


MySQL은 팬텀 읽기 문제를 어떻게 해결합니까? 다음 기사에서는 이 문제에 대해 이야기해 보겠습니다. 질문이 있는 기사를 읽어 보겠습니다.

진부산과 인부시의 빈번한 인터뷰 질문 중 MySQL의 트랜잭션 특성, 격리 수준 및 기타 문제도 이러한 문제에 직면한 매우 고전적인 8부작 에세이 중 하나입니다. 대부분의 친구들이 쉽게 선택할 수 있을 것으로 추정됩니다. 격리(격리 >), 일관성 및 지속성
격리 수준: 커밋되지 않은 읽기 (커밋되지 않은 읽기), 커밋된 읽기(커밋된 읽기), 반복 읽기(REPEATABLE READ code>), <code>직렬화 가능 (SERIALIZABLE)原子性(Atomicity)、隔离性(Isolation)、一致性(Consistency)和持久性
隔离级别:读取未提交(READ UNCOMMITTED),读取已提交(READ COMMITTED),可重复读(REPEATABLE READ),可串行化(SERIALIZABLE)
而每一种隔离级别导致的问题有:
READ UNCOMMITTED隔离级别下,可能发生脏读、不可重复读和幻读问题READ COMMITTED隔离级别下,可能发生不可重复读和幻读问题,但是不可以发生脏读问题REPEATABLE READ隔离级别下,可能发生幻读问题,但是不可以发生脏读和不可重复读的问题SERIALIZABLE隔离级别下,各种问题都不可以发生对于MySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读),从上面的SQL标准的四种隔离级别定义可知,REPEATABLE-READ(可重复读)是不可以防止幻读的,但是我们都知道,MySQL InnoDB存储引擎是解决了幻读问题发生的,那他又是如何解决的呢?
在进入主题之前,我们先大致了解一下什么是行格式,这样有助于我们理解下面的MVCC,行格式是表中的行记录在磁盘的存放方式,Innodb存储引擎总共有4种不同类型的行格式:compact、redundant、dynamic、compress;虽然很很多行格式,但是在原理上,大体都相同,如下,为compact行格式: 从图中可以看出来,一条完整的记录其实可以被分为
从图中可以看出来,一条完整的记录其实可以被分为记录的额外信息和记录的真实数据两大部分,记录的额外信息分别是变长字段长度列表、NULL值列表和记录头信息,而记录的真实数据除了我们自己定义的列之外,MySQL会为每个记录添加一些默认列,这些默认列又称为隐藏列
입니다. 위의 SQL 표준의 4가지 격리 수준 정의에서 REPEATABLE-READ(반복 읽기)를 방지할 수 없음을 알 수 있습니다. reading | , 하지만 우리 모두는 MySQL InnoDB 스토리지 엔진이 팬텀 읽기 문제를 해결한다는 것을 알고 있는데 어떻게 해결할까요? 1. 행 형식 | 본론에 들어가기 전에 행 형식이 무엇인지 대략적으로 알아보면 다음 MVCC를 이해하는 데 도움이 됩니다. row 형식은 테이블의 행 레코드가 디스크에 저장되는 방식입니다. |
