

이 글에서는Python에 대한 관련 지식을 소개합니다. 주로 Python 크롤러가 웹 페이지 데이터를 크롤링하고 데이터를 구문 분석하여 크롤러를 사용하여 웹 페이지를 분석하는 데 도움이 되기를 바랍니다. 모두에게 도움이 됩니다.

【관련 추천:Python3 동영상 튜토리얼】
웹 크롤러(웹 스파이더, 로봇이라고도 함)는 클라이언트가 네트워크 요청을 보내고 요청 응답 수신 , 특정 규칙에 따라 인터넷 정보를 자동으로 캡처하는 프로그램입니다.
브라우저가 무엇이든 할 수 있다면 원칙적으로 크롤러도 할 수 있습니다.
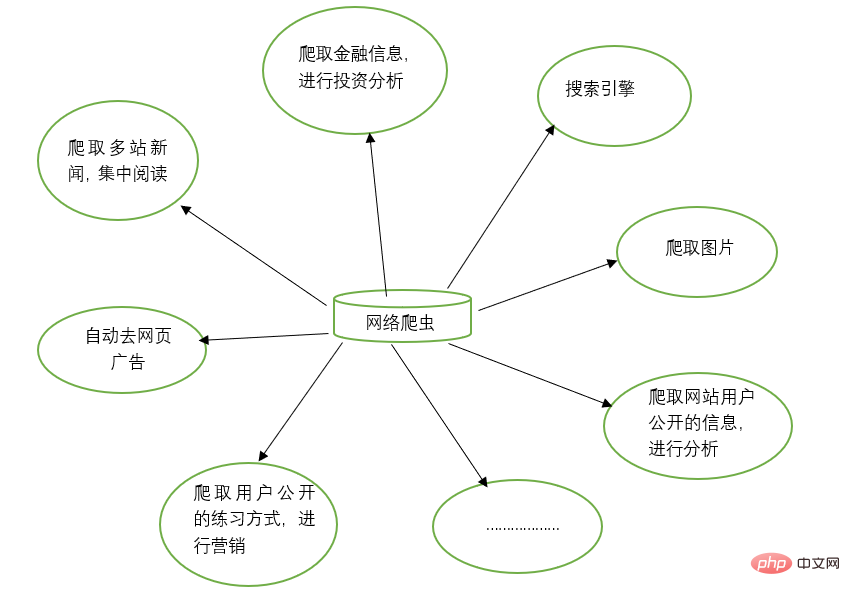
웹 크롤러는 검색 엔진, 웹사이트의 이미지 크롤링 등 많은 작업을 수행하는 수동 작업을 대체할 수 있습니다. 동시에 웹 크롤러는 금융 투자 분야에서도 사용할 수 있습니다. 예를 들어 일부 금융 정보를 자동으로 크롤링하고 투자 분석을 수행할 수 있습니다.
때때로 즐겨찾는 뉴스 웹사이트가 여러 개 있을 수 있으며, 탐색할 때마다 이러한 뉴스 웹사이트를 별도로 열어야 하는 것이 번거롭습니다. 이때 웹 크롤러를 이용하면 이러한 여러 뉴스 사이트의 뉴스 정보를 크롤링하여 함께 읽을 수 있습니다.
가끔 웹에서 정보를 검색하다 보면 광고가 많이 나올 때가 있습니다. 이때, 귀하는 크롤러를 이용하여 해당 웹페이지의 정보를 크롤링할 수 있으며, 이러한 광고를 자동으로 필터링하여 정보를 쉽게 읽고 이용할 수 있도록 할 수 있습니다.
때때로 마케팅을 해야 할 때도 있기 때문에 타겟 고객을 어떻게 찾고 연락처를 찾는지가 중요한 문제입니다. 인터넷에서 수동으로 검색할 수 있지만 이는 매우 비효율적입니다. 이때 당사는 크롤러를 사용하여 해당 규칙을 설정하고 마케팅 용도로 인터넷에서 대상 사용자의 연락처 정보 및 기타 데이터를 자동으로 수집할 수 있습니다.
웹사이트의 사용자 활동, 댓글 수, 인기 기사 및 기타 정보를 분석하는 등 특정 웹사이트의 사용자 정보를 분석하려는 경우가 있습니다. 웹사이트 관리자가 아닌 경우 수동 통계는 매우 어려울 수 있습니다. 거대한 프로젝트. 이때 크롤러를 사용하면 추가 분석을 위해 이러한 데이터를 쉽게 수집할 수 있습니다. 모든 크롤링 작업은 해당 크롤러를 작성하고 해당 규칙을 설계하기만 하면 됩니다.
