


한 기사로 SQL의 창 기능 이해

이 기사에서는 SQL 서버에 대한 관련 지식을 제공합니다. 분석 함수라고도 하는 두 가지 유형의 윈도우 함수가 있습니다. 하나는 집계 윈도우 함수이고, 다른 하나는 제가 주로 소개한 기사입니다. SQL의 윈도잉 기능에 대한 관련 정보를 예제 코드를 통해 자세히 소개하고 있으니 필요하신 분들은 참고하시기 바랍니다.

추천 학습: "SQL Tutorial"
OVER
OVER의 정의는 값 집합에서 작동하는 행에 대한 창을 정의하는 데 사용됩니다. GROUP BY 절을 사용할 필요가 없습니다. 데이터를 그룹화하여 동일한 행에 기본 행 열과 집계 열을 모두 반환하는 기능.
OVER 구문
OVER ( [ PARTITION BY 열 ] [ ORDER BY 열 ] )
PARTITION BY 절은 그룹화를 위한 절이고
ORDER BY 절은 정렬을 위한 절입니다.
윈도우 함수 OVER()는 행 집합을 지정하고, 윈도우 함수는 윈도우 함수에서 출력된 결과 집합의 각 행 값을 계산합니다.
윈도잉 함수는 GROUP BY를 사용하지 않고 데이터를 그룹화할 수 있으며, 기본 행과 집계 열의 열을 동시에 반환할 수도 있습니다.
OVER
OVER 윈도잉 함수 사용법은 집계 함수나 정렬 함수와 함께 사용해야 합니다. 집계 함수는 일반적으로 SUM(), MAX(), MIN, COUNT(), AVG() 등과 같은 일반적인 함수를 의미합니다. . 정렬 함수는 일반적으로 RANK(), ROW_NUMBER(), DENSE_RANK(), NTILE() 등을 참조합니다.
집계 함수에서 OVER를 사용하는 예
SUM 및 COUNT 함수를 예시로 사용합니다.
--建立测试表和测试数据
CREATE TABLE Employee
(
ID INT PRIMARY KEY,
Name VARCHAR(20),
GroupName VARCHAR(20),
Salary INT
)
INSERT INTO Employee
VALUES(1,'小明','开发部',8000),
(4,'小张','开发部',7600),
(5,'小白','开发部',7000),
(8,'小王','财务部',5000),
(9, null,'财务部',NULL),
(15,'小刘','财务部',6000),
(16,'小高','行政部',4500),
(18,'小王','行政部',4000),
(23,'小李','行政部',4500),
(29,'小吴','行政部',4700);SUM 이후의 윈도우 함수
SELECT *,
SUM(Salary) OVER(PARTITION BY Groupname) 每个组的总工资,
SUM(Salary) OVER(PARTITION BY groupname ORDER BY ID) 每个组的累计总工资,
SUM(Salary) OVER(ORDER BY ID) 累计工资,
SUM(Salary) OVER() 总工资
from Employee(팁: 코드를 좌우로 슬라이드할 수 있습니다)
결과는 다음과 같습니다.
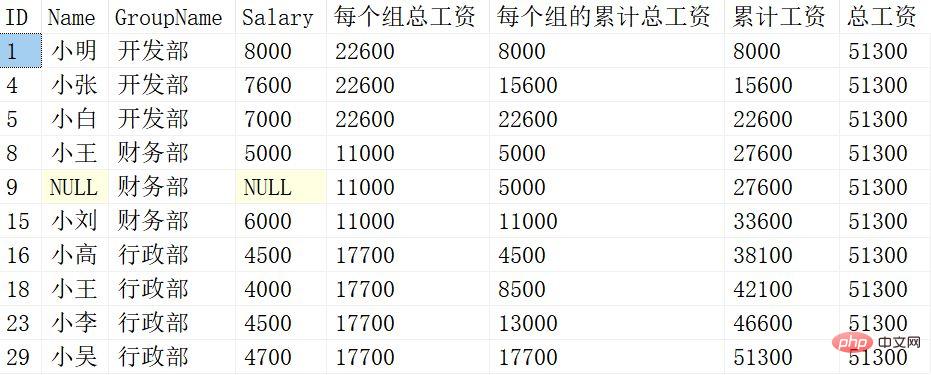
윈도잉 함수마다 의미가 다르기 때문에 자세히 설명하겠습니다. :
SUM (Salary) OVER (PARTITION BY Groupname)