|---|---|---|
| 열 이름 | 길이 | 설명 |
| row_id | 6바이트 | |
| transaction_id | 6바이트 |
숨겨진 열의 값에 대해 걱정할 필요가 없습니다. InnoDB 스토리지 엔진이 이를 더 자세히 그려보겠습니다. 형식은 다음과 같습니다: InnoDB存储引擎会自己帮我们生成的,画得再详细一点,compact行格式如下:
然后将roll_pointer 指向该undolog,所以该列相当于一个指针,通过该列,可以找到修改之前的信息假设有一条记录如下: 插入该记录的
插入该记录的事务id为80,roll_pointer 指针为NULL(为了便于理解,读者可理解为指向为NULL,实际上roll_pointer第一个比特位就标记着它指向的undo日志的类型,如果该比特位的值为1时,就代表着它指向的undo日志类型为insert undo)
假设之后两个事务id分别为100、200的事务对这条记录进行UPDATE操作:
-- 事务id=100 update person set grade =20 where id =1; update person set grade =40 where id =1; -- 事务id=200 update person set grade =70 where id =1;
每次对记录进行改动,都会记录一条undo日志,每条undo日志也都有一个roll_pointer属性(INSERT操作对应的undo日志没有该属性,因为该记录并没有更早的版本),可以将这些undo日志都连起来,串成一个链表,所以现在的情况就像下图一样:
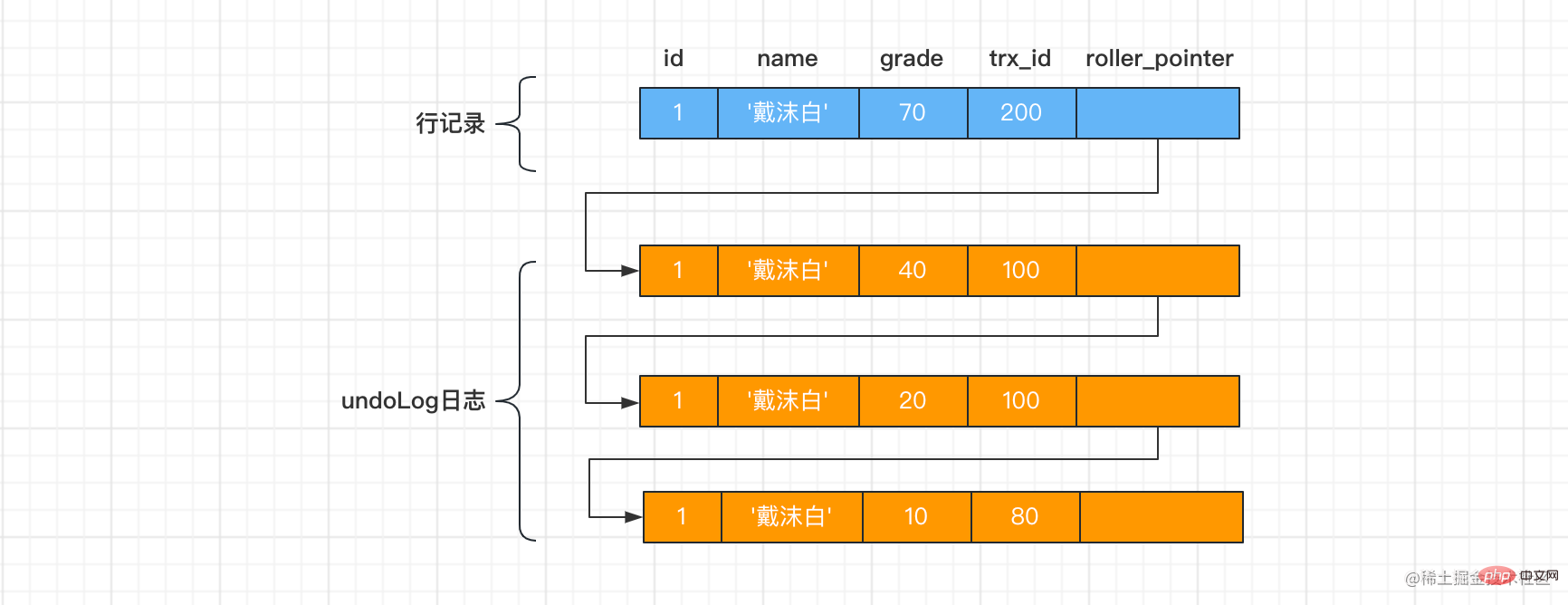 对该记录每次更新后,都会将旧值放到一条
对该记录每次更新后,都会将旧值放到一条undo日志中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被roll_pointer属性连接成一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的事务id
对于数据库的四种隔离级别:1)read uncommitted;2) read committed;3) REPEATABLE READ; 4)SERIALIZABLE;来说,READ UNCOMMITTED,每次读取版本链的最新数据即可;SERIALIZABLE,主要是通过加锁控制;而read committed和REPEATABLE READ都是读取已经提交了的事物,所以对于这两个隔离级别,核心问题是版本链中,哪些事物是对当前事物可见;为了解决这个问题,MySQL提出了read view 概念,其包含四个核心概念:
m_ids:生成read view 时候,活跃的事物id集合min_trx_id:m_ids的最小值,既生成read view的时候,活跃事物的最小值max_trx_id:表示生成read view的时候,系统应该分配下一个事物id值creator_trx_id:创建read view的事物id,即当前事物id。有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
creator_trx_id的时候,说明当前事物正在访问自己修改的记录,所以该版本可见min_trx_id的时候,则说明,在创建read view的时候,该事物已经提交,该版本,对当前事物可读max_trx_id,则说明创建该read view的时候,该说明生成该版本记录的事物id在生成Read view之后才开启,所以该版本不能被当前事物可读transaction_id在m_ids集合中,说明生成Read view的时候,该事物还是活跃的,还没有被提交,则该版本不可以被访问;如果不在,则说明创建ReadView
그런 다음 Roll_pointer는 실행 취소이므로 이 열은 포인터와 동일하며 전달됩니다. 이 열에서는 수정 전 정보를 확인할 수 있습니다🎜<h2 data-id="heading-1">
<strong>MVCC 세부 정보</strong> </h2>
<h3 data-id="heading-2"> <strong>2.1 버전 체인</strong>
</h3>🎜다음과 같은 레코드가 있다고 가정합니다: <img src="https://img.%20php.cn/upload/article/000/000/024/a3789b0f8f8d61a35c454c5a61c58645-2.png" alt="MySQL이 팬텀 읽기 문제를 어떻게 해결하는지 간략하게 분석한 기사" loading="lazy">이 레코드에 삽입된 <code>트랜잭션 ID는 80이고 roll_pointer 포인터는 NULL입니다. (이해의 편의를 위해 독자는 포인터가 NULL이라는 것을 이해할 수 있습니다. 실제로 Roll_pointer의 첫 번째 비트는 실행 취소 로그 유형을 표시합니다. 이 비트의 값이 1이면 그것이 가리키는 실행 취소 로그를 나타냅니다. 유형은 insert undo입니다.🎜🎜트랜잭션 ID를 가진 다음 두 트랜잭션이 라고 가정합니다. 100 및 200 - 이 레코드 업데이트 작업: 🎜rrreee🎜 레코드가 수정될 때마다 실행 취소 로그가 기록됩니다. , 각 실행 취소 로그에는 roll_pointer code> 속성도 있습니다(INSERT 작업에 해당하는 실행 취소 로그는 레코드에 이전 버전이 없기 때문에 이 속성이 없습니다.) 이러한 실행 취소 로그는 모두 연결 목록으로 연결되어 연결되어 있으므로 현재 상황은 아래 그림과 같습니다. 🎜🎜 따라서 기록이 업데이트될 때마다 , 이전 값은
