


MySQL 데이터베이스 명령의 폭발적인 수집(요약 공유)

이 기사는 mysql 데이터베이스 명령에 대한 관련 지식을 제공합니다. 일반적으로 사용되는 많은 명령을 컴파일하여 모든 사람에게 도움이 되기를 바랍니다.

1. 데이터베이스에 대한 일반적인 명령
1. 데이터베이스에 연결
mysql -u 사용자 이름 -p 비밀번호
2. 기존 데이터베이스 표시
데이터베이스 표시;
3. 데이터베이스 생성
데이터베이스 생성 sqlname;
4. 데이터베이스 선택
데이터베이스 sqlname 사용
5. 데이터베이스의 테이블 표시(데이터베이스를 먼저 선택)
show tables; 연결 사용자 이름
select version(),user();
7. 데이터베이스 삭제(삭제 시 프롬프트 없이 삭제)
drop 데이터베이스 sqlname;
2. 데이터베이스의 테이블에 대한 명령
1. tables
(1) 구문 :
create table tablename(
field 1 data type field attribute …
field n
);
(2) 참고:
1. 테이블을 생성할 때 예약어와의 충돌을 방지하려면 다음을 사용합니다. ''로 둘러쌉니다
2. 한 줄 주석: #…
여러 줄 주석: /
…
/ 3. 테이블 생성 시 여러 필드를 영문 쉼표로 구분하고, 마지막 줄에는 쉼표를 사용하지 마세요. . (3) 필드 제약 조건 및 속성
1. null이 아닌 제약 조건
null이 아님(필드는 비어 있을 수 없음)
2. 기본 제약 조건 default(기본값 설정)
3. Unique 제약 조건 unique 키( uk)
(설정된 필드의 값은 고유하고 비어 있을 수 있지만 빈 값은 하나만 있을 수 있음) 4. 기본 키 제약 조건기본 키(pk) (테이블 레코드의 고유 식별자로)
5. 외래 키 제약 조건외래 키(fk)
(두 테이블 간의 관계를 설정하는 데 사용되며, 기본 테이블의 어떤 필드가 참조되는지 지정해야 합니다. 데이터베이스의 스토리지 엔진에서 InnoDB는 외래 키를 지원하지만 MyISAM은 외래 키로서의 필드 요구 사항은 기본 테이블의 기본 키(단일 필드 기본 키)입니다.
외래 키 제약 조건 추가:
CONSTRAINT FK_외래 키 이름 FOREIGN KEY(외부 키 필드) 단어 테이블) REFERENCES 관련 테이블 이름(관련 필드). 단어 테이블의 외래 키인 MySQL 데이터베이스 명령의 폭발적인 수집(요약 공유) 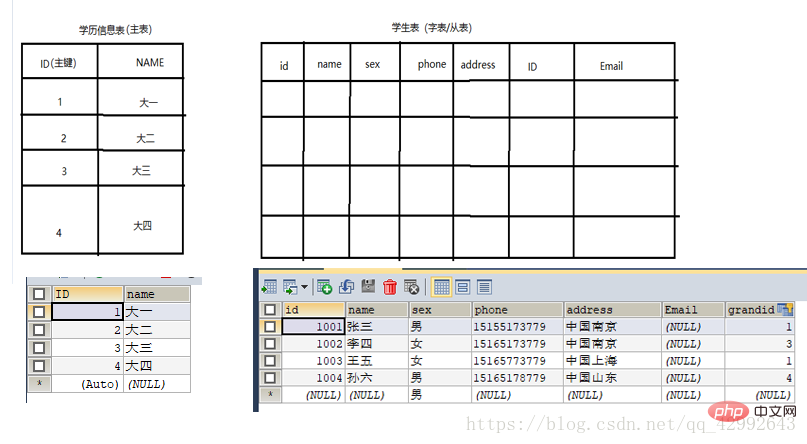
1.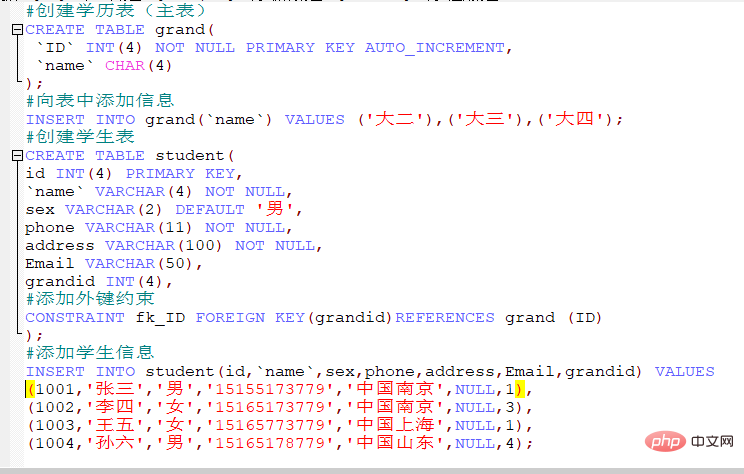 n부터 시작하여 auto_increment=n을 설정합니다.
