


이 기사는 mysql의 논리적 구조와 sql 실행문을 포함하여 mysql 인덱스에 대한 관련 지식을 제공합니다.

MySQL의 스토리지 엔진 아키텍처는 쿼리 처리와 데이터 저장/검색을 분리합니다. 다음은 MySQL의 논리 아키텍처 다이어그램입니다.

각 클라이언트 연결은 서버의 스레드에 해당합니다. 각 연결에 대한 스레드 생성 및 삭제를 방지하기 위해 스레드 풀이 서버에 유지됩니다. 클라이언트가 MySQL 서버에 연결되면 서버가 이를 인증합니다. 인증은 사용자 이름과 비밀번호 또는 SSL 인증서를 통해 수행할 수 있습니다. 로그인 인증이 통과된 후 서버는 클라이언트가 특정 쿼리를 실행할 권한이 있는지 여부도 확인합니다.
SQL 컴파일 및 최적화(예: 테이블 읽기 순서 조정, 적절한 인덱스 선택 등)를 담당합니다. SELECT 문의 경우, 쿼리를 구문 분석하기 전에 서버는 먼저 쿼리 캐시를 확인합니다. 해당 쿼리 결과가 있으면 쿼리 구문 분석, 최적화 등의 작업 없이 쿼리 결과가 직접 반환됩니다. 저장 프로시저, 트리거, 뷰 등은 모두 이 계층에서 구현됩니다.
스토리지 엔진은 MySQL에 데이터 저장, 데이터 추출, 트랜잭션 시작 등을 담당합니다. 스토리지 엔진은 API를 통해 상위 계층과 통신합니다. 이러한 API는 서로 다른 스토리지 엔진 간의 차이점을 보호하여 이러한 차이점을 상위 계층 쿼리 프로세스에 투명하게 만듭니다. 스토리지 엔진은 SQL을 구문 분석하지 않습니다.
MyISAM: 각 MyISAM은 디스크에 3개의 파일로 저장됩니다. 테이블 정의 파일, 데이터 파일, 인덱스 파일이 있습니다. 첫 번째 파일의 이름은 테이블 이름으로 시작하고 확장자는 파일 형식을 나타냅니다. .frm 파일은 테이블 정의를 저장합니다. 데이터 파일 확장자는 .MYD(MYData)입니다. 인덱스 파일의 확장자는 .MYI(MYIndex)입니다.
InnoDB: 모든 테이블은 동일한 데이터 파일(또는 여러 파일 또는 독립적인 테이블 공간 파일)에 저장됩니다. InnoDB 테이블의 크기는 일반적으로 2GB인 운영 체제 파일 크기에 의해서만 제한됩니다.
MyISAM은 세 가지 저장 형식을 지원합니다: 정적 테이블(기본값이지만 데이터 끝에 공백이 있을 수 없으므로 제거됩니다), 동적 테이블 및 압축 테이블. 테이블이 생성되고 데이터를 가져온 후에는 수정되지 않습니다. 압축된 테이블을 사용하면 디스크 공간 사용량을 크게 줄일 수 있습니다.
InnoDB: 더 많은 메모리와 스토리지가 필요하며 데이터 및 인덱스 캐싱을 위해 메인 메모리에 자체 전용 버퍼 풀을 설정합니다.
MyISAM: 데이터가 파일 형식으로 저장되므로 플랫폼 간 데이터 전송에 매우 편리합니다. 백업 및 복구 중에 테이블에 대한 작업을 개별적으로 수행할 수 있습니다.
InnoDB: 무료 솔루션에는 데이터 파일 복사, binlog 백업 또는 mysqldump 사용이 포함되는데, 이는 데이터 볼륨이 수십 기가바이트에 도달하면 상대적으로 고통스럽습니다.
MyISAM: 각 쿼리는 원자적이고 실행 시간이 InnoDB 유형보다 빠르지만 트랜잭션 지원을 제공하지 않습니다.
InnoDB: 트랜잭션 지원, 외래 키 및 기타 고급 데이터베이스 기능을 제공합니다. 트랜잭션(커밋), 롤백(롤백) 및 충돌 복구 기능을 갖춘 트랜잭션 안전(ACID 호환) 테이블입니다.
MyISAM: 다른 필드와 공동 인덱스를 만들 수 있습니다. 엔진의 자동 증가 열은 인덱스여야 합니다. 결합된 인덱스인 경우 자동 증가 열이 첫 번째 열일 필요는 없습니다. 이전 열에 따라 정렬한 후 증분할 수 있습니다.