따라서 기록이 업데이트될 때마다 , 이전 값은 실행 취소 로그에 저장됩니다. 이는 레코드 버전의 이전 값이더라도 업데이트 횟수가 증가함에 따라 모든 버전이 roll_pointer 속성을 버전 체인의 헤드 노드인 버전 체인이라고 부릅니다. 현재 레코드의 최신 값입니다. 또한 각 버전에는 해당 트랜잭션 ID🎜커밋되지 않은 읽기; 2) 커밋된 읽기 3) REPEATABLE READ; ; 예를 들어, READ UNCOMMITTED는 매번 버전 체인의 최신 데이터만 읽어야 하며 SERIALIZABLE은 주로 잠금 및 읽기 커밋을 통해 제어됩니다. > 및 REPEATABLE READ는 모두 커밋된 항목을 읽습니다. 따라서 이 두 격리 수준의 경우 핵심 문제는 버전 체인의 어떤 항목이 현재 항목에 표시되는지입니다. 이 문제를 해결하기 위해 MySQL은 다음을 제안했습니다. 네 가지 핵심 개념이 포함된 읽기 보기 개념: 🎜m_ids: 읽기 보기를 생성할 때 활성 사물 ID 세트 🎜min_trx_id: m_ids의 최소값, 읽기 보기 생성 시 활성 사물의 최소값🎜max_trx_id : 읽기 보기, 시스템은 다음 사물 ID 값을 할당해야 합니다🎜creator_trx_id: 읽기 보기의 사물 ID를 생성합니다. 현재 사물 ID. 🎜🎜🎜이 ReadView를 사용하면 레코드에 액세스할 때 아래 단계에 따라 레코드의 특정 버전이 표시되는지 확인하기만 하면 됩니다.  🎜
🎜min_trx_id보다 작은 경우 , 이는 읽기 보기를 생성할 때 해당 사물이 제출되었으며, 이 버전이 현재 사물에 대해 읽을 수 있다는 의미입니다.🎜max_trx_id는 생성되었음을 의미합니다. 읽기 보기를 사용하면 읽기 보기가 활성화될 때까지 이 버전 레코드를 생성하는 사물 ID가 열리지 않는다는 의미입니다. 생성되므로 현재 항목에서 이 버전을 읽을 수 없습니다🎜transaction_id가 m_ids 컬렉션에 있는 경우 읽을 때 view가 생성되고 트랜잭션이 여전히 활성 상태이고 아직 제출되지 않은 경우 이 버전에 액세스할 수 없습니다. 이는 ReadView를 생성할 때 이 버전을 생성한 트랜잭션을 의미합니다. 제출되었으며 액세스할 수 있습니다🎜🎜🎜참고: 읽은 사물의 사물 ID는 0🎜입니다.MySQL에서 READ COMMITTED와 REPEATABLE READ의 격리 수준 사이의 매우 큰 차이점은 서로 다른 시간에 ReadView를 생성한다는 것입니다. MySQL中,READ COMMITTED和REPEATABLE READ隔离级别的的一个非常大的区别就是它们生成ReadView的时机不同:
READ COMMITTED —— 每次读取数据前都生成一个ReadView
REPEATABLE READ —— 在第一次读取数据时生成一个ReadView
下面我们通过详细例子来说明,两者有何不同:
| 时间编号 | trx 100 | trx 200 | |
|---|---|---|---|
| ① | BEGIN; | ||
| ② | BEGIN; | BEGIN; | |
| ③ | update person set grade =20 where id =1; | ||
| ④ | update person set grade =40 where id =1; | ||
| ⑤ | SELECT * FROM person WHERE id = 1; | ||
| ⑥ | COMMIT; | ||
| ⑦ | update person set grade =70 where id =1; | ||
| ⑧ | SELECT * FROM person WHERE id = 1; | ||
| ⑨ | COMMIT; | ||
| ? | COMMIT; |
在时间④中,因事务trx 100 执行了事务的提交,id=1行记录的版本链如下:
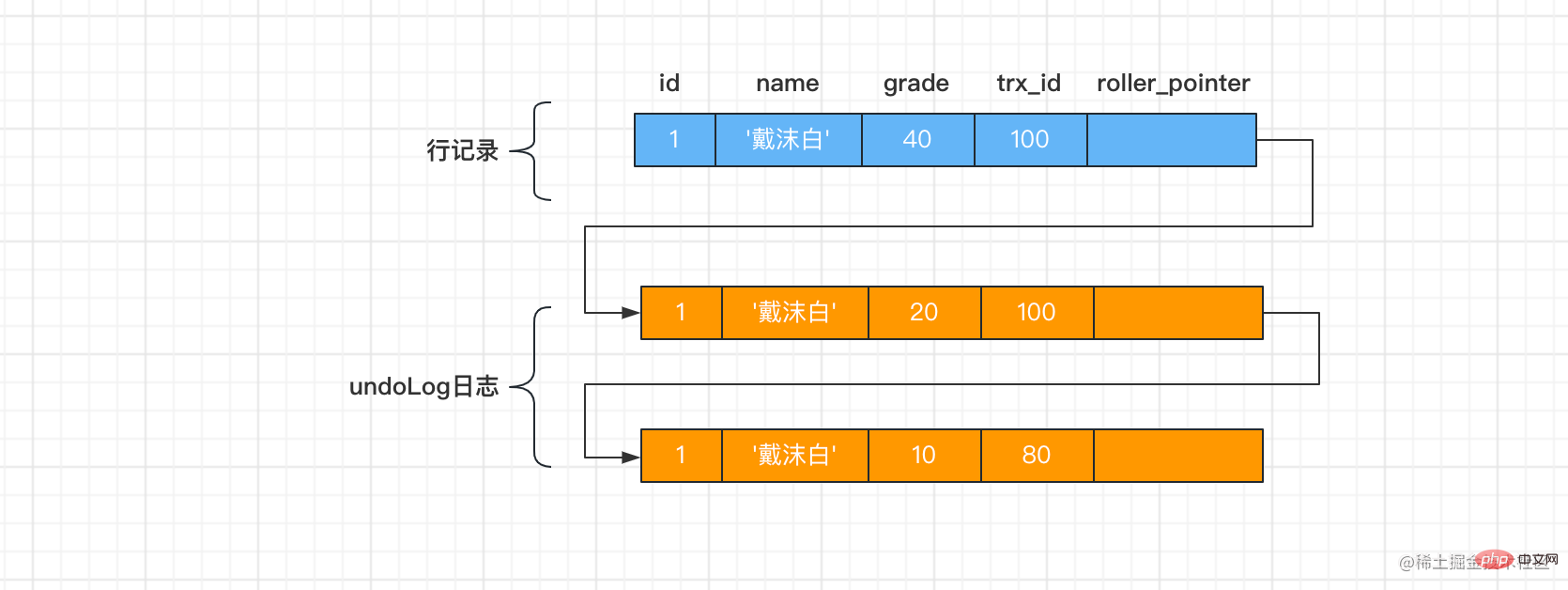 在时间⑥中,因事务
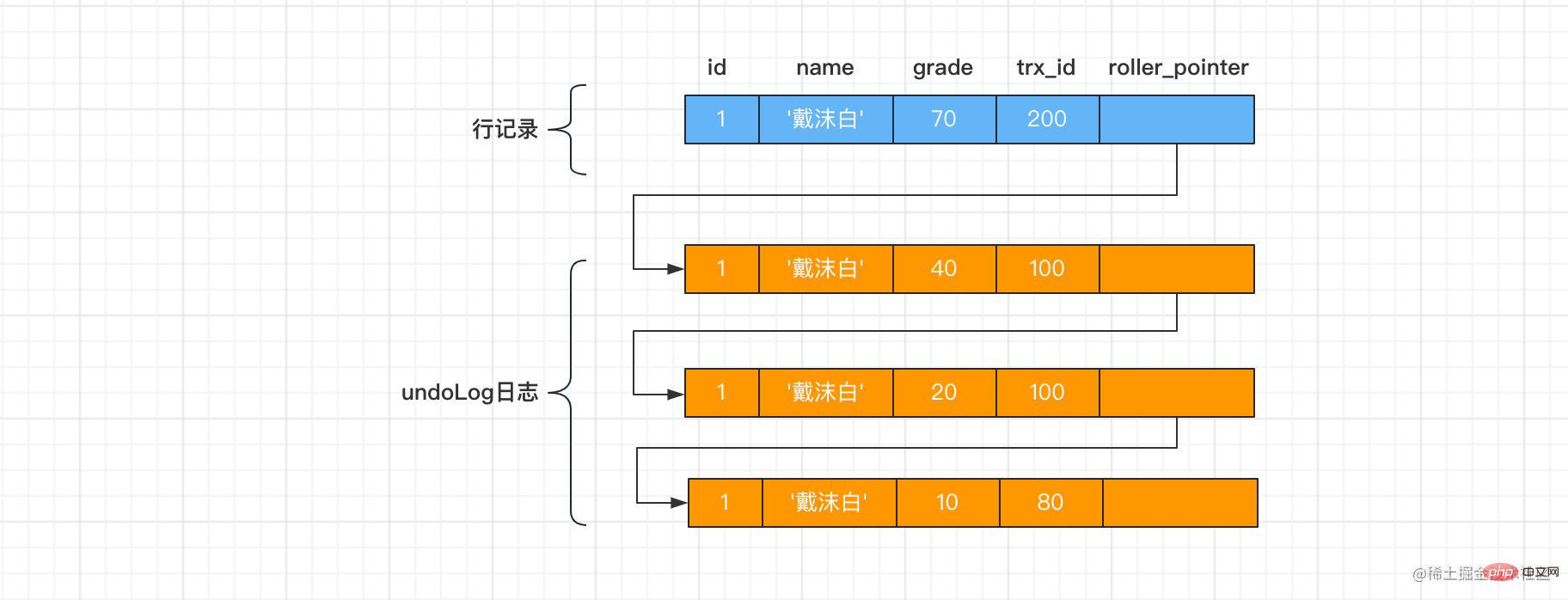
在时间⑥中,因事务trx 200 执行了事务的提交,id=1行记录的版本链如下:
在时间⑤,事务trx 100执行select语句时会先生成一个ReadView,ReadView的m_ids列表的内容就是[100, 200],min_trx_id为100,max_trx_id为201,creator_trx_id为0,此时,从版本链中选可见的记录,版本链从上到下遍历:因为grade=40,trx_id值为100,在m_ids里,所以该记录不可见,同理,grade=20的也不见。继续往下遍历,grade=20,trx_id值为80,小于小于ReadView中的min_trx_id值100,所以这个版本符合要求,返回给用户的是等级为10的记录。
在时间⑧中,如果事务的隔离级别是READ COMMITTED,会单独又生成一个ReadView,该ReadView的m_ids列表的内容就是[200],min_trx_id为200,max_trx_id为201,creator_trx_id为0,此时,从版本链中选可见的记录,版本链从上到下遍历:因为grade=70,trx_id值为200,在m_ids里,所以该记录不可见,继续往下遍历,grade=40,trx_id值为100,小于ReadView中的min_trx_id值200,所以这个版本是符合要求的,返回给用户的是是等级为40的记录。