n부터 시작하여 auto_increment=n을 설정합니다.
2.자동 증가 설정 @@ auto_increment_increment=m, 단계 크기는 m입니다.
3. 다중 필드 설정 기본 키:  기본 키(필드 1, 필드 2...필드 n)
기본 키(필드 1, 필드 2...필드 n)
4. 테이블의 설명/설명 텍스트:)comment="descriptive text";
5. 문자 집합 설정:)charset="Character set";
6. 테이블 구조 보기: describe'table name'/desc table name
7. 데이터베이스 정의 보기: show create Database sqlname;
8. 데이터 테이블 정의 보기: show create table tablename;
9. 기본 스토리지 엔진 보기: show Variable like'storage_engine%';
11. 테이블의 스토리지 엔진 지정: )engine=storage Engine;
10. 테이블 삭제: drop table 'tablename';
11. 현재 날짜 가져오기: now();
12. 테이블 수정: (1) 테이블 이름 수정:
alter table old table name rename new table name;
(2) 필드 추가: alter table table name 추가 필드 이름 데이터 유형...(새 필드 추가)
(3) 필드 수정: alter 테이블 테이블 이름 원래 필드 이름 변경 새 필드 이름 데이터 유형...;
(4) 필드 삭제: alter table table name drop field name
(5) 테이블 생성 후 기본 키 제약 조건 추가:
alter table table name; add Constraint 기본 키 이름 기본 키 테이블 이름(기본 키 필드)
(6) 테이블 생성 후 외래 키 제약 조건을 추가합니다(외래 키로 사용되는 필드는 기본 테이블의 기본 키여야 함(단일 필드)) 기본 키)):
alter 테이블 테이블 이름 추가 제약 조건 외래 키 이름 외래 키(외래 키 필드)는 연결된 테이블 이름(연결된 필드)을 참조합니다.
데이터 삽입
1. 데이터의 단일 행 삽입:
insert 테이블 이름(필드 이름 목록(쉼표로 구분)) 값 (값 목록(쉼표로 구분));
2. 여러 행의 데이터 삽입:
테이블 이름(필드 이름 목록)에 값 (값 list 1), … , (값 목록 n)
3. 쿼리 결과를 새 테이블에 삽입합니다.
create table new table(원본 테이블에서 필드 1, … 선택);查询student表中的id,name,sex,phone数据插入到newstudent表中:
CREATE TABLE newstudent(SELECT id,`name`,sex,phone FROM student);
3. (데이터 수정):
update 테이블 이름 설정 열 이름 = 업데이트 조건이 있는 업데이트 값;修改newstudent表中id=1001的数据名字为tom:
UPDATE newstudent SET `name`='tom' WHERE id=1001;
4. delete Data
삭제 조건이 있는 테이블 이름에서 삭제;
delete가 아닌 전체 데이터를 삭제합니다. 단 하나의 열.
删除newstudent表中名字为tom的数据: DELETE FROM newstudent WHERE `name`='tom';
(2) Truncate table은 데이터를 삭제합니다. truncate table은 테이블의 모든 행을 삭제하지만 테이블 구조, 열, 제약 조건, 인덱스 등은 변경되지 않습니다. 외래 키 제약 조건이 있는 테이블에는 사용할 수 없습니다. 삭제된 데이터는 복구할 수 없습니다.
