


이 글은 mysql에 대한 관련 지식을 제공하며, 일반적인 쿼리 최적화와 관련된 문제를 주로 소개합니다. 모두에게 도움이 되기를 바랍니다.

추천 학습: mysql 비디오 튜토리얼
프로그램이 온라인에 있고 일정 시간 동안 실행된 후 데이터 양이 증가하면 시스템에서 지연, 지연 등을 어느 정도 느낄 것입니다. 이런 문제가 발생하는데, 시스템 튜닝 작업을 수행하려면 프로그래머나 아키텍트가 필요합니다. 많은 튜닝 방법이 있음을 알 수 있듯이, SQL 튜닝과 관련된 내용은 여전히 매우 중요한 부분입니다. , 작업에 포함될 수 있는 몇 가지 SQL 최적화 전략을 요약합니다.
대부분의 시스템에서는 더 많이 읽고 덜 쓰는 것이 표준이라고 할 수 있습니다. 이는 쿼리와 관련된 SQL이 매우 빈번하다는 것을 의미합니다.
준비, 테스트 테이블에 100,000개의 데이터 추가
다음 저장 프로시저를 사용하여 단일 테이블에 대한 데이터 배치를 생성하고 테이블을 자신의 테이블로 바꾸세요
create procedure addMyData() begin declare num int; set num =1; while num <= 100000 do insert into XXX_table values( replace(uuid(),'-',''),concat('测试',num),concat('cs',num),'123456' ); set num =num +1; end while; end ;
그런 다음 이 저장 프로시저를 호출하세요
call addMyData();
이 글에서는 테스트를 위해 각각 500,000, 10,000, 100,000개의 데이터를 포함하는 학생 테이블, 수업 테이블, 계좌 테이블 3개를 준비했습니다. ;
 1 페이징 쿼리는 개발 중에 자주 발생하는 상황은 페이징 수가 매우 많을 때 쿼리에 시간이 많이 걸리는 경우가 많습니다. 예를 들어 학생 테이블을 쿼리하려면 다음 SQL 쿼리를 사용하세요.
