


client=> ··· => 실행 엔진에서 실행됩니다. 이 프로세스는 먼저 찾아서 업데이트해야 합니다. UPDATE 프로세스를 이해하기 위해 먼저 Innodb의 아키텍처 모델을 살펴보겠습니다. 이전 MYSQL 공식 InnoDB 아키텍처 다이어그램: 

[Connection Pool] (授权、线程复用、连接限制、内存检测等) => [SQL Interface] (DML、DDL、Views等) [Parser] (Query Translation、Object privilege) [Optimizer] (Access Paths、 统计分析) [Caches & Buffers] => [Pluggable Storage Engines]复制代码
]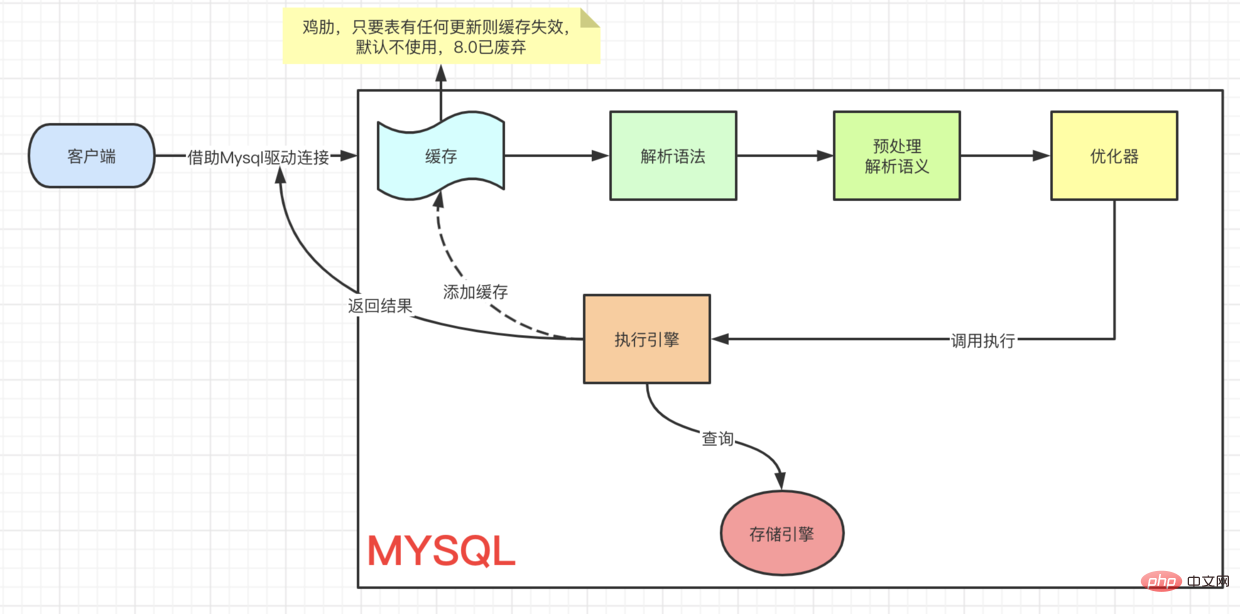
페이지를 가져와서 버퍼 풀로 이동하여 현재 페이지를 쿼리합니다. code> 버퍼 풀에 있는지 여부입니다. 그렇다면 직접 받아보세요. 업데이트 작업인 경우 버퍼의 값이 직접 수정됩니다. 이때 버퍼 풀에 있는 데이터는 실제로 우리 디스크에 저장된 데이터와 일치하지 않는데, 이를 더티 페이지라고 합니다. 때때로 Innodb 스토리지 엔진은 더티 페이지 데이터를 디스크에 플러시합니다. 일반적으로 데이터 조각을 업데이트할 때 수정을 위해 데이터를 버퍼로 읽어온 다음 다시 디스크에 써서 디스크 IO 작업을 완료해야 합니다. update의 작업 성능을 향상시키기 위해 Mysql은 메모리에서 최적화되었습니다. 아키텍처 다이어그램의 버퍼 풀에는 다음과 같은 영역이 있는 것을 볼 수 있습니다. 버퍼 변경. 이름에서 알 수 있듯이 변경된 데이터에 대한 버퍼를 생성합니다. 고유 인덱스 없이 데이터를 업데이트하면 수정된 데이터가 변경 버퍼에 직접 배치됩니다. code> code> 후 병합 작업을 통해 업데이트를 완료하여 디스크 드롭의 IO 작업을 줄입니다. 客户端 => ··· => 执行引擎 是一样的流程,都要先查到这条数据,然后再去更新。要想理解 UPDATE 流程我们先来看看,Innodb的架构模型。
上一张 MYSQL 官方InnoDB架构图:
连接器(JDBC、ODBC等) =>
[MYSQL 内部
rrreee]
=> [File]
这里有个关键点,当我们去查询数据时候会先 拿着我们当前查询的 page 去 buffer pool 中查询 当前page是否在缓冲池中。如果在,则直接获取。
而如果是update操作时,则会直接修改 Buffer中的值。这个时候,buffer pool中的数据就和我们磁盘中实际存储的数据不一致了,称为脏页。每隔一段时间,Innodb存储引擎就会把脏页数据刷入磁盘。一般来说当更新一条数据,我们需要将数据给读取到buffer中修改,然后写回磁盘,完成一次 落盘IO 操作。
为了提高update的操作性能,Mysql在内存中做了优化,可以看到,在架构图的缓冲池中有一块区域叫做:change buffer。顾名思义,给change后的数据,做buffer的,当更新一个没有 unique index 的数据时,直接将修改的数据放到 change buffer,然后通过 merge 操作完成更新,从而减少了那一次 落盘的IO 操作。
没有唯一索引的数据更新时,为什么必须要没有唯一索引的数据更新时才能直接放入change buffer呢?如果是有唯一约束的字段,我们在更新数据后,可能更新的数据和已经存在的数据有重复,所以只能从磁盘中把所有数据读出来比对才能确定唯一性。写多读少 的时候,就可以通过 增加 innodb_change_buffer_max_size 来调整 change buffer在buffer pool 中所占的比例,默认25(即:25%)有四种情况:
redo log写满的时候,merge到磁盘谈到redo,就要谈到innodb的 crash safe,使用 WAL 的方式实现(write Ahead Logging,在写之前先记录日志)
这样就可以在,当数据库崩溃的后,直接从 redo log中恢复数据,保证数据的正确性
redo log 默认存储在两个文件中 ib_logfile0 ib_logfile1,这两个文件都是固定大小的。为什么需要固定大小?