1.使用select查询 2.分组查询 1.聚合函数: 查询结果: 查询结果: in子查询******not in 子查询 它主要是针对字符型字段的,它的作用是在一个字符型字段列中检索包含对应子串的。 A:% 包含零个或多个字符的任意字符串: 1、LIKE’Mc%’ 将搜索以字母 Mc 开头的所有字符串(如 McBadden)。 exists 子查询 not exists子查询 多表连接查询是通过各个表之间共同列的关联性来查询数据。 两种方法查询结果相同。 将没有成绩的学生成绩查出。 1. 트랜잭션 자동 트랜잭션 제출 끄기: set autocommit=0; 인덱스 생성: 테이블 이름(인덱스를 생성할 컬럼)에 [인덱스 유형] 인덱스 인덱스 이름을 생성합니다.
삭제 조건이 있는 테이블 테이블 이름 자르기;数据查询
select 列名/表达式/函数/常量 from 表名 where 查询条件 order by 排序的列名asc/desc;
(1)查询所有的数据行和列:
select * from 表名;
(2)查询部分行和列:
select 列名… from 表名 where 查询条件;
(3)在查询中使用列的别名:
select 列名 AS 新列名 form 表名 where 查询条件;
计算,合并得到新的列名:
select 列名1+’.’+列名2 AS 新列名 from 表名;
(4)查询空值:
通过is null 或者 is not null 判断列值是否为空查询student表中Email为空的学生姓名:
SELECT `name` FROM student WHERE Email IS NULL;

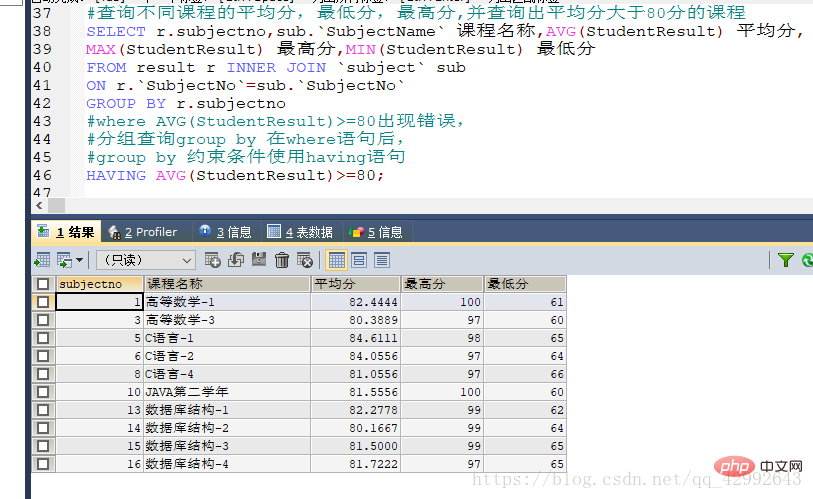
#查询不同课程的平均分,最低分,最高分,并查询出平均分大于80分的课程
SELECT r.subjectno,sub.`SubjectName` 课程名称,AVG(StudentResult) 平均分,
MAX(StudentResult) 最高分,MIN(StudentResult) 最低分
FROM result r INNER JOIN `subject` sub
ON r.`SubjectNo`=sub.`SubjectNo`
GROUP BY r.subjectno
#where AVG(StudentResult)>=80出现错误,
#分组查询group by 在where语句后,
#group by 约束条件使用having语句
HAVING AVG(StudentResult)>=80;
常用函数
(1)AVG (平均值):select avg(列名)from 表名
假设列名为成绩 则查询到的是表中所有成绩的平均值。
(2)count 返回某字段的行数
(3)max 返回某字段的最大数
(4)min 返回某字段的最小值
(5)sum 返回某字段的和。
2.字符串函数:
(1)concat() 连接字符串s1,s2…sn为一个完整的字符串。
(2)insert(s1,p1,n,news)将字符串s1从p1位置开始,n个字符长的字串替换为字符串news。
(3)lower(s)将字符串s中的所有字符改为小写。
(4)upper(s)将字符串s中的所有字符改为大写。
(5)substring(s,num,len)返回字符串s的第num个位置开始长度为len的子字符串。
3.时间日期函数:
(1)获取当前日期:curdate();
(2)获取当前时间:curtime();
(3)获取当前日期和时间:now();
(4)返回日期date为一年中的第几周:week(date);
(5)返回日期date的年份:year(date);
(6)返回时间time的小时值:hour(time);
(7)返回时间time的分钟值:minute(time);
(8)返回日期参数(date1和date2之间相隔的天数):datediff(date1,date2);
(9)计算日期参数date加上n天后的日期:adddate(date,n);