InnoDB: InnoDB에는 이 필드만 있는 인덱스가 포함되어야 합니다. 엔진의 자동 증가 열은 인덱스여야 하며, 복합 인덱스인 경우에는 복합 인덱스의 첫 번째 열이기도 해야 합니다.
MyISAM: 사용자가 myisam 테이블을 작동할 때 잠긴 테이블이 삽입 동시성을 충족하면 select, update, delete 문이 자동으로 테이블을 잠급니다. 이 경우 테이블 끝에 새로운 데이터를 삽입할 수 있습니다.
InnoDB: 트랜잭션 및 행 수준 잠금을 지원하는 것은 innodb의 가장 큰 기능입니다. 행 잠금은 다중 사용자 동시 작업의 성능을 크게 향상시킵니다. 그러나 InnoDB의 행 잠금은 WHERE의 기본 키에서만 유효합니다. 기본 키가 아닌 WHERE는 전체 테이블을 잠급니다.
MyISAM: FULLTEXT 유형 전체 텍스트 인덱스를 지원합니다.
InnoDB: FULLTEXT 유형 전체 텍스트 인덱스를 지원하지 않지만 innodb는 스핑크스 플러그인을 사용하여 전체 텍스트 인덱싱을 지원할 수 있습니다. , 효과가 더 좋습니다.
MyISAM: 인덱스와 기본 키가 없는 테이블이 존재할 수 있도록 합니다. 인덱스는 행이 저장되는 주소입니다.
InnoDB: 기본 키가 없거나 비어 있지 않은 고유 인덱스가 설정되어 있으면 6바이트 기본 키(사용자에게 표시되지 않음)가 자동으로 생성됩니다. 데이터는 기본 인덱스의 일부이며 추가 인덱스는 기본 인덱스.
MyISAM: 테이블의 총 행 수를 저장합니다.
InnoDB: 테이블의 총 행 수는 저장되지 않습니다. 테이블에서 select count(*)를 사용하면 전체 테이블을 탐색하므로 많은 비용이 소모됩니다. myisam과 innodb는 같은 방식으로 처리합니다.select distinct ... from ... join ... on ... where ... group by ... having ... order by ... limit ...
from ... on ... join ... where ... group by ... having ... select distinct ... order by ... limit ...
4. 인덱스
1. 인덱스의 장점예를 들어 B+ 때문에 나이순으로 쿼리합니다. 인덱스 트리 자체적으로 정렬되므로 후속 쿼리에 의해 인덱스가 트리거되면 다시 쿼리할 필요가 없습니다.
2. 인덱스의 단점(3) 인덱스는 추가, 삭제, 수정의 효율성을 떨어뜨립니다
3. 인덱스 분류(3) 통합 인덱스
(4) 기본 키 인덱스
참고: 고유 인덱스와 기본 키 인덱스의 유일한 차이점은 기본 키입니다. index는 null일 수 없습니다.
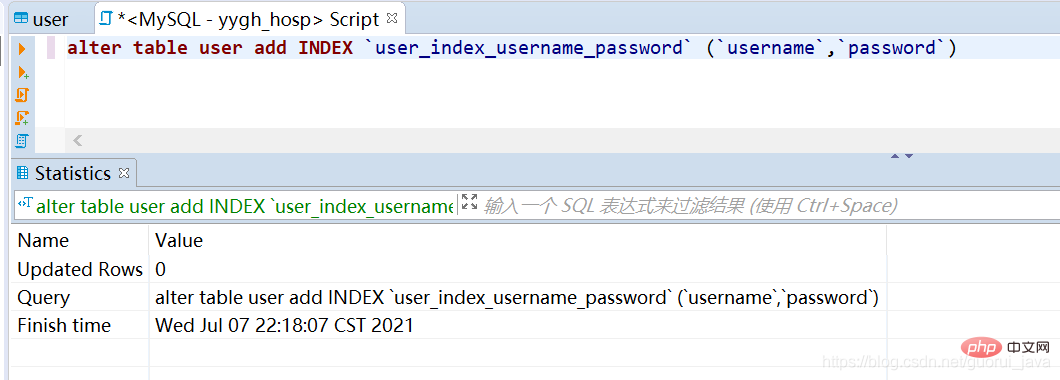
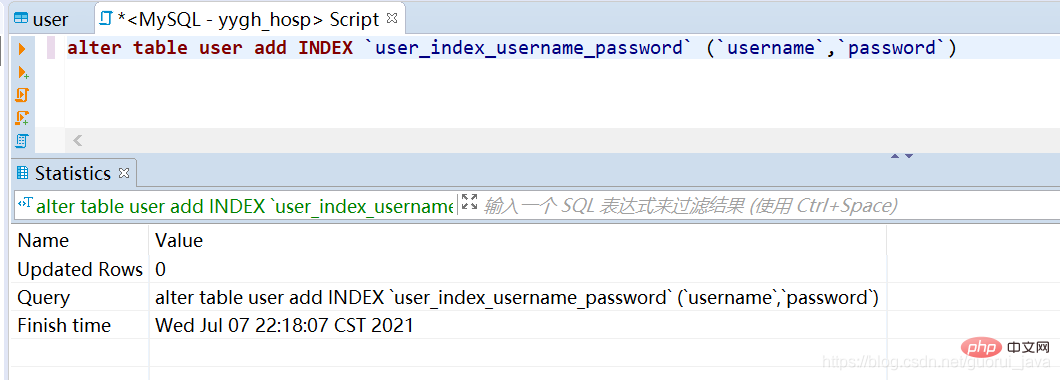
4. 인덱스 생성alter table user add INDEX `user_index_username_password` (`username`,`password`)
 MySQL 인덱스의 기본 데이터 구조는 B+ 트리입니다.
