


이 기사는 페이지 디렉토리, 페이지 헤더 및 파일 헤더에 대한 관련 지식을 포함하여 mysql 원칙의 InnoDB 데이터 페이지에 대한 관련 지식을 제공합니다.

InnoDB에서 저장 공간을 관리하는 기본 단위입니다. 페이지 크기는 일반적으로 16KB입니다. InnoDB는 테이블스페이스 헤더 정보와 삽입 버퍼 정보를 저장하는 페이지 등 다양한 목적을 위해 다양한 유형의 페이지를 설계했습니다. INODE 정보를 저장하는 페이지, 실행 취소 로그 정보를 저장하는 페이지 등 물론 제가 언급한 용어를 하나도 들어보지 못하셨다면 제가 방귀를 뀌었다고 생각하시면 됩니다~ 하지만 오늘은 이런 종류의 페이지에 대해서는 이야기하지 않겠습니다. 테이블에 레코드를 저장하는 이러한 유형의 페이지를 공식적으로 인덱스(INDEX) 페이지라고 합니다. 인덱스가 무엇인지 아직 이해하지 못했기 때문에 이러한 테이블에서는 레코드를 라고 부릅니다. 데이터는 일상생활에 있어서 현재로서는 기록이 저장되어 있는 이 페이지를 데이터 페이지라고 부릅니다. InnoDB管理存储空间的基本单位,一个页的大小一般是16KB。InnoDB为了不同的目的而设计了许多种不同类型的页,比如存放表空间头部信息的页,存放Insert Buffer信息的页,存放INODE信息的页,存放undo日志信息的页等等等等。当然了,如果我说的这些名词你一个都没有听过,就当我放了个屁吧~ 不过这没有一毛钱关系,我们今儿个也不准备说这些类型的页,我们聚焦的是那些存放我们表中记录的那种类型的页,官方称这种存放记录的页为索引(INDEX)页,鉴于我们还没有了解过索引是个什么东西,而这些表中的记录就是我们日常口中所称的数据,所以目前还是叫这种存放记录的页为数据页吧。
数据页代表的这块16KB大小的存储空间可以被划分为多个部分,不同部分有不同的功能,各个部分如图所示:
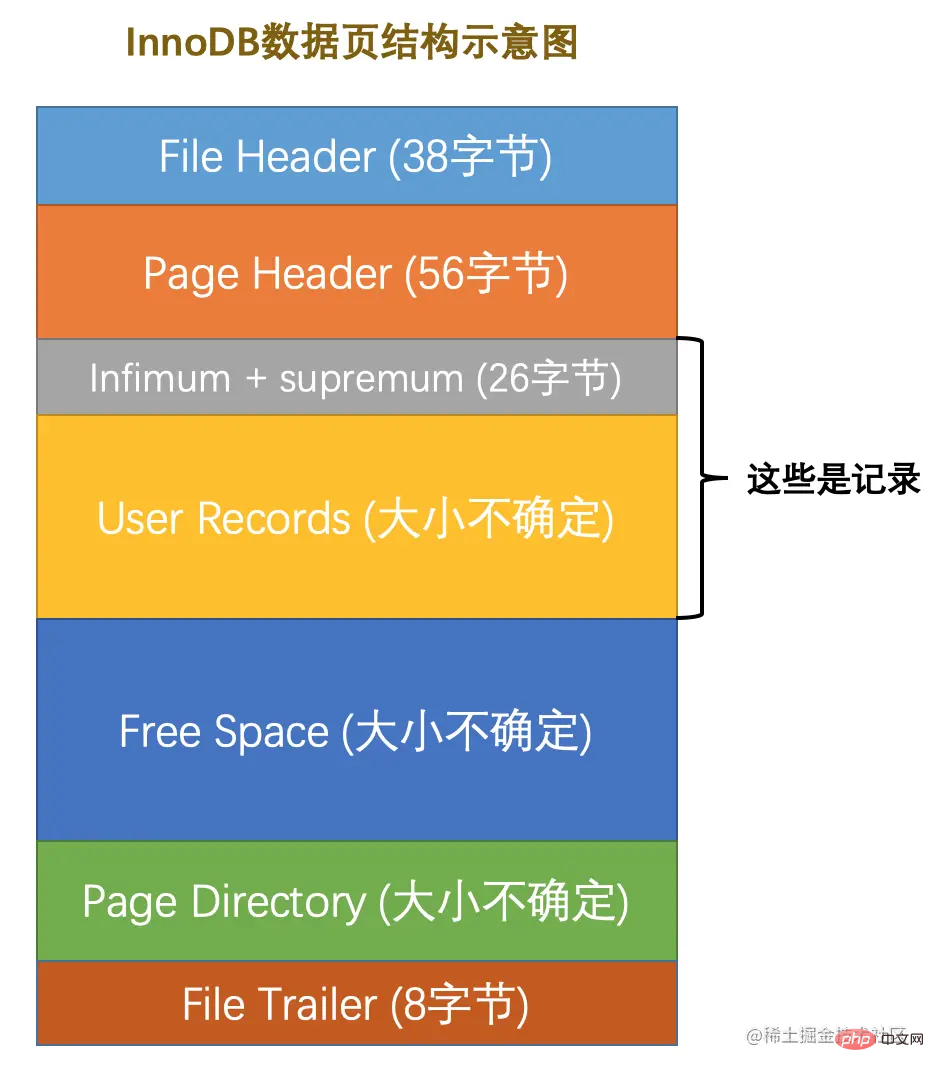
从图中可以看出,一个InnoDB数据页的存储空间大致被划分成了7个部分,有的部分占用的字节数是确定的,有的部分占用的字节数是不确定的。下边我们用表格的方式来大致描述一下这7个部分都存储一些啥内容(快速的瞅一眼就行了,后边会详细唠叨的):
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
File Header |
文件头部 |
38字节 |
页的一些通用信息 |
Page Header |
页面头部 |
56字节 |
数据页专有的一些信息 |
Infimum + Supremum |
最小记录和最大记录 |
26字节 |
两个虚拟的行记录 |
User Records |
用户记录 | 不确定 | 实际存储的行记录内容 |
Free Space |
空闲空间 | 不确定 | 页中尚未使用的空间 |
Page Directory |
页面目录 | 不确定 | 页中的某些记录的相对位置 |
File Trailer |
文件尾部 | 8 | 데이터 페이지 구조 간략히 살펴보기데이터 페이지가 나타내는 |