4.数学函数
(1)返回大于或等于数值x的最小整数:ceil(x);
(2)返回小于或等于数值x的最大整数:floor(x);
(3)返回0~1之间的随机数:rand();
order by 子句
order by子句按照一定的顺序排列查询结果,asc升序排列,desc降序排列。
limit子句
显示指定位置指定行数的记录。
select 字段名列表 form 表名 where 约束条件 group by分组的字段名 order by 排序列名 limit 位置偏移量,行数;
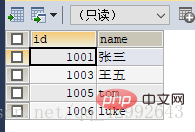
#查询学生信息里gid=1按学号升序排列前四条记录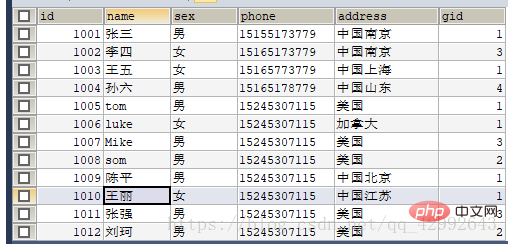
#查询学生信息里gid=1按学号升序排列前四条记录(步长)
SELECT id,`name` FROM `student1` WHERE gid=1 ORDER BY id LIMIT 4;
(查询表里全部信息中gid=1的前四个学生)
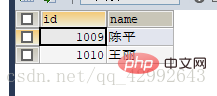
#查询学生信息里gid=1按学号升序排列前四条记录(位置偏移量,步长)
SELECT id,`name` FROM `student1` WHERE gid=1 ORDER BY id LIMIT 4,4;
(查询表中全部信息gid=1前四条以后的全部信息中的前四条学生信息)
模糊查询
使用in关键字可以使父查询匹配子查询返回的多个单字段值。
解决使用比较运算符(=,>等),子查询返回值不唯一错误信息。
like模糊查询
LIKE语句语法格式:select * from 表名 where 字段名 like 对应值(子串)。
2、LIKE’%inger’ 将搜索以字母 inger 结尾的所有字符串(如 Ringer、Stringer)。
3、LIKE’%en%’ 将搜索在任何位置包含字母 en 的所有字符串(如 Bennet、Green、McBadden)。
B:_(下划线) 任何单个字符:LIKE’_heryl’ 将搜索以字母 heryl 结尾的所有六个字母的名称(如 Cheryl、Sheryl)。
C:[ ] 指定范围 ([a-f]) 或集合 ([abcdef]) 中的任何单个字符:、
1,LIKE’[CK]ars[eo]n’ 将搜索下列字符串:Carsen、Karsen、Carson 和 Karson(如 Carson)。
2、LIKE’[M-Z]inger’ 将搜索以字符串 inger 结尾、以从 M 到 Z 的任何单个字母开头的所有名称(如 Ringer)
***D:[^] 不属于指定范围 ([a-f]) 或集合 ([abcdef]) 的任何单个字符:LIKE’M[^c]%’ 将搜索以字母 M 开头,并且第二个字母不是 c 的所有名称(如MacFeather)。
E: 它同于DOS命令中的通配符,代表多个字符:cc代表cc,cBc,cbc,cabdfec等多个字符。
F:?同于DOS命令中的?通配符,代表单个字符 :b?b代表brb,bFb等
G:# 大致同上,不同的是代只能代表单个数字。k#k代表k1k,k8k,k0k 。
F:[!] 排除 它只代表单个字符
下面我们来举例说明一下:
例1,查询name字段中包含有“明”字的。
select * from table1 where name like ‘%明%’
例2,查询name字段中以“李”字开头。
select * from table1 where name like '李’
例3,查询name字段中含有数字的。
select * from table1 where name like ‘%[0-9]%’
例4,查询name字段中含有小写字母的。
select * from table1 where name like ‘%[a-z]%’
例5,查询name字段中不含有数字的。
select * from table1 where name like ‘%[!0-9]%’
