

NGINX는 세계에서 가장 바쁜 웹사이트의 40% 이상을 구동하는 고성능 로드 밸런서, 캐시, 웹 서버로 유명하므로
에는 일정한 참고 가치가 있으므로 도움이 필요한 친구들이 참고할 수 있습니다. 모두에게 도움이 되길 바랍니다

Nginx는 커널과 모듈로 구성되어 있는데, 그 중 커널의 디자인은 매우 작고 간단합니다. 완료된 작업도 매우 간단합니다. 구성 파일을 검색하여 클라이언트 요청을 위치 블록에 매핑하기만 하면 됩니다(위치는 URL 일치에 사용되는 Nginx 구성의 지시문입니다). 그러면 이 위치에 구성된 각 지시문이 시작됩니다. 해당 작업을 완료하기 위한 다른 모듈.
Nginx 모듈은 구조적으로 핵심 모듈, 기본 모듈 및 타사 모듈로 구분됩니다.
핵심 모듈:HTTP 모듈, EVENT 모듈 및 MAIL 모듈
기본 모듈:HTTP 액세스 모듈, HTTP FastCGI 모듈, HTTP 프록시 모듈 및 HTTP 재작성 모듈,
타사 모듈:HTTP 업스트림 요청 해시 모듈, 알림 모듈 및 HTTP 액세스 키 모듈.
사용자가 필요에 따라 개발한 모듈은 타사 모듈입니다. Nginx의 기능이 그토록 강력한 것은 바로 수많은 모듈의 지원 때문입니다.
Nginx 모듈은 기능적으로 다음 세 가지 범주로 나뉩니다.
핸들러(프로세서 모듈). 이러한 유형의 모듈은 요청을 직접 처리하고 콘텐츠 출력, 헤더 정보 수정 등의 작업을 수행합니다. 일반적으로 핸들러 프로세서 모듈은 하나만 있을 수 있습니다.
필터(필터 모듈). 이 유형의 모듈은 주로 다른 프로세서 모듈의 콘텐츠 출력을 수정하고 최종적으로 Nginx에 의해 출력됩니다.
프록시(프록시 클래스 모듈). 이러한 모듈은 Nginx의 HTTP 업스트림과 같은 모듈입니다. 이러한 모듈은 주로 FastCGI와 같은 일부 백엔드 서비스와 상호 작용하여 서비스 프록시 및 로드 밸런싱과 같은 기능을 구현합니다.
그림 1-1은 Nginx 모듈의 일반적인 HTTP 요청 및 응답 프로세스를 보여줍니다.
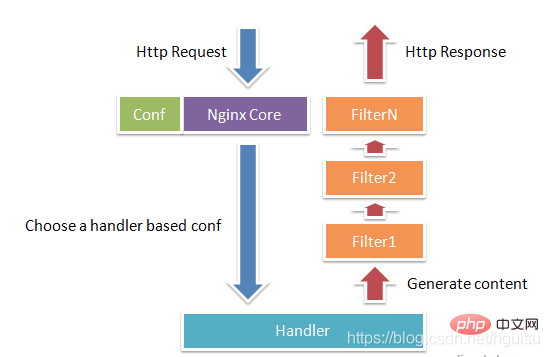
Nginx는 실제로 거의 작업을 수행하지 않습니다. HTTP 요청을 받으면 구성 파일을 검색하여 요청을 위치 블록에 매핑하고 이 위치의 구성은 각 명령이 다른 모듈을 시작합니다. 작업을 완료하기 위해 모듈은 Nginx의 실제 노동자로 간주될 수 있습니다. 일반적으로 한 위치의 명령에는 처리기 모듈과 여러 필터 모듈이 포함됩니다(물론 여러 위치에서 동일한 모듈을 재사용할 수 있음). 핸들러 모듈은 요청을 처리하고 응답 콘텐츠 생성을 완료하는 역할을 담당하며, 필터 모듈은 응답 콘텐츠를 처리합니다.
Nginx 모듈은 Nginx로 직접 컴파일되므로 정적 컴파일 방식입니다. Nginx를 시작하면 Nginx 모듈이 자동으로 로드됩니다. Apache와 달리 먼저 모듈을 so 파일로 컴파일한 다음 로드 여부를 구성 파일에 지정합니다. 구성 파일을 구문 분석할 때 Nginx의 각 모듈은 특정 요청을 처리할 수 있지만 동일한 처리 요청은 하나의 모듈에서만 완료할 수 있습니다.
작업 모드 측면에서 Nginx는 단일 작업자 프로세스와 다중 작업자 프로세스의 두 가지 모드로 구분됩니다. 단일 작업자 프로세스 모드에는 기본 프로세스 외에 단일 스레드인 작업자 프로세스도 있습니다. 다중 작업자 프로세스 모드에서는 각 작업자 프로세스에 여러 스레드가 포함됩니다. Nginx는 기본적으로 단일 작업자 프로세스 모드를 사용합니다.
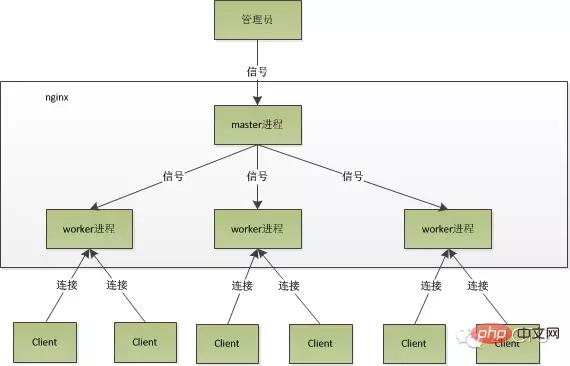
Nginx가 시작된 후에는 마스터 프로세스와 여러 작업자 프로세스가 있습니다.
마스터 프로세스는 주로 작업자 프로세스를 관리하는 데 사용되며 다음 4가지 주요 기능을 포함합니다.
(1) 외부 세계로부터 신호를 받습니다.
(2) 각 작업자 프로세스에 신호를 보냅니다.
(3) Waker 프로세스의 실행 상태를 모니터링합니다.
(4) Waker 프로세스가 종료되면(비정상적인 상황에서) 새 Waker 프로세스가 자동으로 다시 시작됩니다.
사용자 상호 작용 인터페이스:마스터 프로세스는 전체 프로세스 그룹과 사용자 간의 대화형 인터페이스 역할을 하며 프로세스를 모니터링하기도 합니다. 네트워크 이벤트를 처리할 필요가 없으며 비즈니스 실행을 담당하지 않으며 서비스 재시작, 원활한 업그레이드, 로그 파일 교체, 실시간으로 적용되는 구성 파일 등의 기능을 구현하기 위한 작업자 프로세스만 관리합니다.
작업 프로세스 다시 시작:nginx를 제어하려면 kill을 통해 마스터 프로세스에 신호만 보내면 됩니다. 예를 들어, kill -HUP pid는 nginx에게 nginx를 정상적으로 다시 시작하도록 지시합니다. 일반적으로 이 신호를 사용하여 nginx를 다시 시작하거나 구성을 다시 로드하므로 서비스가 중단되지 않습니다.
HUP 신호를 받은 후 마스터 프로세스는 무엇을 합니까?
1) 먼저 신호를 받은 후 마스터 프로세스는 구성 파일을 다시 로드한 다음 새 작업자 프로세스를 시작하고 모든 이전 작업자 프로세스에 신호를 보내 명예롭게 은퇴할 수 있음을 알립니다.
2) 새 작업자가 시작된 후 새 요청을 받기 시작하는 반면, 이전 작업자는 마스터의 신호를 받은 후 새 요청 수신을 중단하고 현재 프로세스에서 처리되지 않은 모든 요청이 요청 처리가 완료된 후 완료됩니다. , 출구.
마스터 프로세스에 직접 신호를 보냅니다. 이는 보다 전통적인 작업 방법입니다. nginx 버전 0.8 이후에는 관리를 용이하게 하기 위해 일련의 명령줄 매개변수가 도입되었습니다.예를 들어 ./nginx -s reload는 nginx를 다시 시작하는 것이고, ./nginx -s stop은 nginx 실행을 중지하는 것입니다.어떻게 하나요? 다시 로드를 예로 들어보겠습니다. 명령을 실행할 때 새 nginx 프로세스가 시작되고 새 nginx 프로세스가 reload 매개변수를 구문 분석한 후 우리의 목적은 구성 파일을 다시 로드하도록 nginx를 제어하는 것임을 알 수 있습니다. 마스터 프로세스에 신호를 보내고 다음 작업은 신호를 마스터 프로세스에 직접 보낸 것과 동일합니다.
기본 네트워크 이벤트는 작업자 프로세스에서 처리됩니다. 여러 작업자 프로세스는 P2P 방식으로 클라이언트의 요청을 놓고 동등하게 경쟁하며 각 프로세스는 서로 독립적입니다. 요청은 하나의 작업자 프로세스에서만 처리할 수 있으며 작업자 프로세스는 다른 프로세스의 요청을 처리할 수 없습니다. 작업자 프로세스 수는 설정할 수 있으며 일반적으로 머신의 CPU 코어 수와 일치하도록 설정합니다. 그 이유는 nginx의 프로세스 모델 및 이벤트 처리 모델과 불가분의 관계입니다.