| 이름 | 중국어 이름 | 점유 공간 | 간단한 설명 | 🎜|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 名称 | 大小(单位:bit) | 描述 |
|---|---|---|
预留位1 |
1 |
没有使用 |
预留位2 |
1 |
没有使用 |
delete_mask |
1 |
标记该记录是否被删除 |
min_rec_mask |
1 |
B+树的每层非叶子节点中的最小记录都会添加该标记 |
n_owned |
4 |
表示当前记录拥有的记录数 |
heap_no |
13 |
表示当前记录在记录堆的位置信息 |
record_type |
3 |
表示当前记录的类型,0表示普通记录,1表示B+树非叶节点记录,2表示最小记录,3表示最大记录 |
next_record |
16
|
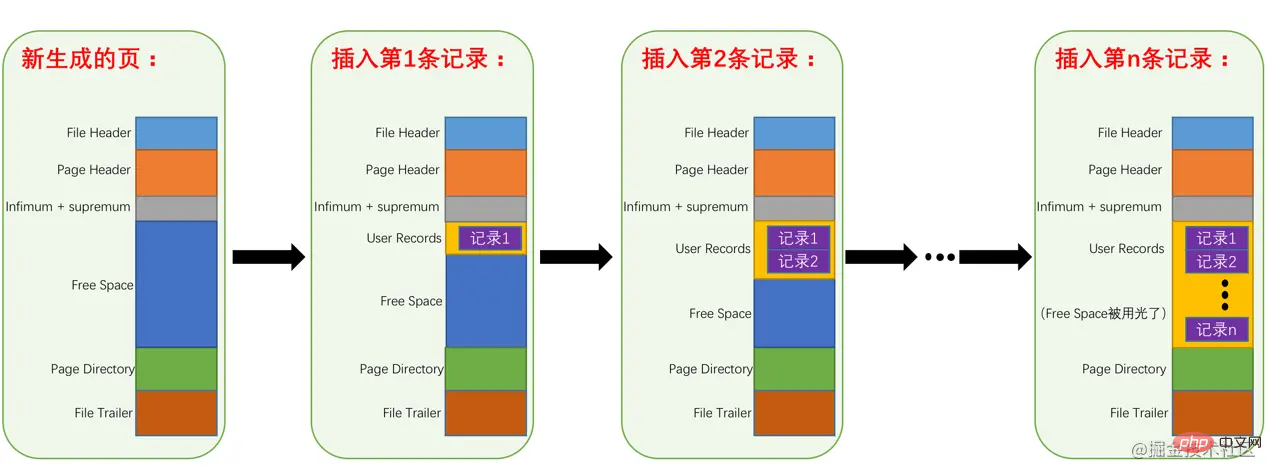
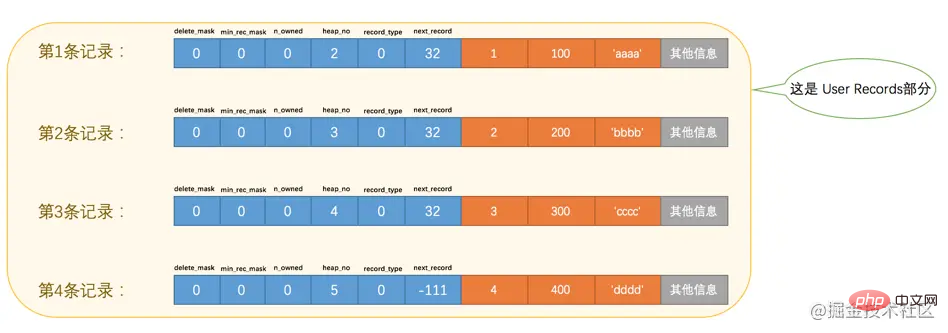
더 나은 관리를 위해InnoDB는 코드>사용자 기록에 있는 이러한 기록에 많은 노력을 기울였습니다. 그냥 사용자 레코드 섹션에 지정된 행 형식에 따라 레코드를 하나씩 배치하는 것이 아닌가요? 사실 레코드 라인 형식의 레코드 헤더 정보부터 시작해야 합니다. |
page_demo 테이블에는 3개의 열이 있습니다. c1 및 c2 열은 정수를 저장하는 데 사용되고 c3 열은 문자열을 저장하는 데 사용됩니다. 🎜c1🎜 열을 기본 키로 지정하므로 특정 행 형식에서 InnoDB는 소위 🎜row_id🎜을 생성할 필요가 없습니다. > 우리에게는 열이 숨겨져 있습니다. 그리고 이 테이블에 ascii 문자 집합과 Compact 행 형식을 지정했습니다. 따라서 이 테이블에 기록된 행 형식 다이어그램은 다음과 같습니다. 🎜 🎜🎜사진에서 볼 수 있듯이
🎜🎜사진에서 볼 수 있듯이 레코드 헤더 정보의 5바이트 데이터를 의도적으로 제공합니다. 이 레코드 헤더 정보에서 각 속성의 일반적인 의미를 다시 한 번 살펴보겠습니다(현재는 Compact 줄 형식을 사용함). 데모): 🎜
| 이름 | 크기(단위: 비트) | 설명 | 🎜 thead>||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | Space size | Description |
|---|---|---|
PAGE_N_DIR_SLOTSPAGE_N_DIR_SLOTS
|
2字节 |
在页目录中的槽数量 |
PAGE_HEAP_TOP |
2字节 |
还未使用的空间最小地址,也就是说从该地址之后就是Free Space
|
PAGE_N_HEAP |
2字节 |
本页中的记录的数量(包括最小和最大记录以及标记为删除的记录) |
PAGE_FREE |
2字节 |
第一个已经标记为删除的记录地址(各个已删除的记录通过next_record也会组成一个单链表,这个单链表中的记录可以被重新利用) |
PAGE_GARBAGE |
2字节 |
已删除记录占用的字节数 |
PAGE_LAST_INSERT |
2字节 |
最后插入记录的位置 |
PAGE_DIRECTION |
2字节 |