可以自定义转移符----》escape’自定义转移符’
distinct------》去除重复项
between*and模糊查询
操作符 BETWEEN … AND 会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
null ,not null查询-- 查询手机号不为null的用户数据
SELECT * from user where phone is not null;
-- 查询手机号为null的用户数据
SELECT * from user where phone is null;
exists子查询用来确认后边的查询是否继续进行
drop table if exists test—>判断是否存在表test,如果存在就删除。
not exists实现取反操作。对不存在对应查询条件的记录。多表连接查询
1.内连接查询
内连接查询根据表中共同的列进行匹配。取两个的表的交集。两个表存在主外键关系是通常使用内连接查询。
内连接使用inner join…on 关键字或者where子句来进行表之间的关联。
inner 可省略 on 用来设置条件。
(1)在where子句中指定连接条件
(2)在from中使用inner join…on关键字#查询学生姓名和成绩
SELECT studentname,studentresult FROM student s,result r
WHERE s.`StudentNo`=r.`StudentNo`
#在from中使用inner join....on关键字
SELECT s.`StudentName`,r.`StudentResult` ,r.`SubjectNo`FROM student s
INNER JOIN result r ON s.`StudentNo`=r.`StudentNo`
2.外连接查询
外连接查询中参与连接的表有主从之分,已主表的每行数据匹配从表的数据列,将符合连接条件的数据直接返回到结果集中,对不符合连接条件的列,将被填上null值再返回到结果集中。
(1)左外连接查询
left join…on 或者left outer join…on关键字进行表之间的关联。SELECT s.`StudentName`,r.`StudentResult` ,r.`SubjectNo`FROM student s
LEFT JOIN result r ON s.`StudentNo`=r.`StudentNo`
(2)右外连接查询
右外连接包含右表中所有的匹配行,右表中有的项在左表中没有对应的项将以null值填充。
right join…on 或right outer join…on关键字进行表之间的关联。
(3)自连接
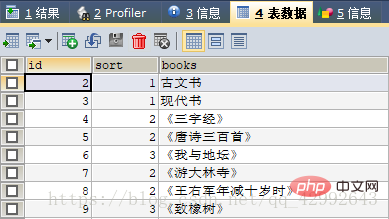
把一个表作为两个表使用。#创建一个表
CREATE TABLE book(
id INT(10),
sort INT(10),
books VARCHAR(10) NOT NULL
);
#插入数据
INSERT INTO book VALUES (2,1,'古文书'),
(3,1,'现代书'),
(4,2,'《三字经》'),
(5,2,'《唐诗三百首》'),
(6,3,'《我与地坛》'),
(7,2,'《游大林寺》'),
(8,2,'《王右军年减十岁时》'),
(9,3,'《致橡树》');
#查询结果为:
#书籍类型 书籍名
#古文书 三字经....
#现代书 我与地坛....
SELECT a.books 书籍类型, b.books 书籍名
FROM book a,book b
WHERE a.id=b.sort;
自连接查询结果: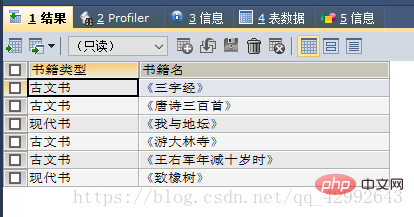
MySQL 트랜잭션, 뷰, 인덱스, 백업 및 복구
트랜잭션은 통합 관리를 위해 일련의 데이터 작업을 전체로 묶는 것을 의미합니다.
모든 명령 전체와 함께 시스템에 생성 요청을 제출하거나 취소합니다.