작업자 프로세스는 동일하며, 각 프로세스는 동일한 요청 처리 기회를 갖습니다. 포트 80에서 http 서비스를 제공하고 연결 요청이 오면 각 프로세스가 연결을 처리할 수 있습니다.
Nginx는 Libevent와 유사하게 비동기 비차단 방식을 사용하여 네트워크 이벤트를 처리합니다. 구체적인 프로세스는 다음과 같습니다.
1) 요청 수신:먼저 각 작업자 프로세스는 마스터 프로세스에서 포크되어 설정됩니다. 마스터 프로세스 소켓을 수신해야 하는 경우(listenfd) 여러 작업자 프로세스를 분기합니다. 모든 작업자 프로세스의 Listenfd는 새 연결이 도착하면 읽을 수 있게 되며 각 작업자 프로세스는 이 소켓(listenfd)을 수락할 수 있습니다. 클라이언트 연결이 도착하면 모든 수락 작업 프로세스에 알림이 전달되지만 한 프로세스만 성공적으로 수락할 수 있고 다른 프로세스는 수락에 실패합니다. 하나의 프로세스만 연결을 처리하도록 하기 위해 Nginx는 공유 잠금 accept_mutex를 제공하여 동시에 하나의 작업 프로세스만 연결을 수락하도록 합니다. 모든 작업자 프로세스는 Listenfd 읽기 이벤트를 등록하기 전에 accept_mutex를 확보합니다. 뮤텍스 잠금을 확보하는 프로세스는 Listenfd 읽기 이벤트를 등록하고 읽기 이벤트에서 accept를 호출하여 연결을 승인합니다.
2) 요청 처리:작업자 프로세스가 연결을 수락하면 요청 읽기, 구문 분석, 요청 처리, 데이터 생성을 시작하여 클라이언트에 반환하고 마지막으로 연결을 끊습니다. 완료요청은 이렇습니다.
요청이 작업자 프로세스에 의해 완전히 처리되고, 하나의 작업자 프로세스에서만 처리되는 것을 볼 수 있습니다. 작업자 프로세스는 동일하며 각 프로세스에는 요청을 처리할 수 있는 동일한 기회가 있습니다.
nginx의 프로세스 모델은 다음 그림으로 표현할 수 있습니다.
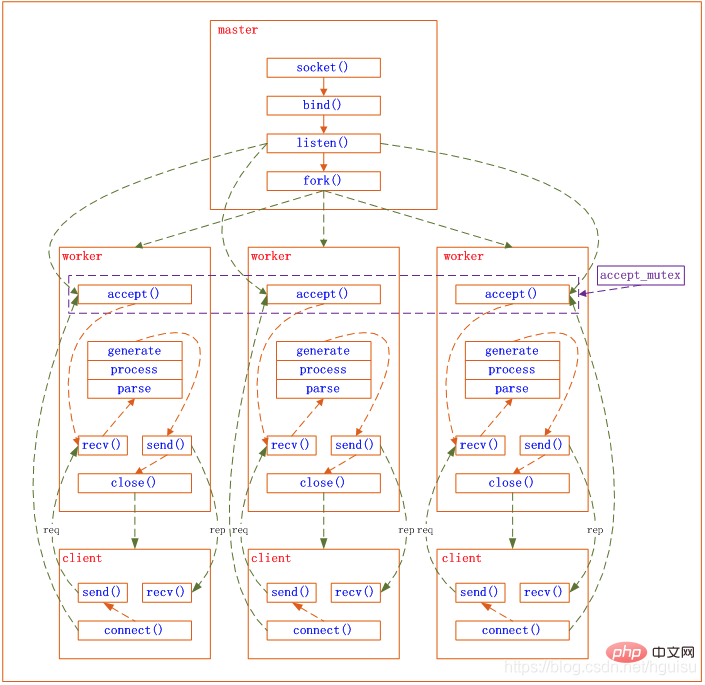
참조 http://mp.weixin.qq.com/s?__biz=MjM5NTg2NTU0Ng==&mid=40788975 7&idx= 3&sn=cfa8a70a5fd2a674a91076f67808273c&scene=23&srcid=0401aeJQEraSG6uvLj69Hfve#rd
각 작업자 프로세스 일반적으로 독립적인 프로세스는 잠글 필요가 없으므로 잠금은 스트랩을 생략하면 오버헤드가 줄어들고 프로그래밍 및 문제 발견 시 훨씬 더 편리해집니다.
두 번째로, 독립적인 프로세스를 사용하면 서로 영향을 미치지 않습니다. 한 프로세스가 종료된 후에도 다른 프로세스는 계속 작동하며 서비스는 중단되지 않으며 마스터 프로세스는 신속하게 새 작업자 프로세스를 시작합니다. 물론 작업자 프로세스가 비정상적으로 종료되면 프로그램에 버그가 있는 것이 틀림없으며 비정상적으로 종료하면 현재 작업자에 대한 모든 요청이 실패하게 되지만 모든 요청에 영향을 미치지는 않으므로 위험이 줄어듭니다.
nginx는 다중 작업자 방법을 사용하여 요청을 처리하지만 각 작업자에는 하나의 기본 스레드만 있습니다. 처리할 수 있는 동시성 수 가능한 한 많은 동시성을 처리할 수 있는 작업자 수는 매우 제한되어 있습니다. 그러면 어떻게 높은 동시성을 달성할 수 있습니까? 아니요, 이것이 nginx의 장점입니다.nginx는 요청을 처리하기 위해 비동기식 및 비차단 방식을 사용합니다즉, nginx는 동시에 수천 개의 요청을 처리할 수 있습니다.작업자 프로세스가 동시에 처리할 수 있는 요청 수는 메모리 크기에 의해서만 제한되며, 아키텍처 설계 측면에서 서로 다른 작업자 프로세스 간의 동시 요청을 처리할 때 동기화 잠금 제한이 거의 없습니다. Nginx의 프로세스 수가 CPU 코어 수와 같을 때(각 작업자 프로세스가 특정 CPU 코어에 바인딩되는 것이 가장 좋음) 프로세스 간 전환 비용이 최소화됩니다. .
그리고 Apache의 일반적인 작업 방식(Apache에도 비동기 비차단 버전이 있지만 자체 모듈 중 일부와 충돌하므로 일반적으로 사용되지 않음),각 프로세스는 하나의 요청만 처리합니다.,그래서,동시성이 수천에 도달하면 동시에 수천 개의프로세스요청을 처리하게 됩니다. 이는프로세스로 인한 메모리 사용량이 매우 큽니다.프로세스의 컨텍스트 전환으로 인해 당연히 성능이 향상될 수 없으며 이러한 오버헤드가 발생합니다. 전혀 의미가 없습니다. ㅋㅋ 자세한 내용은 다음을 참조하세요. libevent 및 libev를 사용하여 네트워크 애플리케이션 성능 향상 - I/O 모델 진화의 역사
원래 지점으로 돌아가서 요청의 전체 프로세스를 살펴보겠습니다. 먼저 요청이 오고 연결됩니다. 설정된 후 데이터가 수신되면 데이터를 수신한 후 다시 데이터를 전송하십시오.层 특히 시스템의 최하위 레벨, 즉 읽기 및 쓰기 이벤트에 대해 읽기 및 쓰기 이벤트가 준비되지 않은 경우에는 Non-Blocking이라고 할 필요가 없으면 준비되지 않은 상태가 됩니다. 통화를 차단하려면 계속하기 전에 이벤트가 준비될 때까지 기다리세요. 차단 호출은 커널에 들어가서 대기하며 CPU는 다른 사람이 사용하게 됩니다. 단일 스레드 작업자의 경우에는 분명히 적합하지 않습니다. 네트워크 이벤트가 더 많으면 모두가 기다리고 있을 때 아무도 CPU를 사용하지 않습니다. 유휴 CPU 사용률은 높은 동시성은 물론, 당연히 속도도 올라갈 수 없습니다. 그런데 프로세스 수를 늘리면 이것이 Apache의 스레딩 모델과 다른 점은 무엇입니까? 불필요한 컨텍스트 전환을 늘리지 않도록 주의하십시오. 따라서 nginx에서는 시스템 호출을 차단하는 것이 가장 금기시됩니다. 차단하지 마세요. 그러면 비차단입니다. 비차단이란 이벤트가 준비되지 않은 경우 이벤트가 아직 준비되지 않았음을 알리기 위해 즉시 EAGAIN으로 돌아가는 것을 의미합니다. 나중에 다시 오세요. 자, 잠시 후 이벤트가 준비될 때까지 다시 이벤트를 확인해 보세요. 이 기간 동안에는 다른 작업을 먼저 하신 후 이벤트가 준비되었는지 확인하시면 됩니다. 더 이상 차단되지는 않지만 수시로 이벤트 상태를 확인해야 더 많은 작업을 수행할 수 있지만 오버헤드가 적지 않습니다.IO 모델 정보: http://blog.csdn.net/hguisu/article/details/7453390
nginx에서 지원하는 이벤트 모델은 다음과 같습니다(nginx wiki):
Nginx는 다음을 지원합니다. 연결 방법(I/O 다중화 방법) 처리 후 이러한 방법은 use 지시어를 통해 지정할 수 있습니다.
