

이 글은 python에 대한 관련 지식을 제공합니다. 주로 숫자, 문자열, 목록, 튜플, 사전 등을 포함한 데이터 구조와 관련된 문제를 소개합니다. 모든 사람에게 도움이 되기를 바랍니다.

추천 학습: python 비디오 튜토리얼
정수 유형(int) - 일반적으로 정수 또는 정수라고 하며 소수점이 없는 양수 또는 음수 정수입니다. Python3 정수에는 크기 제한이 없으며 Long 유형으로 사용할 수 있습니다. 부울은 정수의 하위 유형입니다.
부동 소수점 유형(float) - 부동 소수점 유형은 정수부와 소수부로 구성됩니다. 부동 소수점 유형은 과학 표기법(2.5e2 = 2.5 x 102 = 250)을 사용하여 표현할 수도 있습니다.
복수( ( 복소수 )) - 복소수는 실수부와 허수부로 구성되며, 이는 a + bj 또는 복소수(a,b)로 표현될 수 있습니다. 복소수의 실수부 a와 허수부 b는 모두 부동입니다. 포인트 유형.
int(x) x를 정수로 변환합니다.
float(x) x를 부동 소수점 숫자로 변환합니다.
complex(x) x를 복소수로 변환합니다. 실수 부분은 x이고 허수 부분은 0입니다.
complex(x, y) x와 y를 실수 부분이 x이고 허수 부분이 y인 복소수로 변환합니다. x와 y는 숫자 표현식입니다.
# + - * / %(取余) **(幂运算) # 整数除法中,除法 / 总是返回一个浮点数, # 如果只想得到整数的结果,丢弃可能的分数部分,可以使用运算符 // print(8 / 5) # 1.6 print(8 // 5) # 1 # 注意:// 得到的并不一定是整数类型的数,它与分母分子的数据类型有关系 print(8 // 5.0) # 1.0 # 使用 ** 操作来进行幂运算 print(5 ** 2) # 5的平方 25
index(): 하위 문자열 substr의 첫 번째 항목을 찾습니다. 검색된 하위 문자열이 없으면 ValueErrorrindex()Exception
rindex를 발생시킵니다. (): 하위 문자열 substr의 마지막 항목을 찾습니다. 검색 중인 하위 문자열이 없으면 ValueError() 예외가 발생합니다.
find(): 하위 문자열의 위치를 찾습니다. 검색 중인 하위 문자열이 존재하지 않으면 -1이 반환됩니다.
rfind(): 검색 중인 하위 문자열이 마지막으로 나타난 위치를 찾습니다.
s = 'hello, hello'
print(s.index('lo')) # 3
print(s.find('lo')) # 3
print(s.find('k')) # -1
print(s.rindex('lo')) # 10
print(s.rfind('lo')) # 10upper(): 문자열의 모든 문자를 대문자로 변환
lower(): 문자열의 모든 문자를 소문자로 변환
swapcase(): 문자열의 모든 대문자를 소문자로 변환하고 모든 소문자를 대문자로 변환
capitalize(): 첫 번째 문자를 대문자로 변환하고 나머지 문자를 소문자로 변환
title (): 각 단어의 첫 번째 문자를 대문자로 변환하고, 각 단어의 나머지 문자를 소문자로 변환합니다.
s = 'hello, Python' print(s.upper()) # HELLO, PYTHON print(s.lower()) # hello, python print(s.swapcase()) # HELLO, pYTHON print(s.capitalize()) # Hello, python print(s.title()) # Hello, Python
center(): 가운데 정렬, 첫 번째 매개변수는 너비를 지정하고, 두 번째 매개변수는 필러를 지정합니다. 기본값은 공백입니다. 설정된 너비가 실제 너비보다 작으면 원래 문자열이 반환됩니다.
ljust(): 왼쪽 정렬, 첫 번째 매개변수는 너비를 지정합니다. 두 번째 매개변수 매개변수는 필러를 지정하며, 기본값은 공백입니다. 설정된 너비가 실제 너비보다 작으면 원래 문자열이 반환됩니다.
rjust(): 오른쪽 정렬, 첫 번째 매개변수는 너비를 지정하고, 두 번째 매개변수는 필러를 지정하며 기본값은 공백입니다. 설정된 너비가 실제 너비보다 작으면 원래 문자열이 반환됩니다.