这是因为redo log的 顺序读取
고유 인덱스가 없는 데이터가 업데이트될 때, 왜 고유 인덱스가 없는 데이터가 업데이트될 때여야 합니까? 변경 버퍼에 직접 넣기 전에 어떻게 되나요? 고유 제약 조건이 있는 필드인 경우 데이터를 업데이트한 후 업데이트된 데이터가 기존 데이터와 중복될 수 있으므로 디스크에서 모든 데이터를 읽고 비교를 사용하여 고유성을 확인합니다.
따라서 데이터가 작성 횟수는 늘어나고 읽기 횟수는 줄어들 경우 innodb_change_buffer_max_size 비율을 늘려 버퍼의 <code>변경 버퍼를 조정할 수 있습니다. 풀의, 기본값은 25(예: 25%)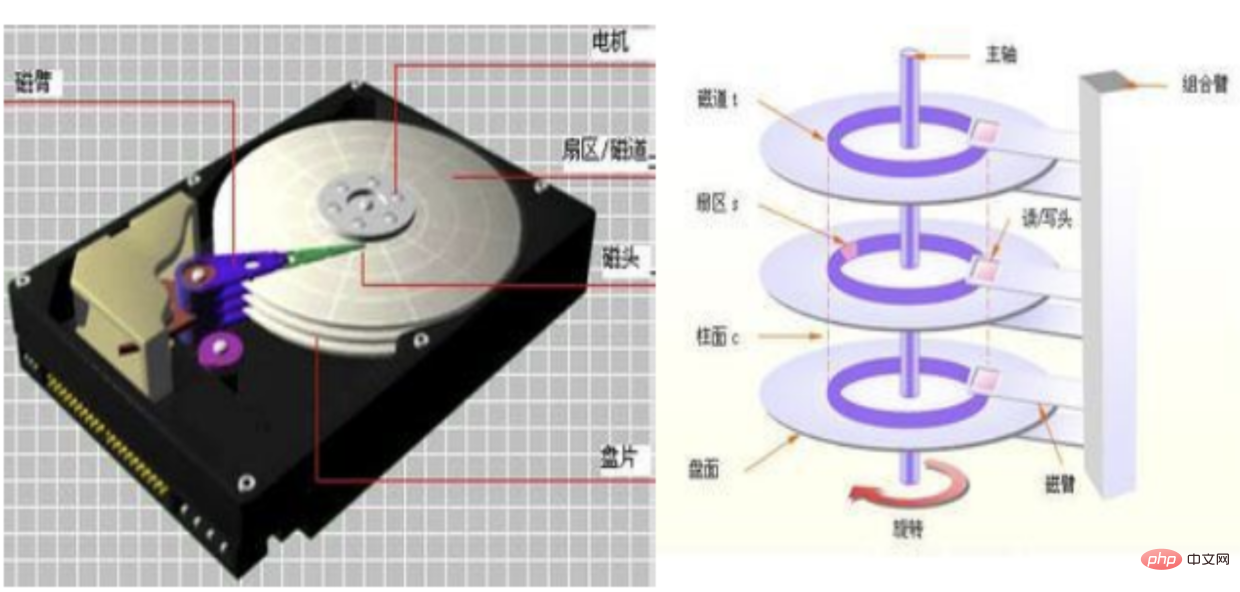
네 가지 상황이 있습니다:
다른 접속자가 있으면 현재 페이지의 데이터가 디스크에 병합됩니다redo 로그 쓰기 가득 차면 디스크에 병합crash safe에 대해 이야기해야 합니다. WAL 구현(Ahead Logging 작성, 쓰기 전에 로그 기록)🎜🎜이렇게 하면 데이터베이스가 충돌할 때 redo 로그에서 직접 데이터를 복원하여 데이터의 정확성을 보장할 수 있습니다🎜 🎜redo 로그 기본적으로 ib_logfile0 ib_logfile1 두 파일에 저장되며, 두 파일 모두 고정 크기입니다. 고정된 크기가 필요한 이유는 무엇입니까? 🎜🎜이것은 redo log의 순차읽기 기능 때문인데, 이는 반드시 연속적인 저장공간이어야 합니다🎜🎜2. 무작위 읽기 및 쓰기와 순차적 읽기 및 쓰기🎜🎜 사진 보기 🎜🎜🎜 일반적으로 데이터는 디스크에 흩어져 있습니다. 🎜🎜기계식 하드 디스크의 읽기 및 쓰기 순서는 다음과 같습니다. 🎜🎜🎜트랙 찾기🎜🎜해당 섹터로 회전을 기다리는 중🎜🎜읽기 및 쓰기 시작 🎜🎜🎜 솔리드 스테이트 읽기 및 쓰기: 🎜사실 기계식이든 고체든 저장 시에는 를 사용합니다. 파일 시스템과 디스크를 처리하는 방법에는 두 가지가 있습니다. 무작위 읽기 및 쓰기 및 순차 읽기 및 쓰기文件系统与磁盘打交道的,而他们打交道的方式就有两个。随机读写和顺序读写
块(默认 1block=8扇区=4K)一串连续的块中,这样读取速度就大大提升了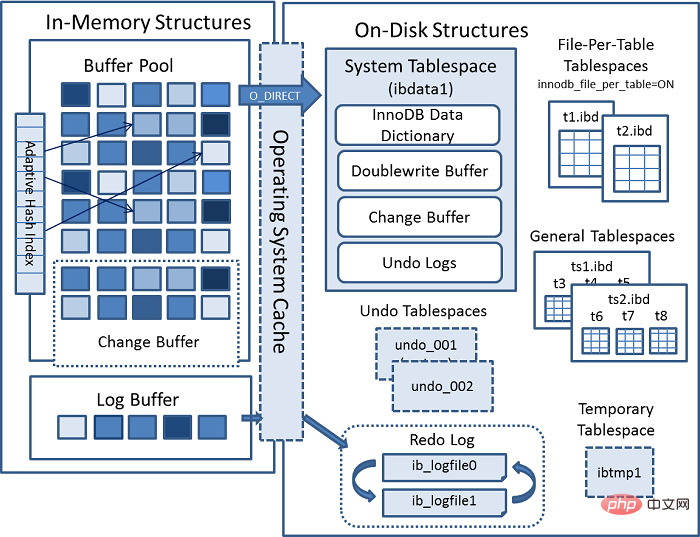
看到buffer pool中的Log Buffer,其就是用来写 redo log 之前存在的缓冲区
在这里,redo log具体的执行策略有三种:
Log Buffer,只需要每秒写redo log 磁盘数据一次,性能高,但会造成数据 1s 内的一致性问题。适用于强实时性,弱一致性,比如评论区评论
Log Buffer,同时写入磁盘,性能最差,一致性最高。 适用于弱实时性,强一致性,比如支付场景
Log Buffer,同时写到os buffer(其会每秒调用 fsync 将数据刷入磁盘),性能好,安全性也高。这个是实时性适中 一致性适中的,比如订单类。我们通过innodb_flush_log_at_trx_commit就可以设置执行策略。默认为 1

