

이 기사에서는python에 대한 관련 지식을 제공합니다. 여기서는 XML의 기본 개요, Python의 XML 파일 구문 분석, XML 파일 작성, XML 파일 업데이트 등을 포함하여 Python이 XML 파일을 작동하는 방법에 대한 관련 문제를 주로 소개합니다. 살펴보겠습니다. 아래 내용이 모든 분들께 도움이 되기를 바랍니다.

추천 학습:python 비디오 튜토리얼
XML(Extensible Markup Language): XML은 인터넷 데이터 전송을 위한 중요한 도구이며 프로그래밍 언어에 국한되지 않습니다. 인터넷 패스 데이터 캐리어. XML은 현재 구조화된 문서 정보를 처리하는 데 있어 매우 강력한 기술입니다. XML은 서버 간에 구조화된 데이터를 이동하는 데 도움이 되므로 개발자는 데이터 저장 및 전송을 보다 쉽게 제어할 수 있습니다.
Xml은 전자 문서를 구조화하기 위해 표시하는 데 사용되는 마크업 언어입니다. 데이터를 표시하고 데이터 유형을 정의하는 데 사용할 수 있습니다. 사용자가 자신의 마크업 언어를 정의할 수 있는 소스 언어입니다. Xml은 SGML(Standard Generalized Markup Language)의 하위 집합이며 웹 전송에 매우 적합합니다. XML은 응용 프로그램이나 공급업체에 관계없이 구조화된 데이터를 설명하고 교환하는 통합된 방법을 제공합니다.
Features:
Function:
애플리케이션 및 웹사이트 구성
데이터 상호작용
Ajax 초석.
HTML과 유사하게 XML은 태그 마크업 언어로 데이터를 저장하는 또 다른 방법입니다. 이는 사람이 읽을 수 있고 확장 가능합니다. 즉, 자체 마크업을 자유롭게 정의할 수 있습니다. XML의 속성, 요소 및 태그는 HTML의 속성, 요소 및 태그와 유사합니다. XML 파일에는 선언이 있을 수도 있고 선언이 없을 수도 있습니다. 그러나 선언이 있는 경우 XML 파일의 첫 번째 줄이어야 합니다. 예:
이 선언문은 버전, 인코딩, 독립성의 세 부분으로 구성됩니다. Version은 사용 중인 XML 표준의 버전을 지정하고, Encoding은 이 파일에 사용된 문자 인코딩 유형을 나타내며, Standalone은 XML 파일의 내용을 해석하기 위해 외부 정보를 원하는지 여부를 파서에게 알려줍니다.
XML 파일은 다음과 같이 표현할 수 있습니다. XML 트리. 이 XML 트리는 루트 요소(상위 요소)에서 시작됩니다. 이 루트 요소는 하위 요소로 추가로 분기됩니다. XML 파일의 각 요소는 XML 트리의 노드입니다. 자식 노드가 없는 요소는 리프 노드입니다. 다음 그림은 원본 XML 파일과 XML 파일의 트리 표현을 명확하게 구분합니다.


새1.xml파일 만들기:
202200110 小白 202200220 小红 202200330 小黑
ElementTree 모듈에서 제공 가벼운 Python API와 효율적인 C 언어 구현, 즉 xml.etree.cElementTree가 있습니다. DOM에 비해 ET는 더 빠르고 API는 더 직접적이고 사용하기 편리합니다. SAX와 비교하여 ET.iterparse 기능은 주문형 구문 분석 기능도 제공하며 전체 문서를 한 번에 메모리로 읽어오지 않습니다. ET의 성능은 SAX 모듈의 성능과 거의 비슷하지만 API가 더 높은 수준이고 사용자가 사용하기 더 편리합니다.
요소 객체 메서드:
| Class method | Description |
|---|---|
Element.iter(tag=None)Element.iter(tag=None) |
遍历该Element所有后代,也可以指定tag进行遍历寻找。 |
Element.iterfind(path, namespaces=None) |
根据tag或path查找所有的后代。 |
Element.itertext() |
遍历所有后代并返回text值。 |
Element.findall(path) |
查找当前元素下tag或path能够匹配的直系节点 |
Element.findtext(path, default=None, namespaces=None) |
寻找第一个匹配子元素,返回其text值。匹配对象可以为tag或path。 |
Element.find(path) |
查找当前元素下tag或path能够匹配的首个直系节点。 |
Element.text |
获取当前元素的text值。 |
Element.get(key, default=None) |
获取元素指定key对应的属性值,如果没有该属性,则返回default值。 |
Element.keys() |
返回元素属性名称列表 |
Element.items() |
返回(name,value)列表 |
Element.getchildren() |
|
Element.getiterator(tag=None) |
|
Element.getiterator(self, tag=None) |
属性方法:
Element.iterfind(path, 네임스페이스=None)
| 方法名 | 说明 |
|---|---|
Element.tag |
节点名(tag)(str) |
Element.attrib |
属性(attributes)(dict) |
Element.text |
文本(text)(str) |
Element.tail |
附加文本(tail) (str) |
Element[:] | Element의 모든 자손을 탐색하거나, 탐색 및 검색할 태그를 지정할 수 있습니다.
