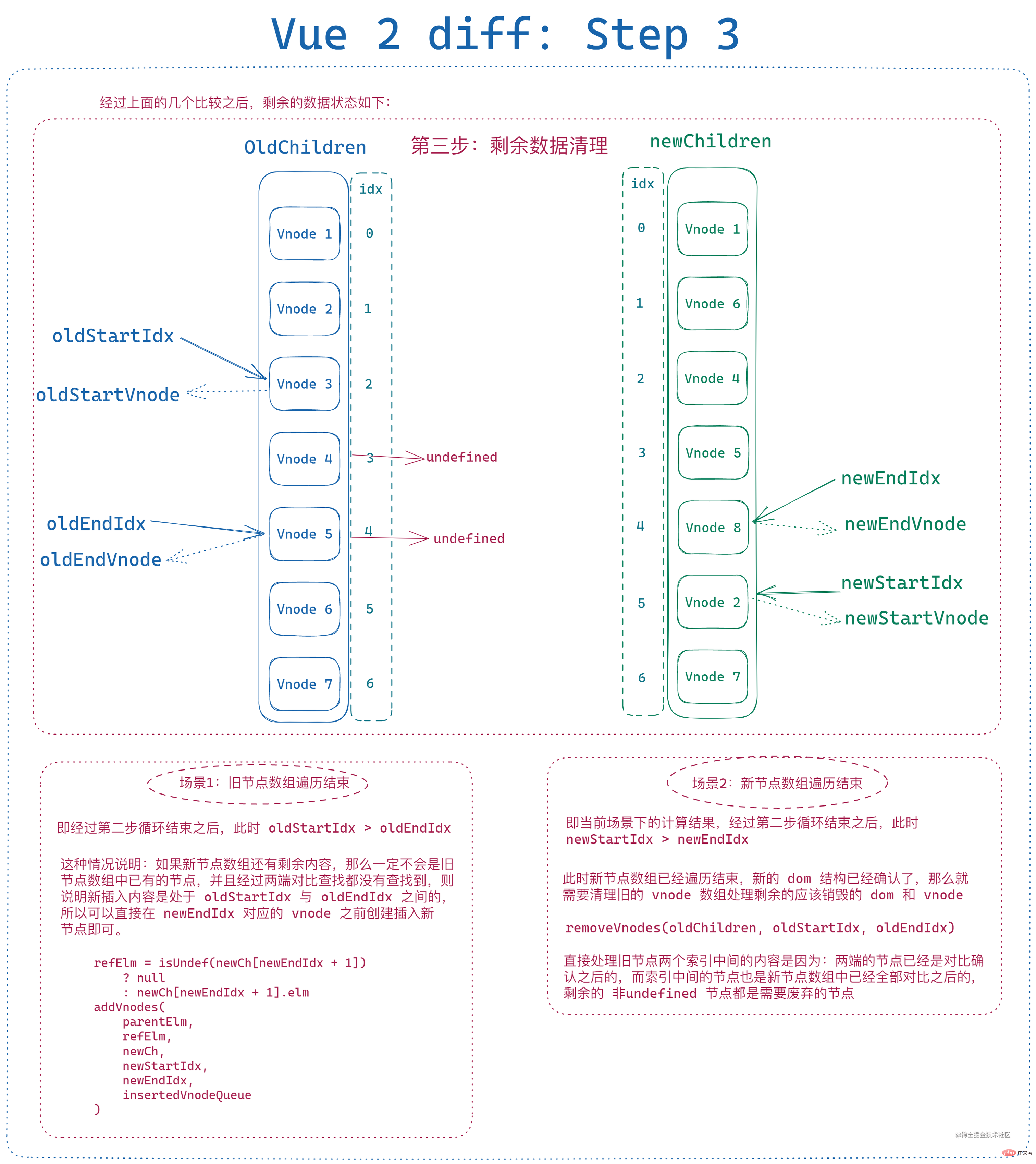
此时节点状态如下:

为了保证新旧节点数组在对比时不会进行无效对比,会首先排除掉旧节点数组 起始部分与末尾部分 连续且值为 Undefined 的数据。
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx]
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
当然我们的例子中没有这种情况,可以忽略。
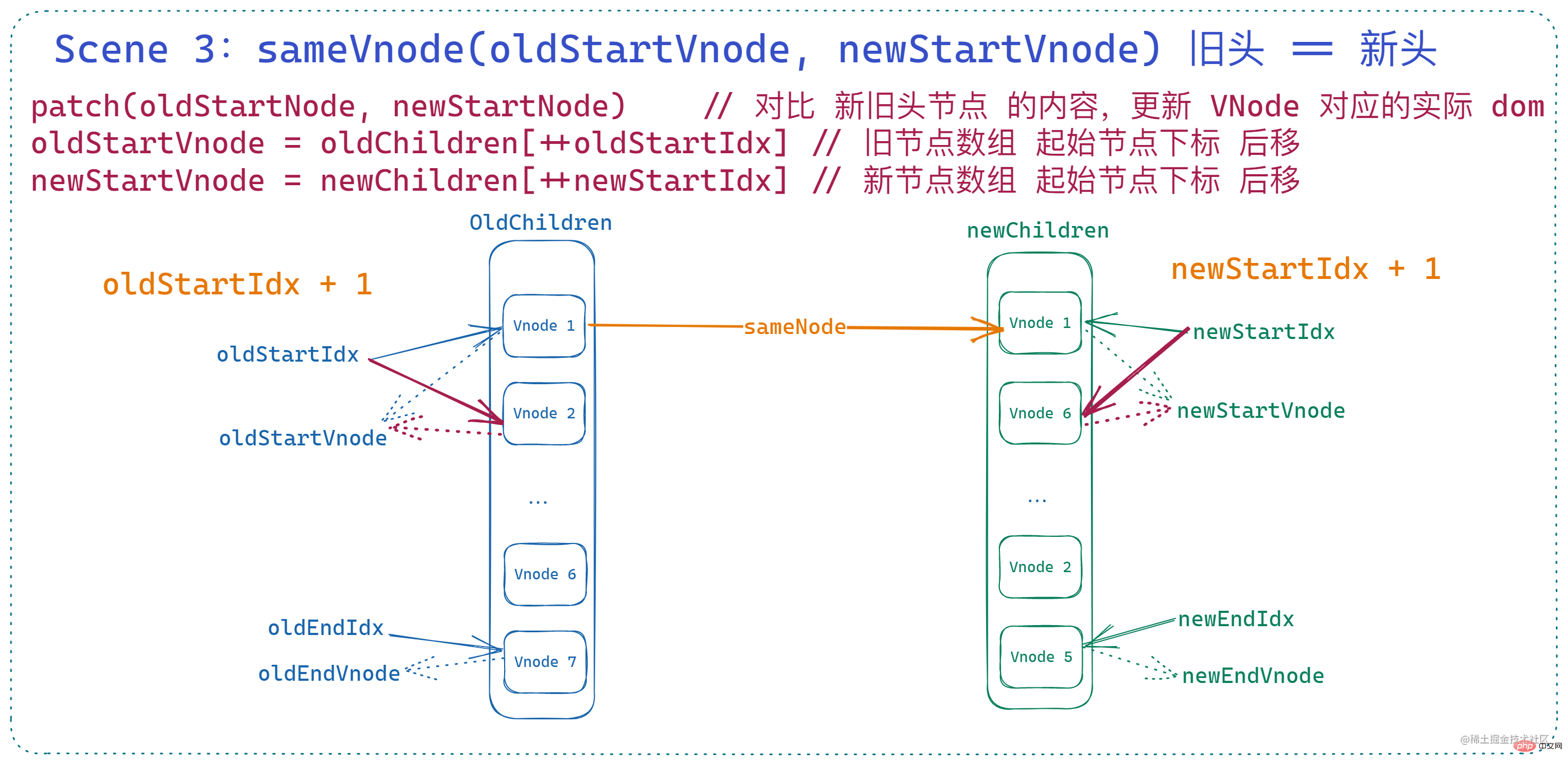
此时相当于新旧节点数组的两个 起始索引 指向的节点是 基本一致的,那么此时会调用 patchVnode 对两个 vnode 进行深层比较和 dom 更新,并且将 两个起始索引向后移动。即:
if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(
oldStartVnode,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
}这时的节点和索引变化如图所示:
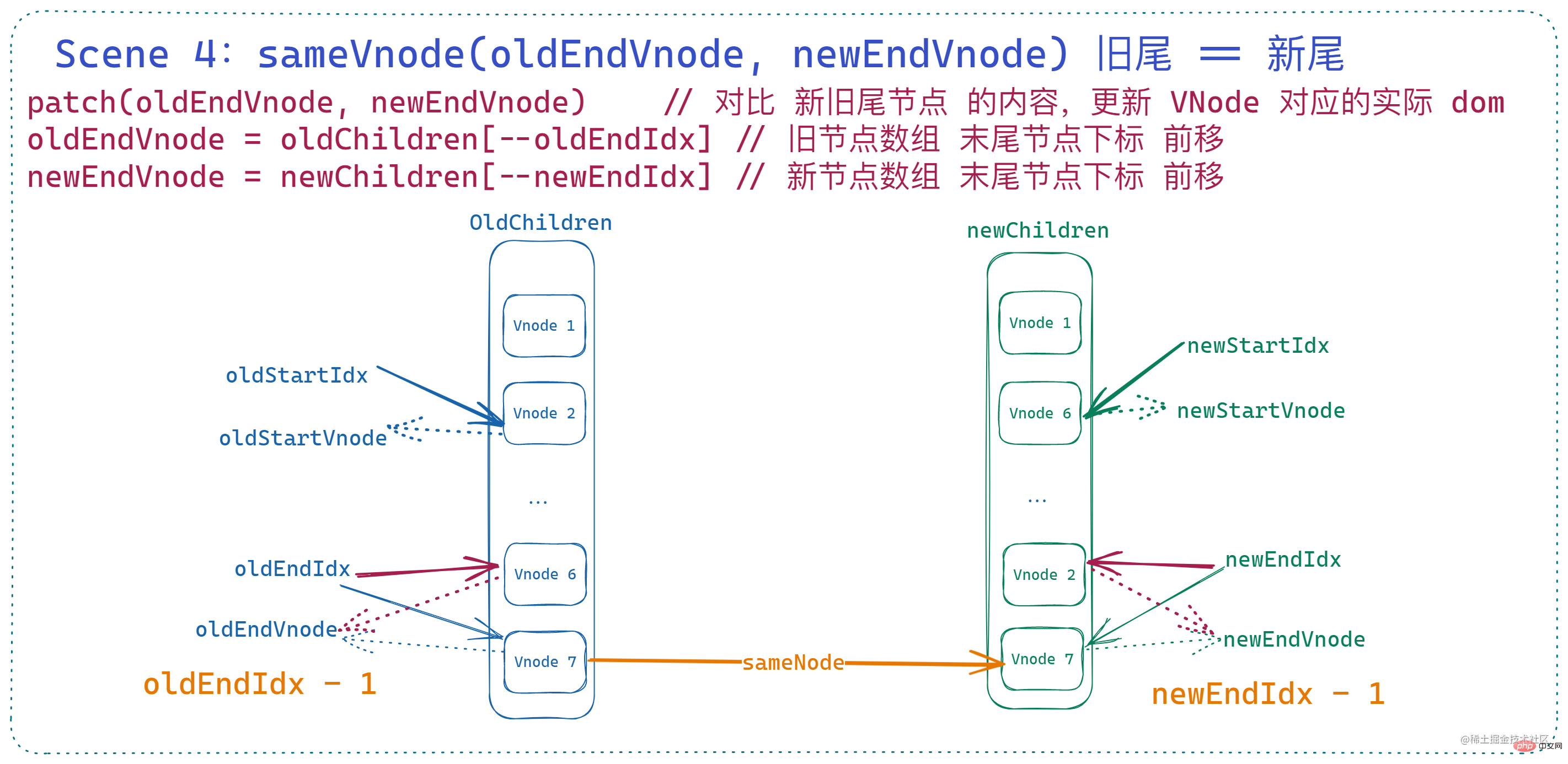
与头结点相等类似,这种情况代表 新旧节点数组的最后一个节点基本一致,此时一样调用 patchVnode 比较两个尾结点和更新 dom,然后将 两个末尾索引向前移动。
if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(
oldEndVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
}这时的节点和索引变化如图所示:
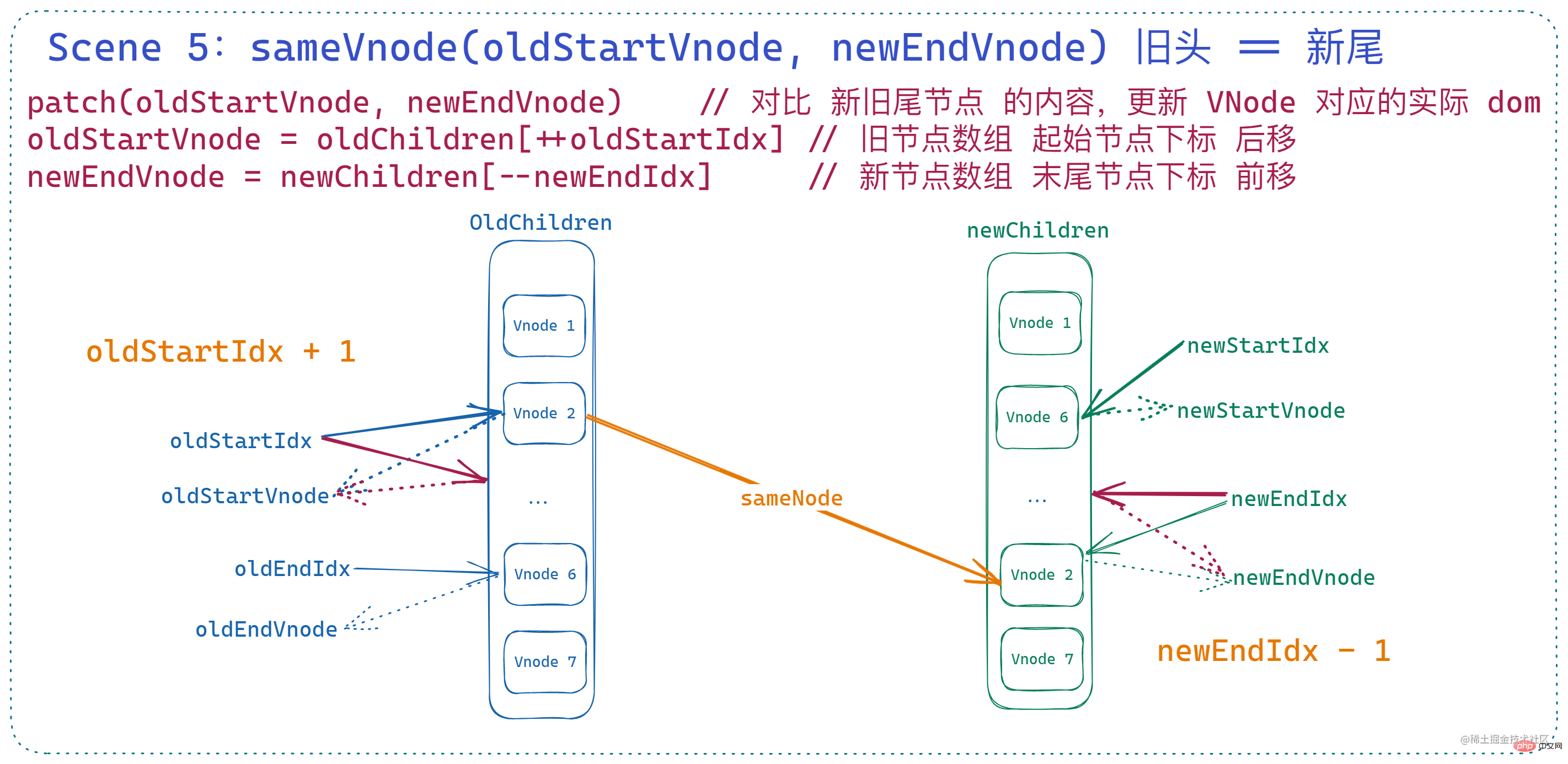
这里表示的是 旧节点数组 当前起始索引 指向的 vnode 与 新节点数组 当前末尾索引 指向的 vnode 基本一致,一样调用 patchVnode 对两个节点进行处理。