PARTITION BY 다음에 Groupname 열만 그룹화하고, 그룹화한 후 Salary의 합을 구합니다.
SUM(Salary) OVER (PARTITION BY Groupname ORDER BY ID)
PARTITION BY 다음에 Groupname 컬럼을 그룹화하고 ORDER BY 다음에 ID별로 정렬한 후 그룹 내에서 Salary를 누적 처리합니다.
SUM(Salary) OVER (ORDER BY ID)
ORDER BY 이후 ID 내용만 정렬하여 정렬된 Salary를 누적합니다.
SUM(Salary) OVER ()
Salary를 요약한 후의 윈도잉 함수
COUNT
SELECT *,
COUNT(*) OVER(PARTITION BY Groupname ) 每个组的个数,
COUNT(*) OVER(PARTITION BY Groupname ORDER BY ID) 每个组的累积个数,
COUNT(*) OVER(ORDER BY ID) 累积个数 ,
COUNT(*) OVER() 总个数
from Employee반환된 결과는 다음과 같습니다.
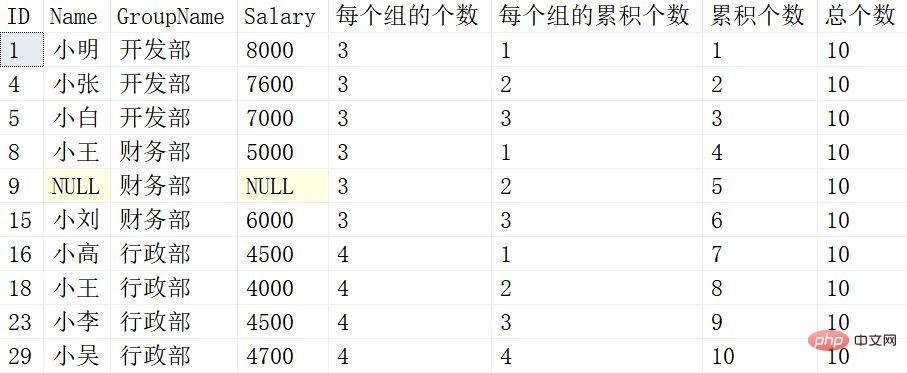
이후의 윈도잉 함수는 더 이상 위의 SUM 다음에 윈도잉 함수를 사용하여 하나씩 비교할 수 있습니다.
정렬 함수에서 OVER를 사용하는 예
네 가지 정렬 함수를 하나씩 보여줍니다
--先建立测试表和测试数据 WITH t AS (SELECT 1 StuID,'一班' ClassName,70 Score UNION ALL SELECT 2,'一班',85 UNION ALL SELECT 3,'一班',85 UNION ALL SELECT 4,'二班',80 UNION ALL SELECT 5,'二班',74 UNION ALL SELECT 6,'二班',80 ) SELECT * INTO Scores FROM t; SELECT * FROM Scores
ROW_NUMBER()
Definition: ROW_NUMBER() 함수의 기능은 SELECT로 쿼리한 데이터를 정렬하는 것입니다. 데이터 조각에 대한 일련 번호는 학생의 점수를 매기는 데 사용할 수 없습니다. 이는 일반적으로 상위 10명 쿼리 및 10~100명의 학생 쿼리와 같은 페이징 쿼리에 사용됩니다. ROW_NUMBER()는 ORDER BY와 함께 사용해야 하며, 그렇지 않으면 오류가 보고됩니다.
학생 점수 정렬
SELECT *, ROW_NUMBER() OVER (PARTITION BY ClassName ORDER BY SCORE DESC) 班内排序, ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS 总排序 FROM Scores;
결과는 다음과 같습니다.
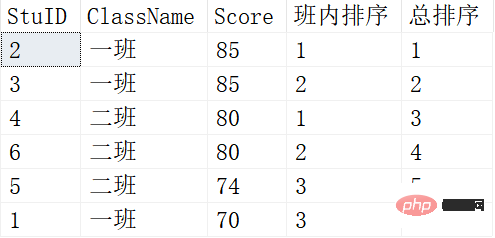
여기서 PARTITION BY 및 ORDER BY의 기능은 위에서 본 집계 기능과 동일하며 그룹화 및 정렬에 사용됩니다.
또한 ROW_NUMBER() 함수는 지정된 순서로 데이터를 가져올 수도 있습니다.
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS 总排序 FROM Scores ) t WHERE t.总排序=2;
결과는 다음과 같습니다.