MySQL 인덱스의 기본 데이터 구조는 B+ 트리입니다.
B-Tree 구조 다이어그램의 각 노드에는 데이터의 키 값뿐만 아니라 데이터 값도 포함됩니다. 각 페이지의 저장 공간은 제한되어 있으며, 데이터 데이터가 크면 각 노드(즉, 한 페이지)에 저장할 수 있는 키의 수가 매우 적습니다. B - Tree의 깊이가 커져 쿼리 중 디스크 I/O 수가 증가하여 쿼리 효율성에 영향을 미칩니다. B+Tree에서는 모든 데이터 레코드 노드가 키 값 순서로 동일한 레이어의 리프 노드에 저장되며, 리프가 아닌 노드에는 키 값 정보만 저장되므로 각 노드에 저장되는 키 값의 수가 크게 늘어날 수 있습니다. node.B+Tree의 높이를 줄입니다.
B+Tree는 B-Tree와 비교하여 몇 가지 차이점이 있습니다.
Non-leaf 노드는 키 값 정보만 저장합니다.
모든 리프 노드 사이에는 링크 포인터가 있습니다.데이터 레코드는 리프 노드에 저장됩니다.
이전 섹션에서 B-Tree를 최적화합니다. B+Tree의 리프가 아닌 노드는 키 값 정보만 저장하므로 각 디스크 블록이 4개의 키 값과 포인터 정보를 저장할 수 있다고 가정하면 B의 구조가 됩니다. +Tree. 아래 그림과 같이: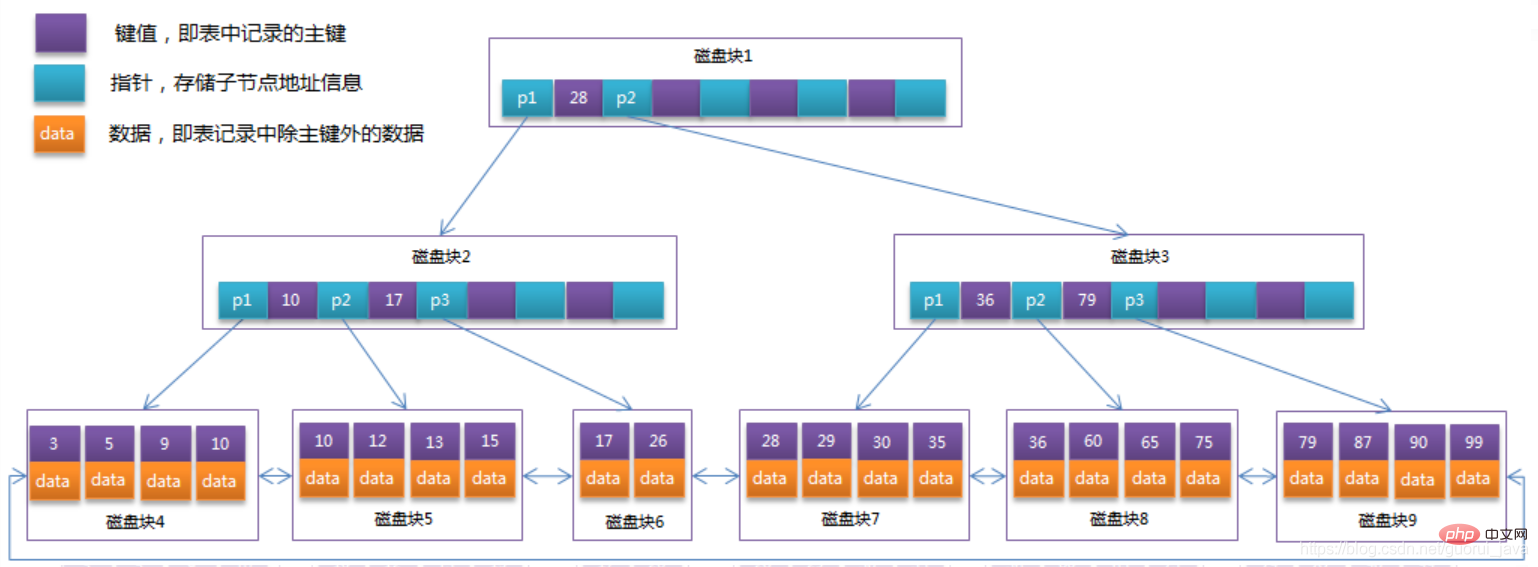 위 예에는 데이터 레코드가 22개만 있을 수 있으며 B+Tree의 장점을 볼 수 없습니다. 계산은 다음과 같습니다.