但是与上面两种有区别的地方在于:这种情况下会造成 节点的移动,所以此时还会在 patchVnode 结束之后 通过 nodeOps.insertBefore 将 旧的头节点 重新插入到 当前 旧的尾结点之后。
然后,会将 旧节点的起始索引后移、新节点的末尾索引前移。
看到这里大家可能会有一个疑问,为什么这里移动的是 旧的节点数组,这里因为 vnode 节点中有一个属性
elmDouble-ended diff 알고리즘
이름에서 알 수 있듯이 Double-ended은 양쪽 끝에서 시작하여 중간으로 이동하는 알고리즘🎜입니다. 🎜🎜double-ended diff에서는 🎜5가지 비교 상황🎜으로 나뉩니다. 🎜🎜그 중 처음 네 가지는 🎜이상적인 상황🎜이고, 다섯 번째는 🎜가장 복잡합니다. 비교상황🎜. 🎜
- 🎜이전 헤더와 새 헤더 같습니다🎜
- 🎜이전 꼬리와 새 꼬리가 같습니다🎜
- 🎜기존 머리가 새 꼬리와 같습니다🎜
- 🎜기존 꼬리가 같습니다 새로운 머리에게🎜
- 🎜네 가지는 상호 배타적인 평등🎜
🎜동등 판정은 🎜미리 설정된 상황을 통해 분석해 보자. 🎜sameVnode(a, b)가true🎜🎜1. 신규 및 기존 노드 상태 사전 설정🎜
🎜위의 5가지 상황을 동시에 보여주기 위해 다음과 같은 신규 및 기존 노드 배열을 사전 설정합니다. : 🎜
- 초기 노드 순서의 이전 노드 배열
oldChildren으로, 총 7개 노드 중 1~7개를 포함- 새 노드 배열로
< /ul>🎜비교되기 전에 먼저 두 노드 세트의 🎜이중 종료 인덱스 🎜를 정의해야 합니다. 🎜newChildrenshuffle code> 뒤에도 7개의 노드가 있지만 이전 노드에 비해vnode 3가 하나 적고vnode 8이 하나 더 있습니다.if (sameVnode(oldStartVnode, newEndVnode)) { patchVnode( oldStartVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx ) canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm)) oldStartVnode = oldCh[++oldStartIdx] newEndVnode = newCh[--newEndIdx] }로그인 후 복사로그인 후 복사🎜복사된 소스 코드, 여기서🎜그런 다음 순회 비교 작업의 중지 조건🎜을 정의합니다🎜:🎜oldCh는 < 그림에서 code>oldChildren,newCh는newChildren🎜🎜여기서 중지 조건은🎜이전 노드 배열과 새 노드 배열 중 하나라도 순회하는 한 종료되면 순회가 즉시 중지됩니다🎜. 🎜🎜이때 노드 상태는 다음과 같습니다. 🎜🎜if (sameVnode(oldEndVnode, newStartVnode)) { patchVnode( oldEndVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx ) canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm) oldEndVnode = oldCh[--oldEndIdx] newStartVnode = newCh[++newStartIdx] }로그인 후 복사로그인 후 복사🎜2. 비교하기 전에 vnode가 존재하는지 확인하세요🎜
🎜이전 노드와 새 노드가 있는지 확인하려면 배열은 잘못 비교되지 않으므로 먼저 이전 노드 배열의 시작과 끝 부분이 연속적이고 값이정의되지 않음인 데이터 🎜를 제외합니다. 🎜🎜if (isUndef(oldKeyToIdx)) { oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx) } idxInOld = isDef(newStartVnode.key) ? oldKeyToIdx[newStartVnode.key] : findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx) if (isUndef(idxInOld)) { // New element createElm( newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx ) } else { vnodeToMove = oldCh[idxInOld] if (sameVnode(vnodeToMove, newStartVnode)) { patchVnode( vnodeToMove, newStartVnode, insertedVnodeQueue, newCh, newStartIdx ) oldCh[idxInOld] = undefined canMove && nodeOps.insertBefore( parentElm, vnodeToMove.elm, oldStartVnode.elm ) } else { // same key but different element. treat as new element createElm( newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx ) } } newStartVnode = newCh[++newStartIdx] }로그인 후 복사로그인 후 복사🎜3. 이전 헤드는 새 헤드와 동일합니다🎜
🎜이때, 이전 헤드와 신규 헤드의 2개의 🎜시작 인덱스 🎜에 해당합니다. 지정된 노드는 🎜기본적으로 일관성이 있고 🎜, 이때patchVnode가 호출되어 두 vnode의 심층 비교 및 DOM 업데이트를 수행하고 🎜두 개의 시작 인덱스를 뒤로 이동합니다🎜. . 즉, 🎜rrreee🎜 이때의 노드 및 인덱스 변경 사항은 그림과 같습니다. 🎜🎜🎜 🎜4. 이전 꼬리는 새 꼬리와 같습니다🎜
🎜 헤드 노드의 동일성과 유사합니다. 이 상황은 이전 노드 배열과 새 노드 배열의 마지막 노드가 기본적으로 동일함을 의미합니다. 이때patchVnode도 호출되어 두 끝을 비교합니다. 노드를 업데이트하고 dom을 업데이트한 다음 두 개의 끝 인덱스를 앞으로 이동합니다. 🎜rrreee🎜 이때 변경된 노드와 인덱스는 그림과 같습니다. 🎜🎜🎜
🎜5. 이전 머리는 새 꼬리와 같습니다🎜