记录插入的方向 |
PAGE_N_DIRECTION |
2字节 |
一个方向连续插入的记录数量 |
PAGE_N_RECS |
2字节 |
该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) |
PAGE_MAX_TRX_ID |
8字节 |
修改当前页的最大事务ID,该值仅在二级索引中定义 |
PAGE_LEVEL |
2字节 |
当前页在B+树中所处的层级 |
PAGE_INDEX_ID |
8字节 |
索引ID,表示当前页属于哪个索引 |
PAGE_BTR_SEG_LEAF |
10字节 |
B+树叶子段的头部信息,仅在B+树的Root页定义 |
PAGE_BTR_SEG_TOP |
10 |
페이지 디렉터리의 슬롯 수 |
PAGE_HEAP_TOP🎜🎜2바이트🎜🎜사용되지 않은 공간의 최소 주소입니다. 즉, 이 주소 다음은 여유 공간🎜 🎜🎜🎜PAGE_N_HEAP🎜🎜2바이트 🎜🎜이 페이지의 레코드 수(최소 및 최대 레코드와 삭제 표시된 레코드 포함) 🎜🎜🎜🎜PAGE_FREE 🎜🎜2바이트🎜🎜삭제 표시된 첫 번째 레코드 주소(삭제된 각 레코드는 next_record를 통해서도 레코드를 형성합니다. 단일 연결 목록, 이 단일 연결의 레코드 목록은 재사용 가능)🎜🎜🎜🎜PAGE_GARBAGE🎜🎜2바이트🎜🎜삭제된 레코드가 차지하는 바이트 수🎜🎜 🎜🎜PAGE_LAST_INSERT 🎜🎜2bytes🎜🎜삽입된 레코드의 마지막 위치🎜🎜🎜🎜PAGE_DIRECTION🎜🎜2Byte 🎜🎜레코드 삽입 방향 🎜🎜🎜🎜PAGE_N_DIRECTION🎜🎜2바이트 🎜🎜한 방향으로 연속적으로 삽입되는 레코드 수🎜🎜🎜🎜PAGE_N_RECS 🎜🎜2바이트 🎜🎜페이지의 레코드 수(최소 및 최대 레코드와 삭제 표시된 레코드 제외)🎜🎜🎜🎜PAGE_MAX_TRX_ID🎜🎜8바이트 🎜🎜현재 페이지의 최대 트랜잭션 ID를 수정하세요. 이 값은 보조 인덱스에서만 정의됩니다.🎜🎜🎜🎜PAGE_LEVEL🎜🎜2 바이트🎜🎜현재 페이지의 레벨 B+ 트리의 페이지🎜🎜🎜🎜PAGE_INDEX_ID🎜🎜8 Bytes🎜🎜index ID, 현재 페이지를 나타냄 인덱스가 🎜🎜🎜🎜PAGE_BTR_SEG_LEAF🎜🎜<code>10바이트 🎜🎜B+ 트리 리프 세그먼트의 헤더 정보, B+ 트리의 루트 페이지에서만 정의됨🎜🎜🎜🎜 PAGE_BTR_SEG_TOP🎜🎜10 bytes🎜🎜B+ 트리의 리프가 아닌 세그먼트의 헤더 정보, B+ 트리의 루트 페이지에서만 정의됨🎜🎜🎜🎜이전 글을 잘 읽어보셨다면 PAGE_N_DIR_SLOTS부터 PAGE_LAST_INSERT, PAGE_N_RECS까지의 의미를 확실히 알고 계실 겁니다. , 죄송합니다. 돌아가서 이전 기사를 다시 읽어보세요. 나머지 상태 정보를 이해하지 못하더라도 걱정하지 마세요. 한 번에 한 입씩 먹고 조금씩 배워야 합니다. (이 명사에 겁먹지 말고 침착하게 행동하세요.) 여기서는 먼저 PAGE_DIRECTION 및 PAGE_N_DIRECTION의 의미에 대해 이야기합니다.