epoll의 장점
FD_SETSIZE FD-SETSIZE FD_SETSIZE를 사용하여 많은 수의 소켓 설명자를 엽니다. 2048입니다. 수만 개의 연결을 지원해야 하는 IM 서버에는 분명히 너무 적습니다. 이때 먼저 이 매크로를 수정하고 커널을 다시 컴파일하도록 선택할 수 있지만, 데이터에 따르면 이로 인해 네트워크 효율성이 저하된다는 점도 지적되어 있습니다. 둘째, 다중 프로세스 솔루션(기존 Apache 솔루션)을 선택할 수 있습니다. 하지만 Linux에서 생성되지만 프로세스 비용은 상대적으로 적지만 여전히 무시할 수 없습니다. 또한 프로세스 간 데이터 동기화는 스레드 간 동기화보다 훨씬 덜 효율적이므로 완벽한 솔루션은 아닙니다. 그러나 epoll에는 이러한 제한이 없습니다. 지원하는 FD의 상한은 열 수 있는 최대 파일 수입니다. 이 수는 일반적으로 2048보다 훨씬 큽니다. 예를 들어 1GB 메모리가 있는 시스템에서는 약 100,000입니다. 구체적인 숫자는 다음과 같습니다. cat /proc /sys/fs/file-max를 확인하세요. 일반적으로 이 숫자는 시스템 메모리와 관련이 많습니다.
기존 선택/폴링의 또 다른 치명적인 약점은 큰 소켓 세트가 있는 경우 네트워크 대기 시간으로 인해 소켓 중 일부만 "활성" 상태라는 것입니다. 언제든지 "이지만 선택/폴링에 대한 각 호출은 전체 컬렉션을 선형적으로 스캔하므로 효율성이 선형적으로 감소합니다. 그러나 epoll에는 이 문제가 없으며 "활성" 소켓에서만 작동합니다. 이는 커널 구현에서 epoll이 각 fd의 콜백 함수를 기반으로 구현되기 때문입니다. 그런 다음 "활성" 소켓만 콜백 함수를 적극적으로 호출하고 다른 유휴 상태 소켓은 호출하지 않습니다. 이 시점에서 epoll은 "의사" AIO를 구현합니다. 왜냐하면 이 시점에서 구동력은 os 커널에 있기 때문입니다. 일부 벤치마크에서는 고속 LAN 환경과 같이 모든 소켓이 기본적으로 활성화된 경우 epoll이 select/poll보다 효율적이지 않습니다. 반대로 epoll_ctl을 너무 많이 사용하면 효율성이 약간 떨어집니다. 그러나 유휴 연결을 사용하여 WAN 환경을 시뮬레이션하면 epoll의 효율성은 선택/폴링의 효율성보다 훨씬 높습니다.
이 점은 실제로 epoll의 구체적인 구현과 관련이 있습니다. select이든 poll이든 epoll이든 커널은 FD 메시지를 사용자 공간에 알려야 하는데, 불필요한 메모리 복사를 방지하는 방법이 매우 중요합니다. 이때 epoll은 사용자 공간에서 동일한 메모리를 mmap하여 구현합니다. 핵심. 그리고 저처럼 2.5 커널부터 epoll을 따라오셨다면 수동 mmap 단계를 절대 잊지 않으실 것입니다.
이는 실제로 epoll의 장점이 아니라 전체 Linux 플랫폼의 장점입니다. Linux 플랫폼이 의심스러울 수도 있지만 Linux 플랫폼이 제공하는 커널 미세 조정 기능을 피할 수는 없습니다. 예를 들어, 커널 TCP/IP 프로토콜 스택은 메모리 풀을 사용하여 sk_buff 구조를 관리하고 이 메모리 풀(skb_head_pool)의 크기는 런타임 중에 동적으로 조정될 수 있습니다. echo XXXX>/proc/sys/net/core로 완료됩니다. /hot_list_length. 또 다른 예는 청취 기능의 두 번째 매개변수(TCP가 3방향 핸드셰이크를 완료한 후 패킷 큐의 길이)이며, 이는 플랫폼의 메모리 크기에 따라 동적으로 조정될 수도 있습니다. 우리는 데이터 패킷 수는 많지만 각 데이터 패킷 자체의 크기는 매우 작은 특수 시스템에서 최신 NAPI 네트워크 카드 드라이버 아키텍처를 시도하기도 했습니다.
(epoll 내용, epoll_Interactive Encyclopedia 참조)
작업자 수를 CPU 코어 수로 설정하는 것이 좋습니다. 여기서는 작업자가 많아지면 프로세스가 경쟁하게 된다는 것을 이해하기 쉽습니다. 리소스가 모두 소모되어 불필요한 컨텍스트 전환이 발생합니다. 또한, 멀티 코어 기능을 더 잘 활용하기 위해 nginx는 CPU 선호도 바인딩 옵션을 제공하므로 특정 프로세스를 특정 코어에 바인딩하여 프로세스 전환으로 인해 캐시가 실패하지 않도록 할 수 있습니다. 이와 같은 작은 최적화는 nginx에서 매우 일반적이며 nginx 작성자의 고된 노력을 보여줍니다. 예를 들어 nginx는 4바이트 문자열을 비교할 때 4자를 int 유형으로 변환한 다음 이를 비교하여 CPU 명령어 수를 줄이는 등의 작업을 수행합니다.
nginx의 이벤트 처리 모델을 요약하는 코드:
while (true) { for t in run_tasks: t.handler(); update_time(&now); timeout = ETERNITY; for t in wait_tasks: /* sorted already */ if (t.time <= now) { t.timeout_handler(); } else { timeout = t.time - now; break; } nevents = poll_function(events, timeout); for i in nevents: task t; if (events[i].type == READ) { t.handler = read_handler; } else { /* events[i].type == WRITE */ t.handler = write_handler; } run_tasks_add(t); }
FastCGI는 An입니다. HTTP 서버와 동적 스크립팅 언어 간의 확장 가능한 고속 통신을 위한 인터페이스입니다. 가장 널리 사용되는 HTTP 서버는 Apache, Nginx, lighttpd 등을 포함한 FastCGI를 지원합니다. 동시에 FastCGI는 PHP를 포함한 많은 스크립팅 언어에서도 지원됩니다.
FastCGI는 CGI에서 개발 및 개선되었습니다. 전통적인 CGI 인터페이스 방법의 가장 큰 단점은 성능이 좋지 않다는 것입니다. 왜냐하면 HTTP 서버가 동적 프로그램을 만날 때마다 구문 분석을 수행하기 위해 스크립트 파서를 다시 시작해야 하고 결과가 HTTP 서버로 반환되기 때문입니다. 이는 높은 동시 액세스를 처리할 때 거의 사용할 수 없습니다. 또한 기존의 CGI 인터페이스 방식은 보안성이 취약하여 현재는 거의 사용되지 않습니다.
FastCGI 인터페이스 모드는 HTTP 서버와 스크립트 구문 분석 서버를 분리하고 스크립트 구문 분석 서버에서 하나 이상의 스크립트 구문 분석 데몬을 시작할 수 있는 C/S 구조를 채택합니다. HTTP 서버가 동적 프로그램을 만날 때마다 실행을 위해 FastCGI 프로세스로 직접 전달된 다음 결과가 브라우저로 반환됩니다. 이 방법을 사용하면 HTTP 서버가 정적 요청을 독점적으로 처리하거나 동적 스크립트 서버의 결과를 클라이언트에 반환할 수 있으므로 전체 응용 프로그램 시스템의 성능이 크게 향상됩니다.