트랜잭션 속성: 원자성, 일관성, 격리성, 내구성.
myISA 스토리지 엔진은 트랜잭션을 지원하지 않습니다.
(1) 트랜잭션 시작: 트랜잭션 시작/
(2) 트랜잭션 제출: 커밋
(3) 트랜잭션 롤백/실행 취소: 롤백; set autocommit=1;
결과를 다음으로 설정하시겠습니까? ? 인코딩 형식 표시: 이름을 설정하시겠습니까? ? ;
2. 보기 보기는 데이터베이스에 있는 하나 이상의 테이블에 있는 데이터를 보는 방법입니다. 뷰는 하나 이상의 테이블에서 행 또는 열의 하위 집합으로 생성된 가상 테이블입니다. 뷰는 쿼리에서 테이블 필터 역할을 합니다.
(1) 뷰 생성:
또는 테이블 생성 시 컬럼 뒤에 인덱스 유형을 추가합니다.
또는 테이블 변경 테이블 이름 추가 인덱스 인덱스 이름(인덱스 열)
인덱스 보기: 테이블 이름에서 인덱스 표시
1. mysqldump 명령을 사용하여 데이터베이스 백업 mysqldump -u -p 데이터베이스 이름 > 데이터베이스 위치 및 이름 백업
테이블 데이터를 텍스트 파일로 내보내기
쿼리 조건이 있는 테이블 이름에서 데이터베이스 위치 및 이름 백업 선택 ;
2. mysql 명령을 사용하여 데이터베이스 복원
(먼저 새 데이터베이스 생성)
소스 데이터베이스 백업 파일을 복원하려면
New user
#Create local userCREATE USER `user`@`localhost` IDENTIFIED BY '123123';
#사용자는 모든 원격지에 로그인할 수 있습니다. 호스트, 와일드카드 %
CREATE USER `user2`@`123 %` IDENTIFIED BY '123123';
#사용자에게 모든 권한을 승인합니다
GRANT ALL ON mysql.`user` TO `user2`@`123 %`;
#생성된 사용자를 승인합니다
GRANT SELECT ,INSERT ON mysql.`user` TO `user2`@`123%`;
#사용자를 생성할 때 승인
GRANT SELECT,INSERT ON mysql.` user` TO `user_2`@`123%` 식별됨 '123123';
#사용자 user2 삭제(삭제 문을 사용할 때 데이터베이스 전역 권한이 있거나 선택 권한이 있어야 함)
DROP USER `user2`@`123%` ;
DROP USER `user_2`@`123%`;
DROP USER `user`@`localhost`;
#mysqladmin 슈퍼유저 user2 계정의 비밀번호를 변경합니다(mysqladmin 명령은 cmd에서 사용되며, 슈퍼유저 비밀번호 변경)
mysqladmin -u root -p PASSWORD "123456";
#현재 로그인된 사용자의 비밀번호를 변경합니다
SET PASSWORD =PASSWORD("123456");
#비밀번호 변경 다른 사용자
`user2`@`123%`에 대한 비밀번호 설정=PASSWORD("123456");
권장 학습:
mysql 비디오 튜토리얼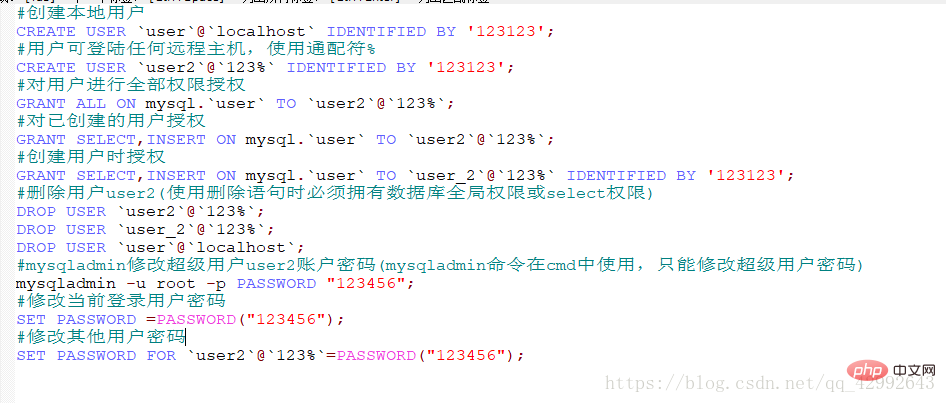
위 내용은 MySQL 데이터베이스 명령의 폭발적인 수집(요약 공유)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undress AI Tool
무료로 이미지를 벗다

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 MySQL에서 모든 데이터베이스를 표시하는 방법
Aug 08, 2025 am 09:50 AM
MySQL에서 모든 데이터베이스를 표시하는 방법
Aug 08, 2025 am 09:50 AM