PAGE_N_DIR_SLOTS到PAGE_LAST_INSERT以及PAGE_N_RECS的意思大家一定是清楚的,如果不清楚,对不起,你应该回头再看一遍前边的文章。剩下的状态信息看不明白不要着急,饭要一口一口吃,东西要一点一点学(一定要稍安勿躁哦,不要被这些名词吓到)。在这里我们先唠叨一下PAGE_DIRECTION和PAGE_N_DIRECTION的意思:PAGE_DIRECTION
假如新插入的一条记录的主键值比上一条记录的主键值大,我们说这条记录的插入方向是右边,反之则是左边。用来表示最后一条记录插入方向的状态就是PAGE_DIRECTION。
PAGE_N_DIRECTION
假设连续几次插入新记录的方向都是一致的,InnoDB会把沿着同一个方向插入记录的条数记下来,这个条数就用PAGE_N_DIRECTION这个状态表示。当然,如果最后一条记录的插入方向改变了的话,这个状态的值会被清零重新统计。
至于我们没提到的那些属性,我没说是因为现在不需要大家知道。不要着急,当我们学完了后边的内容,你再回头看,一切都是那么清晰。
上边唠叨的Page Header是专门针对数据页记录的各种状态信息,比方说页里头有多少个记录了呀,有多少个槽了呀。我们现在描述的File Header针对各种类型的页都通用,也就是说不同类型的页都会以File Header作为第一个组成部分,它描述了一些针对各种页都通用的一些信息,比方说这个页的编号是多少,它的上一个页、下一个页是谁啦吧啦吧啦~ 这个部分占用固定的38个字节,是由下边这些内容组成的:
| 名称 | 占用空间大小 | 描述 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
FIL_PAGE_SPACE_OR_CHKSUM |
4字节 |
页的校验和(checksum值) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
FIL_PAGE_OFFSET |
4字节 |
页号 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
FIL_PAGE_PREV |
4字节 |
上一个页的页号 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
FIL_PAGE_NEXT |
4字节 |
下一个页的页号 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
FIL_PAGE_LSN |
8字节 |
页面被最后修改时对应的日志序列位置(英文名是:Log Sequence Number) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
FIL_PAGE_TYPE |
2字节 |
该页的类型 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
FIL_PAGE_FILE_FLUSH_LSN |
8字节 |
仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID |
4PAGE_DIRECTION | 새로 삽입된 레코드의 기본 키 값이 이전 레코드의 기본 키 값보다 크면 해당 레코드의 삽입 방향이 오른쪽이라고 하고 그 반대도 마찬가지입니다. 마지막 레코드의 삽입 방향을 나타내는 데 사용되는 상태는 PAGE_N_DIRECTION | 새 레코드를 여러 번 연속해서 삽입하는 방향이 같다고 가정하면,
| 이름 | 점유 공간 | 설명 |
|---|
FIL_PAGE_SPACE_OR_CHKSUM🎜🎜4바이트 🎜🎜페이지의 체크섬 값🎜 🎜FIL_PAGE_OFFSET🎜🎜4 code>바이트 🎜🎜페이지 번호🎜🎜<tr>🎜<code>FIL_PAGE_PREV🎜🎜4bytes🎜🎜이전 페이지의 페이지 번호🎜🎜<tr>🎜<code> FIL_PAGE_NEXT🎜🎜4바이트🎜🎜다음 페이지의 페이지 번호🎜🎜🎜FIL_PAGE_LSN🎜🎜8바이트 🎜🎜페이지가 마지막으로 수정되었을 때 해당 로그 시퀀스 위치(영문 이름: Log Sequence Number)🎜🎜FIL_PAGE_TYPE🎜🎜2bytes🎜🎜The 페이지 유형🎜🎜FIL_PAGE_FILE_FLUSH_LSN🎜🎜8 바이트 🎜🎜는 시스템 테이블스페이스의 한 페이지에만 정의됩니다. 즉, 파일이 최소한 해당 LSN 값 🎜🎜FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID🎜🎜4 단어로 플러시됩니다. 섹션 🎜🎜 페이지가 속한 테이블스페이스는 🎜🎜🎜🎜이 표와 비교하여 현재 중요한 몇 가지 부분을 살펴보겠습니다.
FIL_PAGE_SPACE_OR_CHKSUMFIL_PAGE_SPACE_OR_CHKSUM
这个代表当前页面的校验和(checksum)。啥是个校验和?就是对于一个很长很长的字节串来说,我们会通过某种算法来计算一个比较短的值来代表这个很长的字节串,这个比较短的值就称为校验和。这样在比较两个很长的字节串之前先比较这两个长字节串的校验和,如果校验和都不一样两个长字节串肯定是不同的,所以省去了直接比较两个比较长的字节串的时间损耗。
FIL_PAGE_OFFSET
每一个页都有一个单独的页号,就跟你的身份证号码一样,InnoDB通过页号来可以唯一定位一个页。
FIL_PAGE_TYPE
这个代表当前页的类型,我们前边说过,InnoDB为了不同的目的而把页分为不同的类型,我们上边介绍的其实都是存储记录的数据页,其实还有很多别的类型的页,具体如下表:
| 类型名称 | 十六进制 | 描述 |
|---|---|---|
FIL_PAGE_TYPE_ALLOCATED |
