

이미지 파일은 일반적으로 코딩 중복성, 픽셀 간 중복성 및 심리 시각적 중복성을 사용하여 압축됩니다. 데이터 중복성은 디지털 이미지 압축의 주요 문제이며, 세 가지 기본 데이터 중복성, 즉 코딩 중복성, 픽셀 간 중복성 및 심리 시각적 중복성을 결정하고 활용할 수 있습니다. 주어진 양의 정보를 표현하는 데 필요한 데이터)는 그 중 하나 이상이 감소되거나 제거될 때 달성됩니다.

이 튜토리얼의 운영 환경: Windows 7 시스템, Dell G3 컴퓨터.
이미지 압축으로 해결되는 문제는 디지털 이미지를 표현하는 데 필요한 데이터 양을 최소화하는 것이며, 데이터 양을 줄이는 기본 원리는 과잉 데이터를 제거하는 것입니다.
이미지 압축 모델: 주로 신호 소스의 인코딩 및 디코딩을 소개하며 전송 프로세스의 신호 채널에 대해서는 논의하지 않습니다.

데이터 압축은 주어진 양의 정보를 표현하는 데 필요한 데이터의 양을 줄이는 것을 의미합니다.
Data는 정보 전송 수단입니다. 같은 양의 정보라도 다른 양의 데이터로 표현될 수 있습니다.
Information: 이미지 자체의 정보를 나타내는 데 사용됩니다.
데이터 중복은 디지털 이미지 압축의 주요 문제입니다. n1과 n2가 동일한 정보를 나타내는 두 데이터 세트에 포함된 정보 단위의 수를 나타내는 경우 첫 번째 데이터 세트(n1로 표시되는 세트)의 상대적 데이터 중복성 RD은 다음과 같이 정의할 수 있습니다.
여기서 C는 압축 비율이라고도 하며 다음과 같이 정의됩니다.
디지털 이미지 압축에서는 세 가지 기본 유형의 데이터 중복성, 즉 코딩 중복성, 픽셀 간 중복성, 심리적 비전 중복성을 식별하고 활용할 수 있습니다. 이러한 세 가지 중복 중 하나 이상이 줄어들거나 제거되면 데이터 압축이 달성됩니다.
이미지의 경우 이산 확률 변수가 이미지의 회색 수준을 나타내고 각 회색 수준(rk)이 나타날 확률은 pr이라고 가정할 수 있습니다.
여기서 L은 회색 레벨 수이고, nk은 k번째 회색 레벨이 이미지에 나타나는 횟수, n은 이미지의 총 픽셀 수입니다. 각 rk값을 나타내는 데 사용되는 비트 수가 l(rk)이면 각 픽셀을 표현하는 데 필요한 평균 비트 수는 다음과 같습니다.

즉, 각 회색조가 표시됩니다. 레벨 값에 사용된 비트 수에 계조 발생 확률을 곱하고 그 결과를 더하여 서로 다른 계조 값의 평균 코드워드 길이를 얻습니다. 특정 인코딩의 평균 비트 수가 엔트로피에 가까우면 인코딩 중복이 더 작아집니다.
【참고】
엔트로피: 단일 소스의 출력을 관찰하여 얻은 정보의 평균 양을 정의합니다.

예:
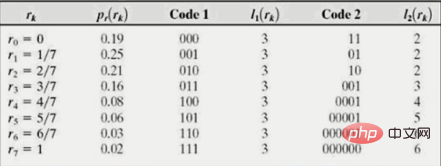
원본 이미지의 엔트로피는 2.588
자연 이진 인코딩을 사용하면 평균 길이는 3입니다.
표에서 인코딩 2를 사용하는 경우 평균 비트 수는 다음과 같습니다.

인코딩 압축을 달성하려면 두 함수 pr(rk) 및 l(rk) 역비를 곱합니다. 즉, 특정 계조 rk의 확률 pr(rk)이 클수록 코딩 길이 l(rk)은 작아져야 하며, 이는 평균 비트 수를 줄일 수 있습니다. 엔트로피에 가깝습니다. 아래와 같이

픽셀 간 중복성은 픽셀 간의 상관 관계와 직접적인 관련이 있는 일종의 데이터 중복성입니다.
정적 사진의 경우 공간 중복성(기하학적 중복성)이 있습니다. 이는 사진의 이미지에 대한 단일 픽셀의 시각적 기여가 중복되는 경우가 많기 때문이며 이는 회색조 값을 사용하여 확인할 수 있습니다. 인접한 픽셀을 추론합니다.
연속적인 사진이나 동영상의 경우 시간적 중복(프레임 간 중복)도 발생합니다. 인접한 사진 간의 해당 픽셀이 대부분 천천히 과도해집니다.

심리시각적 중복성은 실제 시각적 정보와 관련이 있습니다. 동일한 사진에 대해 사람마다 심리적 시각적 중복성이 다릅니다. 중복된 심리 시각적 데이터를 제거하면 필연적으로 정량적 정보의 손실이 발생하며 이러한 시각적 정보의 손실은 되돌릴 수 없는 작업입니다. 이미지(확대할 수 없음)가 상대적으로 작은 것처럼 인간의 눈은 해상도를 직접적으로 판단할 수 없습니다. 이미지의 데이터량을 압축하기 위해 인간의 눈으로 직접 볼 수 없는 일부 정보는 제거될 수 있습니다. 확대해도 제거되지 않습니다. 심리 시각적 중복이 있는 이미지는 심리 시각적 중복이 제거된 이미지와 크게 다릅니다.
그림 C는 인간 시각 시스템의 특성을 최대한 활용하는 양자화 프로세스가 이미지의 성능을 크게 향상시킬 수 있음을 보여줍니다. 이 양자화 프로세스의 압축 비율은 여전히 2:1에 불과하지만 추가적인 오버헤드가 추가됩니다. 잘못된 윤곽선을 줄이고 성가신 거친 질감을 줄이기 위해 이 결과를 생성하는 데 사용된 방법은 향상된 그레이 스케일(IGS) 양자화 방법입니다. 먼저, 현재 8비트 그레이 스케일 값과 4. 이전에 생성된 최하위 비트는 초기 값이 0인 합을 형성합니다. 현재 값의 최상위 4비트가 1111이면 여기에 0000을 추가합니다. 획득한 합계의 최상위 4비트 값을 인코딩된 픽셀 값으로 사용합니다.
정보 손실 정도를 표현할 수 있는 경우 함수가 초기 또는 입력 이미지와 먼저 압축된 후 압축이 풀린 출력 이미지의 함수인 경우 객관적인 충실도 기준을 기반으로 한다고 합니다.

위 내용은 이미지 파일을 압축하는 데 일반적으로 어떤 중복성이 사용됩니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


























![HarmonyOS 2.0 애플리케이션 개발 실습 [홍멍 시스템 APP 개발]](https://img.php.cn/upload/course/000/000/041/61c970d04644f402.jpg)

![PHP Composer 튜토리얼 [자신만의 PHP 개발 프레임워크 구축]](https://img.php.cn/upload/course/000/000/041/61e7b13f39314635.jpg)

![모방 Meituan APP의 실제 개발 [프론트엔드 프로그래머를 위한 필수 JavaScript 프로젝트]](https://img.php.cn/upload/course/000/000/068/6242bebc05ca9210.png)





![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