🎜이것은 이전 노드 배열의 현재 상태 시작 인덱스가 가리키는 vnode는 기본적으로 새 노드 배열의 현재 끝 인덱스가 가리키는 vnode와 동일합니다. 두 노드를 처리하려면patchVnode를 호출하세요. 🎜🎜하지만 위 둘과 다른 점은 이 경우 🎜노드가 이동🎜하므로 이때 🎜patchVnode가 끝난 후nodeOps.insertBefore도 전달한다는 것입니다🎜🎜현재 이전 테일 노드🎜 뒤에 🎜이전 헤드 노드🎜를 다시 삽입합니다. 🎜🎜그러면 이전 노드의 🎜시작 인덱스가 뒤로 이동하고 새 노드의 끝 인덱스가 앞으로 🎜이동됩니다. 🎜🎜이 내용을 보면 🎜이전 노드 배열🎜이 왜 여기로 옮겨졌는지 궁금하실 것입니다. 이는 vnode 노드에 다음을 가리키는elm속성이 있기 때문입니다. 해당 vnode는 실제 dom 노드이므로 여기서 이전 노드 배열을 이동하는 것은 실제로 🎜실제 dom 노드 순서를 측면에서 이동하는 것🎜이며, 이것이 🎜현재 테일 노드라는 점에 유의하세요. 원래의 이전 노드 배열의 끝 🎜. 🎜即:
if (sameVnode(oldStartVnode, newEndVnode)) { patchVnode( oldStartVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx ) canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm)) oldStartVnode = oldCh[++oldStartIdx] newEndVnode = newCh[--newEndIdx] }로그인 후 복사로그인 후 복사此时状态如下:
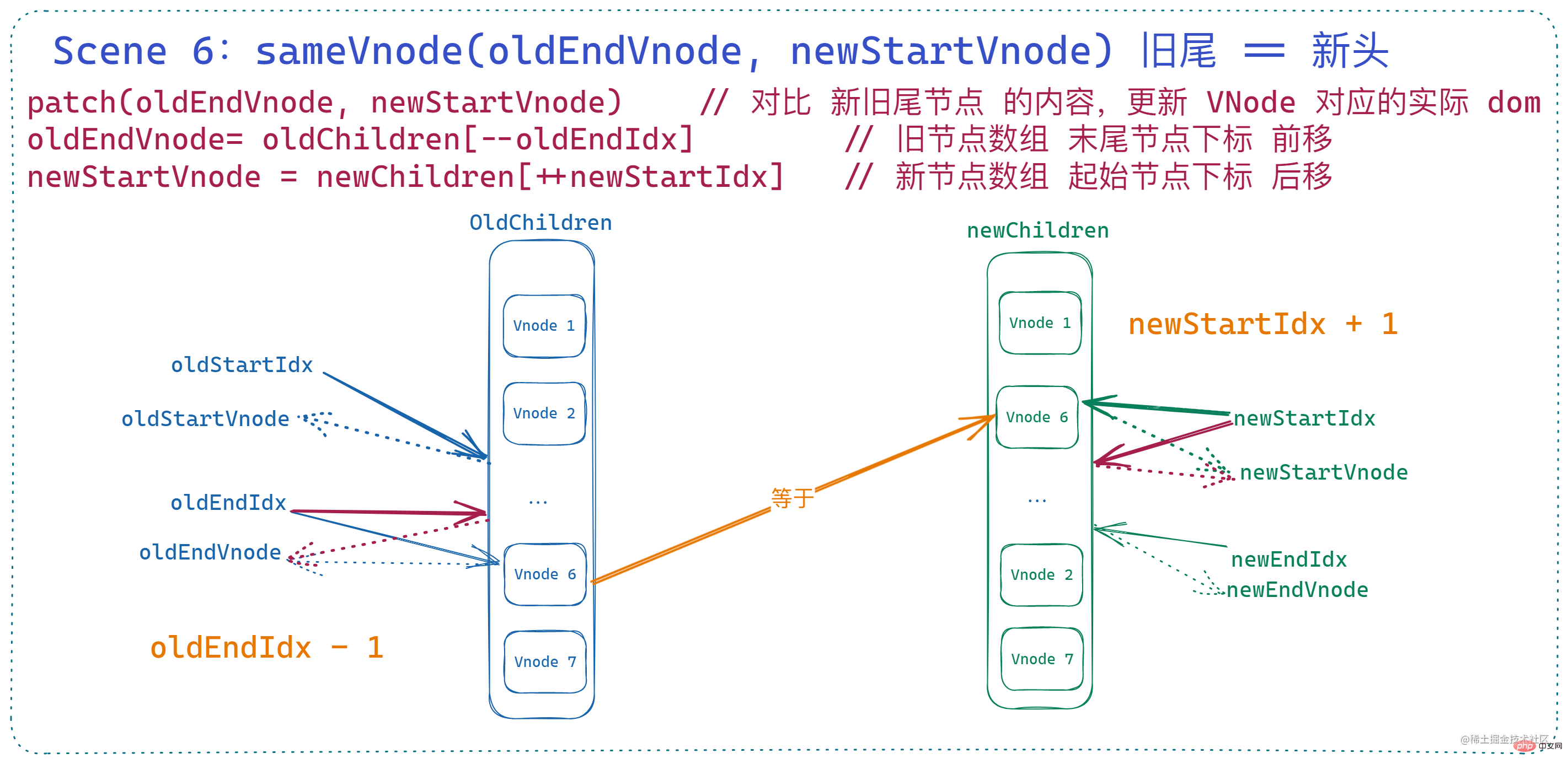
6. 旧尾等于新头
这里与上面的 旧头等于新尾 类似,一样要涉及到节点对比和移动,只是调整的索引不同。此时 旧节点的 末尾索引 前移、新节点的 起始索引 后移,当然了,这里的 dom 移动对应的 vnode 操作是 将旧节点数组的末尾索引对应的 vnode 插入到旧节点数组 起始索引对应的 vnode 之前。