0x0000 | 最新分配,还没使用 |
FIL_PAGE_UNDO_LOG |
0x0002 | Undo日志页 |
FIL_PAGE_INODE |
0x0003 | 段信息节点 |
FIL_PAGE_IBUF_FREE_LIST |
0x0004 | Insert Buffer空闲列表 |
FIL_PAGE_IBUF_BITMAP |
0x0005 | Insert Buffer位图 |
FIL_PAGE_TYPE_SYS |
0x0006 | 系统页 |
FIL_PAGE_TYPE_TRX_SYS |
0x0007 | 事务系统数据 |
FIL_PAGE_TYPE_FSP_HDR |
0x0008 | 表空间头部信息 |
FIL_PAGE_TYPE_XDES |
0x0009 | 扩展描述页 |
FIL_PAGE_TYPE_BLOB |
0x000A | 溢出页 |
FIL_PAGE_INDEX |
0x45BF | 索引页,也就是我们所说的数据页
| 이는 현재 페이지의 체크섬을 나타냅니다. 체크섬이란 무엇입니까? 매우 긴 바이트 문자열의 경우 일부 알고리즘을 사용하여 긴 바이트 문자열을 나타내는 더 짧은 값을 계산합니다. 이 짧은 값을
FIL_PAGE_OFFSET🎜🎜각 페이지에는 ID 번호, InnoDB code>A <code>와 마찬가지로 별도의 페이지 번호가 있습니다. 페이지는 페이지 번호를 통해 고유하게 찾을 수 있습니다. 🎜
FIL_PAGE_TYPE🎜🎜이것은 현재 페이지의 유형을 나타냅니다. 앞서 말했듯이 InnoDB는 이를 다른 용도로 사용합니다. 페이지는 여러 가지 유형으로 나누어집니다. 위에서 소개한 것은 실제로 기록을 저장하는 데이터 페이지입니다. 실제로 다음 표에 자세히 설명된 것처럼 다양한 유형의 페이지가 있습니다. FIL_PAGE_TYPE_ALLOCATED🎜FIL_PAGE_UNDO_LOG🎜FIL_PAGE_INODE🎜FIL_PAGE_IBUF_FREE_LIST🎜FIL_PAGE_IBUF_BITMAP🎜FIL_PAGE_TYPE_SYS code >🎜<td>0x0006🎜</td>
<td>시스템 페이지🎜🎜</td>
<tr>
<td>
<code>FIL_PAGE_TYPE_TRX_SYS🎜FIL_PAGE_TYPE_XDES🎜FIL_PAGE_TYPE_BLOB🎜FIL_PAGE_INDEX🎜데이터 페이지🎜🎜🎜🎜라고 부르는 인덱스 페이지우리가 기록을 저장하는 데이터 페이지의 유형은 실제로 FIL_PAGE_INDEX, 소위 인덱스 페이지입니다. 인덱스가 무엇인지는 다음 장을 들어보시죠~FIL_PAGE_INDEX,也就是所谓的索引页。至于啥是个索引,且听下回分解~
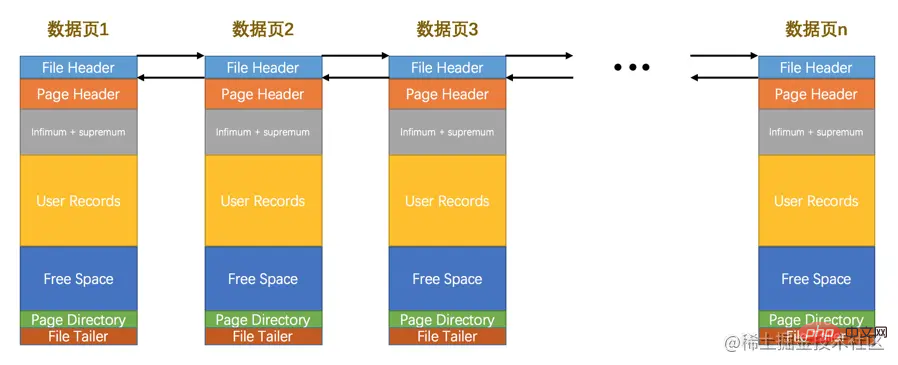
FIL_PAGE_PREV和FIL_PAGE_NEXT
我们前边强调过,InnoDB都是以页为单位存放数据的,有时候我们存放某种类型的数据占用的空间非常大(比方说一张表中可以有成千上万条记录),InnoDB可能不可以一次性为这么多数据分配一个非常大的存储空间,如果分散到多个不连续的页中存储的话需要把这些页关联起来,FIL_PAGE_PREV和FIL_PAGE_NEXT就分别代表本页的上一个和下一个页的页号。这样通过建立一个双向链表把许许多多的页就都串联起来了,而无需这些页在物理上真正连着。需要注意的是,并不是所有类型的页都有上一个和下一个页的属性,不过我们本集中唠叨的数据页(也就是类型为FIL_PAGE_INDEX的页)是有这两个属性的,所以所有的数据页其实是一个双链表,就像这样:
关于File Header的其他属性我们暂时用不到,等用到的时候再提哈~
我们知道InnoDB存储引擎会把数据存储到磁盘上,但是磁盘速度太慢,需要以页为单位把数据加载到内存中处理,如果该页中的数据在内存中被修改了,那么在修改后的某个时间需要把数据同步到磁盘中。但是在同步了一半的时候中断电了咋办,这不是莫名尴尬么?为了检测一个页是否完整(也就是在同步的时候有没有发生只同步一半的尴尬情况),设计InnoDB的大叔们在每个页的尾部都加了一个File Trailer部分,这个部分由8个字节组成,可以分成2个小部分:
前4个字节代表页的校验和
这个部分是和File Header中的校验和相对应的。每当一个页面在内存中修改了,在同步之前就要把它的校验和算出来,因为File Header在页面的前边,所以校验和会被首先同步到磁盘,当完全写完时,校验和也会被写到页的尾部,如果完全同步成功,则页的首部和尾部的校验和应该是一致的。如果写了一半儿断电了,那么在File Header中的校验和就代表着已经修改过的页,而在File Trailer中的校验和代表着原先的页,二者不同则意味着同步中间出了错。
后4个字节代表页面被最后修改时对应的日志序列位置(LSN)
这个部分也是为了校验页的完整性的,只不过我们目前还没说LSN是个什么意思,所以大家可以先不用管这个属性。
这个File Trailer与File Header类似,都是所有类型的页通用的。
InnoDB为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做数据页。
一个数据页可以被大致划分为7个部分,分别是
File Header,表示页的一些通用信息,占固定的38字节。Page Header,表示数据页专有的一些信息,占固定的56个字节。Infimum + Supremum,两个虚拟的伪记录,分别表示页中的最小和最大记录,占固定的26个字节。User Records:真实存储我们插入的记录的部分,大小不固定。Free Space:页中尚未使用的部分,大小不确定。Page Directory:页中的某些记录相对位置,也就是各个槽在页面中的地址偏移量,大小不固定,插入的记录越多,这个部分占用的空间越多。File Trailer:用于检验页是否完整的部分,占用固定的8个字节。每个记录的头信息中都有一个next_record属性,从而使页中的所有记录串联成一个单链表。