1 페이징 쿼리는 개발 중에 자주 발생하는 상황은 페이징 수가 매우 많을 때 쿼리에 시간이 많이 걸리는 경우가 많습니다. 예를 들어 학생 테이블을 쿼리하려면 다음 SQL 쿼리를 사용하세요.

limit 400000,10 을 실행하면, 정렬하기 전에 MySQL 4000이 필요합니다 10 record record, 400000 - 4 00만 반환됩니다. 010 레코드, 기타 레코드 삭제 및 쿼리 정렬 비용이 매우 높습니다
1)
SELECT * FROM student t1,(SELECT id FROM student ORDER BY id LIMIT 400000,10) t2 WHERE t1.id =t2.id;
执行上面的sql,可以看到响应时间有一定的提升;
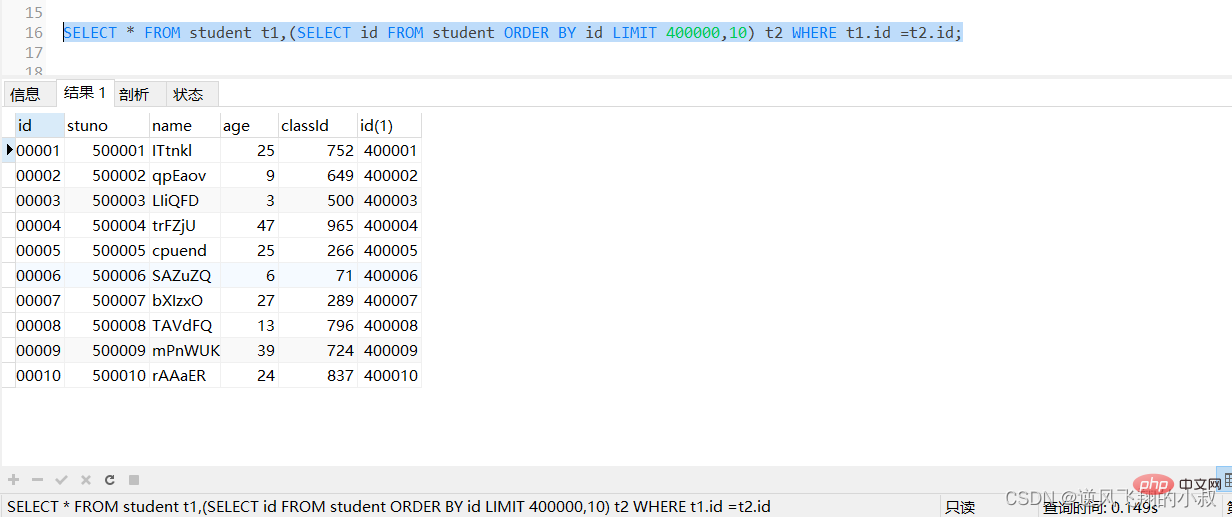
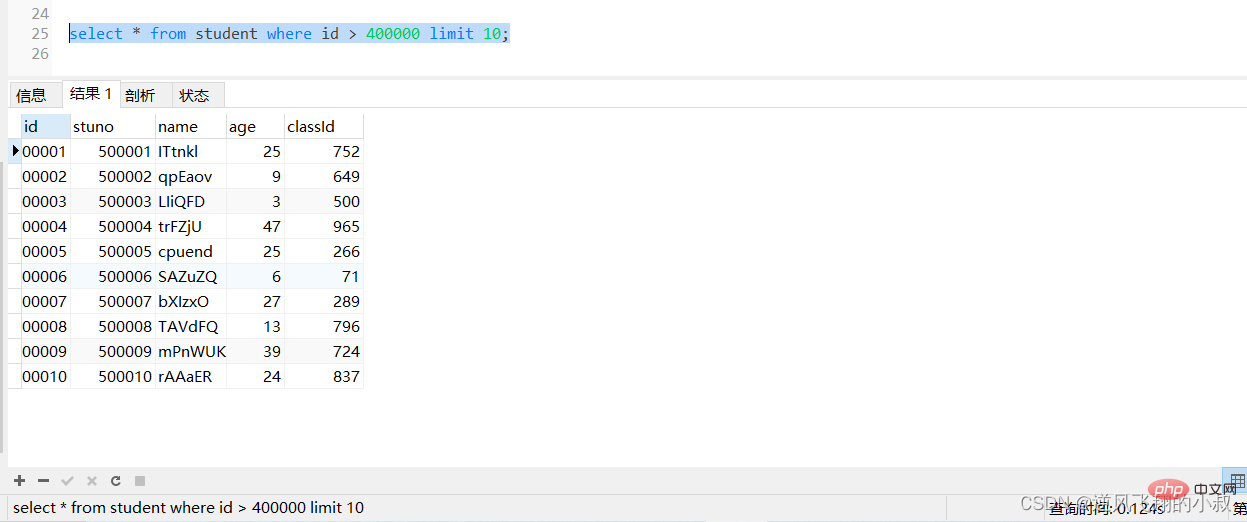
2)对于主键自增的表,可以把Limit 查询转换成某个位置的查询
select * from student where id > 400000 limit 10;
执行上面的sql,可以看到响应时间有一定的提升;
2、关联查询优化
在实际的业务开发过程中,关联查询可以说随处可见,关联查询的优化核心思路是,最好为关联查询的字段添加索引,这是关键,具体到不同的场景,还需要具体分析,这个跟mysql的引擎在执行优化策略的方案选择时有一定关系;
2.1 左连接或右连接
下面是一个使用left join 的查询,可以预想到这条sql查询的结果集非常大
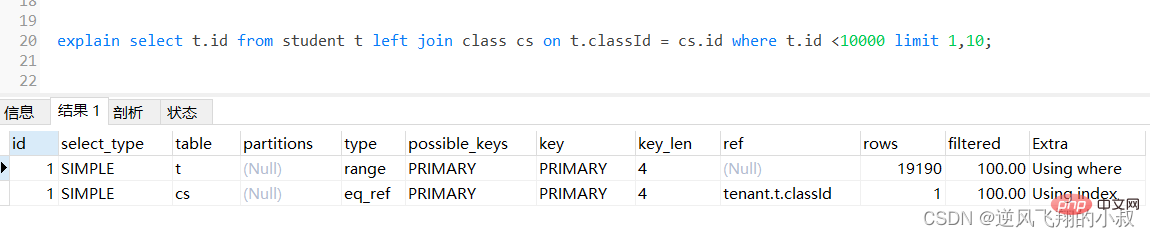
select t.* from student t left join class cs on t.classId = cs.id;로그인 후 복사为了检查下sql的执行效率,使用explain做一下分析,可以看到,第一张表即left join左边的表student走了全表扫描,而class表走了主键索引,尽管结果集较大,还是走了索引;
针对这种场景的查询,思路如下:
- 让查询的字段尽量包含在主键索引或者覆盖索引中;
- 查询的时候尽量使用分页查询;
关于左连接(右连接)的explain结果补充说明
- 左连接左边的表一般为驱动表,右边的表为被驱动表;
- 尽可能让数据集小的表作为驱动表,减少mysql内部循环的次数;
- 两表关联时,explain结果展示中,第一栏一般为驱动表;
2.2 关联查询关联的字段建立索引
看下面的这条sql,其关联字段非表的主键,而是普通的字段;
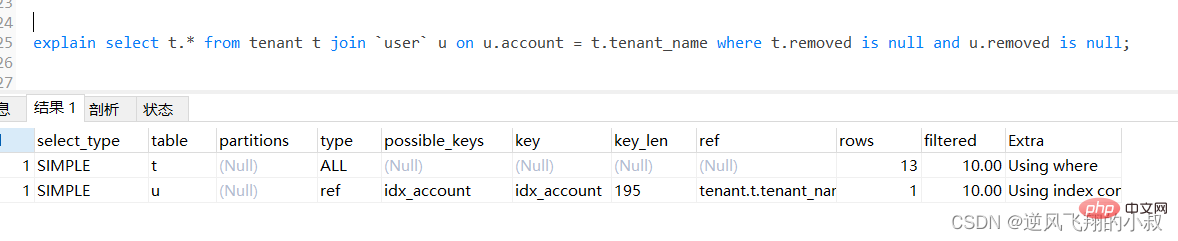
explain select u.* from tenant t left join `user` u on u.account = t.tenant_name where t.removed is null and u.removed is null;로그인 후 복사
通过explain分析可以发现,左边的表走了全表扫描,可以考虑给左边的表的tenant_name和user表的account 各自创建索引;
create index idx_name on tenant(tenant_name);
create index idx_account on `user`(account);
再次使用explain分析结果如下
可以看到第二行type变为ref,rows的数量优化比较明显。这是由左连接特性决定的,LEFT JOIN条件用于确定如何从右表搜索行,左边一定都有,所以右边是我们的关键点,一定需要建立索引 。
2.3 内连接关联的字段建立索引
我们知道,左连接和右连接查询的数据分别是完全包含左表数据,完全包含右表数据,而内连接(inner join 或join) 则是取交集(共有的部分),在这种情况下,驱动表的选择是由mysql优化器自动选择的;
在上面的基础上,首先移除两张表的索引
ALTER TABLE `user` DROP INDEX idx_account;
ALTER TABLE `tenant` DROP INDEX idx_name;使用explain语句进行分析
然后给user表的account字段添加索引,再次执行explain我们发现,user表竟然被当作是被驱动表了;