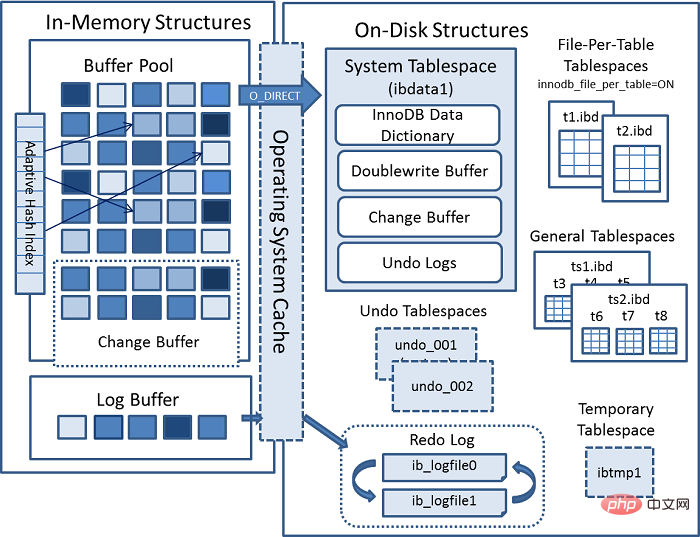
自适应Hash索引主要用于加快查询 页。在查询时,Innodb通过监视索引搜索的机制来判断当前查询是否能走Hash索引。比如LIKE运算符和% 通配符就不能走。存储在一个叫ibdata1的文件中,其中包含:
Buffer Pool写入数据页时,不是直接写入到文件,而是先写入到这个区域。这样做的好处的是,一但操作系统,文件系统或者mysql挂掉,可以直接从这个Buffer中获取数据。每一张表都有一张 .ibd 的文件,存储数据和索引。
每表文件表空间可以使得 ALTER TABLE与 TRUNCATE TABLE 性能得到很好的提升。比如 ALTER TABLE,相较于对驻留在共享表空间中的表,在修改表时,会进行表复制操作,这可能会增加表空间占用的磁盘空间量。此类操作可能需要与表中的数据以及索引一样多的额外空间。该空间不会像每表文件表空间
블록에 분산됩니다(기본값 1block= 8 섹터 =4K)일련의 연속된 블록으로 분산되어 읽기 속도가 크게 향상됩니다
버퍼 풀의 로그 버퍼를 참조하세요. , 및 its 리두 로그 이전에 존재했던 버퍼를 작성하는 데 사용됩니다🎜🎜여기서 리두 로그에 대한 세 가지 구체적인 실행 전략이 있습니다:🎜로그 버퍼를 작성할 필요가 없습니다. code>, just 각각 Redo 로그 디스크 데이터는 1초에 한 번씩 기록되므로 성능은 좋지만 1초 이내에 데이터 일관성 문제가 발생합니다. <code>댓글 영역의 댓글과 같은 강한 실시간, 약한 일관성에 적용 가능🎜🎜로그 버퍼 쓰기 동시에 디스크에 쓰기 성능은 최악이고 일관성은 가장 높습니다. 결제 시나리오🎜🎜와 같은 약한 실시간, 강력한 일관성에 적용 가능 로그 버퍼 쓰기 및 쓰기 os 버퍼(매초 fsync를 호출하여 데이터를 디스크에 플러시)는 우수한 성능과 높은 보안을 제공합니다. 이는 주문 유형과 같은 보통 실시간 보통 일관성입니다. 🎜🎜🎜innodb_flush_log_at_trx_commit을 통해 실행 정책을 설정할 수 있습니다. 기본값은 1🎜🎜🎜🎜가속을 위한 버퍼 풀 Read🎜🎜Change Buffer는 고유하지 않은 인덱스 없이 쓰기 속도를 높이는 데 사용됩니다.🎜🎜Log Buffer는 redo 로그 쓰기 속도를 높이는 데 사용됩니다.🎜🎜Adaptive Hash Index는 주로 page . 쿼리할 때 Innodb는 인덱스 검색 메커니즘을 모니터링하여 현재 쿼리가 <code>해시 인덱스를 통과할 수 있는지 여부를 결정합니다. 예를 들어 LIKE 연산자와 % 와일드카드 문자는 사용할 수 없습니다. 🎜🎜ibdata1 파일: 🎜🎜🎜InnoDB 데이터 사전, 테이블 구조 정보, 인덱스 등과 같은 메타데이터를 저장합니다. 