RANK()
정의: RANK() 함수는 이름에서 알 수 있듯이 특정 필드의 순위를 지정할 수 있는 순위 함수입니다. ROW_NUMBER()? ROW_NUMBER()는 같은 성적을 가진 학생이 있을 경우 순서대로 정렬합니다. 일련번호는 다르지만 Rank()는 다릅니다. 동일하게 표시되면 순위가 동일합니다. 아래 예를 살펴보겠습니다.
Example
SELECT ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores; SELECT RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores;
Result:
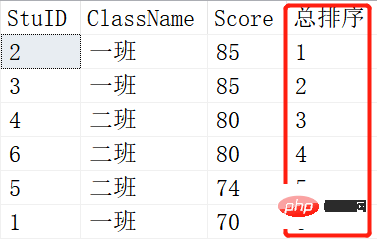
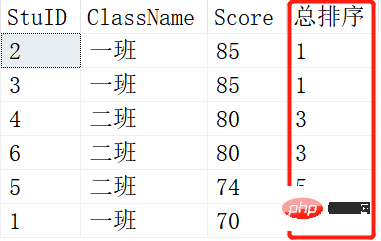
위 그림은 ROW_NUMBER()의 결과이고, 아래 그림은 RANK()의 결과입니다. 두 학생이 같은 성적을 받으면 변화가 있습니다. RANK()는 1-1-3-3-5-6인 반면 ROW_NUMBER()는 여전히 1-2-3-4-5-6입니다. 이것이 RANK()와 ROW_NUMBER()의 차이점입니다.
DENSE_RANK()
定义:DENSE_RANK()函数也是排名函数,和RANK()功能相似,也是对字段进行排名,那它和RANK()到底有什么不同那?特别是对于有成绩相同的情况,DENSE_RANK()排名是连续的,RANK()是跳跃的排名,一般情况下用的排名函数就是RANK() 我们看例子:
示例
SELECT RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores; SELECT DENSE_RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores;
结果如下:
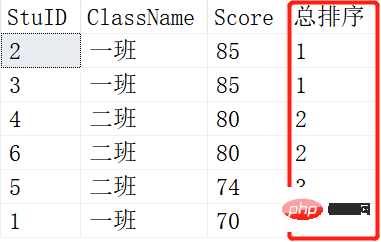
上面是RANK()的结果,下面是DENSE_RANK()的结果
NTILE()
定义:NTILE()函数是将有序分区中的行分发到指定数目的组中,各个组有编号,编号从1开始,就像我们说的'分区'一样 ,分为几个区,一个区会有多少个。
SELECT *,NTILE(1) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores; SELECT *,NTILE(2) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores; SELECT *,NTILE(3) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores;
结果如下:
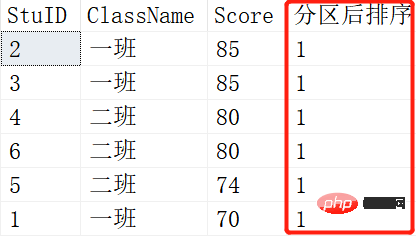
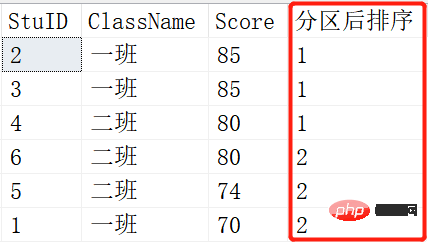
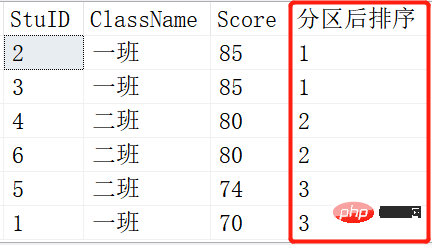
就是将查询出来的记录根据NTILE函数里的参数进行平分分区。
总结
OVER开窗函数是我们工作中经常要使用到的,特别是在做数据分析计算的时候,经常要对数据进行分组排序。上面我们额外介绍了聚合函数和排序函数的与OVER结合的使用方法,此外还有很多与OVER一起使用的函数,比如LEAD函数,LAG函数,STRING_AGG函数等等都会使用到开窗函数OVER,其使用方法也要务必掌握。
推荐学习:《SQL教程》
위 내용은 한 기사로 SQL의 창 기능 이해의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undress AI Tool
무료로 이미지를 벗다