InnoDB会把页中的记录划分为若干个组,每个组的最后一个记录的地址偏移量作为一个槽,存放在Page Directory
FIL_PAGE_PREV와 FIL_PAGE_NEXT앞서 InnoDB가 둘 다 데이터 기반으로 페이지에 저장됩니다. 때로는 특정 유형의 데이터를 저장할 때 매우 많은 양의 공간을 차지합니다(예를 들어 테이블에 수천 개의 레코드가 있을 수 있음). > 한꺼번에 저장하지 못할 수도 있습니다. 너무 많은 데이터가 매우 큰 저장 공간을 할당합니다. 여러 개의 불연속적인 페이지에 분산되어 저장되면 이러한 페이지를 FIL_PAGE_PREV와 연결해야 합니다. code>FIL_PAGE_NEXT는 각각 이 페이지의 이전 페이지와 다음 페이지의 페이지 번호를 나타냅니다. 이러한 방식으로 페이지를 물리적으로 연결할 필요 없이 이중 연결 목록을 설정하여 많은 페이지를 직렬로 연결합니다. 모든 유형의 페이지가 이전 페이지와 다음 페이지의 속성을 갖는 것은 아니지만, 이번 에피소드에서 이야기하는 데이터 페이지(즉, 유형은 FIL_PAGE_INDEX 페이지)에는 이 두 가지 속성이 있으므로 모든 데이터 페이지는 실제로 다음과 같은 이중 연결 목록입니다.
파일 헤더정보> 지금은 >의 다른 속성을 사용하지 않지만 사용할 때 언급하겠습니다. 🎜InnoDB 스토리지 엔진이 그러나 디스크 속도가 너무 느리고, 페이지의 데이터를 메모리에서 수정하려면 페이지 단위로 데이터를 메모리에 로드해야 합니다. 수정 후 특정 시점에 메모리에 로드됩니다. 그런데 동기화 도중에 전원이 끊기면 어떻게 해야 하나요? 페이지가 완성되었는지(즉, 동기화 중에 페이지의 절반만 동기화되는 당황스러운 상황이 있는지) 확인하기 위해 InnoDB를 설계한 삼촌들이 파일을 에 추가했습니다. 예고편 부분은 8 바이트로 구성되며 두 개의 작은 부분으로 나눌 수 있습니다: 🎜🎜🎜🎜처음 4바이트는 페이지의 체크섬을 나타냅니다. 🎜🎜이 부분은 파일 헤더의 체크섬에 해당합니다. 페이지가 메모리에서 수정될 때마다 동기화 전에 체크섬을 계산해야 합니다. 파일 헤더가 페이지 앞에 있기 때문에 체크섬이 먼저 디스크에 동기화됩니다. 전체 동기화에 성공하면 페이지 시작 부분과 끝 부분의 체크섬이 일치해야 합니다. 작성 중 전원이 꺼지면 파일 헤더의 체크섬이 수정된 페이지를 나타내고, 파일 예고편의 체크섬이 원본 페이지를 나타냅니다. 이는 동기화 중에 오류가 발생했음을 의미합니다. 🎜🎜🎜🎜마지막 4바이트는 페이지가 마지막으로 수정되었을 때 해당 로그 시퀀스 위치(LSN)를 나타냅니다.🎜🎜이 부분도 페이지의 무결성을 확인하기 위한 부분이지만 아직 LSN은 언급하지 않았습니다. code>는 무엇을 의미하므로 지금은 이 속성을 무시해도 됩니다. 🎜🎜🎜이 <code>파일 예고편은 파일 헤더와 유사하며 모든 유형의 페이지에 공통됩니다. 🎜데이터 페이지라고 부릅니다. 🎜🎜🎜🎜데이터 페이지는 대략 7개 부분으로 나눌 수 있는데, 🎜🎜🎜파일 헤더는 페이지의 일반적인 정보를 나타내며 고정된 38바이트를 차지합니다. 🎜🎜페이지 헤더는 데이터 페이지에만 있는 일부 정보를 나타내며 고정된 56바이트를 차지합니다. 🎜🎜Infimum + Supremum, 두 개의 가상 의사 레코드, 각각 페이지의 최소 및 최대 레코드를 나타내며 고정된 26 바이트를 차지합니다. 🎜🎜사용자 레코드: 우리가 삽입한 레코드가 실제로 저장되는 부분으로 크기가 고정되어 있지 않습니다. 🎜🎜여유 공간: 페이지의 사용되지 않은 부분, 크기가 불확실합니다. 🎜🎜페이지 디렉토리: 페이지 내 특정 레코드의 상대적 위치, 즉 페이지 내 각 슬롯의 주소 오프셋은 크기가 고정되지 않습니다. 더 많은 레코드를 삽입할수록 더 많은 공간이 확보됩니다. 부분이 많이 차지합니다. 🎜🎜파일 예고편: 페이지가 완성되었는지 확인하는 데 사용되며 고정된 8바이트를 차지합니다. 🎜🎜🎜🎜각 레코드의 헤더 정보에는 next_record 속성이 있어 페이지의 모든 레코드가 단일 연결 목록으로 연결됩니다. 🎜🎜🎜🎜InnoDB는 페이지의 레코드를 여러 그룹으로 나눕니다. 각 그룹의 마지막 레코드의 주소 오프셋은 슬롯으로 사용되며 페이지 디렉토리각 데이터 페이지의 파일 헤더 부분에는 이전 페이지와 다음 페이지의 번호가 포함되어 있으므로 모든 데이터 페이지는 이중 연결 목록을 구성합니다. File Header部分都有上一个和下一个页的编号,所以所有的数据页会组成一个双链表。
为保证从内存中同步到磁盘的页的完整性,在页的首部和尾部都会存储页中数据的校验和和页面最后修改时对应的LSN值,如果首部和尾部的校验和和LSN
LSN 값이 페이지의 시작과 끝 부분에 저장됩니다. 페이지의 헤더와 트레일러의 체크섬과 LSN 값이 성공적으로 확인되지 않으면 동기화 프로세스에 문제가 있는 것입니다. 추천 학습: 🎜mysql 비디오 튜토리얼🎜🎜위 내용은 MySQL 원칙의 InnoDB 데이터 페이지에 대한 심층 연구의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!