🎜🎜Doublewrite Buffer <code>Buffer Pool이 데이터 페이지를 쓸 때 , 파일에 직접 쓰는 것이 아니라 이 영역에 먼저 씁니다. 이것의 장점은 운영 체제, 파일 시스템 또는 mysql이 중단되면 이 버퍼에서 직접 데이터를 얻을 수 있다는 것입니다. 🎜🎜버퍼 변경 Mysql이 종료되면 수정 사항이 디스크에 저장됩니다.🎜🎜실행 취소 로그는 트랜잭션 수정 작업을 기록합니다🎜🎜.ibd 파일이 있습니다. 🎜🎜🎜테이블당 파일 테이블스페이스를 사용하면 ALTER TABLE 및 TRUNCATE TABLE의 성능을 크게 향상시킬 수 있습니다. 예를 들어, ALTER TABLE은 공유 테이블스페이스에 있는 테이블과 비교하여, 테이블 수정 시 테이블 복사 작업이 수행되어 테이블 공간이 늘어날 수 있습니다. 디스크 공간을 차지합니다. 이러한 작업에는 테이블 및 인덱스의 데이터만큼 추가 공간이 필요할 수 있습니다. 이 공간은 file-per-table tablespace처럼 운영 체제로 다시 해제되지 않습니다. 🎜🎜I/O 최적화, 공간 관리 또는 백업을 위해 테이블별 테이블스페이스 데이터 파일을 별도의 저장 장치에 생성할 수 있습니다. 이는 테이블 데이터와 구조가 서로 다른 데이터베이스 간에 쉽게 마이그레이션된다는 것을 의미합니다. 🎜🎜데이터 손상이 발생하거나 백업 또는 바이너리 로그를 사용할 수 없거나 MySQL 서버 인스턴스를 다시 시작할 수 없는 경우 단일 테이블스페이스 데이터 파일에 테이블을 저장하면 시간이 절약되고 성공적인 복구 가능성이 높아집니다. 🎜🎜🎜물론 장점과 단점이 있습니다:🎜테이블 삭제 시 성능에 영향을 미칩니다(조각화를 직접 관리하지 않는 한) Drop table的时候会影响性能(除非你自己管理了碎片)fsync一次性刷入数据到文件中文件句柄, 以提供维持对文件的持续访问共享表空间,他可以存储多个表的数据每表表空间 小
存储在一个叫 ibtmp1 的文件中。正常情况下Mysql启动的时候会创建临时表空间,停止的时候会删除临时表空间。并且它能够自动扩容。
原子性,即当修改到一半,出现异常,可以通过Undo 日志回滚。系统表空间``撤销表空间``临时表空间中,如架构图所示。前面已经介绍过
origin,返给执行器modification
modification刷入内存,Buffer Pool的 Change Buffer
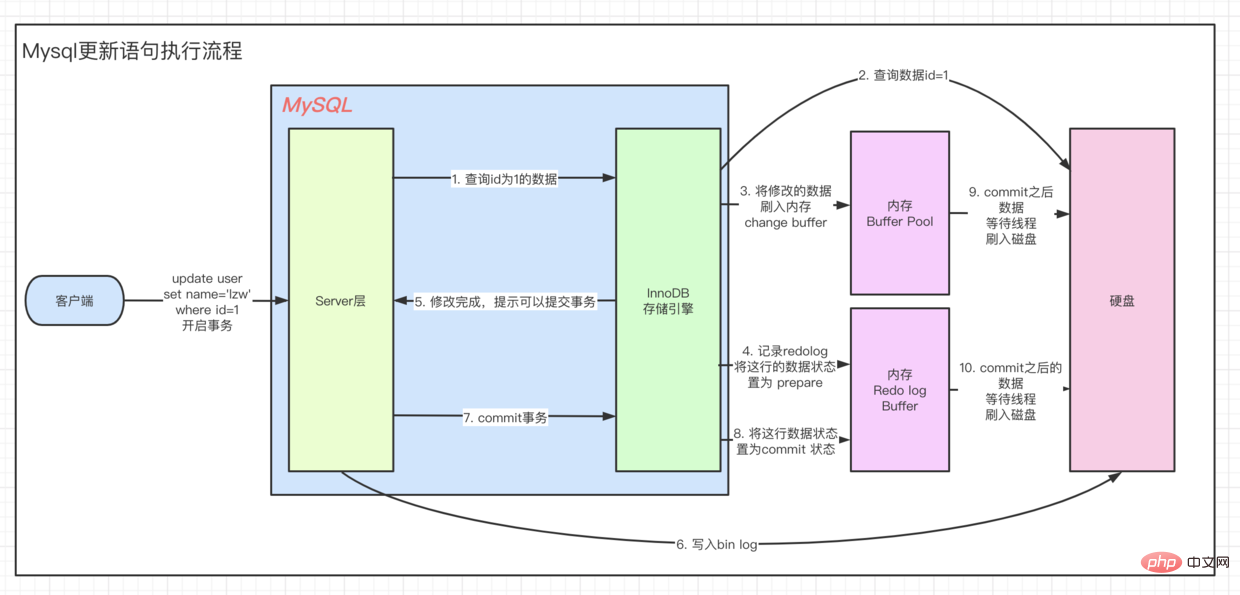
说了 Undo、Redo也顺便说一下Bin log.
innodb引擎没有多大关系,我们前面说的那两种日志,都在是innodb引擎层的。而Bin log是处于服务层的。所以他能被各个引擎所通用Bin log 是以事件的形式,记录了各个 DDL DML 语句,它是一种逻辑意义上的日志。主从复制, 从服务器拿到主服务器的bin log日志,然后执行。数据恢复,拿到某个时间段的日志,重新执行一遍。索引试试华丽的分割线