Element.itertext()모든 하위 항목을 반복하고 텍스트 값을 반환합니다.
Element.findall(path)현재 요소 아래의 태그 또는 경로와 일치할 수 있는 직접 노드를 찾습니다.
Element.findtext(path, default=None, 네임스페이스 = 없음)첫 번째로 일치하는 하위 요소를 찾아 해당 텍스트 값을 반환합니다. 일치하는 개체는 태그 또는 경로일 수 있습니다.
Element.find(path)현재 요소 아래의 태그 또는 경로가 일치할 수 있는 첫 번째 직접 노드를 찾습니다.
Element.text현재 요소의 텍스트 값을 가져옵니다.
Element.get(key, default=None)요소의 지정된 키에 해당하는 속성 값을 가져옵니다. 해당 속성이 없으면 기본값이 반환됩니다.
Element.keys()요소 속성 이름 목록을 반환합니다.
Element.items()(이름, 값)
Element.getchildren()
Element.getiterator(tag=None)
속성 메서드:
메서드 이름 DescriptionElement.tag노드 이름(태그) (str)
Element.attrib속성( dict) )
Element.texttext (str)
Element.tail추가 텍스트(tail)(str)
요소[:]하위 노드 목록(목록)
1)接下来,我们加载这个文档,并进行解析:
>>> import xml.etree.ElementTree as ET>>> tree = ET.ElementTree(file='1.xml')
2) 然后,我们获取根元素(root element):
>>> tree.getroot()
3)根元素(root)是一个Element对象。我们看看根元素都有哪些属性:
>>> root = tree.getroot()>>> root.tag, root.attrib('collection', {'shelf': 'New Arrivals'})
4)根元素也具备遍历其直接子元素的接口:
>>> for child_of_root in root:... print(child_of_root.tag, child_of_root.attrib)...class {'className': '1班'}class {'className': '2班'}class {'className': '3班'}
5)通过索引值来访问特定的子元素:
>>> root[0].tag, root[0].text('class', '\n\t ')
6) 查找需要的元素
从上面的示例中,可以明显发现我们能够通过简单的递归方法(对每一个元素,递归式访问其所有子元素)获取树中的所有元素。但是,由于这是十分常见的工作,ET提供了一些简便的实现方法。
Element对象有一个iter方法,可以对某个元素对象之下所有的子元素进行深度优先遍历(DFS)。ElementTree对象同样也有这个方法。下面是查找XML文档中所有元素的最简单方法:
>>> for elem in tree.iter():... print(elem.tag, elem.attrib)...collection {'shelf': 'New Arrivals'}class {'className': '1班'}code {}number {}teacher {}class {'className': '2班'}code {}number {}teacher {}class {'className': '3班'}code {}number {}teacher {}
7)对树进行任意遍历——遍历所有元素,iter方法可以接受tag名称,然后遍历所有具备所提供tag的元素:
>>> for elem in tree.iter(tag='teacher'):... print(elem.tag, elem.text)...teacher 小白 teacher 小红 teacher 小黑
8)支持通过XPath查找元素
>>> for elem in tree.iterfind('class/teacher'):... print(elem.tag, elem.text)...teacher 小白 teacher 小红 teacher 小黑
9)查找所有具备某个name属性的className元素:
>>> for elem in tree.iterfind('class[@className="1班"]'):... print(elem.tag, elem.attrib)...class {'className': '1班'}
10)完整解析代码
import xml.etree.ElementTree as ET tree = ET.ElementTree(file='1.xml')print(type(tree))root = tree.getroot() # root是根元素print(type(root))print(root.tag)for index, child in enumerate(root): print("第%s个%s元素,属性:%s" % (index, child.tag, child.attrib)) for i, child_child in enumerate(child): print("标签:%s,内容:%s" % (child_child.tag, child_child.text))
输出结果:
collection 第0个class元素,属性:{'className': '1班'}标签:code,内容:2022001标签:number,内容:10标签:teacher,内容:小白 第1个class元素,属性:{'className': '2班'}标签:code,内容:2022002标签:number,内容:20标签:teacher,内容:小红 第2个class元素,属性:{'className': '3班'}标签:code,内容:2022003标签:number,内容:30标签:teacher,内容:小黑