위 예에는 데이터 레코드가 22개만 있을 수 있으며 B+Tree의 장점을 볼 수 없습니다. 계산은 다음과 같습니다.
InnoDB 스토리지 엔진의 페이지 크기는 16KB이고 기본 키 유형은 일반 테이블은 INT(4워드 점유) 섹션) 또는 BIGINT(8바이트 점유)이며 포인터 유형은 일반적으로 4 또는 8바이트입니다. 이는 한 페이지(B+Tree의 노드)가 약 16KB/(8B+8B)를 저장한다는 것을 의미합니다. )=1K 키값(추정이므로 계산의 편의를 위해 여기서 K값은 〖10〗^3)입니다. 즉, 깊이가 3인 B+Tree 인덱스는 10^3 * 10^3 * 10^3 = 10억 개의 레코드를 유지할 수 있습니다.
실제 상황에서는 각 노드가 완전히 채워지지 않을 수 있으므로 데이터베이스에서 B+Tree의 높이는 일반적으로 2~4레이어입니다. MySQL의 InnoDB 스토리지 엔진은 루트 노드가 메모리에 상주하도록 설계되었습니다. 즉, 특정 키 값의 행 레코드를 찾는 데 1~3회의 디스크 I/O 작업만 필요하다는 의미입니다.
데이터베이스의 B+Tree 인덱스는 클러스터형 인덱스와 보조 인덱스로 나눌 수 있습니다. 위의 B+Tree 예시 다이어그램은 클러스터형 인덱스로 데이터베이스에 구현되어 있으며, 클러스터형 인덱스의 B+Tree에 있는 리프 노드에는 테이블 전체의 행 레코드 데이터가 저장됩니다. 보조 인덱스와 클러스터형 인덱스의 차이점은 보조 인덱스의 리프 노드에는 행 레코드의 모든 데이터가 포함되어 있는 것이 아니라 해당 행 데이터를 저장하는 클러스터형 인덱스 키, 즉 기본 키가 포함된다는 점입니다. 보조 인덱스를 통해 데이터를 쿼리할 때 InnoDB 스토리지 엔진은 보조 인덱스를 순회하여 기본 키를 찾은 다음 기본 키를 통해 클러스터형 인덱스에서 전체 행 레코드 데이터를 찾습니다.