Nginx는 외부 프로그램의 직접 호출이나 구문 분석을 지원하지 않습니다. 모든 외부 프로그램(PHP 포함)은 FastCGI 인터페이스를 통해 호출되어야 합니다. FastCGI 인터페이스는 Linux의 소켓입니다(이 소켓은 파일 소켓 또는 IP 소켓일 수 있습니다).
wrapper:CGI 프로그램을 호출하려면 FastCGI 래퍼도 필요합니다(래퍼는 다른 프로그램을 시작하는 데 사용되는 프로그램으로 이해될 수 있음). 이 래퍼는 포트나 파일과 같은 고정 소켓에 바인딩됩니다. 소켓. Nginx가 이 소켓에 CGI 요청을 보내면 래퍼는 FastCGI 인터페이스를 통해 요청을 받은 다음 새 스레드를 포크(파생)하여 스크립트를 처리하고 반환 데이터를 읽습니다. 그런 다음 래퍼는 FastCGI 인터페이스와 고정 소켓을 통해 반환된 데이터를 Nginx에 전달합니다. 마지막으로 Nginx는 반환된 데이터(html 페이지 또는 그림)를 클라이언트에 보냅니다. 이는 그림 1-3과 같이 Nginx+FastCGI의 전체 동작 과정이다.我们 ,
, 먼저 래퍼가 필요합니다. 이 래퍼는 다음을 완료해야 합니다.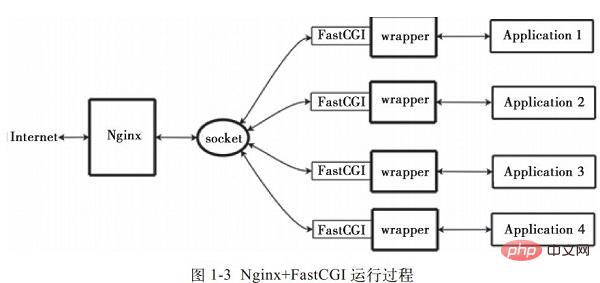 FastCGI(라이브러리)의 기능은 래퍼에 투명하지 않은 호출됩니다.)
FastCGI(라이브러리)의 기능은 래퍼에 투명하지 않은 호출됩니다.)
스레드 예약, 포크 및 종료
통신 응용 프로그램(php)
스폰-fcgi와 PHP-FPM의 유사점과 차이점:1) 스폰-fcgi는 HTTP 서버 lighttpd의 일부이며 독립적인 프로젝트가 되었으며 일반적으로 PHP를 지원하기 위해 lighttpd와 함께 사용됩니다. 그러나 ligttpd의 spwan-fcgi는 메모리 누수를 일으키거나 동시 액세스가 많은 동안 FastCGI를 자동으로 다시 시작할 수도 있습니다. 즉, 이때 사용자가 PHP 스크립트 프로세서에 접근하면 흰색 페이지가 나타날 수 있습니다(즉, PHP를 구문 분석할 수 없거나 오류가 발생함).2) Nginx는 PHP를 구문 분석하기 위해 타사 FastCGI 프로세서를 사용해야 합니다.그래서 실제로
nginx
는 매우 유연하며 모든 타사와 상호 작용할 수 있습니다.
PHP구문 분석을 수행하기 위해 연결할 구문 분석 프로세서(는nginx.conf)에서 쉽게 설정할 수 있습니다.nginx는spwan-fcgi를 사용할 수도 있습니다(는lighttpd와 함께 설치해야 하지만nginx용 포트는 피해야 합니다. 일부 이전blog에는 이 설치 튜토리얼)이지만,spawn-fcgi은 위에서 언급한 것처럼 사용자들에 의해 점차 결함이 발견되었기 때문에nginx+spawn-fcgi조합이 이제 서서히 줄어들고 있습니다.spawn-fcgi의 결함으로 인해 이제 타사(현재 PHP 코어에 추가됨) PHP FastCGI 프로세서 PHP-FPM이 있습니다.spawn-fcgi와 비교하면 다음과 같은 장점이 있습니다.PHP 패치로 개발되었으므로 설치 중에 PHP 소스 코드와 함께 컴파일해야 합니다. 즉, PHP 코어로 컴파일되므로 성능 측면에서도 더 좋습니다. 높은 동시성을 처리할 때 생성됩니다. -fcgi는 적어도 fastcgi 프로세서를 자동으로 다시 시작하지 않습니다. 따라서 PHP를 구문 분석하려면 Nginx+PHP/PHP-FPM 조합을 사용하는 것이 좋습니다.Spawn-FCGI에 비해 PHP-FPM은 더 나은 CPU 및 메모리 제어 기능을 갖추고 있으며 전자는 쉽게 충돌하므로 crontab으로 모니터링해야 하지만 PHP-FPM에는 이러한 문제가 없습니다.FastCGI의 가장 큰 장점은 HTTP 서버에서 동적 언어를 분리하는 것입니다. 따라서 Nginx와 PHP/PHP-FPM은 프론트 엔드 Nginx 서버에 대한 압력을 공유하기 위해 종종 다른 서버에 배포되므로 Nginx는 독점적으로 정적 요청을 처리하고 동적 요청을 전달하며, PHP/PHP-FPM 서버는 PHP 동적 요청을 독점적으로 구문 분석합니다.
PHP-FPM은 FastCGI를 관리하는 관리자입니다. PHP를 설치하고 PHP-FPM을 사용하려면 이전 버전을 설치해야 합니다. php 버전(php5.3.3 이전)에서는 PHP에 PHP-FPM을 패치 형태로 설치해야 하며, PHP는 PHP-FPM 버전과 일관성이 있어야 합니다. 필수)
PHP-FPM은 실제로 FastCGI 프로세스 관리를 통합하도록 설계된 PHP 소스 코드 패치가 PHP 패키지에 통합되었습니다. PHP 소스 코드에 패치해야 하며, PHP를 컴파일하고 설치한 후에 사용할 수 있습니다.
PHP5.3.3에는 php-fpm이 통합되어 있으며 더 이상 타사 패키지가 아닙니다. PHP-FPM은 더 나은 PHP 프로세스 관리 방법을 제공하고, 메모리와 프로세스를 효과적으로 제어할 수 있으며, PHP 구성을 원활하게 다시 로드할 수 있습니다. 이는spawn-fcgi보다 더 많은 장점을 가지고 있어 공식적으로 PHP에 포함됩니다. ./configure에 –enable-fpm 매개변수를 전달하여 PHP-FPM을 켤 수 있습니다.
Fastcgi는 이미 php5.3.5의 핵심에 있으므로 구성 시 --enable-fastcgi를 추가할 필요가 없습니다. php5.2와 같은 이전 버전에는 이 항목을 추가해야 합니다.
Nginx와 PHP-FPM을 설치할 때 구성 정보:
PHP-FPM의 기본 구성 php-fpm.conf:
Listen_address 127.0.0.1:9000 #이것은 PHP의 fastcgi 프로세스 수신을 나타냅니다. IP 주소 및 포트
conf를 열고 다음 명령문을 추가하세요:
location ~ .php US$ 포함 fastcgi_params;
nginx /html$fastcgi_script_name;}Nginx
는 위치 명령을 사용하여 처리를 위해 127.0.0.1:9000의 접미사로 php가 포함된 모든 파일을 전달하며 여기의 IP 주소와 포트는 FastCGI 프로세스가 수신하는 것입니다. IP 주소와 포트에.전체 작업 흐름:
1) FastCGI 프로세스 관리자 php-fpm은 자체적으로 초기화되고 기본 프로세스 php-fpm을 시작하고start_serversCGI 하위 프로세스를 시작합니다. H p 주요 프로세스 PHP-FPM은 주로 FastCGI 하위 프로세스를 관리하고 9000 포트를 모니터링합니다. GFastcgi 대체웹 서버의 연결을 기다리는 중입니다.
2) 클라이언트 요청이 웹 서버 Nginx에 도달하면
Nginx
는 위치 명령을 사용하여 처리를 위해 php 접미사가 127.0.0.1:9000인 모든 파일을 넘겨줍니다. 즉,
Nginx
위치를 통해 처리를 위해 PHP 접미사가 127.0.0.1:9000인 모든 파일을 넘겨주는 지침입니다.
3) FastCGI 프로세스 관리자 PHP-FPM은 하위 프로세스 CGI 인터프리터를 선택하고 연결합니다. 웹 서버는 CGI 환경 변수와 표준 입력을 FastCGI 하위 프로세스로 보냅니다.4) FastCGI 하위 프로세스는 처리가 완료된 후 동일한 연결에서 표준 출력 및 오류 정보를 웹 서버로 반환합니다. FastCGI 하위 프로세스가 연결을 닫으면 요청이 처리됩니다.
5) 그런 다음 FastCGI 하위 프로세스는 FastCGI 프로세스 관리자(WebServer에서 실행)의 다음 연결을 기다리고 처리합니다.
5. Nginx+PHP의 올바른 구성
일반적으로 웹에는 통합된 입구가 있습니다. 모든 PHP 요청을 동일한 파일로 보낸 다음 이 파일의 "REQUEST_URI"를 구문 분석하여 라우팅을 구현합니다.Nginx 구성 파일은 외부에서 내부로의 공통 블록은 "http", "서버", "위치" 등입니다. 기본 상속 관계는 외부에서 내부로, 즉 내부 블록 외부 블록의 값은 자동으로 기본값으로 획득됩니다.