MySQL에 모든 데이터베이스를 표시하려면 ShowDatabases 명령을 사용해야합니다. 1. MySQL 서버에 로그인 한 후 ShowDatabase를 실행할 수 있습니다. 현재 사용자가 액세스 할 권한이있는 모든 데이터베이스를 나열하도록 명령. 2. Information_Schema, MySQL, Performance_Schema 및 SYS와 같은 시스템 데이터베이스는 기본적으로 존재하지만 권한이 부족한 사용자는이를 볼 수 없을 수 있습니다. 3. SelectSchema_namefrominformation_schema.schemata를 통해 데이터베이스를 쿼리하고 필터링 할 수도 있습니다. 예를 들어, 사용자가 만든 데이터베이스 만 표시하려면 시스템 데이터베이스를 제외합니다. 사용하십시오
 MySQL의 기존 테이블에 기본 키를 추가하는 방법은 무엇입니까?
Aug 12, 2025 am 04:11 AM
MySQL의 기존 테이블에 기본 키를 추가하는 방법은 무엇입니까?
Aug 12, 2025 am 04:11 AM
기존 테이블에 기본 키를 추가하려면 AddPrimarykey 절을 사용하여 Altertable 문을 사용하십시오. 1. 대상 열에 널 값이없고 복제가 없으며 NOTNULL로 정의되어 있는지 확인하십시오. 2. 단일 열차 기본 키 구문은 Altertable 테이블 이름 AddPrimaryKey (열 이름)입니다. 3. 멀티 컬럼 조합 기본 키 구문은 Altertable 테이블 이름 AddPrimaryKey (열 1, 열 2)입니다. 4. 열에서 NULL을 허용하는 경우 먼저 NOTNULL을 설정하도록 수정을 실행해야합니다. 5. 각 테이블에는 하나의 기본 키만이있을 수 있으며 추가하기 전에 기존 기본 키를 삭제해야합니다. 6. 직접 늘려야하는 경우 modify를 사용하여 auto_increment를 설정할 수 있습니다. 작동하기 전에 데이터를 확인하십시오
 일반적인 MySQL 연결 오류 문제를 해결하는 방법은 무엇입니까?
Aug 08, 2025 am 06:44 AM
일반적인 MySQL 연결 오류 문제를 해결하는 방법은 무엇입니까?
Aug 08, 2025 am 06:44 AM
MySQL 서비스가 실행 중인지 확인하고 sudosystemctlstatusmysql을 사용하여 확인하고 시작하십시오. 2. 원격 연결을 허용하고 서비스를 다시 시작하기 위해 BAND-ADDRESS가 0.0.0.0으로 설정되어 있는지 확인하십시오. 3. 3306 포트가 열려 있는지 확인하고 포트를 허용하도록 방화벽 규칙을 확인하고 구성하십시오. 4. "AccessDenied"오류의 경우 사용자 이름, 비밀번호 및 호스트 이름을 확인한 다음 MySQL에 로그인하여 MySQL.user 테이블을 쿼리하여 권한을 확인해야합니다. 필요한 경우 사용자를 생성하거나 업데이트하여 'Your_user'@'%'사용과 같은 승인; 5. Caching_sha2_password로 인해 인증이 손실 된 경우
 MySQL에서 데이터베이스를 백업하는 방법
Aug 11, 2025 am 10:40 AM
MySQL에서 데이터베이스를 백업하는 방법
Aug 11, 2025 am 10:40 AM
mysqldump를 사용하는 것이 MySQL 데이터베이스를 백업하는 가장 일반적이고 효과적인 방법입니다. 테이블 구조 및 데이터가 포함 된 SQL 스크립트를 생성 할 수 있습니다. 1. 기본 구문은 다음과 같습니다. mysqldump-u [user name] -p [database name]> backup_file.sql입니다. 실행 후 암호를 입력하여 백업 파일을 생성하십시오. 2.-databases 옵션으로 여러 데이터베이스를 백업 옵션 : mysqldump-uroot-p-- databasesdb1db2> multip_dbs_backup.sql. 3. all-databases : mysqldump-uroot-p를 사용하여 모든 데이터베이스를 백업합니다
 MySQL 지원 PHP 응용 프로그램에 대한 데이터베이스 인덱싱 전략 (예 : B-Tree, Full-Text)을 설명하십시오.
