

스레드와 프로세스는 컴퓨터 운영체제의 기본 개념이자 프로그래머들 사이에서 자주 등장하는 단어입니다. 그렇다면 이를 어떻게 이해하시나요? Node.js의 프로세스와 스레드는 어떻습니까? 다음 문서에서는 Node의 프로세스와 스레드에 대한 심층적인 이해를 제공합니다. 도움이 필요한 친구들이 모두 참고할 수 있기를 바랍니다.

위의 설명은 상대적으로 어렵고, 읽은 후에는 이해하지 못할 수도 있어 이해와 기억에 도움이 되지 않습니다. 그럼 간단한 예를 들어보겠습니다.
당신이 어떤 특급 배송 사이트에 있는 남자라고 가정해 보세요. 처음에는 이 사이트가 담당하는 지역에 주민이 많지 않고, 당신만이 택배를 수거하는 사람입니다. 패키지를 Zhang San의 집으로 배달한 후 Li Si의 집으로 가서 가져가는 작업을 하나씩 수행해야 합니다. 이를 단일 스레드라고 하며 모든 작업은 순서대로 수행되어야 합니다.
나중에는 이 지역에 더 많은 주민이 생겼고, 사이트에서는 이 지역에 더 많은 사람과 팀 리더를 배정했습니다. 이를 멀티 스레딩이라고 하며, 팀 리더는 메인 스레드입니다. 모든 사람은 스레드입니다.
빠른 배송 사이트에서 사용하는 트롤리와 같은 도구는 사이트에서 제공되며 한 사람이 아니라 누구나 사용할 수 있습니다. 이를 멀티 스레드 리소스 공유라고 합니다.
현재 사이트 장바구니는 하나만 있으며 모든 사람이 이를 사용해야 합니다. 이를 충돌이라고 합니다. 줄을 서서 기다리거나 다른 사람이 작업을 마쳤을 때 알림을 기다리는 등 이를 해결하는 방법은 다양합니다. 이를 스레드 동기화라고 합니다.
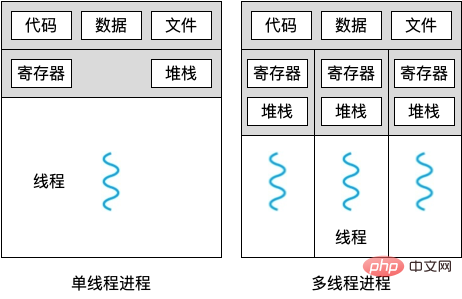
본사에는 여러 사이트가 있으며 각 사이트의 운영 모델은 거의 동일합니다. 이를 멀티 프로세스라고 합니다. 본사를 주공정, 각 현장을 하부공정이라고 합니다.
본사와 현장 간, 각 현장 간 카트는 서로 독립적이며 혼합될 수 없습니다. 이를 프로세스 간 리소스 공유 없음이라고 합니다. 각 사이트는 전화 통화 등을 통해 서로 통신할 수 있습니다. 이를 파이프라인이라고 합니다. 프로세스 간 동기화라고 하는 대규모 컴퓨팅 작업의 완료를 용이하게 하기 위해 사이트 간 협업을 위한 다른 수단이 있습니다.
Ruan Yifeng의 프로세스 및 스레드에 대한 간단한 설명도 살펴보실 수 있습니다.
Node.js는 단일 스레드 서비스, 이벤트 중심 및 비차단 I/O 모델 언어 기능으로 Node.js를 효율적이고 가볍게 만듭니다. 장점은 빈번한 스레드 전환과 리소스 충돌을 피한다는 것입니다. I/O 집약적인 작업에 적합합니다(기본 모듈 libuv는 멀티태스킹을 수행하기 위해 멀티스레드를 통해 운영 체제에서 제공하는 비동기 I/O 기능을 호출합니다). , 그러나 서버 측 Node.js의 경우 초당 수백 개의 요청을 처리해야 할 수 있습니다. CPU 집약적인 요청에 직면하면 단일 스레드 모드이므로 필연적으로 차단이 발생합니다.
우리는 Koa를 사용하여 간단하게 웹 서비스를 구축하고 Fibonacci 수열 방법을 사용하여 CPU 집약적인 컴퓨팅 작업을 처리하는 Node.js를 시뮬레이션합니다.
Fibonacci 숫자 시퀀스라고도 함 황금분할 순서로 세 번째 항목부터 시작하고 각 항목은 이전 두 항목의 합과 같습니다: 0, 1, 1, 2, 3, 5, 8, 13, 21,... .