zfill(): 오른쪽 정렬되고 왼쪽이 0으로 채워집니다. 메서드는 문자열 너비를 지정하는 데 사용되는 하나의 매개 변수만 받습니다. 지정된 너비가 문자열 길이보다 작거나 같으면 문자열 자체를 반환합니다
s = 'hello,Python'
'''居中对齐'''
print(s.center(20, '*')) # ****hello,Python****
'''左对齐 '''
print(s.ljust(20, '*')) # hello,Python********
print(s.ljust(5, '*')) # hello,Python
'''右对齐'''
print(s.rjust(20, '*')) # ********hello,Python
'''右对齐,使用0进行填充'''
print(s.zfill(20)) # 00000000hello,Python
print('-1005'.zfill(8)) # -0001005Split
s = 'hello word Python'
print(s.split()) # ['hello', 'word', 'Python']
s1 = 'hello|word|Python'
print(s1.split(sep='|')) # ['hello', 'word', 'Python']
print(s1.split('|', 1)) # ['hello', 'word|Python'] # 左侧开始
print(s1.rsplit('|', 1)) # ['hello|word', 'Python'] # 右侧开始slicing
s = 'hello,world' print(s[:5]) # hello 从索引0开始,到4结束 print(s[6:]) # world 从索引6开始,到最后一个元素 print(s[1:5:1]) # ello 从索引1开始,到4结束,步长为1 print(s[::2]) # hlowrd 从开始到结束,步长为2 print(s[::-1]) # dlrow,olleh 步长为负数,从最后一个元素(索引-1)开始,到第一个元素结束 print(s[-6::1]) # ,world 从索引-6开始,到最后一个结束
문자열 교체
s = 'hello,Python,Python,Python'
print(s.replace('Python', 'Java')) # 默认全部替换 hello,Java,Java,Java
print(s.replace('Python', 'Java', 2)) # 设置替换个数 hello,Java,Java,Python문자열 연결
lst = ['hello', 'java', 'Python']
print(','.join(lst)) # hello,java,Python
print('|'.join(lst)) # hello|java|Pythonname = '张三'
age = 20
print('我叫%s, 今年%d岁' % (name, age))
print('我叫{0}, 今年{1}岁,小名也叫{0}'.format(name, age))
print(f'我叫{name}, 今年{age}岁')
# 我叫张三, 今年20岁
# 我叫张三, 今年20岁,小名也叫张三
# 我叫张三, 今年20岁에 변수 쓰기 숫자의 너비와 정밀도 설정
# 设置数字的宽度和精度
'''%占位'''
print('%10d' % 99) # 10表示宽度
print('%.3f' % 3.1415926) # .3f表示小数点后3位
print('%10.3f' % 3.1415926) # 同时设置宽度和精度
'''{}占位 需要使用:开始'''
print('{:.3}'.format(3.1415926)) # .3表示3位有效数字
print('{:.3f}'.format(3.1415926)) # .3f表示小数点后3位
print('{:10.3f}'.format(3.1415926)) # .3f表示小数点后3位
# 99
#3.142
# 3.142
#3.14
#3.142
# 3.142s = '但愿人长久' # 编码 将字符串转换成byte(二进制)数据 print(s.encode(encoding='gbk')) #gbk,中文占用2个字节 print(s.encode(encoding='utf-8')) #utf-8,中文占用3个字节 # 解码 将byte(二进制)转换成字符串数据 # 编码与解码中,encoding方式需要一致 byte = s.encode(encoding='gbk') print(byte.decode(encoding='gbk')) # b'\xb5\xab\xd4\xb8\xc8\xcb\xb3\xa4\xbe\xc3' # b'\xe4\xbd\x86\xe6\x84\xbf\xe4\xba\xba\xe9\x95\xbf\xe4\xb9\x85' # 但愿人长久
순서순
인덱스 매핑만 A 데이터
可以存储重复数据
任意数据类型混存
根据需要动态分配和回收内存
语法格式:[i*i for i in range(i, 10)]
解释:i表示自定义变量,i*i表示列表元素的表达式,range(i, 10)表示可迭代对象
print([i * i for i in range(1, 10)])# [1, 4, 9, 16, 25, 36, 49, 64, 81]
in / not in
for item in list: print(item)
list.index(item)