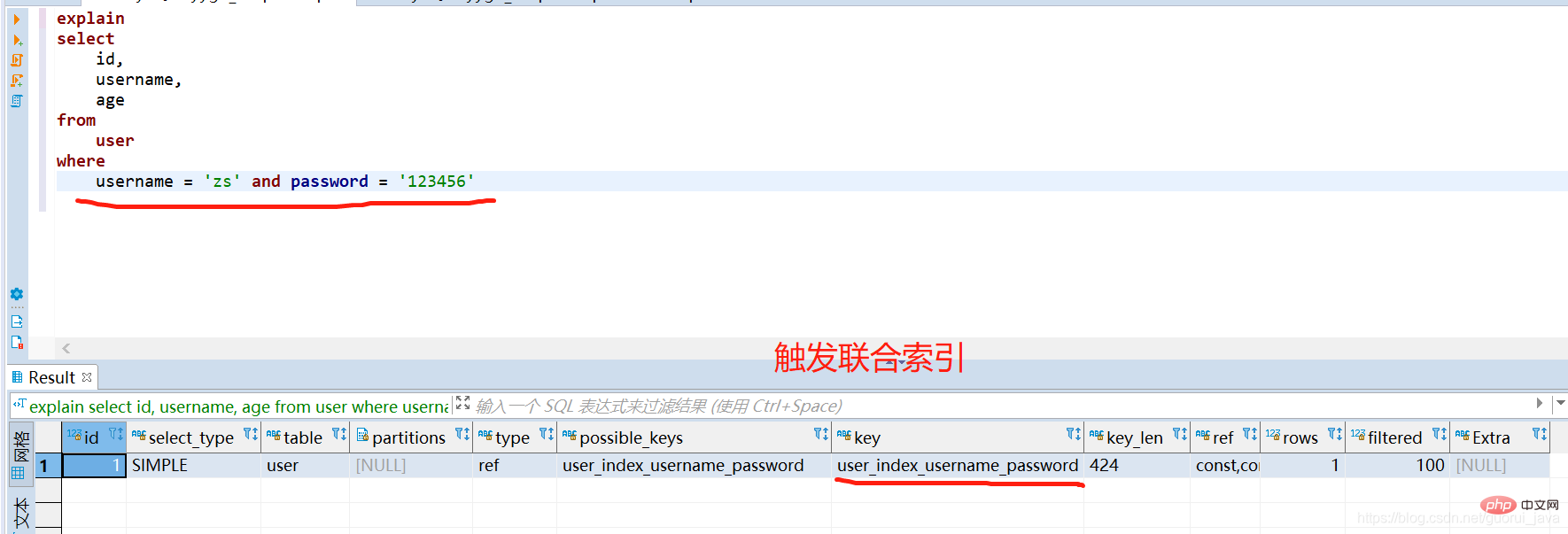
(1) 조인트 인덱스의 모든 인덱스 키를 사용합니다. to Trigger the Joint Index
(2) 조인트 인덱스의 모든 인덱스 키를 사용하지만 or와 연결하면 조인트 인덱스가 트리거될 수 없습니다
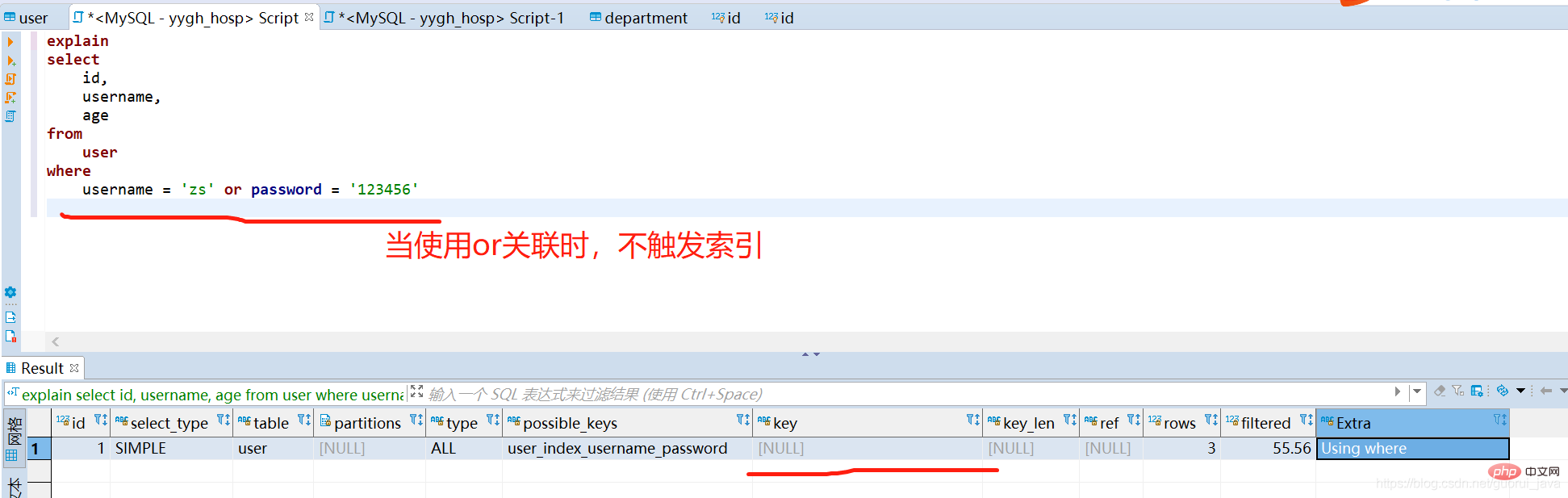
(3) 왼쪽의 첫 번째 필드가 조인트 인덱스 단독 사용 시 조인트 인덱스 트리거 가능

(4) 조인트 인덱스의 다른 필드 단독 사용 시 조인트 인덱스 트리거 불가

explain은 SQL 최적화를 시뮬레이션하여 SQL 문을 실행할 수 있습니다.