또한 크롤러는 많은 강력한 기능을 수행할 수도 있습니다. 즉, 크롤러의 출현은 웹 페이지에 대한 수동 액세스를 어느 정도 대체할 수 있습니다. 따라서 이전에 인터넷 정보에 수동으로 액세스해야 했던 작업을 이제 크롤러를 사용하여 자동화할 수 있으며, 이는 인터넷에서 효과적인 정보를 보다 효율적으로 사용할 수 있습니다. .
데이터를 크롤링하고 구문 분석하기 전에 Python 실행 환경에서 타사 라이브러리 요청을 다운로드하고 설치해야 합니다.
Windows 시스템에서 cmd(명령 프롬프트) 인터페이스를 열고 인터페이스에 pip 설치 요청을 입력한 후 Enter를 눌러 설치하세요. (네트워크 연결에 주의하세요) 아래와 같이
그림과 같이 설치가 완료되었습니다.
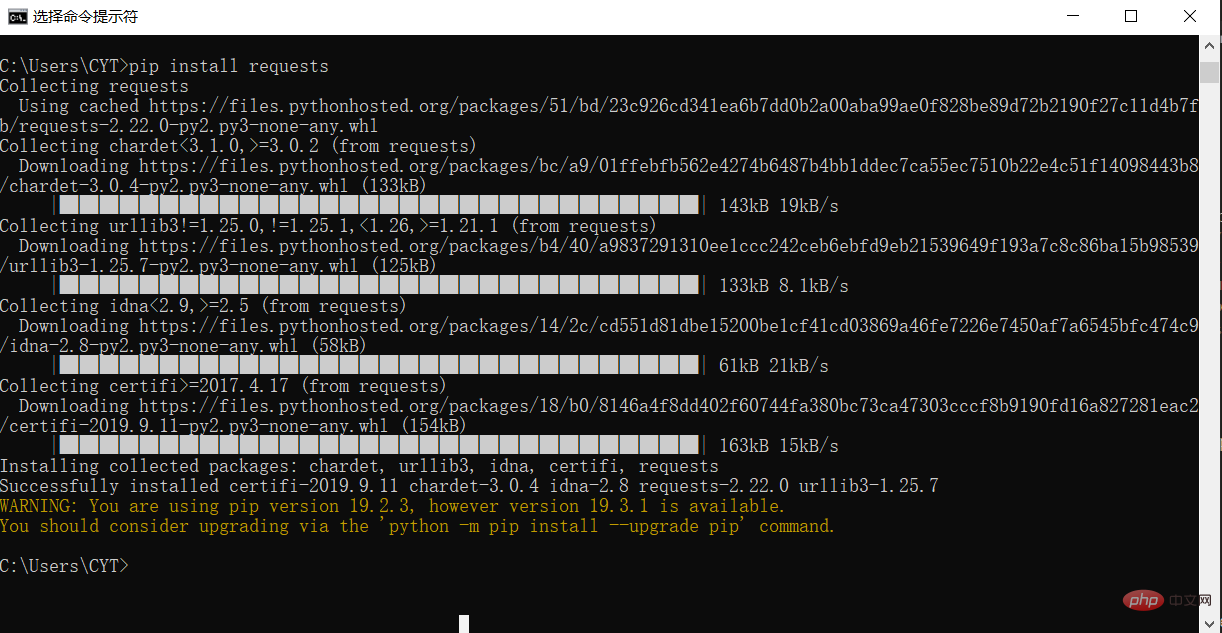
# 请求库 import requests # 用于解决爬取的数据格式化 import io import sys sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8') # 爬取的网页链接 r= requests.get("https://www.taobao.com/") # 类型 # print(type(r)) print(r.status_code) # 中文显示 # r.encoding='utf-8' r.encoding=None print(r.encoding) print(r.text) result = r.text
실행 결과는 다음과 같습니다. 그림
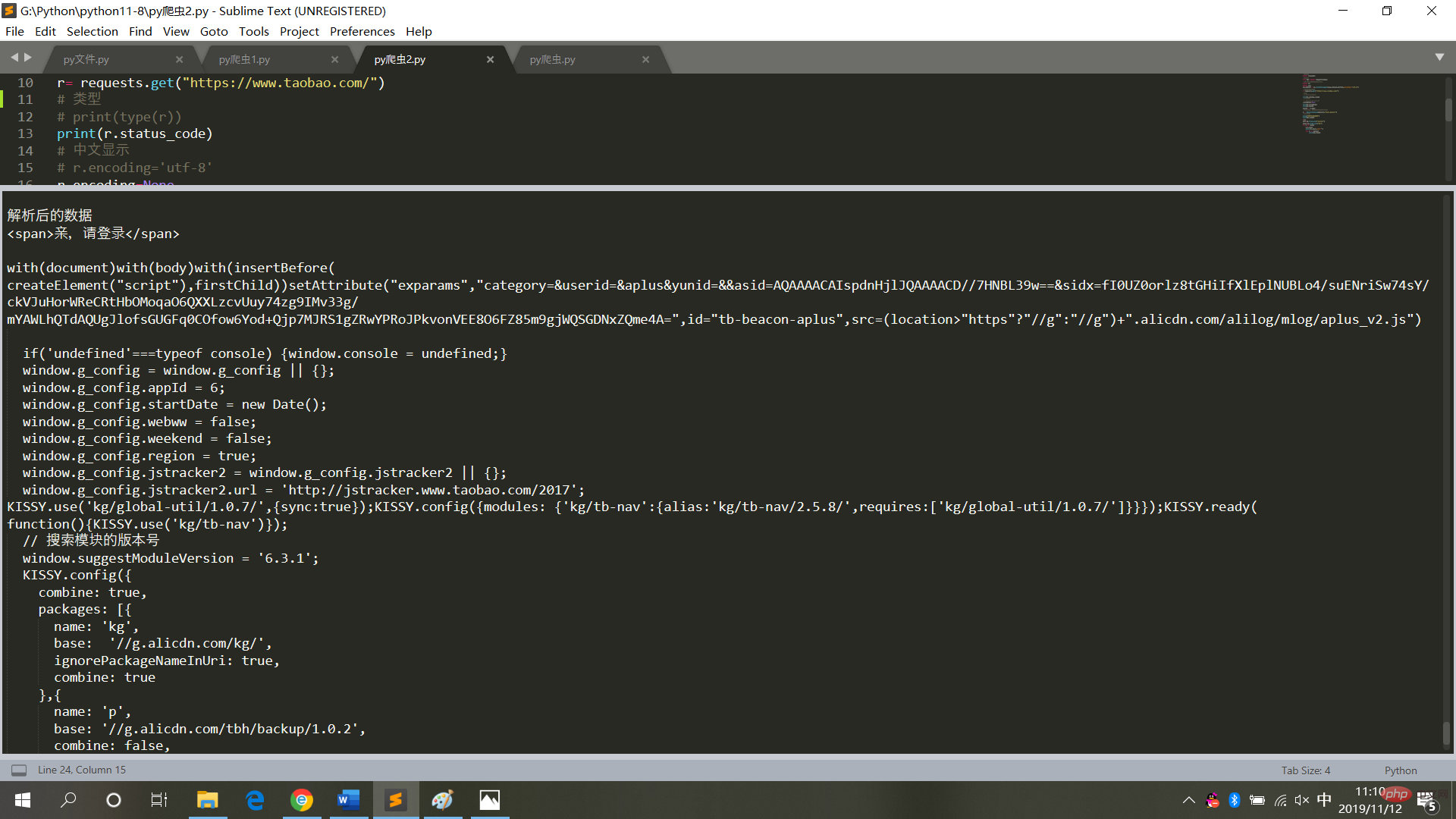
# 请求库 import requests # 解析库 from bs4 import BeautifulSoup # 用于解决爬取的数据格式化 import io import sys sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8') # 爬取的网页链接 r= requests.get("https://www.taobao.com/") # 类型 # print(type(r)) print(r.status_code) # 中文显示 # r.encoding='utf-8' r.encoding=None print(r.encoding) print(r.text) result = r.text # 再次封装,获取具体标签内的内容 bs = BeautifulSoup(result,'html.parser') # 具体标签 print("解析后的数据") print(bs.span) a={} # 获取已爬取内容中的script标签内容 data=bs.find_all('script') # 获取已爬取内容中的td标签内容 data1=bs.find_all('td') # 循环打印输出 for i in data: a=i.text print(i.text,end='') for j in data1: print(j.text)
실행 결과는 그림
Python3 비디오 튜토리얼
】위 내용은 Python 크롤러는 웹페이지 데이터를 크롤링하고 데이터를 구문 분석합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!































![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