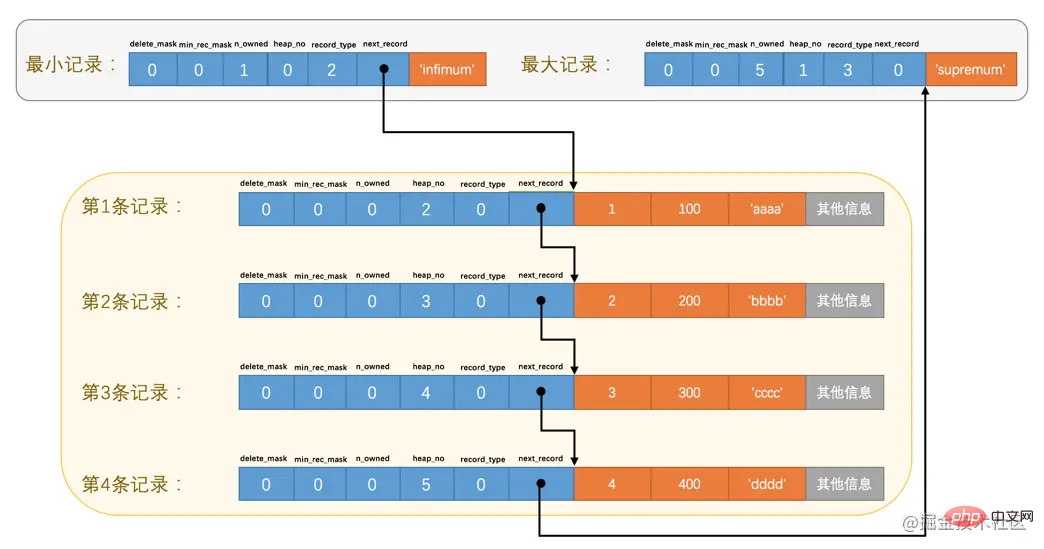

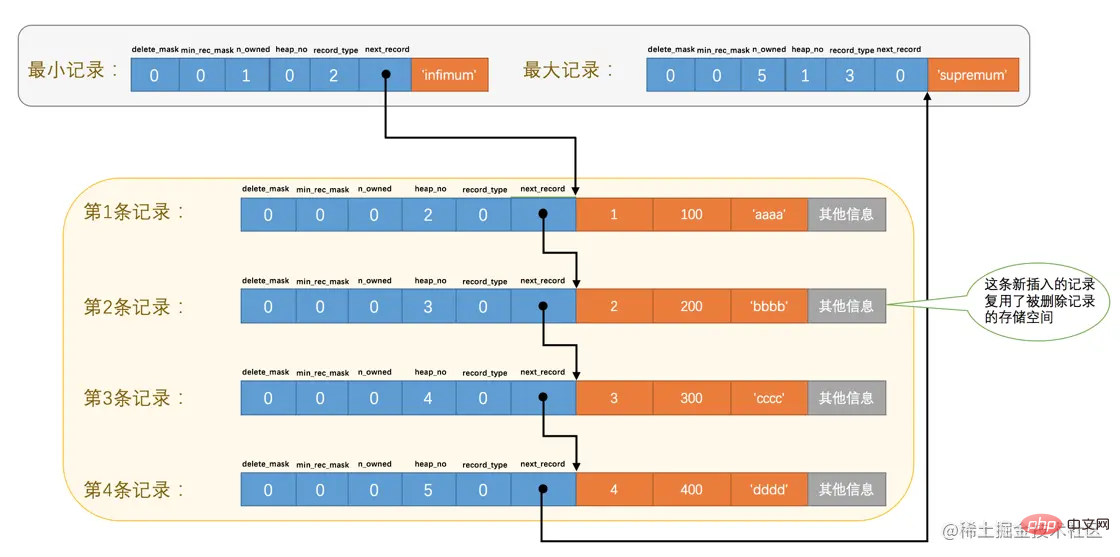
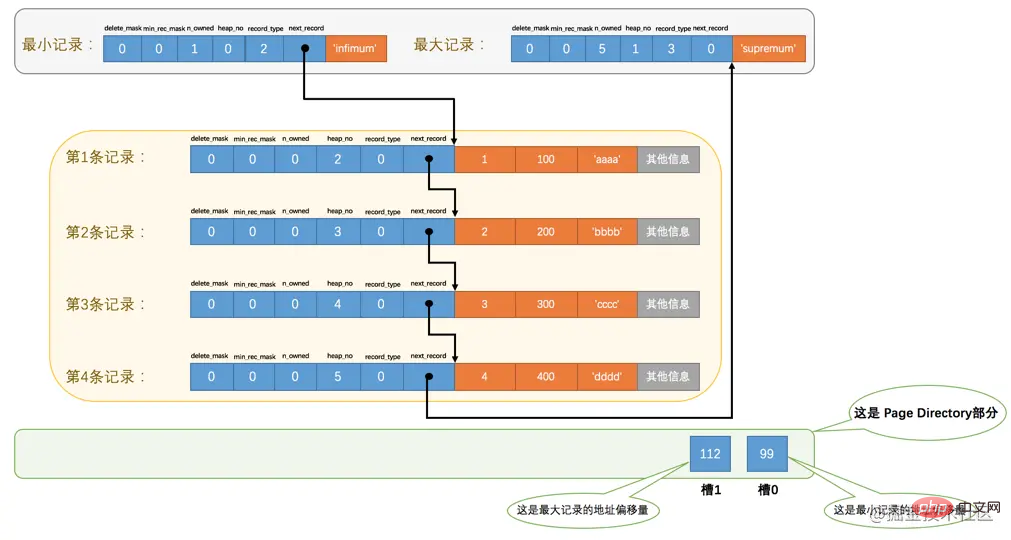

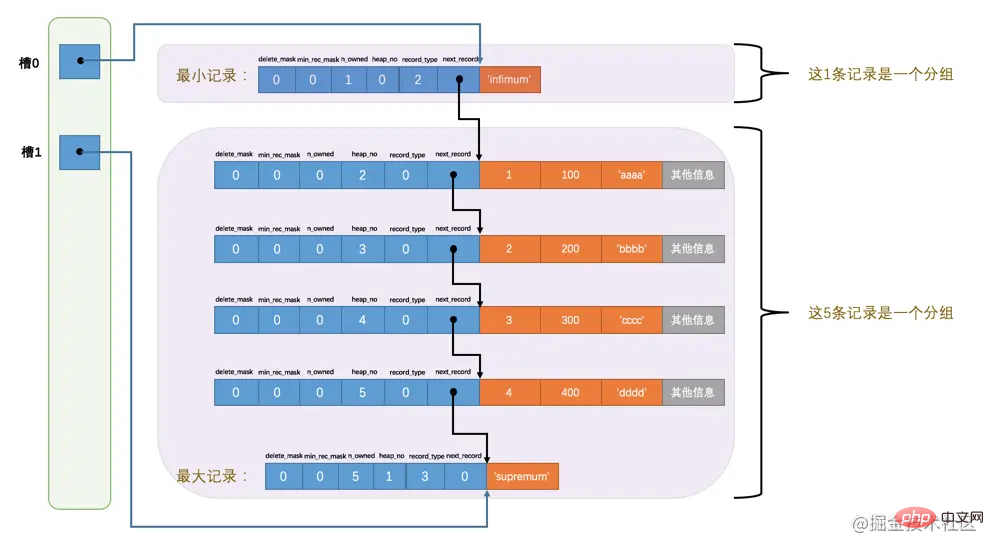
 🎜🎜오 이상해 보이네 이런 지저분한 사진은 내 강박증에 참을 수 없으니까 그럼 해보자 당분간 저장 장치의 레코드 배열에 관계없이 이러한 레코드와 페이지 디렉토리 간의 관계를 논리적으로 살펴보십시오. 🎜