사용법 소개 (1) 사용자 테이블

(2) 부서 테이블
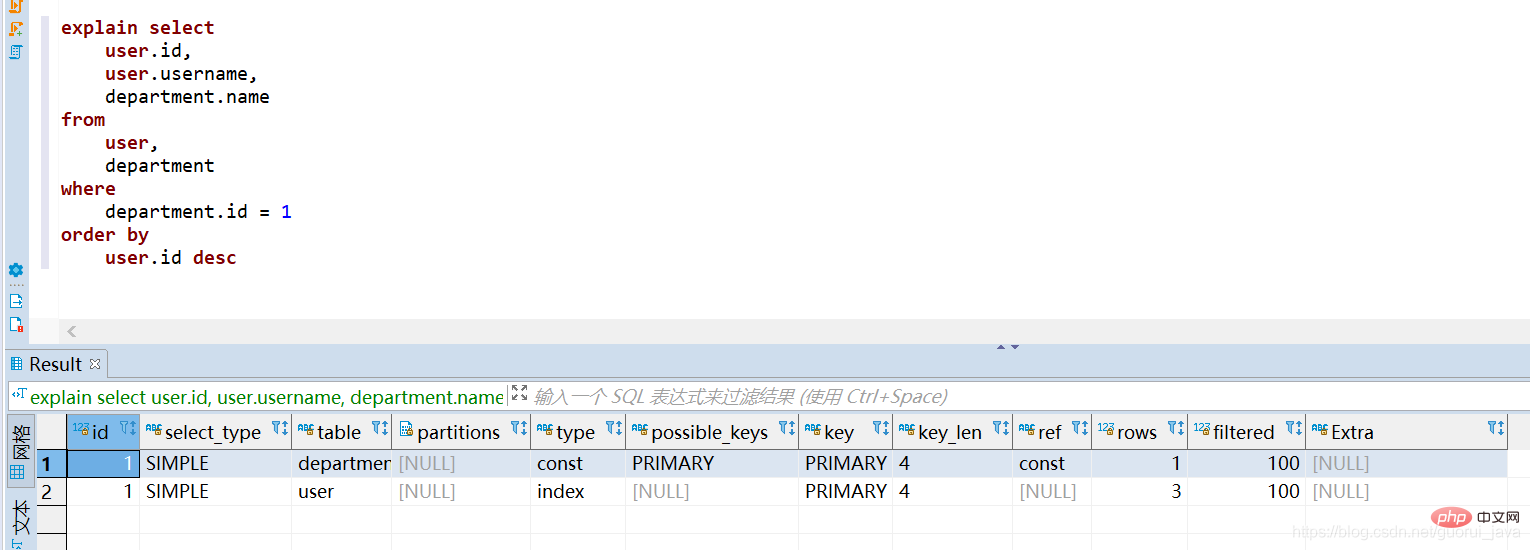
(3) Untriggered index
(4) Triggered index
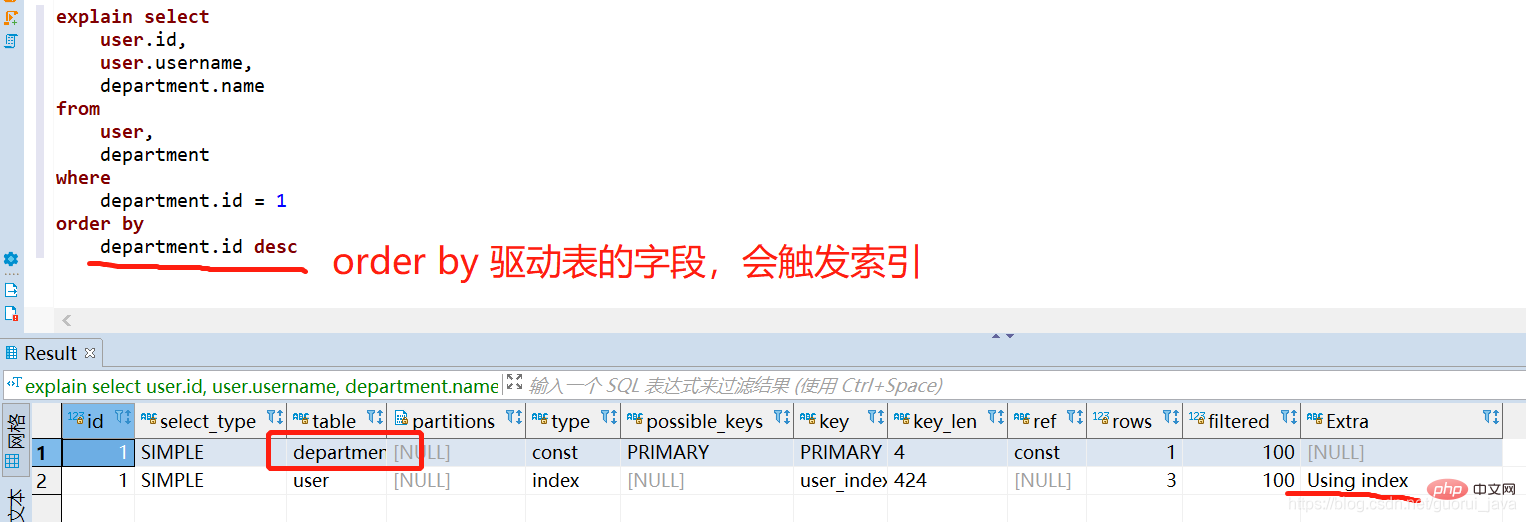
(5) 결과 분석 설명의 첫 번째 줄에 나타나는 테이블이 드라이버 테이블입니다.
조인 조건이 지정되면 쿼리 조건을 만족하는 몇 개의 행이 있는 테이블이 [구동 테이블]
index_merge: 이 조인 유형은 인덱스 병합 최적화 방법이 사용됨을 나타냅니다. 이 경우 키 열에는 사용된 인덱스 목록이 포함되고, key_len에는 사용된 인덱스의 가장 긴 키 요소가 포함됩니다.
unique_subquery: 이 유형은 IN 하위 쿼리의 참조를 다음 형식으로 대체합니다. value IN (SELECT Primary_key FROM Single_table WHERE some_expr) Unique_subquery는 하위 쿼리를 완전히 대체할 수 있고 더 효율적인 인덱스 조회 함수입니다.
index_subquery: 이 조인 유형은 Unique_subquery와 유사합니다. IN 하위 쿼리는 대체될 수 있지만 다음 형식의 하위 쿼리에 있는 고유하지 않은 인덱스에만 해당됩니다. value IN (SELECT key_column FROM Single_table WHERE some_expr)