if (sameVnode(oldEndVnode, newStartVnode)) { patchVnode( oldEndVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx ) canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm) oldEndVnode = oldCh[--oldEndIdx] newStartVnode = newCh[++newStartIdx] }로그인 후 복사로그인 후 복사此时状态如下:
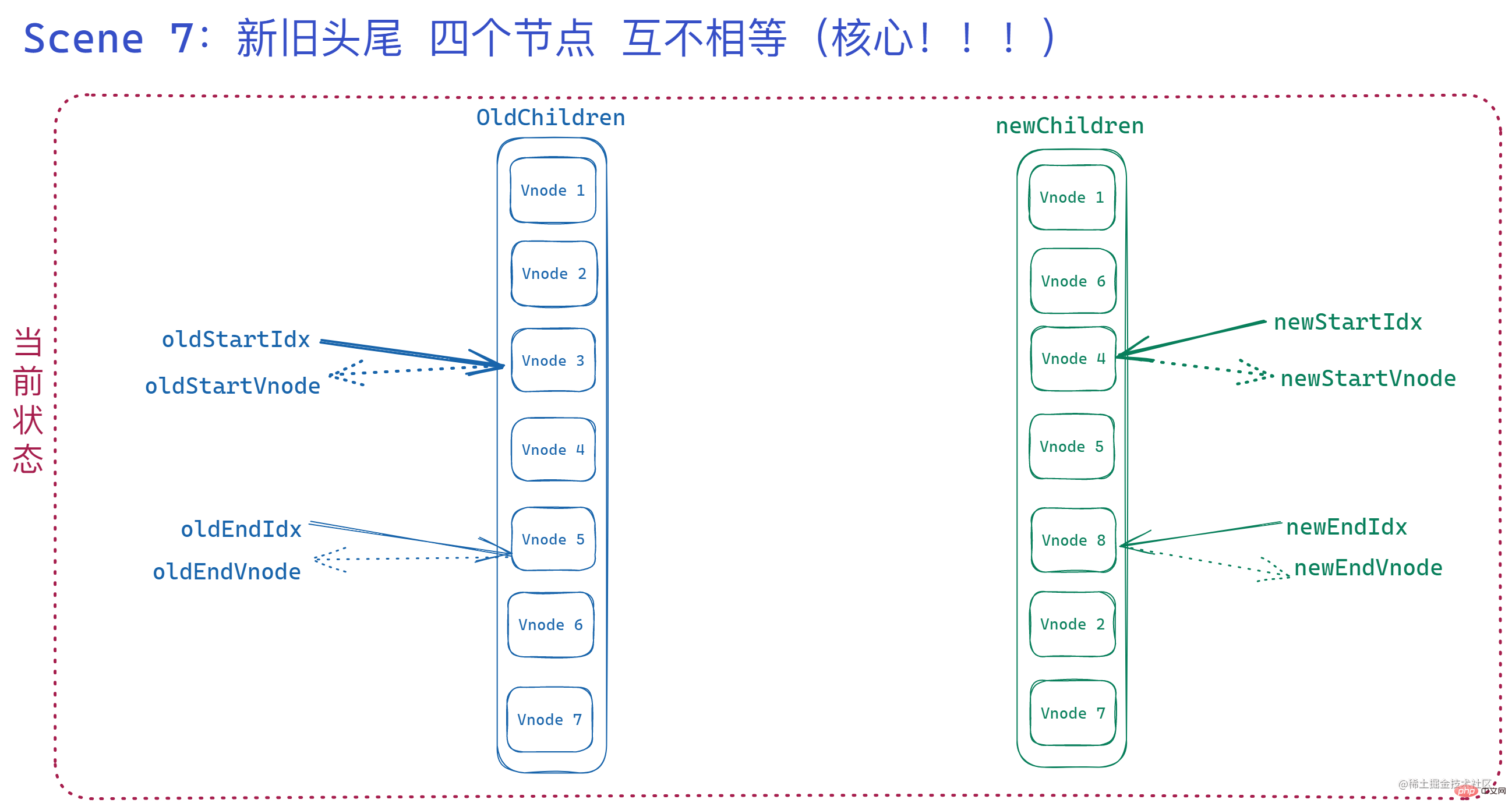
7. 四者均不相等
在以上情况都处理之后,就来到了四个节点互相都不相等的情况,这种情况也是 最复杂的情况。
当经过了上面几种处理之后,此时的 索引与对应的 vnode 状态如下:
可以看到四个索引对应的 vnode 分别是:vnode 3、vnode 5、 vnode 4、vnode 8,这几个肯定是不一样的。
此时也就意味着 双端对比结束。
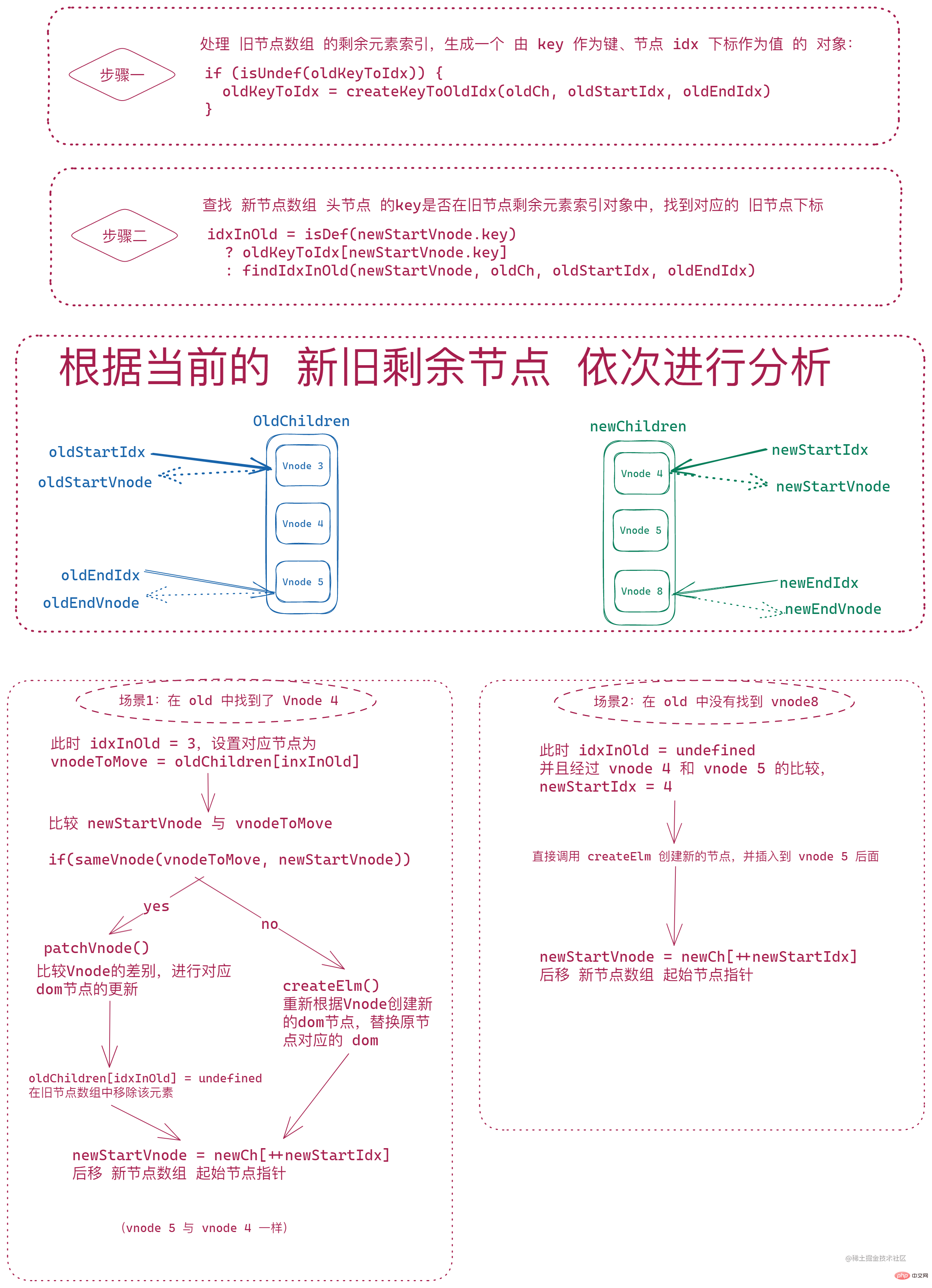
后面的节点对比则是 将旧节点数组剩余的 vnode (
oldStartIdx到oldEndIdx之间的节点)进行一次遍历,生成由vnode.key作为键,idx索引作为值的对象oldKeyToIdx,然后 遍历新节点数组的剩余 vnode(newStartIdx到newEndIdx之间的节点),根据新的节点的key在oldKeyToIdx进行查找。此时的每个新节点的查找结果只有两种情况:
找到了对应的索引,那么会通过
sameVNode对两个节点进行对比:
- 相同节点,调用
patchVnode进行深层对比和 dom 更新,将oldKeyToIdx中对应的索引idxInOld对应的节点插入到oldStartIdx对应的 vnode 之前;并且,这里会将 旧节点数组中idxInOld对应的元素设置为undefined- 不同节点,则调用
createElm重新创建一个新的 dom 节点并将 新的 vnode 插入到对应的位置没有找到对应的索引,则直接