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.


Stock Market GPT
더 현명한 결정을 위한 AI 기반 투자 연구

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

 열을 SQL의 여러 값과 비교하는 방법은 무엇입니까?
Sep 16, 2025 am 02:12 AM
열을 SQL의 여러 값과 비교하는 방법은 무엇입니까?
Sep 16, 2025 am 02:12 AM
IN 연산자를 사용하여 열을 선택*Fromployeeswheredepartment_idin (1,2,3)과 같은 여러 값과 효율적으로 비교하십시오. 여러 값이 제외되면 NOTIN을 사용하지만 결과에 영향을 미치는 NULL에주의하십시오.
 SQL에서 음성 검색에 Soundex 기능을 사용하는 방법은 무엇입니까?
Sep 21, 2025 am 01:54 AM
SQL에서 음성 검색에 Soundex 기능을 사용하는 방법은 무엇입니까?
Sep 21, 2025 am 01:54 AM
SoundEx 함수는 텍스트를 발음을 나타내는 4 자리 코드로 변환하고 첫 번째 문자에 3 자리를 추가하고 모음과 특정 문자를 무시하며, 유사한 발음을 가진 자음을 동일한 숫자로 맵핑하여 발음 기반 검색을 실현합니다. 예를 들어, Smith와 Smythe는 모두 S530을 생성하고 유사한 발음을 가진 이름은 Wheresoundex (last_name) = soundex ( 'Smith')를 통해 찾을 수 있습니다. 차이 함수와 결합하여 유사성 점수 0에서 4의 유사성 점수를 반환하고, 발음 닫기 결과를 필터링 할 수 있으며, 이는 철자 차이를 다루는 데 적합하지만 영어 이외의 이름에 영향을 미치며 성능 최적화에주의를 기울여야합니다.
 SQL의 테이블 또는 열에 주석을 추가하는 방법은 무엇입니까?
Sep 21, 2025 am 05:22 AM
SQL의 테이블 또는 열에 주석을 추가하는 방법은 무엇입니까?
Sep 21, 2025 am 05:22 AM
UseCommentOncolumnoraltertablewithCommentTodocumentTables 및 ColumnsInsql; syntaxvariesBydbms - postgresqlandoracleUsecommenton, mysqlusescommentincreate/alterstatements 및 andcommentscanbeviewedviasystemtablikedinformation_schema, rantsuppport.
 SQL의 서브 쿼리와 CTE의 차이점은 무엇입니까?
Sep 16, 2025 am 07:47 AM
SQL의 서브 쿼리와 CTE의 차이점은 무엇입니까?
Sep 16, 2025 am 07:47 AM
하위 쿼리는 다른 쿼리에 중첩 된 쿼리입니다. 그들은 간단한 일회성 계산에 적합하며, 선택,에서 또는 시점에 위치 할 수 있습니다. 2. CTE는 복잡한 쿼리의 가독성을 향상시키고 재귀 및 다중 참조를 지원하기 위해 조항으로 정의됩니다. 3. 하위 쿼리는 단일 사용에 적합하며 CTE는 명확한 구조, 재사용 또는 재귀가 필요한 시나리오에 더 적합합니다.
 SQL 테이블에서 고아 기록을 찾는 방법은 무엇입니까?
Sep 17, 2025 am 04:51 AM
SQL 테이블에서 고아 기록을 찾는 방법은 무엇입니까?
Sep 17, 2025 am 04:51 AM
tofindorphaneDrecords, usealeftjoinornoTexoTexistStoIndItifyHildRecordsWithOutmatchingParentRecords.forexample, selecto, formorderSoleftJoincustomerscono.customer_id = c.customer_idwherec.customer_idullesturnsorderdonon-allinternon-allernon-allernon-allernon-allernon-allistomer
 SQL 열에 고유 한 제약 조건을 추가하는 방법은 무엇입니까?
Sep 24, 2025 am 04:27 AM
SQL 열에 고유 한 제약 조건을 추가하는 방법은 무엇입니까?
Sep 24, 2025 am 04:27 AM
CreateTable을 사용할 때는 고유 한 키워드를 추가하거나 AltertableAddConstraint를 사용하여 기존 테이블에 제약 조건을 추가하여 열의 값이 고유하고 단일 열 또는 여러 열을 지원하십시오. 추가하기 전에 데이터가 복제되지 않도록해야합니다. DropConstraint를 통해 삭제하고 다른 데이터베이스와 NULL 값의 구문 차이에주의를 기울일 수 있습니다.
 SQL에서 비 equi 조인을 수행하는 방법은 무엇입니까?
Sep 16, 2025 am 07:37 AM
SQL에서 비 equi 조인을 수행하는 방법은 무엇입니까?
Sep 16, 2025 am 07:37 AM
anon-equijoinusescopisonoperators winder ween, or! =, 또는! = tomatchrowsbetweentables.2.plisuseFulforRangeComparisonSsuchassalaryordateranges.3.syntaxinvolvesspecifingConditionSintheonTheconconditionSinTheonConconconditionSinTheonConconConditionSinTheonforSalargrades.4
 SQL에서 주어진 날짜의 달의 마지막 날을 얻는 방법은 무엇입니까?
Sep 18, 2025 am 12:57 AM
SQL에서 주어진 날짜의 달의 마지막 날을 얻는 방법은 무엇입니까?
Sep 18, 2025 am 12:57 AM
마지막 _day () 함수 (MySQL, Oracle)를 사용하여 지정된 날짜가 마지막 날 ( '2023-10-15')와 같이 2023-10-31을 반환합니다. 2. SQLServer는 Eomonth () 함수를 사용하여 동일한 함수를 달성합니다. 3. PostgreSQL Date_trunc 및 간격을 통해 월말을 계산합니다. 4. sqlite는 날짜 함수를 사용하여 'startofmonth', '1month'및 '-1day'를 결합하여 결과를 얻습니다.