要想彻底弄明白InnoDB中的索引是个什么东西,就必须要了解它的文件存储级别
Pages, Extents, Segments, and Tablespaces
它们的关系是:
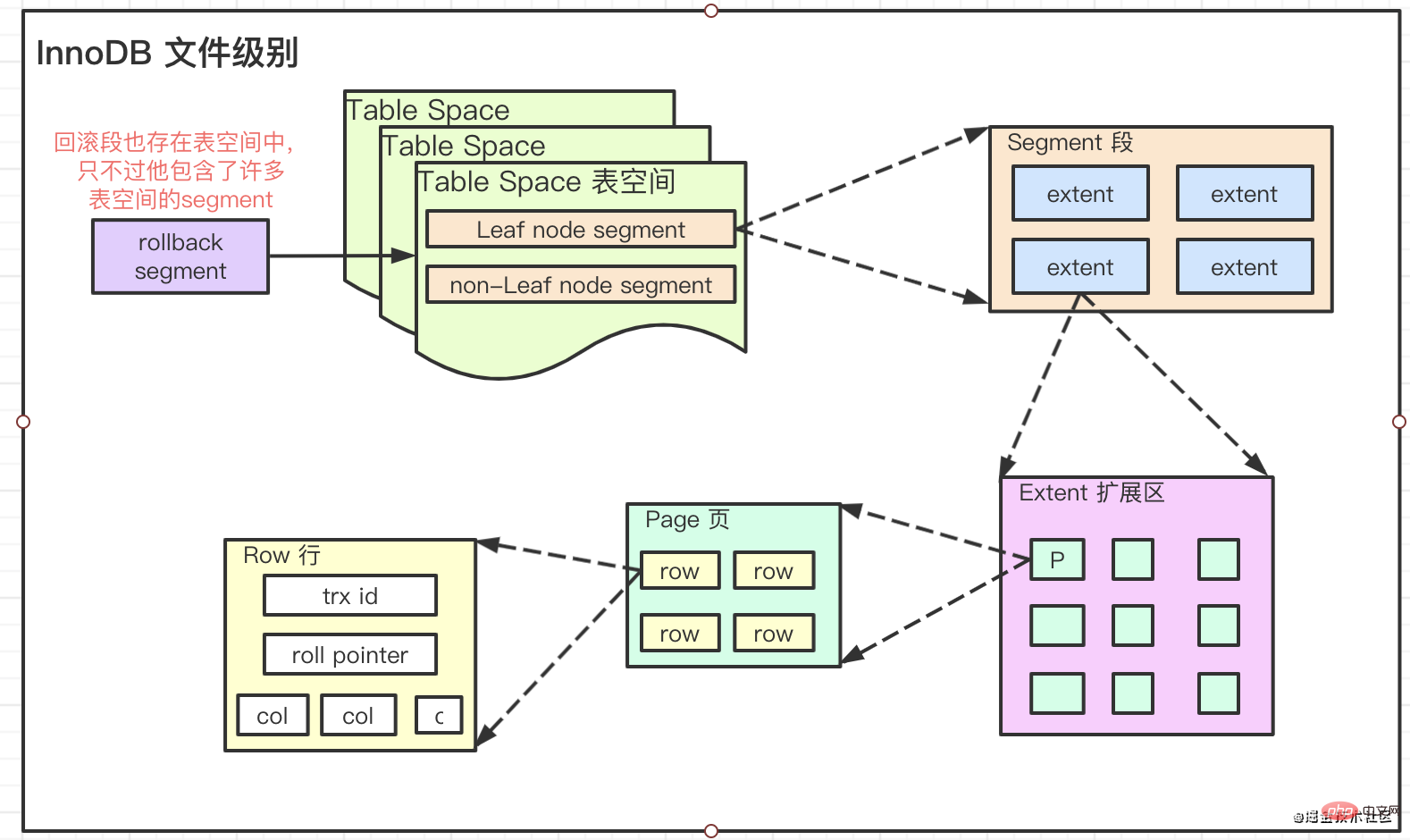
extent 大小为 1M 即 64个 16KB的Page。平常我们文件系统所说的页大小是 4KB,包含 8 个 512Byte
fsync를 수행할 수 없습니다파일 핸들을 계속 유지합니다. 파일에 대한 지속적인 액세스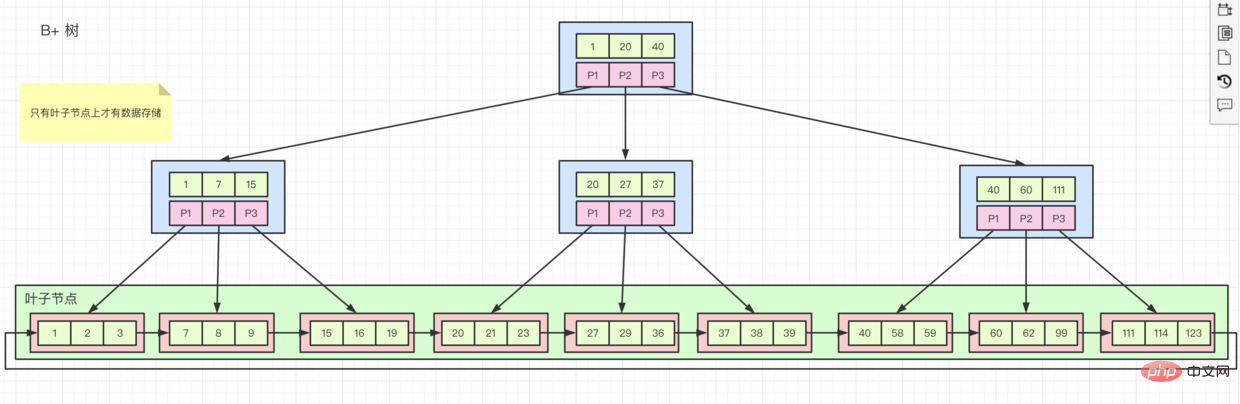
공유 테이블스페이스라고도 하며 여러 테이블 data页 上,存满一个页再去申请新的页,然后接着存。
但如果我们的字段是无序的,存储的位置就会在不同的页上。当我们的数据存储到一个已经被 存满的页上时,就会造成页分裂,从而形成碎片동일한 수의 테이블을 저장하는 경우 소비되는 저장 공간은 테이블당 테이블 공간
ibtmp1라는 파일에 저장됩니다. 정상적인 상황에서 MySQL은 시작 시 임시 테이블스페이스를 생성하고, 중지 시 임시 테이블스페이스를 삭제합니다. 그리고 자동으로 확장될 수도 있습니다. 🎜원자성을 제공합니다. 즉, 수정 도중 예외가 발생할 수 있습니다. 실행 취소 로그를 통해 롤백되었습니다. 🎜🎜거래가 시작되기 전의 원본 데이터와 수정 작업을 저장합니다. 🎜🎜Undo 로그는 롤백 세그먼트에 존재하며, 롤백 세그먼트는 아키텍처 다이어그램과 같이 시스템 테이블스페이스 ``언두 테이블스페이스 ``임시 테이블스페이스 에 존재합니다. 🎜origin이라고 함)을 쿼리하고 이를 실행자에게 반환합니다.🎜🎜실행자에서 수정 code>🎜🎜수정을 메모리에 플래시, 버퍼 풀의 변경 버퍼🎜🎜엔진 레이어: 실행 취소 로그 기록( 트랜잭션 원자성을 달성하기 위해) 🎜🎜엔진 레이어: 리두 로그 기록(충돌 복구에 사용) 🎜🎜서비스 레이어: bin 로그 기록(DDL 기록) 🎜🎜업데이트 성공 결과 반환 🎜🎜데이터가 디스크에 플러시되기를 기다리고 있습니다. 작업자 스레드 🎜🎜 🎜
🎜실행 취소라고 말했습니다. >, Redo 그런데 Bin 로그도 있습니다.🎜🎜🎜이 로그는 innodb 엔진과 거의 관련이 없습니다. 앞서 언급한 두 항목은 모두 innodb 엔진 계층에 있습니다. 그리고 Bin 로그는 서비스 계층에 있습니다. 그래서 모든 엔진에서 사용할 수 있습니다🎜🎜주요 기능은 무엇인가요? 먼저, Bin log는 각 DDL DML 문을 이벤트 형태로 기록하는 로그입니다. 🎜🎜<code>마스터-슬레이브 복제를 구현할 수 있습니다. <code>마스터 서버의 bin log 로그를에서 가져옵니다. 서버를 선택한 후 실행하세요. 🎜🎜데이터 복구를 하고, 일정 기간의 로그를 얻어서 다시 실행해 보세요. 🎜인덱스 code>를 추가해 보겠습니다.