// app.js
const Koa = require('koa')
const router = require('koa-router')()
const app = new Koa()
// 用来测试是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', (ctx) => {
const { num = 38 } = ctx.query
const start = Date.now()
// 斐波那契数列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
ctx.body = {
pid: process.pid,
duration: Date.now() - start
}
})
app.use(router.routes())
app.listen(9000, () => {
console.log('Server is running on 9000')
})Executionnode app.js 서비스를 시작하고 Postman을 사용하여 요청을 보내면 38개의 계산이 617ms가 소요된 것을 볼 수 있습니다. 즉, CPU 집약적인 컴퓨팅 작업을 수행했기 때문에 Node.js 메인 스레드가 6개 이상 차단되었습니다. 백 밀리초. 동시에 처리되는 요청이 더 많거나 계산 작업이 더 복잡하면 해당 요청 이후의 모든 요청이 지연됩니다.

여러 요청 전송을 시뮬레이션하기 위해 새로운 axios.js를 만들어 보겠습니다. 이때 더 복잡한 컴퓨팅 작업을 시뮬레이션하려면 app.js의 fibo 계산 수를 43으로 변경하세요.
// axios.js
const axios = require('axios')
const start = Date.now()
const fn = (url) => {
axios.get(`http://127.0.0.1:9000/${ url }`).then((res) => {
console.log(res.data, `耗时: ${ Date.now() - start }ms`)
})
}
fn('test')
fn('fibo?num=43')
fn('test')
可以看到,当请求需要执行 CPU 密集型的计算任务时,后续的请求都被阻塞等待,这类请求一多,服务基本就阻塞卡死了。对于这种不足,Node.js 一直在弥补。
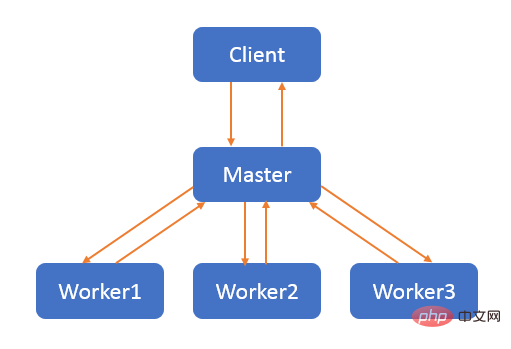
master-worker 模式是一种并行模式,核心思想是:系统有两个及以上的进程或线程协同工作时,master 负责接收和分配并整合任务,worker 负责处理任务。
线程是 CPU 调度的一个基本单位,只能同时执行一个线程的任务,同一个线程也只能被一个 CPU 调用。如果使用的是多核 CPU,那么将无法充分利用 CPU 的性能。
多线程带给我们灵活的编程方式,但是需要学习更多的 Api 知识,在编写更多代码的同时也存在着更多的风险,线程的切换和锁也会增加系统资源的开销。
worker_threads 是 Node.js 提供的一种多线程 Api。对于执行 CPU 密集型的计算任务很有用,对 I/O 密集型的操作帮助不大,因为 Node.js 内置的异步 I/O 操作比 worker_threads 更高效。worker_threads 中的 Worker,parentPort 主要用于子线程和主线程的消息交互。
将 app.js 稍微改动下,将 CPU 密集型的计算任务交给子线程计算:
// app.js
const Koa = require('koa')
const router = require('koa-router')()
const { Worker } = require('worker_threads')
const app = new Koa()
// 用来测试是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', async (ctx) => {
const { num = 38 } = ctx.query