range: 지정된 행 범위만 검색하고 인덱스를 사용하여 행을 선택합니다. 키 열에는 사용된 인덱스가 표시됩니다. key_len에는 사용된 인덱스의 가장 긴 키 요소가 포함됩니다. 이 유형에서는 ref 열이 NULL입니다. =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN 또는 IN 연산자를 사용할 때 키 열을 상수와 비교할 때 range
를 사용할 수 있습니다index: 이 조인 유형은 인덱스 트리만 스캔한다는 점을 제외하면 ALL과 동일합니다. 인덱스 파일은 일반적으로 데이터 파일보다 작기 때문에 일반적으로 ALL보다 빠릅니다.
all: 이전 테이블의 모든 행 조합에 대해 전체 테이블 스캔을 수행합니다. 테이블이 const로 표시되지 않은 첫 번째 테이블인 경우 일반적으로 좋지 않으며, 이 경우 일반적으로 나쁩니다. 일반적으로 이전 테이블의 상수 값이나 열 값을 기반으로 행을 검색할 수 있도록 ALL을 사용하지 않고도 인덱스를 더 추가하는 것이 가능합니다.
(5) available_keys: available_keys 열은 MySQL이 테이블에서 행을 찾는 데 사용할 수 있는 인덱스를 나타냅니다. 이 열은 EXPLAIN 출력에 표시된 테이블 순서와 완전히 독립적입니다. 이는 available_keys의 일부 키가 생성된 테이블 순서에 실제로 사용될 수 없음을 의미합니다.
(6) 키: 키 열에는 MySQL이 실제로 사용하기로 결정한 키(인덱스)가 표시됩니다. 인덱스를 선택하지 않으면 키는 NULL입니다. MySQL이 available_keys 열의 인덱스를 사용하거나 무시하도록 하려면 쿼리에서 FORCE INDEX, USE INDEX 또는 IGNORE INDEX를 사용하십시오.