Aug 13, 2025 pm 02:57 PM
MySQL 지원 PHP 응용 프로그램에 대한 데이터베이스 인덱싱 전략 (예 : B-Tree, Full-Text)을 설명하십시오.
Aug 13, 2025 pm 02:57 PM
b-treeindexesarebestformostphpapplications, asysupportequalityandrangequeries, 분류, andareidealforcolumnsusedinwhere, ororderbyclauses;
 MySQL의 연합과 연합의 차이점은 무엇입니까?
Aug 14, 2025 pm 05:25 PM
MySQL의 연합과 연합의 차이점은 무엇입니까?
Aug 14, 2025 pm 05:25 PM
UnionleMovesDuplicates는 Duplicates; 1.unionperformsDeduplicationBysorting 및 ComcomparingRows, ReturnOnlyUniqueresults, whathitSlowerOnlargedAtasets;
 MySQL에서 테이블을 잠그는 방법
Aug 15, 2025 am 04:04 AM
MySQL에서 테이블을 잠그는 방법
Aug 15, 2025 am 04:04 AM
Locktables를 사용하여 수동으로 테이블을 잠글 수 있습니다. 읽기 잠금은 여러 세션을 읽을 수 있지만 쓸 수는 없습니다. Write Lock은 현재 세션에 대한 독점 읽기 및 쓰기 권한을 제공하며 다른 세션은 읽고 쓸 수 없습니다. 2. 잠금은 현재 연결을위한 것입니다. STARTTRANSACTION 및 기타 명령의 실행은 암시 적으로 잠금을 해제합니다. 잠금 후 잠긴 테이블에만 액세스 할 수 있습니다. 3. MyISAM 테이블 유지 보수 및 데이터 백업과 같은 특정 시나리오에서만 사용하십시오. InnoDB는 성능 문제를 피하기 위해 Select ... ForupDate와 같은 트랜잭션 및로드 레벨 잠금을 사용하는 데 우선 순위를 부여해야합니다. 4. 작업이 완료된 후 잠금 해제 가능성을 명시 적으로 릴리스해야합니다. 그렇지 않으면 자원 막힘이 발생할 수 있습니다.
 MySQL에서 Group_Concat 분리기를 변경하는 방법
Aug 22, 2025 am 10:58 AM
MySQL에서 Group_Concat 분리기를 변경하는 방법
Aug 22, 2025 am 10:58 AM
Group_Concat () 함수에서 분리기 키워드를 사용하여 분리기를 사용자 정의 할 수 있습니다. 1. 분리기를 사용하여 구분 기호와 같은 사용자 정의 분리기를 지정하십시오. '분리기는 세미콜론 및 플러스 공간으로 변경할 수 있습니다. 2. 일반적인 예제에는 파이프 문자 '|', space '', 라인 브레이크 문자 '\ n'또는 사용자 정의 문자열 '->'가 포함됩니다. 3. 분리기는 문자열 리터럴 또는 표현식이어야하며 결과 길이는 Group_Concat_Max_Len 변수에 의해 제한되며 SetSessionGroup_CONCAT_MAX_LEN = 100000으로 조정할 수 있습니다. 4. 분리기는 선택 사항입니다