ctx.body = await asyncFibo(num)
})
const asyncFibo = (num) => {
return new Promise((resolve, reject) => {
// 创建 worker 线程并传递数据
const worker = new Worker('./fibo.js', { workerData: { num } })
// 主线程监听子线程发送的消息
worker.on('message', resolve)
worker.on('error', reject)
worker.on('exit', (code) => {
if (code !== 0) reject(new Error(`Worker stopped with exit code ${code}`))
})
})
}
app.use(router.routes())
app.listen(9000, () => {
console.log('Server is running on 9000')
})新增 fibo.js 文件,用来处理复杂计算任务:
const { workerData, parentPort } = require('worker_threads')
const { num } = workerData
const start = Date.now()
// 斐波那契数列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
parentPort.postMessage({
pid: process.pid,
duration: Date.now() - start
})执行上文的 axios.js,此时将 app.js 中的 fibo 计算次数改为 43,用来模拟更复杂的计算任务:

可以看到,将 CPU 密集型的计算任务交给子线程处理时,主线程不再被阻塞,只需等待子线程处理完成后,主线程接收子线程返回的结果即可,其他请求不再受影响。
上述代码是演示创建 worker 线程的过程和效果,实际开发中,请使用线程池来代替上述操作,因为频繁创建线程也会有资源的开销。
线程是 CPU 调度的一个基本单位,只能同时执行一个线程的任务,同一个线程也只能被一个 CPU 调用。
我们再回味下,本小节开头提到的线程和 CPU 的描述,此时由于是新的线程,可以在其他 CPU 核心上执行,可以更充分的利用多核 CPU。
Node.js 为了能充分利用 CPU 的多核能力,提供了 cluster 模块,cluster 可以通过一个父进程管理多个子进程的方式来实现集群的功能。
cluster 底层就是 child_process,master 进程做总控,启动 1 个 agent 进程和 n 个 worker 进程,agent 进程处理一些公共事务,比如日志等;worker 进程使用建立的 IPC(Inter-Process Communication)通信通道和 master 进程通信,和 master 进程共享服务端口。
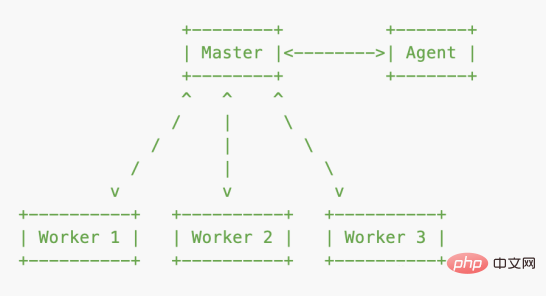
新增 fibo-10.js,模拟发送 10 次请求:
// fibo-10.js
const axios = require('axios')
const url = `http://127.0.0.1:9000/fibo?num=38`
const start = Date.now()
for (let i = 0; i {
console.log(res.data, `耗时: ${ Date.now() - start }ms`)
})
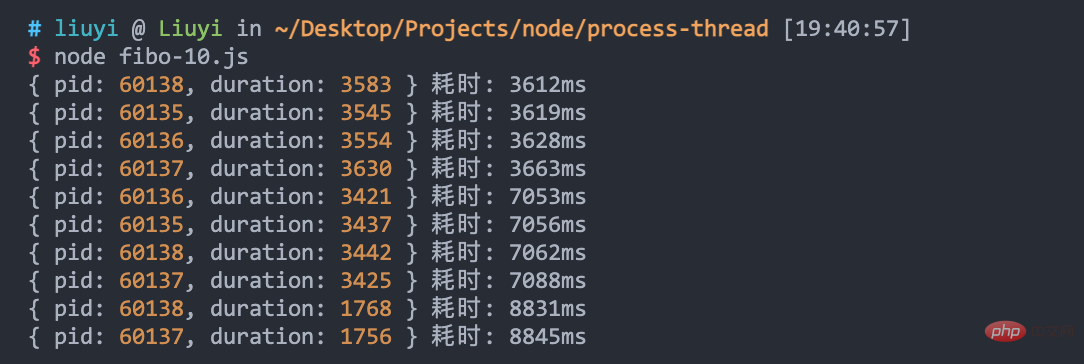
}可以看到,只使用了一个进程,10 个请求慢慢阻塞,累计耗时 15 秒:
接下来,将 app.js 稍微改动下,引入 cluster 模块:
// app.js
const cluster = require('cluster')
const http = require('http')
const numCPUs = require('os').cpus().length