list = [1, 4, 9, 16, 25, 36, 49, 64, 81]print(list[3]) # 16print(list[3:6]) # [16, 25, 36]
append():在列表的末尾添加一个元素
extend():在列表的末尾至少添加一个元素
insert0:在列表的指定位置添加一个元素
切片:在列表的指定位置添加至少一个元素
rerove():一次删除一个元素,
重复元素只删除第一个,
元素不存在抛出ValceError异常
pop():删除一个指定索引位置上的元素,
指定索引不存在抛出IndexError异常,
不指定索引,删除列表中最后一个元素
切片:一次至少删除一个元素
clear0:清空列表
del:删除列表
list.sort()
sorted(list)
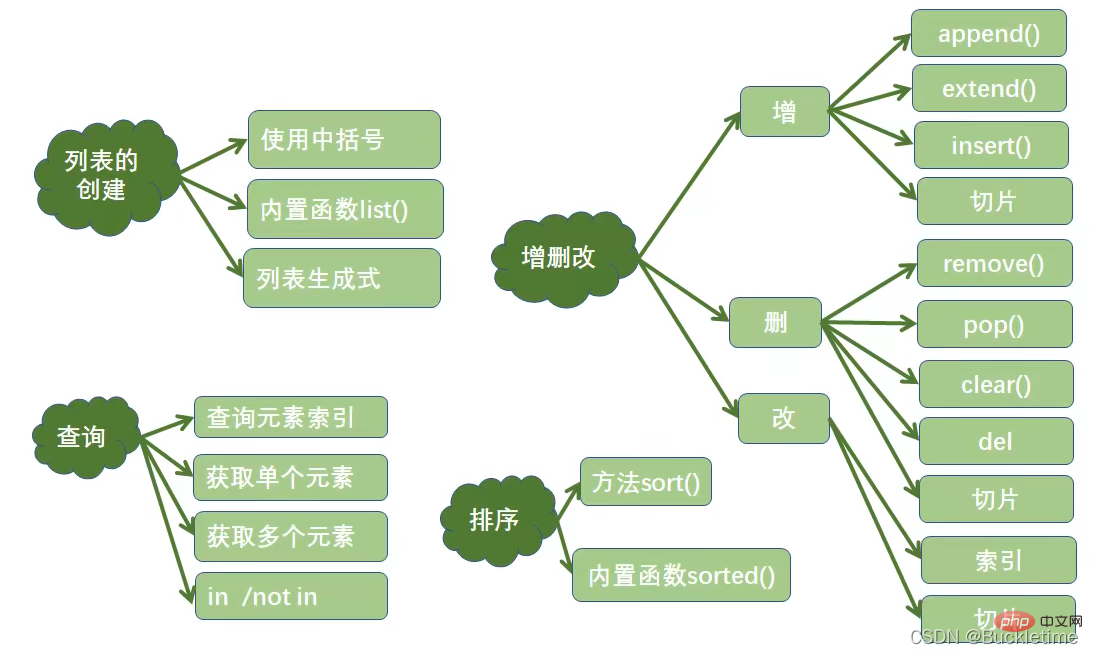
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号
t = ('Python', 'hello', 90)tuple(('Python', 'hello', 90))t = (10,)
items = ['fruits', 'Books', 'Others']
prices = [12, 36, 44]
d = {item.upper(): price for item, price in zip(items, prices)}
print(d) # {'FRUITS': 12, 'BOOKS': 36, 'OTHERS': 44}user = {"id": 1, "name": "zhangsan"}
user["age"] = 25
print(user) # {'id': 1, 'name': 'zhangsan', 'age': 25}user = {"id": 1, "name": "zhangsan", "age": 25}
user["age"] = 18
print(user) # {'id': 1, 'name': 'zhangsan', 'age': 18}user = {"id": 1, "name": "zhangsan"}del user["id"]print(user) # {'name': 'zhangsan'}del useruser = {"id": 1, "name": "zhangsan"}user.clear()print(user) # {}scores = {'张三': 100, '李四': 95, '王五': 88}for name in scores:
print(name, scores[name])scores = {'张三': 100, '李四': 95, '王五': 88}for name, score in scores.items():
print(name, score)
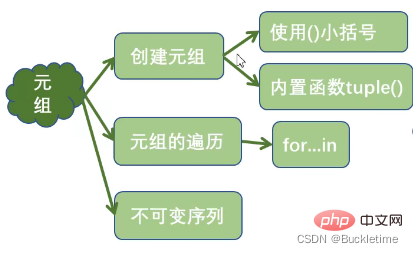
s = {'Python', 'hello', 90}print(set("Python"))print(set(range(1,6)))print(set([3, 4, 7]))print(set((3, 2, 0)))print(set({"a", "b", "c"}))# 定义空集合:set()print(set())print({i * i for i in range(1, 10)})# {64, 1, 4, 36, 9, 16, 49, 81, 25}两个集合是否相等:可以使用运算符 == 或 != 进行判断,只要元素相同就相等
一个集合是否是另一个集合的子集:issubset()
s1 = {10, 20, 30, 40, 50, 60}s2 = {10, 30, 40}s3 = {10, 70}print(s2.issubset(s1))
# Trueprint(s3.issubset(s1)) # Falseprint(s1.issuperset(s2)) # Trueprint(s1.issuperset(s3)) # False
s1 = {10, 20, 30, 40, 50, 60}s2 = {10, 30, 40}s3 = {20, 70}print(s1.isdisjoint(s2))
# False 有交集print(s3.isdisjoint(s2)) # True 无交集s1 = {10, 20, 30, 40}s2 = {20, 30, 40, 50, 60}print(s1.intersection(s2)) # {40, 20, 30}print(s1 & s2) # {40, 20, 30}print(s1.union(s2)) # {40, 10, 50, 20, 60, 30}print(s1 | s2) # {40, 10, 50, 20, 60, 30}print(s2.difference(s1)) # {50, 60}print(s2 - s1) # {50, 60}print(s2.symmetric_difference(s1)) # {10, 50, 60}print(s2 ^ s1) # {10, 50, 60}
推荐学习:python教程
위 내용은 Python3 데이터 구조 지식 포인트에 대한 자세한 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!




















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