InnoDB의 인덱스를 제대로 이해하고 싶다면 무엇을 그렇다면 <code>파일 저장 수준을 이해해야 합니다🎜 🎜
🎜extent 크기는 1M 즉 64입니다. 16KB 페이지. 일반적으로 파일 시스템에서 참조하는 페이지 크기는 4KB이며 512Byte의 8 섹터를 포함합니다. 🎜🎜🎜저장 구조 B-트리 변형 B+ 트리🎜🎜🎜🎜🎜때때로 기본 키를 정렬해야 하는 이유를 묻는 이유는 정렬된 필드에 인덱스를 생성한 다음 데이터를 삽입하기 때문입니다.
innodb는 저장할 때 페이지에 하나씩 순서대로 저장합니다. 한 페이지가 가득 차면 새 페이지를 신청한 후 계속 저장합니다. 🎜🎜그러나 필드가 정렬되지 않은 경우 저장 위치는 다른 페이지에 있습니다. 데이터가 가득인 페이지에 저장되면 페이지 분할이 발생하여 조각이 형성됩니다. . 🎜B+트리 다이어그램에 표시된 것처럼 클러스터형 인덱스, 행 데이터는 하위 노드에 저장되고 색인의 정렬 순서가 색인 키 값 순서와 일치하면 클러스터형 색인입니다. 기본 키 인덱스는 클러스터형 인덱스입니다. 기본 키 인덱스를 제외하고 다른 모든 인덱스는 보조 인덱스B+树图所示,子节点上存储行数据,并且索引的排列的顺序和索引键值顺序一致的话就是 聚簇索引。主键索引就是聚簇索引,除了主键索引,其他所以都是辅助索引
辅助索引,它的叶子节点上只存储自己的值和主键索引的值。这就意味着,如果我们通过辅助索引查询所有数据,就会先去查找辅助索引中的主键键值,然后再去主键索引里面,查到相关数据。这个过程称为回表
rowid 如果没有主键索引怎么办呢?聚簇索引。rowid 的东西,根据这个id来创建 聚簇索引
자체 값과 기본 키 인덱스 값만 저장합니다. 즉, 보조 인덱스를 통해 모든 데이터를 쿼리하면 먼저 보조 인덱스에서 기본 키 값을 찾은 다음 기본 키 값으로 이동합니다. 키 인덱스데이터를 찾으세요. 이 프로세스를 테이블 반환rowid라고 합니다. 기본 키 인덱스가 없으면 어떻게 해야 하나요? 클러스터형 인덱스가 생성됩니다. 그러면 위 둘 중 하나도 없으므로 걱정하지 마세요. innodb는 rowid라는 것을 유지하고 이 ID를 기반으로 클러스터형 인덱스를 생성합니다
全表查询)。比如 性别字段。这样反而浪费了大量的存储空间。
联合字段索引,比如 idx(name, class_name)
select * from stu where class_name = xx and name = lzw 查询时,也能走 idx 这个索引的,因为优化器将SQL优化为了 name = lzw and class_name = xx
select ··· where name = lzw 的时候,不需要创建一个单独的 name索引,会直接走 idx这个索引覆盖索引。如果我们此次查询的所有数据全都包含在索引里面了,就不需要再 回表去查询了。比如:select class_name from stu where name =lzw
索引条件下推(index_condition_pushdown)
select * from stu where name = lzw and class_name like '%xx'
索引条件下推,因为后面是 like '%xx'的查询条件,所以这里首先根据 name 走 idx联合索引 查询到几条数据后,再回表查询到全量row数据,然后在server层进行 like 过滤找到数据引擎层对like也进行过滤了,相当于把server层这个过滤操作下推到引擎层了。如图所示: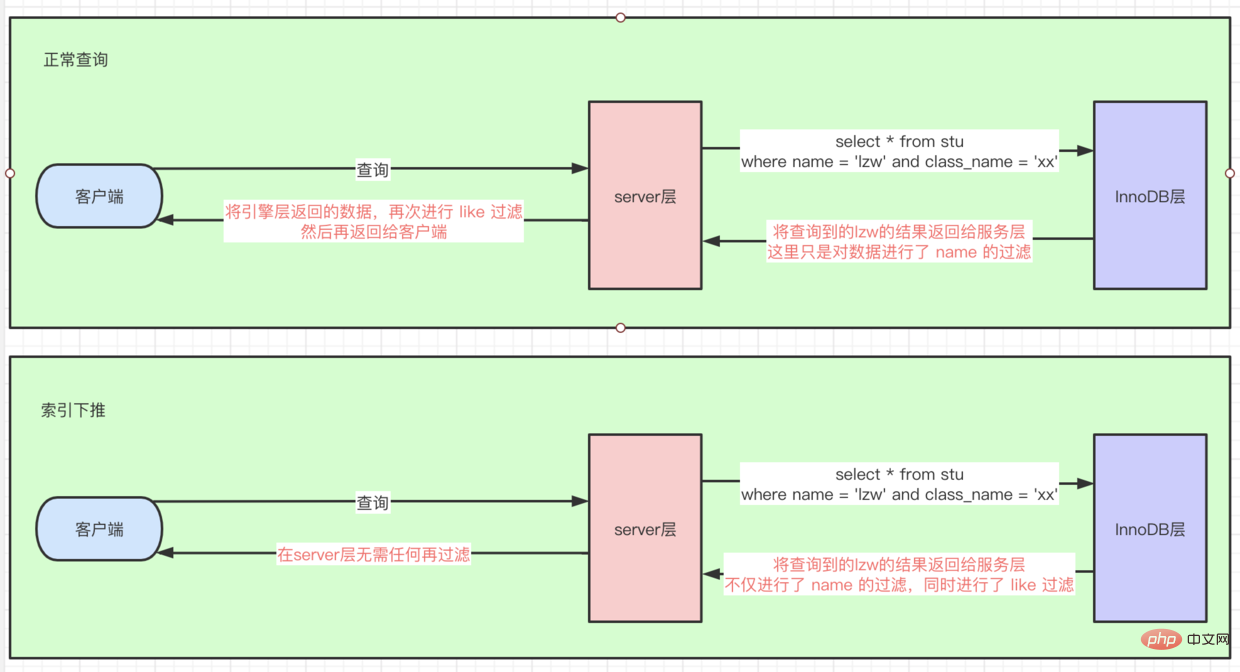