// const numCPUs = 10 // worker 进程的数量一般和 CPU 核心数相同
const Koa = require('koa')
const router = require('koa-router')()
const app = new Koa()
// 用来测试是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', (ctx) => {
const { num = 38 } = ctx.query
const start = Date.now()
// 斐波那契数列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
ctx.body = {
pid: process.pid,
duration: Date.now() - start
}
})
app.use(router.routes())
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`)
// 衍生 worker 进程
for (let i = 0; i {
console.log(`worker ${worker.process.pid} died`)
})
} else {
app.listen(9000)
console.log(`Worker ${process.pid} started`)
}执行 node app.js 启动服务,可以看到,cluster 帮我们创建了 1 个 master 进程和 4 个 worker 进程:
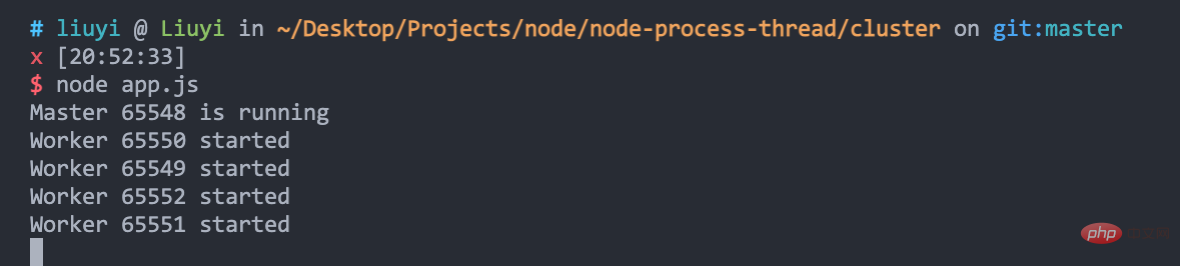
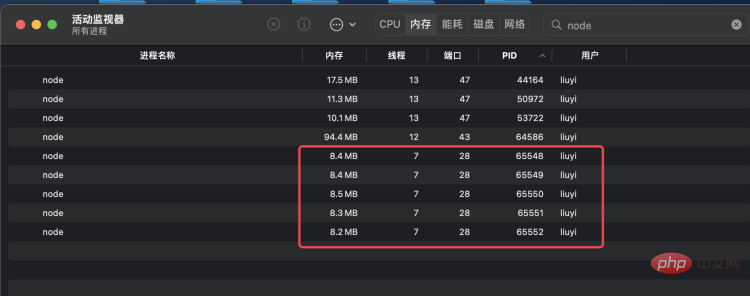
通过 fibo-10.js 模拟发送 10 次请求,可以看到,四个进程处理 10 个请求耗时近 9 秒:
10개의 작업자 프로세스가 시작되면 효과를 살펴보세요.
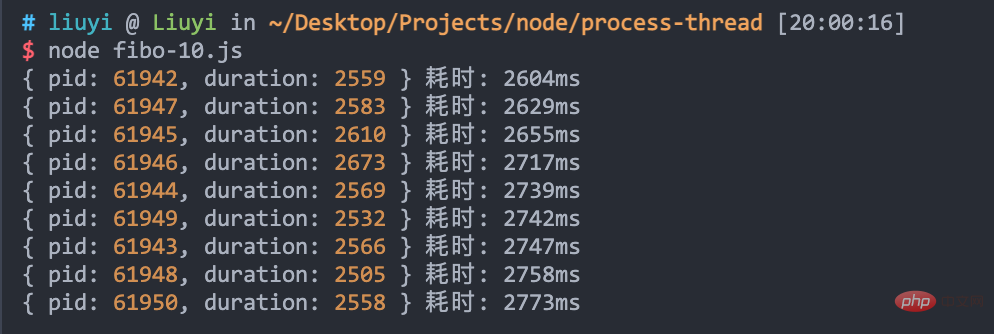
3초도 채 걸리지 않지만 프로세스 수는 무제한이 아닙니다. 일일 개발에서 작업자 프로세스 수는 일반적으로 CPU 코어 수와 동일합니다.
멀티 프로세스를 활성화하는 것은 전적으로 높은 동시성을 처리하기 위한 것이 아니라 Node.js의 멀티 코어 CPU 사용률 부족 문제를 해결하기 위한 것입니다.
fork 방식을 통해 상위 프로세스에서 파생된 하위 프로세스는 상위 프로세스와 동일한 리소스를 가지지만 독립적이며 서로 리소스를 공유하지 않습니다. 시스템 리소스가 제한되어 있기 때문에 일반적으로 프로세스 수는 CPU 코어 수에 따라 설정됩니다.
1. 멀티스레딩을 통한 CPU 집약적인 컴퓨팅 작업에 대한 대부분의 솔루션은 다중 프로세스 솔루션으로 대체될 수 있습니다.
2. 메인 스레드의 원활한 흐름을 보장하려면 CPU를 차단하지 않는 것이 가장 좋습니다.
3. 단지 시스템의 요구 사항을 충족하고 효율성을 높이세요. 민첩성은 프로젝트에 필요한 것이며 Node.js의 경량 기능이기도 합니다.
4. 기사에는 언급되었지만 자세히 논의되지 않거나 언급되지 않은 Node.js의 프로세스 및 스레드 개념이 많이 있습니다. 예: libuv, IPC 통신 채널, Node.js 기반 I/ O 데몬과 프로세스 간 리소스가 공유되지 않을 때 예약된 작업, 에이전트 프로세스 등을 처리하는 방법
5. 위 코드는 https://github.com/liuxy0551/node-process-thread에서 볼 수 있습니다.
노드 관련 지식을 더 보려면 nodejs 튜토리얼을 방문하세요!
위 내용은 Node의 프로세스와 스레드에 대한 심층 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!




















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