在时间⑧中,如果事务的隔离级别是 REPEATABLE READ,在时间⑧中,不会单独生成一个ReadView,而是沿用时间5的ReadView,所以返回给用户的等级是10。前后两次select得到的是一样的,这就是可重复读的含义。
通过分析MVCC详解部分,可以得出,基于MVCC,在RR隔离级别下,很好解决了幻读问题,但是我们知道,select for update是产生当前读,不再是快照读,那么此种情况,MySQL又是怎么解决幻读问题的呢?基于时间问题(整理画图的确需要花比较多的时间),此处先给结论,后面再分析在当前读的情况下,MySQL是怎么解决幻读
READ COMMITTED —— 데이터를 읽기 전에 매번 ReadView를 생성합니다. REPEATABLE READ —— 처음으로 데이터를 읽을 때 ReadView| 시간 숫자 | trx 100 | trx 200 | |
|---|---|---|---|
| ① td> | 시작; | ||
| ② |
|
시작; | 시작; |
| 3 | ID =1인 경우 개인 설정 등급 =20 업데이트; | ||
| 4 | |
ID =1인 경우 개인 세트 등급 =40 업데이트; | |
| ⑤ td> | SELECT * FROM 사람 WHERE ID = 1; | ||
| ⑥ | 커밋; | ||
| 7 | 개인 설정 등급 =70, ID =1인 업데이트; | ||
| 8 | SELECT * FROM 사람 WHERE ID = 1; | ||
| ⑨ | 커밋; | ||
| ? | COMMIT; |
trx 100 트랜잭션에 대해 id=1 줄에 기록된 버전 체인은 다음과 같습니다.  6시, 트랜잭션 제출을 실행하는
6시, 트랜잭션 제출을 실행하는 trx 200 트랜잭션으로 인해 버전이 id=1 행 레코드의 체인은 다음과 같습니다:
trx 100 트랜잭션이 select 문을 실행할 때 먼저 ReadView를 생성합니다. >, ReadView의 m_ids 목록 내용은 [100, 200]이고, min_trx_id는 입니다. 100, max_trx_id는 201, creator_trx_id는 0입니다. 이때 보이는 것을 선택하세요. 버전 체인의 기록입니다. 버전 체인은 맨 위에서 시작하여 다음으로 이동합니다. grade=40이므로 trx_id의 값은 에 있는 <code>100입니다. m_ids이므로 기록이 보이지 않습니다. 마찬가지로 grade= 20세 미만의 항목도 누락되었습니다. 계속해서 아래로 이동하세요. grade=20, trx_id 값은 80이며, 이는 ReadView의 min_trx_id 값 code>100이므로 이 버전은 요구 사항을 충족하며 수준 10의 기록이 사용자에게 반환됩니다. 