예:
server { listen 80; server_name foo.com; root /path; location / { index index.html index.htm index.php; if (!-e $request_filename) { rewrite . /index.php last; } } location ~ \.php$ { include fastcgi_params; fastcgi_param SCRIPT_FILENAME /path$fastcgi_script_name; fastcgi_pass 127.0.0.1:9000; fastcgi_index index.php; } }
一旦未来需要加入新的「location」,必然会出现重复定义的「index」指令,这是因为多个「location」是平级的关系,不存在继承,此时应该在「server」里定义「index」,借助继承关系,「index」指令在所有的「location」中都能生效。
接下来看看「if」指令,说它是大家误解最深的Nginx指令毫不为过:
if (!-e $request_filename) {
rewrite . /index.php last;
}
很多人喜欢用「if」指令做一系列的检查,不过这实际上是「try_files」指令的职责:
try_files $uri $uri/ /index.php;
除此以外,初学者往往会认为「if」指令是内核级的指令,但是实际上它是rewrite模块的一部分,加上Nginx配置实际上是声明式的,而非过程式的,所以当其和非rewrite模块的指令混用时,结果可能会非你所愿。
include fastcgi_params;
Nginx有两份fastcgi配置文件,分别是「fastcgi_params」和「fastcgi.conf」,它们没有太大的差异,唯一的区别是后者比前者多了一行「SCRIPT_FILENAME」的定义:
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
注意:$document_root 和 $fastcgi_script_name 之间没有 /。
原本Nginx只有「fastcgi_params」,后来发现很多人在定义「SCRIPT_FILENAME」时使用了硬编码的方式,于是为了规范用法便引入了「fastcgi.conf」。
不过这样的话就产生一个疑问:为什么一定要引入一个新的配置文件,而不是修改旧的配置文件?这是因为「fastcgi_param」指令是数组型的,和普通指令相同的是:内层替换外层;和普通指令不同的是:当在同级多次使用的时候,是新增而不是替换。换句话说,如果在同级定义两次「SCRIPT_FILENAME」,那么它们都会被发送到后端,这可能会导致一些潜在的问题,为了避免此类情况,便引入了一个新的配置文件。
此外,我们还需要考虑一个安全问题:在PHP开启「cgi.fix_pathinfo」的情况下,PHP可能会把错误的文件类型当作PHP文件来解析。如果Nginx和PHP安装在同一台服务器上的话,那么最简单的解决方法是用「try_files」指令做一次过滤:
try_files $uri =404;
依照前面的分析,给出一份改良后的版本,是不是比开始的版本清爽了很多:
server { listen 80; server_name foo.com; root /path; index index.html index.htm index.php; location / { try_files $uri $uri/ /index.php; } location ~ \.php$ { try_files $uri =404; include fastcgi.conf; fastcgi_pass 127.0.0.1:9000; } }
1).减小Nginx编译后的文件大小
在编译Nginx时,默认以debug模式进行,而在debug模式下会插入很多跟踪和ASSERT之类的信息,编译完成后,一个Nginx要有好几兆字节。而在编译前取消Nginx的debug模式,编译完成后Nginx只有几百千字节。因此可以在编译之前,修改相关源码,取消debug模式。具体方法如下:
在Nginx源码文件被解压后,找到源码目录下的auto/cc/gcc文件,在其中找到如下几行:
# debug CFLAGS=”$CFLAGS -g”
注释掉或删掉这两行,即可取消debug模式。
2.为特定的CPU指定CPU类型编译优化
在编译Nginx时,默认的GCC编译参数是“-O”,要优化GCC编译,可以使用以下两个参数:
CPU 유형을 확인하려면 다음 명령을 사용할 수 있습니다:#cat /proc/cpuinfo | grep "model name"
TCMalloc의 전체 이름은 Thread-Caching Malloc이며 Google에서 개발한 오픈 소스 도구 google-perftools의 구성원입니다. 표준 glibc 라이브러리의 Malloc과 비교하여 TCMalloc 라이브러리는 메모리 할당이 훨씬 더 효율적이고 빠릅니다. 이는 동시성이 높은 상황에서 서버 성능을 크게 향상시켜 시스템의 부하를 줄입니다. 다음은 Nginx에 TCMalloc 라이브러리 지원을 추가하는 방법에 대한 간략한 소개입니다.
TCMalloc 라이브러리를 설치하려면 libunwind(32비트 운영 체제의 경우 설치가 필요하지 않음)와 google-perftools 두 가지 소프트웨어 패키지를 설치해야 합니다. libunwind 라이브러리는 64 기반 프로그램에 대한 기본 함수 호출 체인 및 함수 호출 레지스터를 제공합니다. -비트 CPU 및 운영 체제. 다음은 Nginx를 최적화하기 위해 TCMalloc을 사용하는 구체적인 작업 프로세스를 설명합니다.
1) libunwind 라이브러리를 설치합니다.
http://download.savannah.gnu.org/releases/libunwind에서 해당 libunwind 버전을 다운로드할 수 있습니다. 여기에서 다운로드한 것은 libunwind-0.99-alpha.tar입니다. gz. 설치 과정은 다음과 같습니다
#tar zxvf libunwind-0.99-alpha.tar.gz
# cd libunwind-0.99-alpha/
#CFLAGS=-fPIC ./configure
#make CFLAGS=-fPIC
#make CFLAGS= -fPIC 설치
2) google-perftools
를 설치합니다. http://google-perftools.googlecode.com에서 해당 google-perftools 버전을 다운로드할 수 있습니다. 여기에서 다운로드한 것은 google-perftools-1.8.tar입니다. .gz. 설치 과정은 다음과 같습니다:
[root@localhost home]#tar zxvf google-perftools-1.8.tar.gz
[root@localhost home]#cd google-perftools-1.8/
[root@localhost google-perftools -1.8] # ./configure
[root@localhost google-perftools-1.8]#make && make install
[root@localhost google-perftools-1.8]#echo "/usr/
local/lib" > ld.so .conf.d/usr_local_lib.conf
[root@localhost google-perftools-1.8]# ldconfig
이제 google-perftools 설치가 완료되었습니다.
3) Nginx 재컴파일
Nginx가 google-perftools를 지원하려면 설치 과정에서 “–with-google_perftools_module” 옵션을 추가하여 Nginx를 재컴파일해야 합니다. 설치 코드는 다음과 같습니다:
[root@localhostnginx-0.7.65]#./configure
>--with-google_perftools_module --with-http_stub_status_module --prefix=/opt/nginx
[root@localhost nginx- 0.7.65 ]#make
[root@localhost nginx-0.7.65]#make install
여기서 Nginx 설치가 완료됩니다.
4) google-perftools
에 대한 스레드 디렉터리를 추가합니다. 스레드 디렉터리를 만들고 파일을 /tmp/tcmalloc에 배치합니다. 작업은 다음과 같습니다:
[root@localhost home]#mkdir /tmp/tcmalloc
[root@localhost home]#chmod 0777 /tmp/tcmalloc
5) Nginx 기본 구성 파일을 수정합니다
Modify nginx.conf 파일에서 pid 줄 아래에 다음 코드를 추가합니다.
#pidlogs/nginx.pid;
google_perftools_profiles /tmp/tcmalloc; 그런 다음 Nginx를 다시 시작하여 google-perftools 로드를 완료합니다.
google-perftools가 정상적으로 로드되었는지 확인하려면 다음 명령을 통해 확인할 수 있습니다.
[root@ localhost home]# lsof -n | grep tcmalloc
nginx 2395 아무도 9w REG 8,8 0 1599440 /tmp/tcmalloc.2395
nginx 2396 아무도 11w REG 8,8 0 1599443 /tmp/tcmalloc.2396
nginx 2397 아무도 13w REG 8,8 0 1599441 /tmp/tcmalloc.2397
nginx 2398 아무도 15w REG 8,8 0 1599442 /tmp/tcmalloc.2398
Nginx 구성 파일에서 Worker_processes 값이 4로 설정되어 있으므로 4개의 Nginx 스레드가 활성화되어 있으며 각 스레드에는 레코드 행이 있습니다. 각 스레드 파일 뒤의 숫자 값은 시작된 Nginx의 pid 값입니다.
이제 TCMalloc을 이용한 Nginx 최적화 작업이 완료되었습니다.
커널 매개변수 최적화는 주로 Linux 시스템의 Nginx 애플리케이션에 대한 시스템 커널 매개변수 최적화입니다.
아래에 참고용으로 최적화 예시가 나와 있습니다.
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_syncookies = 1
net.core.somaxconn = 262144
net.core.netdev_max_backlog = 262144
net.ipv4.tcp_max_orphans = 262144
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_syn_ret ries = 1
net.ipv4.tcp_fin_timeout = 1
net .ipv4.tcp_keepalive_time = 30
위의 커널 매개변수 값을 /etc/sysctl.conf 파일에 추가한 후 다음 명령을 실행하여 적용합니다.
[root@ localhost home]#/sbin/sysctl -p
다음은 예제에서 옵션의 의미를 소개합니다.