此时,如果我们给tenant表的tenant_name加索引,并移除user表的account索引,得出的结果竟然都没有走索引,再次说明,使用内连接的情况下,查询优化器将会根据自己的判断进行选择;
3、子查询优化
子查询在日常编写业务的SQL时也是使用非常频繁的做法,不是说子查询不能用,而是当数据量超出一定的范围之后,子查询的性能下降是很明显的,关于这一点,本人在日常工作中深有体会;
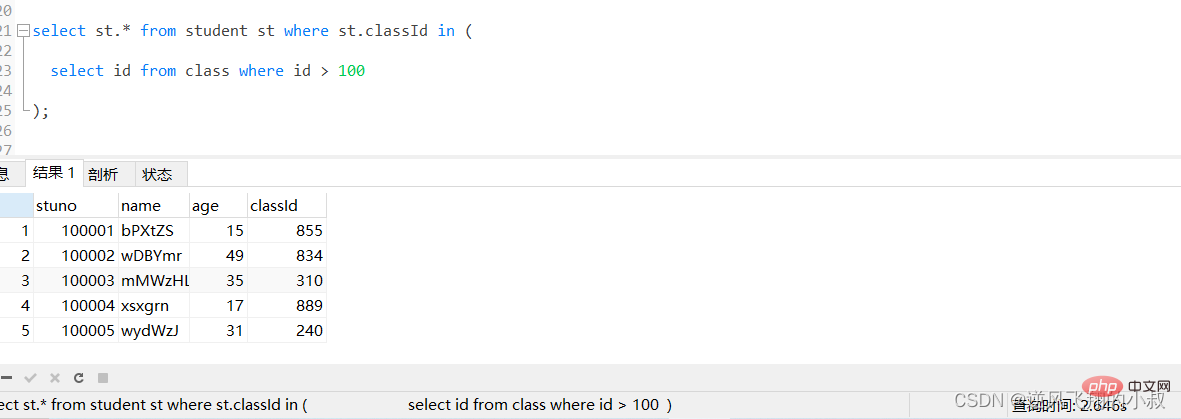
比如下面这条sql,由于student表数据量较大,执行起来耗时非常长,可以看到耗费了将近3秒;
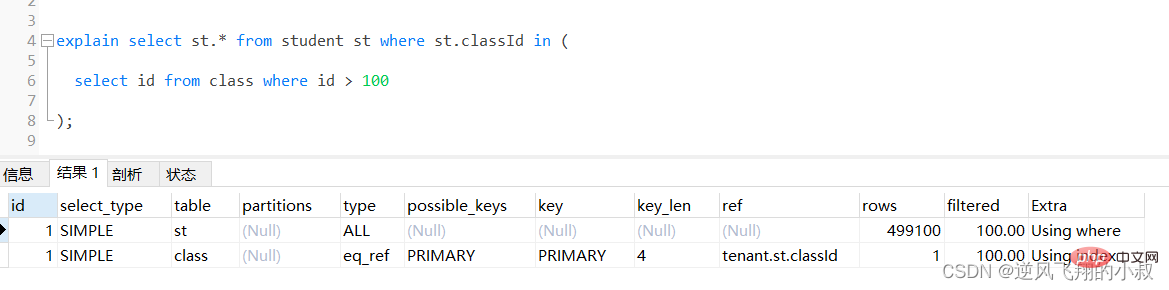
select st.* from student st where st.classId in ( select id from class where id > 100 );로그인 후 복사
通过执行explain进行分析得知,内层查询 id > 100的子查询尽管用上了主键索引,但是由于结果集太大,带入到外层查询,即作为in的条件时,查询优化器还是走了全表扫描;
针对上面的情况,可以考虑下面的优化方式
select st.id from student st join class cl on st.classId = cl.id where cl.id > 100;
子查询性能低效的原因
- 子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表 ,然后外层查询语句从临时表中查询记录,查询完毕后,再撤销这些临时表 。这样会消耗过多的CPU和IO资源,产生大量的慢查询;
- 子查询结果集存储的临时表,不论是内存临时表还是磁盘临时表都不能走索引 ,所以查询性能会受到一定的影响;
- 对于返回结果集比较大的子查询,其对查询性能的影响也就越大;
使用mysql查询时,可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表 ,其速度比子查询要快 ,如果查询中使用索引的话,性能就会更好,尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代;