🎜🎜오 이상해 보이네 이런 지저분한 사진은 내 강박증에 참을 수 없으니까 그럼 해보자 당분간 저장 장치의 레코드 배열에 관계없이 이러한 레코드와 페이지 디렉토리 간의 관계를 논리적으로 살펴보십시오. 🎜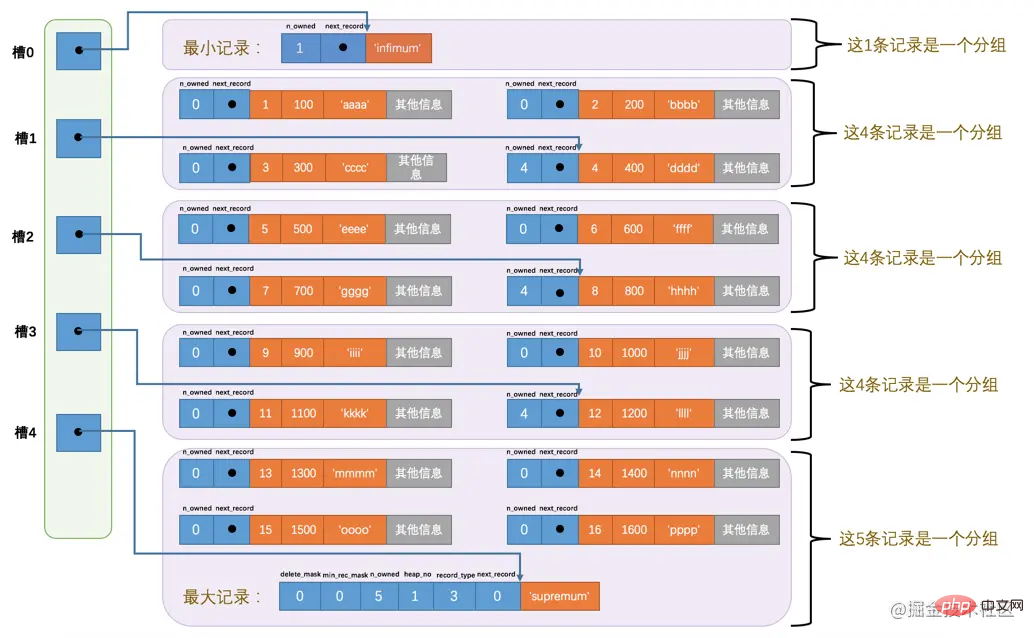














![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