TCP 매개변수 설정:
net.ipv4.tcp_max_tw_buckets:옵션은 다음 작업에 사용됩니다. 대기 시간을 설정합니다. 기본값은 180 000 이고 여기서는 6000으로 설정됩니다.
net.ipv4.ip_local_port_range:옵션은 시스템이 열 수 있는 포트 범위를 설정하는 데 사용됩니다. 동시성이 높은 상황에서는그렇지 않으면 포트 번호가 충분하지 않습니다. NGINX가 프록시 역할을 하면 업스트림 서버에 대한 각 연결은 임시 또는 임시 포트를 사용합니다.
net.ipv4.tcp_tw_recycle:옵션은 새로운 TCP 연결에 대해 timewait 빠른 재활용을 활성화하는 데 사용됩니다.
net.ipv4.tcp_syncookies:옵션은 SYN 쿠키를 설정하는 데 사용됩니다. SYN 대기 대기열이 오버플로되면 쿠키가 처리되도록 활성화됩니다.
net.ipv4.tcp_max_orphans:옵션은 사용자 파일 핸들과 연결되지 않은 시스템의 최대 TCP 소켓 수를 설정하는 데 사용됩니다. 이 숫자를 초과하면 분리된 연결이 즉시 재설정되고 경고 메시지가 인쇄됩니다. 이 제한은 단순한 DoS 공격을 방지하기 위한 것입니다. 이 제한에 너무 의존하거나 이 값을 인위적으로 줄일 수도 없습니다. 대부분의 경우 이 값을 늘려야 합니다.
net.ipv4.tcp_max_syn_backlog:옵션은 아직 클라이언트 확인 정보를 받지 못한 연결 요청의 최대값을 기록하는 데 사용됩니다. 이 매개변수의 기본값은 메모리가 128MB인 시스템의 경우 1024이고, 메모리가 작은 시스템의 경우 128입니다.
net.ipv4.tcp_synack_retries 매개변수의 값은 커널이 연결을 포기하기 전에 전송되는 SYN+ACK 패킷 수를 결정합니다.net.ipv4.tcp_syn_retries 옵션은 커널이 연결 설정을 포기하기 전에 전송된 SYN 패킷 수를 나타냅니다.net.ipv4.tcp_fin_timeout 옵션은 소켓이 FIN-WAIT-2 상태로 유지되는 시간을 결정합니다. 기본값은 60초입니다. 이 값을 올바르게 설정하는 것이 매우 중요합니다. 로드가 적은 웹 서버라도 데드 소켓 수가 많아 메모리 오버플로 위험이 있는 경우가 있습니다.
net.ipv4.tcp_syn_retries 옵션은 커널이 연결 설정을 포기하기 전에 전송된 SYN 패킷 수를 나타냅니다.
발신자가 소켓을 닫아야 하는 경우 net.ipv4.tcp_fin_timeout 옵션은 소켓이 FIN-WAIT-2 상태로 유지되는 기간을 결정합니다. 수신 측에서는 오류가 발생하고 연결이 닫히지 않거나 예기치 않게 충돌이 발생할 수도 있습니다.
net.ipv4.tcp_fin_timeout의 기본값은 60초입니다. 로드가 적은 웹 서버라도 데드 소켓이 많아 메모리 오버플로 위험이 있다는 점에 유의해야 합니다. FIN-WAIT-2는 최대 1.5KB의 메모리만 소비할 수 있기 때문에 FIN-WAIT-1보다 덜 위험하지만 수명이 더 깁니다.
net.ipv4.tcp_keepalive_time 옵션은 keepalive가 활성화되었을 때 TCP가 keepalive 메시지를 보내는 빈도를 나타냅니다. 기본값은 2(단위는 시간)입니다.
버퍼 큐:
net.core.somaxconn:옵션의 기본값은 128입니다. 이 매개변수는 시스템이 시작하는 TCP 연결 수를 조정하는 데 사용됩니다. 동시에 동시 요청 수가 많은 경우 기본값을 사용하면 링크 시간 초과 또는 재전송이 발생할 수 있으므로 이 값은 동시 요청 수에 맞춰 조정되어야 합니다.
NGINX에서 허용하는 숫자에 따라 결정됩니다. 기본값은 일반적으로 낮지만 NGINX는 매우 빠르게 연결을 수신하므로 허용 가능하지만 웹 사이트에 트래픽이 많은 경우 이 값을 늘려야 합니다. 커널 로그의 오류 메시지는 이 값이 너무 작다는 것을 알려주며 오류 메시지가 사라질 때까지 값을 늘립니다.
참고: 이 값을 512보다 크게 설정하면 그에 따라 NGINX Listen 명령의 백로그 매개변수도 변경해야 합니다.
net.core.netdev_max_backlog:옵션은 각 네트워크 인터페이스가 커널이 처리할 수 있는 것보다 더 빠른 속도로 패킷을 수신할 때 대기열로 전송이 허용되는 최대 패킷 수를 나타냅니다.
로드가 많은 웹 사이트에서 PHP-FPM을 사용하여 FastCGI를 관리하는 경우 다음 팁이 유용할 수 있습니다.
1) FastCGI 프로세스 수 늘리기
PHP FastCGI를 넣어 자식 프로세스 수를 100개 이상으로 조정하세요. 4G 메모리가 있는 서버에서는 200개까지 사용할 수 있으므로 스트레스 테스트를 통해 최적의 값을 얻는 것이 좋습니다.
2) PHP-FPM 열린 파일 설명자 제한을 늘립니다.
rlimit_files 태그는 열린 파일 설명자에 대한 PHP-FPM 제한을 설정하는 데 사용됩니다. 기본값은 1024입니다. 이 레이블의 값은 Linux 커널의 열린 파일 수와 연결되어야 합니다. 예를 들어 이 값을 65 535로 설정하려면 Linux 명령줄에서 "ulimit -HSn 65536"을 실행해야 합니다. H 그런 다음 加 PHP-FPM을 추가하여 파일 설명자 제한을 엽니다:
# vi /path/to/php-fpm.conf찾기"& lt; value =" rlimit_files "& gt; 1024 & lt;/value & gt;" "1024를 4096 이상으로 변경하세요
.PHP-FPM을 다시 시작하세요.
ulimit -n을
65536이상으로 조정하세요. 이 매개변수를 조정하는 방법은 인터넷의 일부 기사를 참조할 수 있습니다. 수정하려면 명령줄에서 ulimit -n65536을 실행하세요. 수정할 수 없는 경우 /etc/security/limits.conf를 설정하고* hard nofile65536
* Soft nofile65536
3)max_re을 적절하게 늘리십시오. Quests
max_requests 태그는 각 자녀가 닫히기 전에 처리할 수 있는 최대 요청 수를 지정합니다. 기본 설정은 500입니다.
5.nginx.conf 매개변수 최적화
nginx 시작되는 프로세스 수는 일반적으로 총 프로세스 수와 같습니다. 실제로 CPU의 코어는 일반적으로 4개 또는 8개를 사용할 수 있습니다.worker_cpu_affinity
Linux에만 해당됩니다. 이 옵션을 사용하여 작업자 프로세스와 CPU를 바인딩합니다(2.4 커널이 있는 시스템에서는 사용할 수 없음)
CPU가 8개인 경우 할당은 다음과 같습니다.
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000
00100000 01000000 10000000
nginx는 다음과 같은 이유로 여러 작업자 프로세스를 사용할 수 있습니다.
SMP를 사용하기 위해
작업자가 디스크 I/O에서 차단할 때 대기 시간을 줄이기 위해
select()/poll()이
사용될 때 프로세스당 연결 수를 제한하기 위해 이벤트 섹션
의 Worker_processes 및 Worker_connections를 사용하면 maxclients 값을 계산할 수 있습니다: k max_clients = 작업자_프로세스 * 작업자_연결
worker_rlimit_nofile 102400;
각 nginx 프로세스에 대한 최대 열린 파일 설명자 수 구성은 시스템의 단일 프로세스에 대한 열린 파일 수와 일치해야 합니다. 2.6 커널은 65535이므로 nginx가 예약되면 작업자_rlimit_nofile은 65535로 채워져야 합니다. 프로세스에 대한 요청 수가 균형을 이루지 못하여 제한을 초과하면 502 오류가 반환됩니다. 제가 여기에 쓴 내용은 조금 더 큽니다
epoll을 사용하세요
Nginx는 최신 epoll(Linux 2.6 커널)과 kqueue(freebsd) 네트워크 I/O 모델을 사용하는 반면 Apache는 기존 선택 모델을 사용합니다.
많은 연결의 읽기 및 쓰기를 처리하기 위해 Apache에서 채택한 선택 네트워크 I/O 모델은 매우 비효율적입니다. 동시성이 높은 서버에서 I/O 폴링은 가장 시간이 많이 걸리는 작업입니다. 현재 Linux는 액세스되는 Squid와 Memcached 모두 epoll 네트워크 I/O 모델을 사용합니다.
worker_processesNGINX 작업자 프로세스 수(기본값은 1) 대부분의 경우 CPU 코어당 하나의 작업자 프로세스를 실행하는 것이 가장 좋으며 이 명령을 자동으로 설정하는 것이 좋습니다. 때로는 작업자 프로세스가 많은 디스크 I/O를 수행해야 하는 경우와 같이 이 값을 늘리고 싶을 수도 있습니다.
worker_connections 65535;작업자 프로세스당 허용되는 최대 동시 연결 수(Maxclient = work_processes * Worker_connections)
Keepalive 시간 초과
여기에 참고할 공식 문장이 있습니다. :
매개변수 할 수 있다 Line Keep-Alive:
timeout=time은 Mozilla와 Konqueror를 이해합니다. MSIE 자체는
keep-alive 연결을 약 60초 후에 종료합니다.