页分裂,索引按顺序存储,如果存储页满了,再去插入就会造成页分裂)函数的时候不会使用索引,所以没必要额外建select count(distinct left(name, 10))/count(*) 来看离散度,决定到底提取前几位)优化器决定的。比如你使用了 Cost Base Optimizer 인덱스 작동 원리테이블 전체를 쿼리하겠습니다). 예를 들어 성별 필드입니다. 이로 인해 저장 공간이 많이 낭비됩니다. idx(name, class_name)과 같은 결합 필드 인덱스select * from stu where class_name = xx 및 name = lzw 쿼리를 실행할 때 최적화 프로그램이 SQL을 name = lzw 및 class_name = xx🎜🎜로 최적화하기 때문에 인덱스 idx를 사용할 수 있습니다. select ··· where name =이 필요한 경우 lzw, 별도의 name 색인을 만들 필요가 없으며 idx 색인이 직접🎜🎜covering 색인으로 사용됩니다. 이번에 쿼리한 모든 데이터가 인덱스에 모두 포함되어 있으면 쿼리하기 위해 테이블로 돌아가 필요가 없습니다. 예: select class_name from stu where name =lzw🎜🎜🎜🎜🎜index_condition_pushdown)🎜🎜🎜이러한 SQL이 있습니다. select * from stu where name = lzw 및 class_name like '% xx'🎜🎜인덱스 조건 푸시다운이 없으면 like '%xx'라는 쿼리 조건이 따르기 때문에 먼저 다음과 같이 합니다. name은 idx 조인트 인덱스를 사용하여 여러 데이터 조각을 쿼리한 다음 테이블로 돌아가 전체 행 데이터를 쿼리합니다. >, 코드>서버 레이어는 데이터를 찾기 위해 필터링과 같은 작업을 수행합니다🎜🎜있는 경우 엔진 레이어에서도 직접 필터링됩니다. 서버 계층 필터링 작업은 엔진 계층으로 푸시다운됩니다. 그림과 같이: 🎜🎜🎜🎜🎜 🎜
🎜페이지 분할 발생, 색인은 순서대로 저장되며, 저장 페이지가 가득 찬 경우 다시 삽입하면 페이지 분할이 발생함) 🎜🎜교체, 합계, 계산 등을 사용하세요. . 함수는 인덱스를 사용하지 않으므로 추가로 인덱스를 만들 필요가 없습니다. 문자열을 int로 변환하는 등 암시적 변환이 발생하는 경우 특히 긴 필드의 경우 인덱스가 필요하지 않습니다. front 인덱스를 생성할 숫자 수(select count(distinct left(name, 10))/count(*)를 사용하여 분산을 확인하고 상위 몇 개를 추출하는 방법을 결정할 수 있음)🎜🎜 옵티마이저에 의해 결정됩니다. 예를 들어 비용 기반 최적화 도구 비용 기반 최적화 도구를 사용하는 경우 비용이 가장 낮은 최적화 도구를 사용하세요. 🎜🎜🎜색인을 이해한 후 잠금 장의 사본을 열 수 있습니다 🎜🎜또 다른 멋진 구분선🎜🎜🎜잠금 장🎜🎜4가지 주요 기능🎜🎜먼저 우리에게 익숙한 몇 가지 기본 개념을 검토해 보겠습니다. : 🎜전제, 트랜잭션:
SQL92 표준 규정: (동시성은 왼쪽에서 오른쪽으로 감소합니다)

이 두 가지 솔루션은 Innodb에서 함께 사용됩니다. 다음은 RR의 MVCC 구현에 대한 간략한 설명입니다. 그림에서 롤백 ID의 초기 값은 0이 아니라 NULL이어야 합니다. 편의상 0RR 的 MVCC实现,图中 回滚id 初始值不应该为0而是NULL,这里为了方便写成0

RC的MVCC实现是对 同一个事务的多个读 创建一个版本 而 RR 是 同一个事务任何一条都创建一个版本
通过MVCC与LBCC的结合,InnoDB能解决对于不加锁条件下的 幻读的情况。而不必像 Serializable 一样,必须让事务串行进行,无任何并发。
下面我们来深入研究一下InnoDB锁是如何实现 RR 事务隔离级别的
表级别的 共享和排它锁 => (IS、IX)上面这四把锁是最基本锁的类型
这三把锁,理解成对于上面四把锁实现的三种算法方式,我们这里暂且把它们称为:高阶锁
上面三把是额外扩展的锁
lock in share mode 。排它锁默认 Insert、Update、Delete会使用。显示使用在语句后加for update。打一个标记,记录这个表是否被锁住了) => 如果没有这个锁,别的事务想锁住这张表的时候,就要去全表扫描是否有锁,效率太低。所以才会有意向锁的存在。锁的是索引,那么这个时候可能有人要问了:那如果我不创建索引呢?