(7) key_len: key_len 열은 MySQL이 사용하기로 결정한 키 길이를 보여줍니다. 키가 NULL이면 길이도 NULL입니다. key_len 값을 사용하여 MySQL이 실제로 사용할 다중 부분 키워드의 부분을 결정할 수 있습니다.
(8) ref: ref 열은 테이블에서 행을 선택하기 위해 키와 함께 사용되는 열 또는 상수를 보여줍니다.
(9) 행: 행 열은 MySQL이 쿼리를 실행할 때 확인해야 한다고 생각하는 행 수를 표시합니다.
(10)추가: 이 열에는 MySQL이 쿼리를 해결한 방법에 대한 세부 정보가 포함되어 있습니다.
고유함: MySQL은 일치하는 첫 번째 행을 찾은 후 현재 행 조합에 대해 더 많은 행 검색을 중지합니다.
존재하지 않음: MySQL은 쿼리에서 LEFT JOIN 최적화를 수행할 수 있습니다. LEFT JOIN 표준과 일치하는 행을 찾은 후에는 더 이상 테이블에서 이전 행 조합에 대해 더 많은 행을 확인하지 않습니다.
각 레코드에 대한 범위 확인(인덱스 맵: #): MySQL은 사용할 수 있는 좋은 인덱스를 찾지 못했지만, 이전 테이블의 열 값이 알려진 경우 일부 인덱스가 사용될 수 있음을 발견했습니다. 이전 테이블의 각 행 조합에 대해 MySQL은 range 또는 index_merge 액세스 방법을 사용하여 행을 검색할 수 있는지 여부를 확인합니다.
파일 정렬 사용: MySQL은 정렬된 순서로 행을 검색하는 방법을 알아내기 위해 한 번의 추가 단계가 필요합니다. 정렬은 조인 유형을 기준으로 모든 행을 찾아보고 WHERE 절과 일치하는 모든 행에 대한 정렬 키와 행 포인터를 저장하여 수행됩니다. 그런 다음 키가 정렬되고 행이 정렬된 순서로 검색됩니다.
인덱스 사용: 추가 검색 없이 인덱스 트리에 있는 정보만 사용하여 실제 행을 읽어 테이블에서 열 정보를 검색합니다. 이 전략은 쿼리가 단일 인덱스의 일부인 열만 사용할 때 사용할 수 있습니다.
임시 사용: 쿼리를 해결하려면 MySQL은 결과를 수용할 임시 테이블을 생성해야 합니다. 일반적인 상황은 다양한 상황에 따라 열을 나열할 수 있는 GROUP BY 및 ORDER BY 절이 쿼리에 포함된 경우입니다.
where 사용: WHERE 절은 다음 테이블과 일치하는 행을 제한하거나 고객에게 전송되는 행을 제한하는 데 사용됩니다. 테이블의 모든 행을 구체적으로 요청하거나 확인하지 않는 한 Extra 값이 Using where가 아니고 테이블 조인 유형이 ALL 또는 index인 경우 쿼리에 오류가 발생할 수 있습니다.
sort_union(...) 사용, Union(...) 사용, intersect(...) 사용: 이 함수는 index_merge 조인 유형에 대한 인덱스 스캔을 병합하는 방법을 보여줍니다.
그룹별로 인덱스 사용: 테이블에 액세스하는 인덱스 사용 방법과 유사하게, 그룹별로 인덱스를 사용한다는 것은 MySQL이 GROUP BY 또는 DISTINCT 쿼리의 모든 열을 쿼리하지 않고 쿼리하는 데 사용할 수 있는 인덱스를 찾았음을 의미합니다. 추가 검색. 실제 테이블에 대한 하드 디스크 액세스. 또한 각 그룹에 대해 몇 개의 인덱스 항목만 읽혀지도록 가장 효율적인 방법으로 인덱스를 사용하십시오.
EXPLAIN 출력의 행 열에 있는 모든 값을 곱하면 조인이 어떻게 수행되는지에 대한 힌트를 얻을 수 있습니다. 이는 MySQL이 쿼리를 실행하기 위해 확인해야 하는 행 수를 대략적으로 알려줍니다. 이 제품은 max_join_size 변수를 사용하여 쿼리를 제한할 때 실행할 다중 테이블 SELECT 문을 결정하는 데에도 사용됩니다.
추천 학습: mysql 비디오 튜토리얼
위 내용은 mysql 인덱싱 기술을 완전히 마스터하세요(요약 공유)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