고객 요청 헤더 버퍼 크기 nginx는 기본적으로 client_header_buffer_size 버퍼를 사용합니다. 헤더 값이 너무 큰 경우에는 Large_client_header_buffers를 사용하여 읽습니다. HTTP 헤더/쿠키가 너무 작게 설정되면 400 오류 nginx 400 잘못된 요청이 보고됩니다요청이 버퍼를 초과하면, HTTP 414 오류(URI가 너무 김)가 보고됩니다. nginx에서 허용하는 가장 긴 HTTP 헤더 크기는 버퍼 중 하나보다 커야 합니다. 그렇지 않으면 400 HTTP 오류(잘못된 요청)가 보고됩니다.
open_file_cache max 102400
사용 필드: http, server, location 이 지시어는 캐시 활성화 여부를 지정합니다. 활성화되면 파일에 대한 다음 정보가 기록됩니다. ·열린 파일 설명자, 크기 정보 및 수정 시간. ·기존 디렉토리 메시지 · 파일 검색 중 오류 메시지 - 이 파일이 없으면 올바르게 읽을 수 없습니다. open_file_cache_errors 지시어 옵션을 참조하세요.
· max - 캐시가 오버플로되는 경우 가장 오래 사용되는 파일인 최대 캐시 수를 지정합니다. (LRU) 제거됨
open_file_cache_errors
open_file_cache_min_uses
구문: open_file_cache_min_uses 숫자 기본값: open_file_cache_min_uses 1 사용 필드: http, 서버, 위치 이 지시어는 잘못된 매개변수에서 특정 시간 범위를 지정합니다. open_file_cache 지시어입니다. 더 큰 값을 사용하면 파일 설명자가 항상 캐시에 열려 있습니다.
open_file_cache_valid
구문: open_file_cache_valid 60 사용되는 필드: http, server, location 이 지시어는 open_file_cache에서 캐시된 항목의 유효한 정보를 확인해야 하는 경우를 지정합니다.
gzip on
gzip_types 텍스트/ 일반 애플리케이션/x- javascript 텍스트/ cssapplication/xml;
gzip_vary on;
캐시 정적 파일:
location ~* ^.+.(swf|gif|png|jpg|js|css)$ {
root /usr/local/ku6 /ktv/show.ku6.com/;
만료 1분;
}
응답 버퍼:
proxy_buffer_size 128k;
Proxy_buffers 32 128k;
Proxy_busy_buffers_size 128k;
Nginx는 해당 서비스를 프록시한 후 또는 우리가 구성한 UpStream 및 위치를 기반으로 해당 파일을 얻습니다. 먼저 파일은 nginx의 메모리 또는 임시 파일 디렉터리로 구문 분석됩니다. , 그러면 nginx가 응답합니다. 그런 다음 Proxy_buffers, Proxy_buffer_size 및 Proxy_busy_buffers_size가 너무 작으면 nginx 구성에 따라 콘텐츠가 임시 파일로 생성되지만 임시 파일의 크기에도 기본값이 있습니다. 따라서 이 4가지 값이 너무 작으면 일부 파일의 일부만 로드됩니다. 따라서,proxy_buffers,proxy_buffer_size,proxy_busy_buffers_size,proxy_temp_file_write_size는 당사 서버 상황에 맞게 적절하게 조정되어야 합니다. 구체적인 매개변수의 세부 사항은 다음과 같습니다.
proxy_buffers 32 128k; 32개의 버퍼 영역이 설정되며, 각 크기는 128k입니다.
proxy_buffer_size 128k, 두 값이 일 때 각 버퍼 영역의 크기는 128k입니다. 불일치, 특정 정보를 찾을 수 없음 위 설정과 일치하는 것이 효과적입니까?
proxy_busy_buffers_size 128k; 사용 중인 버퍼 영역의 크기를 설정하고 최대
proxy_temp_file_write_size 캐시 파일 크기를 제어합니다.
각 요청 회의 기록 CPU 소모 그리고 나/ O 주기. 이러한 영향을 줄이는 한 가지 방법은 액세스 로그를 버퍼링하는 것입니다. NGINX는 각 로그 레코드에 대해 별도의 쓰기 작업을 수행하는 대신 버퍼링을 사용하여 일련의 로그 레코드를 버퍼링하고 단일 작업으로 이를 파일에 함께 씁니다.
액세스 로그 캐시를 활성화하려면 access_log 지시어에 buffer=size 매개변수를 포함해야 합니다. 버퍼가 크기 값에 도달하면 NGINX는 버퍼의 내용을 로그에 기록합니다. 지정된 기간 후에 NGINX가 캐시에 쓰도록 하려면 플러시=시간 매개변수를 포함합니다. 두 매개변수가 모두 설정되면 NGINX는 다음 로그 항목이 버퍼 값을 초과하거나 버퍼의 로그 항목이 설정된 시간 값을 초과할 때 해당 항목을 로그 파일에 기록합니다. 이는 작업자 프로세스가 로그 파일을 다시 열거나 종료할 때도 기록됩니다. 액세스 로깅을 완전히 비활성화하려면 access_log 지시어를 off 매개변수로 설정하세요.
사용자가 너무 많은 리소스를 소비하지 않도록 하고 시스템 성능, 사용자 경험 및 보안에 영향을 미치지 않도록 여러 제한을 설정할 수 있습니다. 관련 지시문은 다음과 같습니다.
limit_conn 및limit_conn_zone:NGINX는 단일 IP 주소에서의 연결과 같은 고객 연결 수에 대한 제한을 허용합니다. 이러한 지시문을 설정하면 단일 사용자가 너무 많은 연결을 열고 사용할 수 있는 것보다 더 많은 리소스를 소비하는 것을 방지할 수 있습니다.
limit_rate:클라이언트에 대한 전송 응답 속도 제한입니다(여러 연결을 여는 각 클라이언트는 더 많은 대역폭을 소비합니다). 이 제한을 설정하면 시스템 과부하를 방지하고 모든 클라이언트에 대해 보다 균일한 서비스 품질을 보장할 수 있습니다.
limit_req 및limit_req_zone:limit_rate와 동일한 기능을 갖는 NGINX 처리 요청에 대한 속도 제한입니다. 너무 느린 프로그램이 애플리케이션 요청(예: DDoS 공격)을 덮어쓰는 것을 방지하기 위해 사용자 제한 요청 비율에 합리적인 값을 설정하면 특히 로그인 페이지의 보안을 향상시킬 수 있습니다.
max_conns: 업스트림 구성 블록의 서버 명령 매개변수입니다. 업스트림 서버 그룹에서 단일 서버가 허용할 수 있는 최대 동시성 수입니다. 업스트림 서버의 과부하를 방지하려면 이 제한을 사용하십시오. 값을 0(기본값)으로 설정하면 제한이 없음을 의미합니다.queue(NGINX Plus):
최대 max_cons 제한을 초과하는 업스트림 서버의 요청 수를 저장하기 위해 대기열을 만듭니다. 이 지시문은 대기 중인 요청의 최대 수를 설정하고 선택적으로 오류를 반환하기 전 최대 대기 시간을 설정합니다(기본값은 60초). 이 지시문을 생략하면 요청이 대기열에 추가되지 않습니다.
일반적인 이유:
1. 백엔드 서비스가 중단되면 직접 502(nginx 오류 로그: connect() 실패(111: 연결이 거부됨))2. 백엔드 서비스가 다시 시작됩니다
예: 백엔드 서비스 교체 이를 끄고 nginx의 백엔드 인터페이스에 요청을 보내면 nginx 로그에서 502 오류를 볼 수 있습니다.
nginx+php에서 502가 발생하면 오류 분석:
php-cgi 프로세스 수가 충분하지 않거나, php 실행 시간이 길거나(mysql이 느림), php-cgi 프로세스가 종료되면 502 오류가 발생합니다. 발생
일반적으로 Nginx 502 Bad Gateway는 php-fpm.conf 설정과 관련이 있고, Nginx 504 Gateway Time-out은 nginx.conf 설정과 관련이 있습니다.
1) 현재 PHP FastCGI 프로세스 수가 몇 개인지 확인하세요. 충분함:
netstat -anpo | grep "php-cgi" | wc -l
사용된 "FastCGI 프로세스 수"가 기본 "FastCGI 프로세스 수"에 가깝다면 이는 "FastCGI 프로세스 수"를 의미합니다. FastCGI 프로세스"로는 충분하지 않으며 늘려야 합니다.
2) 일부 PHP 프로그램의 실행 시간은 Nginx의 대기 시간을 초과합니다. nginx.conf 구성 파일에서 FastCGI의 시간 초과 시간을 적절하게 늘릴 수 있습니다. 예:
http {
...