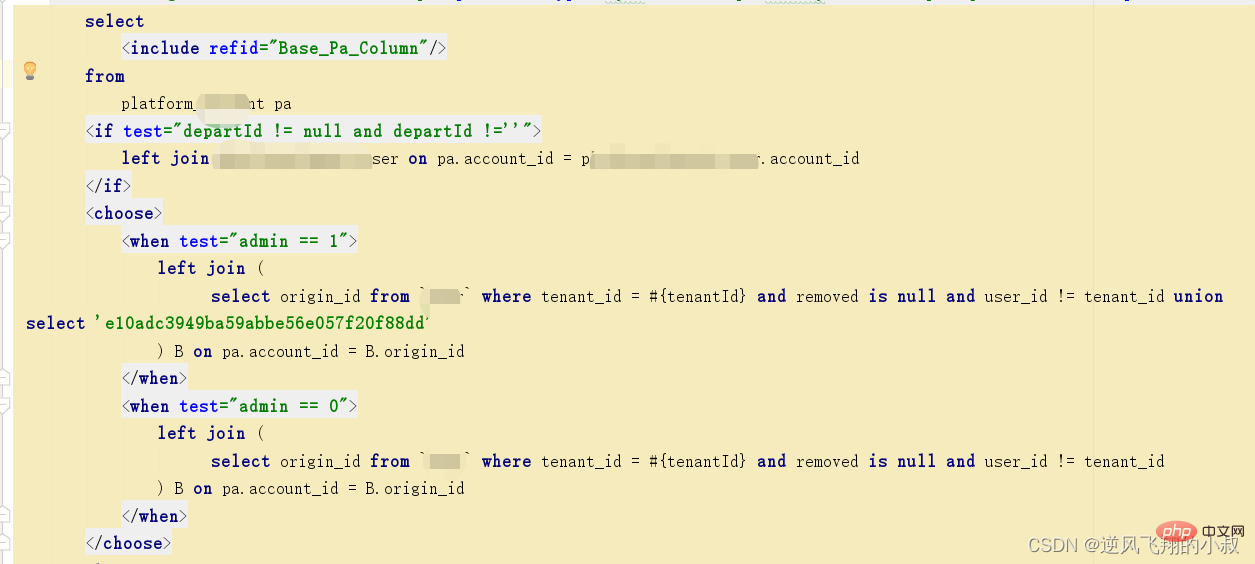
一个真实的案例
在下面的这段sql中,优化前使用的是子查询,在一次生产问题的性能分析中,发现某个tenant_id下的数据达到了35万多,这样直接导致某个列表页面的接口查询耗时达到了5秒左右;
找到了问题的根源后,尝试使用上面的优化思路进行解决即可,优化后的sql大概如下,
4、排序(order by)优化
在mysql,排序主要有两种方式
- Using filesort : 通过表索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort
buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序;- Using index : 通过有序的索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高;
对于以上两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index
4.1 使用age字段进行排序
由于age字段未加索引,查询结果按照age排序的时候发现使用了filesort,排序性能较低;
给age字段添加索引,再次使用order by时就走了索引;
4.2 使用多字段进行排序
通常在实际业务中,参与排序的字段往往不只一个,这时候,就可以对参与排序的多个字段创建联合索引;
如下根据stuno和age排序
给stuno和age添加联合索引
create index idx_stuno_age on `student`(stuno,age);
再次分析时结果如下,此时排序走了索引
关于多字段排序时的注意事项
1)排序时,需要满足最左前缀法则,否则也会出现 filesort;
위에서 생성한 조인트 인덱스의 순서는 stuno와 age입니다. 즉, stuno가 앞에 있고 age가 뒤에 있습니다. 쿼리 중에 정렬 순서가 바뀌면 어떻게 될까요? 결과를 분석한 결과 filesort를 사용한 것으로 나타났습니다.