🎜🎜8번 시점에서 트랜잭션의 격리 수준이 READ COMMITTED인 경우 별도의 ReadView가 생성되며, 이 ReadView /code> m_ids 목록의 내용은 [200]이고 min_trx_id는 200이며 max_trx_id입니다. code>는 <code> 201, creator_trx_id는 0입니다. 이때 버전 체인에서 보이는 레코드를 선택하고, 위에서부터 버전 체인을 순회합니다. 맨 아래로: grade=70이므로 trx_id 값은 m_ids에 있는 200이므로 레코드가 계속해서 아래로 탐색됩니다. grade=40,trx_id >값은 100이며, min_trx_id 값 200보다 작습니다. >ReadView이므로 이 버전이 요구 사항을 충족하므로 사용자에게 제공되는 것은 레벨 40의 레코드입니다. 🎜🎜8번 시간에 트랜잭션의 격리 수준이 REPEATABLE READ인 경우 8번 시간에는 별도의 ReadView가 생성되지 않지만 가 생성됩니다. >ReadView가 사용되므로 사용자에게 반환되는 레벨은 10입니다. 두 선택의 결과는 동일합니다. 반복 읽기의 의미입니다. 🎜 팬텀은 읽기 문제를 잘 해결했지만 업데이트를 위해 선택이 현재 읽기를 생성하고 더 이상 스냅샷 읽기가 아니라는 것을 알고 있습니다. 이 경우 MySQL은 팬텀 읽기 >문제는 어떻습니까? 시간 문제(그림을 정리하고 그리는 데 시간이 많이 걸립니다)를 기반으로 먼저 여기서 결론을 내린 다음 현재 읽기 상황에서 MySQL이 <code>팬텀 읽기 문제를 어떻게 해결하는지 분석해 보겠습니다. 🎜🎜🎜🎜 현재 읽기🎜: Next-Key Lock(gap lock)을 사용하여 팬텀 읽기가 발생하지 않도록 잠급니다🎜🎜🎜Gap lock이 현재 읽기 상황에서 팬텀 읽기 문제를 어떻게 해결하는지에 대해 관심 있는 친구는 추가할 수 있습니다. 좋아요🎜🎜[관련 추천: 🎜mysql 비디오 튜토리얼🎜]🎜
위 내용은 MySQL이 팬텀 읽기 문제를 어떻게 해결하는지 간략하게 분석한 기사의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!









![MySQL 쿼리 최적화 솔루션 [주요 제조업체의 설계자가 강의] [MySQL 인덱싱 시작하기] 고급 자습서 |](https://img.php.cn/upload/course/000/000/068/6242a7d5be236814.png)









![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