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
......
}
nginx서버가 게이트웨이로 작동하거나 프록시가 수행을 시도합니다. 요청, 업스트림 서버(HTTP, FTP, LDAP와 같은 URI로 식별되는 서버)로부터 적시에 응답을 받지 못했습니다.일반적인 이유:
이 인터페이스는 시간이 너무 많이 걸립니다. 백엔드 서비스가 요청을 수신하고 실행을 시작하지만 설정된 시간 내에 nginx에 데이터를 반환하지 못합니다.백엔드 서버의 전체 부하가 너무 높습니다. . 요청을 받은 후, 바쁜 스레드로 인해 요청에 대한 인터페이스를 정렬할 수 없어 설정된 시간에 nginx에 데이터를 반환하지 못했습니다
클라이언트 _max_body_size: 지시문은 요청 헤더의 Content-Length 필드에 나타나는 클라이언트 연결에 허용되는 최대 요청 엔터티 크기를 지정합니다. 클라이언트는 "요청 엔터티가 너무 큼"(413) 오류를 받게 됩니다. 브라우저는 이 오류를 표시하는 방법을 알지 못합니다.
php.ini에서
post_max_size 및 upload_max_filesize를 늘리세요헤더가 다음과 같은 경우 프록시는 nginx에서 클라이언트로 사용됩니다. 너무 커서 기본 1k를 초과하면 위의 업스트림에서 너무 큰 헤더를 전송하게 됩니다(직설적으로 말하면). 이는 nginx가 백엔드 서버에 외부 요청을 보내는 데 의해 발생하며 백엔드 서버에서 반환된 헤더는 다음과 같습니다. nginx가 처리하기에는 너무 큽니다.
#다음 3줄을 추가하세요.
Proxy_buffers 32 32k;
Proxy_set_header 호스트 $host;Proxy_set_header X -Real-IP $remote_addr;proxy_set_head erX- Forwarded-For $proxy_add_x_forwarded_for;
}
}
2) nginx+PHPcgi
인 경우 오류는 업스트림에 있습니다: "fastcgi://127.0.0.1:9000 ". 그냥
더 추가하세요:
fastcgi_buffers 4 128k;
server { server_name ddd.com;index index.html index.htm index.php;
client_header_buffer_size 128k;Large_client_header_buffers 4 128k;
Proxy_buffer_size 64k;Proxy_buffers 8 64k;fastcgi_buffer_size 128k;
위치 / {
ㅋㅋㅋ 종종 역방향 프록시로 사용되며 PHP 작동을 매우 잘 지원할 수도 있습니다. 80sec에서는 기본적으로 서버가 PHP의 모든 유형의 파일을 잘못 구문 분석할 수 있으며 이로 인해 악의적인 공격자가 PHP 서버를 지원하는 nginx를 손상시킬 수 있음을 발견했습니다.
취약점 분석: nginx는 기본적으로 cgi 모드에서 실행되는 PHP를 지원합니다. 예를 들어 구성 파일에서
location ~ .php$ { root html;
fastcgi_pass 127.0을 사용할 수 있습니다. 0.1:9000 ; fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name; include fastcgi_params;
}
/80sec.jpg/80sec.php
위치 명령 후 요청은 처리를 위해 백엔드 fastcgi로 전달되고 nginx는 이에 대한 환경 변수 SCRIPT_FILENAME을 다음과 같이 설정합니다./scripts /80sec.jpg/80sec.phplocation ~ .php$ {
root html;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
include fastcgi_params;
}
的方式支持对php的解析,location对请求进行选择的时候会使用URI环境变量进行选择,其中传递到后端Fastcgi的关键变量SCRIPT_FILENAME由nginx生成的$fastcgi_script_name决定,而通过分析可以看到$fastcgi_script_name是直接由URI环境变量控制的,这里就是产生问题的点。而为了较好的支持PATH_INFO的提取,在PHP的配置选项里存在cgi.fix_pathinfo选项,其目的是为了从SCRIPT_FILENAME里取出真正的脚本名。
那么假设存在一个http://www.80sec.com/80sec.jpg,我们以如下的方式去访问
http://www.80sec.com/80sec.jpg/80sec.php
将会得到一个URI/80sec.jpg/80sec.php
经过location指令,该请求将会交给后端的fastcgi处理,nginx为其设置环境变量SCRIPT_FILENAME,内容为/scripts/80sec.jpg/80sec.php
而在其他的webserver如lighttpd当中,我们发现其中的SCRIPT_FILENAME被正确的设置为/scripts/80sec.jpg
所以不存在此问题。
后端的fastcgi在接受到该选项时,会根据fix_pathinfo配置决定是否对SCRIPT_FILENAME进行额外的处理,一般情况下如果不对fix_pathinfo进行设置将影响使用PATH_INFO进行路由选择的应用,所以该选项一般配置开启。Php通过该选项之后将查找其中真正的脚本文件名字,查找的方式也是查看文件是否存在,这个时候将分离出SCRIPT_FILENAME和PATH_INFO分别为/scripts/80sec.jpg和80sec.php
最后,以/scripts/80sec.jpg作为此次请求需要执行的脚本,攻击者就可以实现让nginx以php来解析任何类型的文件了。
POC: 访问一个nginx来支持php的站点,在一个任何资源的文件如robots.txt后面加上/80sec.php,这个时候你可以看到如下的区别:
访问http://www.80sec.com/robots.txtHTTP/1.1 200 OK
Server: nginx/0.6.32
Date: Thu, 20 May 2010 10:05:30 GMT
Content-Type: text/plain
Content-Length: 18
Last-Modified: Thu, 20 May 2010 06:26:34 GMT
Connection: keep-alive
Keep-Alive: timeout=20
Accept-Ranges: bytes
访问访问http://www.80sec.com/robots.txt/80sec.phpHTTP/1.1 200 OK
Server: nginx/0.6.32
Date: Thu, 20 May 2010 10:06:49 GMT
Content-Type: text/html
Transfer-Encoding: chunked
Connection: keep-alive
Keep-Alive: timeout=20
X-Powered-By: PHP/5.2.6
其中的Content-Type的变化说明了后端负责解析的变化,该站点就可能存在漏洞。
漏洞厂商:http://www.nginx.org
解决方案:
我们已经尝试联系官方,但是此前你可以通过以下的方式来减少损失关闭cgi.fix_pathinfo为0
或者if ( $fastcgi_script_name ~ ..*/.*php ) {의 내용 lighttpd와 같은 다른 웹서버에서는 SCRIPT_FILENAME이
return 403;
}
/scripts/80sec.jpg로 올바르게 설정되어 있음을 발견했습니다. >
그래서 존재하지 않는 문제입니다.
백엔드 fastcgi가 이 옵션을 받으면 fix_pathinfo 구성을 기반으로 SCRIPT_FILENAME에 대한 추가 처리를 수행할지 여부를 결정합니다. 일반적으로 fix_pathinfo가 설정되지 않으면 라우팅에 PATH_INFO를 사용하는 애플리케이션에 영향을 미치므로 이 옵션은 일반적으로 다음과 같이 구성됩니다. 켜져 있습니다. 이 옵션을 전달하면 Php는 실제 스크립트 파일 이름을 검색합니다. 이때 파일이 존재하는지 확인하는 방법도 있습니다. 이때 SCRIPT_FILENAME과 PATH_INFO는/scripts/80sec.jpg 및 80sec로 구분됩니다. .php
HTTP/1.1 200 OK 서버: nginx/0.6.32 날짜: 2010년 5월 20일 목요일 10:05:30 GMT 콘텐츠 유형: text/plain 콘텐츠 길이: 18 최종 수정: 2010년 5월 20일 목요일 06:26:34 GMT 연결: keep-alive Keep-Alive: timeout=20 Accept-Ranges: byteshttp:// /www를 방문하세요. 80sec.com/robots.txt/80sec.php
HTTP/1.1 200 OK 서버: nginx/0.6.32 날짜: 2010년 5월 20일 목요일 10:06:49 GMT 콘텐츠 유형: text/ html Transfer-Encoding: Chunked 연결: keep-alive Keep-Alive: timeout=20 X-Powered-By: PHP/5.2.6콘텐츠 유형 변경에 대한 설명 백엔드가 담당하는 경우 변경 사항을 구문 분석하면 사이트가 취약해질 수 있습니다. 취약점 공급업체: http://www.nginx.org해결책: 공식 담당자에게 연락을 시도했지만 그 전에 다음 방법을 통해 손실을 줄일 수 있습니다
cgi.fix_pathinfo를 닫습니다. 0 또는 if ( $fastcgi_script_name ~ ..*/.*php ) { return 403; }PS: 감사합니다 laruence Daniel 분석 과정에서 도움을 주세요
위 내용은 'Xiaobai'는 Nginx의 모듈과 작동 원리를 이해하도록 안내합니다! ! !의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!































![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