2) 정렬 시 정렬 유형이 일관되게 유지됩니다.
필드 정렬 순서를 변경하지 않고 기본적으로 오름차순 또는 내림차순으로 유지하는 경우 order, order By는 인덱스를 사용할 수 있습니다. 하나는 오름차순이고 다른 하나는 내림차순이면 어떻게 될까요? 분석에 따르면 이 경우에도 filesort가 사용됩니다.
5. Group by 최적화
group by의 최적화 전략은 order by의 최적화 전략과 매우 유사합니다.
- 그룹별 필터링 조건이 없어도 인덱스를 직접 사용할 수 있습니다.
- 그룹별로 먼저 정렬한 다음 인덱스 구성을 위한 가장 좋은 왼쪽 접두사 규칙을 따릅니다.
- 인덱스 열을 사용할 수 없는 경우 max_length_for_sort_data 및 sort_buffer_size를 늘립니다.
- where가 갖는 것보다 더 효율적입니다. 조건을 where에 쓸 수 있으면 have에 쓰지 마세요.
- order by의 사용을 줄이고 가능하면 정렬을 사용하지 마세요. 프로그램. order by, group by 및 discover와 같은 문은 더 많은 CPU를 소비하며 데이터베이스의 CPU 리소스는 매우 중요합니다.
- SQL에 order by, group by 및 discover와 같은 쿼리 문이 포함된 경우 결과 집합을 유지하세요. 1000에서 where 조건으로 필터링됩니다. 그렇지 않으면 SQL이 매우 느려집니다.
5.1 필드별로 그룹화에 인덱스를 추가합니다.
필드가 인덱스되지 않은 경우 이 결과의 분석 결과는 다음과 같습니다. 는 분명히 매우 비효율적입니다
stuno에 인덱스를 추가한 후
stuno와 age에 조인트 인덱스를 추가합니다
최적의 왼쪽 접두어를 따르지 않으면 성능별 그룹이 상대적으로 비효율적
최적의 왼쪽 접두사를 따르는 상황은 다음과 같습니다
6. 카운트 최적화
count()는 반환된 결과 집합에 대해 한 줄씩 판단됩니다. .count 함수의 매개변수가 NULL이 아니면 누적값을 1씩 더하고, 그렇지 않으면 추가하지 않고 최종적으로 누적값을 반환합니다.
사용법: count(*), count(기본 키), count(필드), count(숫자)
다음은 count
Usage Explanation InnoDB는 모든 필드를 가져오지는 않지만 특히 값을 가져오지 않도록 최적화되어 있습니다. 서비스 계층은 행을 직접 누적합니다. count(기본 키) InnoDB가 테이블 전체를 순회하는 여러 가지 방법에 대한 자세한 설명입니다. , 각 행의 기본 키 ID 값을 가져와 서비스 계층에 반환합니다. 서비스 계층은 기본 키를 가져온 후 이를 행별로 직접 누적합니다(기본 키는 null일 수 없음). (*) 에는 null이 아닌 제약이 없습니다. 전체 테이블을 순회하여 각 행의 필드 값을 꺼내 서비스 계층으로 반환합니다. 서비스 계층은 null인지 여부를 확인하고 null 제약 조건이 없으면 개수를 누적합니다. : InnoDB 엔진은 각 행의 필드 값을 꺼내서 서비스 계층으로 반환하고 행별로 직접 누적합니다. count(필드) InnoDB 엔진은 전체 테이블을 탐색합니다. 하지만 그 가치를 받아들이지는 않습니다. 반환된 각 행에 대해 서비스 레이어는 숫자 "1"을 넣고 행별로 직접 누적합니다. 기본 키 ID) < count(1) ≒ count(*)이므로 count(*)를 사용해 보세요 count(number) 추천 학습: mysql 비디오 튜토리얼 위 내용은 MySql의 일반적인 쿼리 최적화 전략에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

































![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