createElm创建新的 dom 节点并将新的 vnode 插入到对应位置注:这里 只有找到了旧节点并且新旧节点一样才会将旧节点数组中
idxInOld中的元素置为undefined。最后,会将 新节点数组的 起始索引 向后移动。
if (isUndef(oldKeyToIdx)) { oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx) } idxInOld = isDef(newStartVnode.key) ? oldKeyToIdx[newStartVnode.key] : findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx) if (isUndef(idxInOld)) { // New element createElm( newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx ) } else { vnodeToMove = oldCh[idxInOld] if (sameVnode(vnodeToMove, newStartVnode)) { patchVnode( vnodeToMove, newStartVnode, insertedVnodeQueue, newCh, newStartIdx ) oldCh[idxInOld] = undefined canMove && nodeOps.insertBefore( parentElm, vnodeToMove.elm, oldStartVnode.elm ) } else { // same key but different element. treat as new element createElm( newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx ) } } newStartVnode = newCh[++newStartIdx] }로그인 후 복사로그인 후 복사大致逻辑如下图:
剩余未比较元素处理
经过上面的处理之后,根据判断条件也不难看出,遍历结束之后 新旧节点数组都刚好没有剩余元素 是很难出现的,当且仅当遍历过程中每次新头尾节点总能和旧头尾节点中总能有两个新旧节点相同时才会发生,只要有一个节点发生改变或者顺序发生大幅调整,最后 都会有一个节点数组起始索引和末尾索引无法闭合。
那么此时就需要对剩余元素进行处理:
- 旧节点数组遍历结束、新节点数组仍有剩余,则遍历新节点数组剩余数据,分别创建节点并插入到旧末尾索引对应节点之前
- 新节点数组遍历结束、旧节点数组仍有剩余,则遍历旧节点数组剩余数据,分别从节点数组和 dom 树中移除
即:
小结
Vue 2 的 diff 算法相对于简单 diff 算法来说,通过 双端对比与生成索引 map 两种方式 减少了简单算法中的多次循环操作,新旧数组均只需要进行一次遍历即可将所有节点进行对比。
이중 끝 비교는 각각 4번씩 비교되고 이동되며 성능이 최적의 솔루션이 아닙니다. 따라서 Vue 3에서는 이중 끝 비교를 대체하기 위해 가장 긴 증가 하위 시퀀스를 도입했지만 나머지는 여전히 통과합니다. 인덱스 맵 형태로 변환하면 공간 확장을 통해 시간 복잡도가 줄어들어 컴퓨팅 성능이 더욱 향상됩니다.
물론, 이 글의 그림에는 vnode에 해당하는 elm의 실제 dom 노드가 나와 있지 않습니다. 둘 사이의 모바일 관계는 오해를 불러일으킬 수 있으니, "Vue.js 설계 및 구현"과 함께 읽어보시길 권장합니다. .
전체 과정은 다음과 같습니다.
(학습 영상 공유: vuejs 입문 튜토리얼, 기본 프로그래밍 영상)
위 내용은 Vue2 diff 알고리즘을 빠르게 이해하세요. (자세한 설명은 그림과 텍스트로 설명되어 있습니다.)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!










![프론트엔드 Vue3 실전 전투 [손글씨 vue 프로젝트]](https://img.php.cn/upload/course/000/000/068/639b12e98e0b5441.png)









![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