DOM (Document Object Model)将XML文档作为一棵树状结构进行分析,获取节点的内容以及相关属性,或是新增、删除和修改节点的内容。XML解析器在加载XML文件以后,DQM模式将XML文件的元素视为一个树状结构的节点,一次性读入内存。
解析代码:
from xml.dom.minidom import parse# 读取文件dom = parse('1.xml')# 获取文档元素对象elem = dom.documentElement# 获取 classclass_list_obj = elem.getElementsByTagName('class')print(class_list_obj)print(type(class_list_obj))for class_element in class_list_obj: # 获取标签中内容 code = class_element.getElementsByTagName('code')[0].childNodes[0].nodeValue number = class_element.getElementsByTagName('number')[0].childNodes[0].nodeValue teacher = class_element.getElementsByTagName('teacher')[0].childNodes[0].nodeValue print('code:', code, ', number:', number, ', teacher:', teacher)
输出结果:
[, , ] code: 2022001 , number: 10 , teacher: 小白 code: 2022002 , number: 20 , teacher: 小红 code: 2022003 , number: 30 , teacher: 小黑
doc.writexml():生成xml文档,将创建的存在于内存中的xml文档写入本地硬盘中,这时才能看到新建的xml文档
语法格式:writexml(file,indent=’’,addindent=’’,newl=’’,endocing=None)
参数说明:
file:要保存为的文件对象名indent:根节点的缩进方式allindent:子节点的缩进方式newl:针对新行,指明换行方式encoding:保存文件的编码方式案例代码:
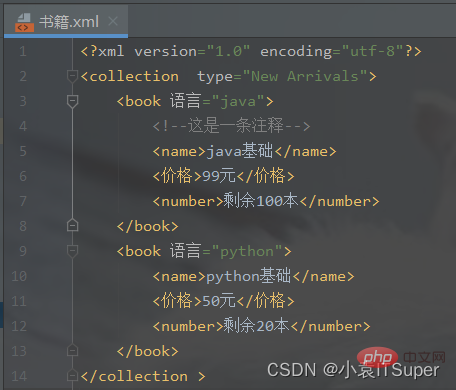
import xml.dom.minidom # 1、在内存中创建一个空的文档doc = xml.dom.minidom.Document() # 2、创建根元素root = doc.createElement('collection ')# print('添加的xml标签为:',root.tagName) # 3、设置根元素的属性root.setAttribute('type', 'New Arrivals') # 4、将根节点添加到文档对象中doc.appendChild(root) # 5、创建子元素book = doc.createElement('book') # 6、添加注释book.appendChild(doc.createComment('这是一条注释')) # 7、设置子元素的属性book.setAttribute('语言', 'java') # 8、子元素中嵌套子元素,并添加文本节点name = doc.createElement('name')name.appendChild(doc.createTextNode('java基础'))price = doc.createElement('价格')price.appendChild(doc.createTextNode('99元'))number = doc.createElement('number')number.appendChild(doc.createTextNode('剩余100本'))# 9、将子元素添加到boot节点中book.appendChild(name)book.appendChild(price)book.appendChild(number)# 10、将book节点添加到root根元素中root.appendChild(book)# 创建子元素book = doc.createElement('book')# 设置子元素的属性book.setAttribute('语言', 'python')# 子元素中嵌套子元素,并添加文本节点name = doc.createElement('name')name.appendChild(doc.createTextNode('python基础'))price = doc.createElement('价格')price.appendChild(doc.createTextNode('50元'))number = doc.createElement('number')number.appendChild(doc.createTextNode('剩余20本'))# 将子元素添加到boot节点中book.appendChild(name)book.appendChild(price)book.appendChild(number)# 将book节点添加到root根元素中root.appendChild(book)print(root.toxml())fp = open('./书籍.xml', 'w', encoding='utf-8') # 需要指定utf-8的文件编码格式,不然notepad中显示十六进制doc.writexml(fp, indent='', addindent='\t', newl='\n', encoding='utf-8')fp.close()
生成书籍.xml文件:
向xml中插入新的子元素
案例代码:
import xml.dom.minidomfrom xml.dom.minidom import parse# 对book.xml新增一个子元素english,并删除math元素xml_file = './书籍.xml'# 拿到根节点domTree = parse(xml_file)rootNode = domTree.documentElement# rootNode.removeChild(rootNode.getElementsByTagName('book')[0])# print(rootNode.toxml())# 在内存中创建一个空的文档doc = xml.dom.minidom.Document()book = doc.createElement('book')book.setAttribute('语言', 'c++')# 子元素中嵌套子元素,并添加文本节点name = doc.createElement('name')name.appendChild(doc.createTextNode('c++基础'))price = doc.createElement('价格')price.appendChild(doc.createTextNode('200元'))number = doc.createElement('number')number.appendChild(doc.createTextNode('剩余300本'))# 将子元素添加到boot节点中book.appendChild(name)book.appendChild(price)book.appendChild(number)math_book = rootNode.getElementsByTagName('book')[0]# insertBefore方法 父节点.insertBefore(新节点,父节点中的子节点)rootNode.insertBefore(book, math_book)# appendChild将新产生的子元素在最后插入rootNode.appendChild(book)print(rootNode.toxml())with open(xml_file, 'w', encoding='utf-8') as fh: domTree.writexml(fh, indent='', addindent='\t', newl='', encoding='utf-8')
输出结果:添加了新节点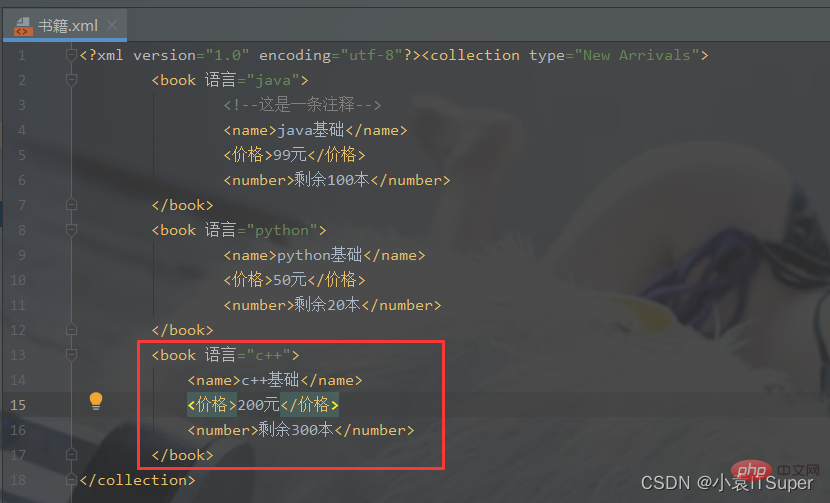
记录工作中常用的一个小技巧
cmd控制台安装第三方模块:
pip install xmltodict
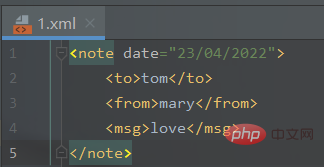
新建一个1.xml文件:
tom mary love
转换代码实现:
import jsonimport xmltodictdef xml_to_json(xml_str): """parse是的xml解析器,参数需要 :param xml_str: xml字符串 :return: json字符串 """ xml_parse = xmltodict.parse(xml_str) # json库dumps()是将dict转化成json格式,loads()是将json转化成dict格式。 # dumps()方法的ident=1,格式化json json_str = json.dumps(xml_parse, indent=1) return json_str XML_PATH = './1.xml' # xml文件的路径with open(XML_PATH, 'r') as f: xmlfile = f.read() with open(XML_PATH[:-3] + 'json', 'w') as newfile: newfile.write(xml_to_json(xmlfile))
输出结果(生成json文件):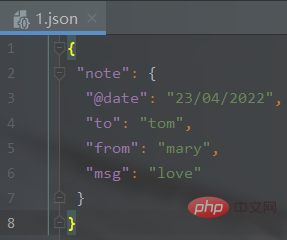
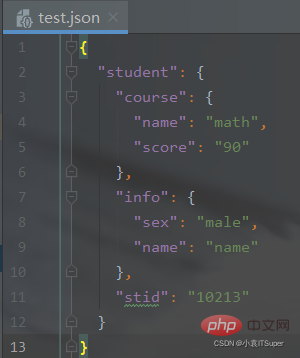
新建test.json文件:
{ "student": { "course": { "name": "math", "score": "90" }, "info": { "sex": "male", "name": "name" }, "stid": "10213" }}
转换代码实现:
import xmltodictimport jsondef json_to_xml(python_dict): """xmltodict库的unparse()json转xml :param python_dict: python的字典对象 :return: xml字符串 """ xml_str = xmltodict.unparse(python_dict) return xml_str JSON_PATH = './test.json' # json文件的路径with open(JSON_PATH, 'r') as f: jsonfile = f.read() python_dict = json.loads(jsonfile) # 将json字符串转换为python字典对象 with open(JSON_PATH[:-4] + 'xml', 'w') as newfile: newfile.write(json_to_xml(python_dict))
输出结果(生成xml文件):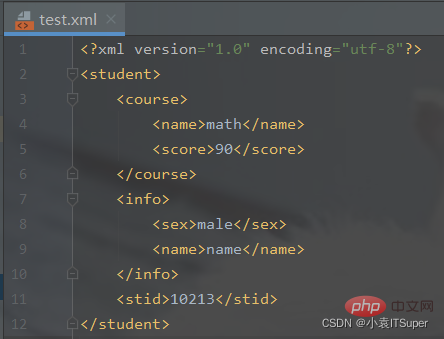
推荐学习:python视频教程
위 내용은 Python이 XML 파일을 작동하는 방법을 분석해 보겠습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!































![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