索引的存在,我们上面讲过了,这里再回顾一下,有下面几种情况
完整的数据)聚簇索引
rowid 的东西,根据这个id来创建 聚簇索引
所以一个表里面,必然会存在一个索引,所以锁当然总有索引拿来锁住了。
当要给一张你没有显示创建索引的表,进行加锁查询时,数据库其实是不知道到底要查哪些数据的,整张表可能都会用到。所以索性就锁整张表
🎜🎜🎜RC의 MVCC 구현은 동일한 트랜잭션의 여러 읽기에 대한 버전을 생성하는 것이며 RR은 동일한 트랜잭션 중 하나에 대한 버전을 생성하는 것입니다🎜🎜🎜throughMVCC와 LBCC의 조합을 통해 InnoDB는 no locking 조건에서 팬텀 읽기 문제를 해결할 수 있습니다. 트랜잭션은 직렬화 가능과 같은 방식이 아니라 동시성 없이 수행되는 직렬이어야 합니다. 🎜🎜InnoDB 잠금이 RR 트랜잭션 격리 수준을 구현하는 방법에 대해 심층적으로 연구해 보겠습니다.🎜테이블 수준에서 실제로 공유 및 배타적 잠금인 두 개의 잠금 => (IS, IX)🎜🎜🎜위의 네 가지 잠금은 가장 기본적인 유형의 잠금입니다. locks🎜4개의 잠금에 의해 구현된 것은 여기에서 일시적으로 다음과 같이 호출됩니다: 고차 잠금🎜공유 모드 잠금을 추가하세요. 배타적 잠금은 기본적으로 삽입, 업데이트, 삭제로 사용됩니다. 명령문 뒤에 for update를 사용하여 표시합니다. 🎜🎜의도 잠금은 데이터베이스 자체에서 유지 관리됩니다. (주요 기능은 테이블에 전체 데이터를 저장함)인 기본 키를 생성했습니다. >) 🎜🎜기본 키는 없지만 고유 키가 있습니다. 둘 다 null이 아닌 경우 이 키를 기반으로 클러스터형 인덱스가 생성됩니다. 🎜🎜위 둘 다 없으면 걱정하지 마세요. innodb에서 자체적으로 관리하는 것이 rowid이고, 이 ID를 기반으로 클러스터형 인덱스가 생성됩니다. 따라서 인덱스가 있어야 합니다. 테이블에는 잠금을 가져오는 인덱스가 항상 있으므로 와서 잠그세요. 🎜🎜인덱스를 명시적으로 생성하지 않은 테이블에 대해 잠긴 쿼리를 수행하려는 경우 데이터베이스는 실제로 어떤 데이터를 확인할지 알 수 없습니다. 테이블을 사용할 수 있습니다. 그러니 간단히 전체 테이블을 잠그세요. 🎜辅助索引加写锁,比如select * from where name = ’xxx‘ for update 最后要回表查主键上的信息,所以这个时候除了锁辅助索引还要锁主键索引
배타적 잠금이고 임시 키 잠금 = 레코드 잠금 + 간격 잠금업데이트를 위해 id = 3인 xxx에서 *를 선택할 때 code>, 레코드 잠금이 생성됩니다x
업데이트를 위해 id = 5인 xxx에서 *를 선택하면 간격 잠금이 생성됩니다 => 여기에서 특히 주의하세요: 거기. 排它锁, 并且 临键锁 = 记录锁 + 间隙锁
select * from xxx where id = 3 for update 时,产生记录锁select * from xxx where id = 5 for update 时,产生间隙锁 => 锁住了(3,6),这里要格外注意一点:间隙锁之间是不冲突的。select * from xxx where id = 5 for update 时,产生临键锁 => 锁住了(3,6], mysql默认使用临键锁,如果不满足 1 ,2 情况 则他的行锁的都是临键锁Record Lock 行锁防止别的事务修改或删除,Gap Lock 间隙锁防止别的事务新增,Gap Lock 和 Record Lock结合形成的Next-Key锁共同解决RR级别在写数据时的幻读问题。show status like 'innodb_row_lock_%'select * from information_schema.INNODB_TRX 能查看到当前正在运行和被锁住的事务show full processlist = select * from information_schema.processlist 能查询出是 哪个用户 在哪台机器host的哪个端口上 连接哪个数据库 执行什么指令 的 状态与时间 업데이트를 위해 id = 5인 xxx에서 *를 선택하면 임시 키 잠금이 생성됩니다 => 잠깁니다(3,6]. mysql은 임시 키 잠금을 사용합니다. 기본값, 1이 만족되지 않으면 2의 경우 모든 행 잠금은 임시 키 잠금입니다 Record Lock 행 잠금은 다른 트랜잭션에 의한 수정 또는 삭제를 방지합니다. Gap Lock Gap lock은 Gap Lock과 Record Lock의 조합으로 형성된 Next-Key 잠금으로 RR 수준 데이터 쓰기 시 팬텀 읽기 문제 'innodb_row_lock_%'과 같은 상태 표시information_schema.INNODB_TRX에서 *를 선택하세요 현재 실행 중이고 잠긴 트랜잭션을 볼 수 있습니다
전체 프로세스 목록 표시 = information_schema.processlist에서 * 선택은 어떤 사용자 어느 사용자인지 쿼리할 수 있습니다. 어느 머신 호스트의 포트 어떤 데이터베이스가 연결되어 있는지 어떤 명령이 실행됩니까? 상태 및 시간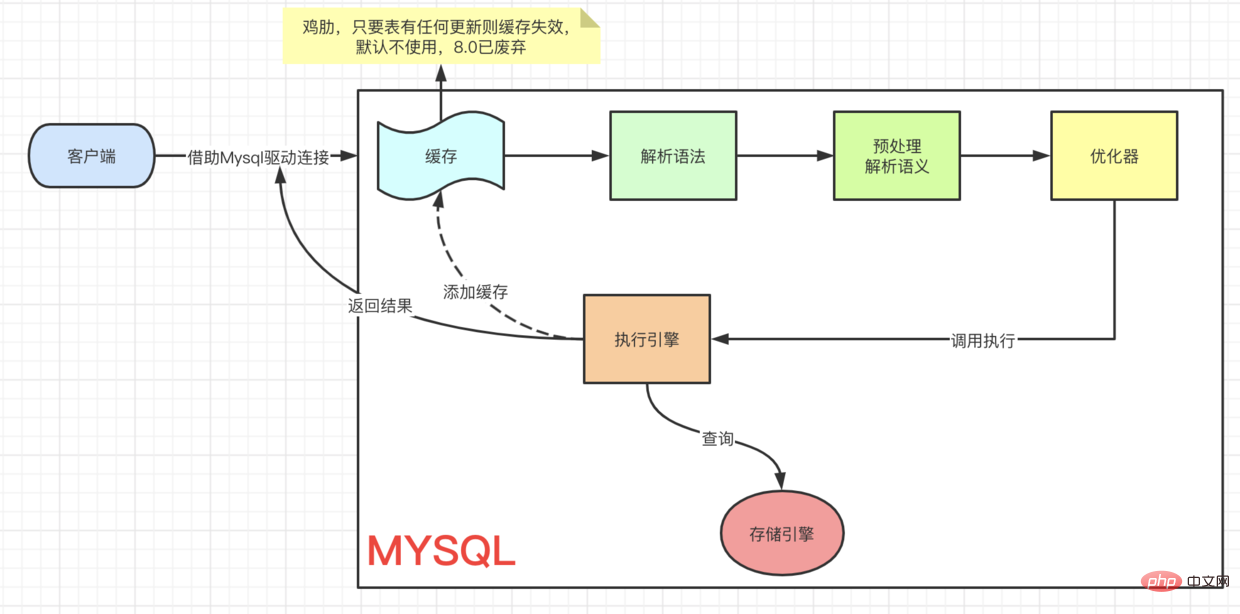
查询执行过程入手
添加连接池,避免每次都新建、销毁连接
쿼리 실행 프로세스🎜를 방지하세요. >매번 연결을 생성하고 파괴합니다. 그러면 연결 풀이 많을수록 더 좋습니까?
관심 있는 친구들은 다음 기사를 읽어보세요: 풀 크기 조정 정보🎜🎜대략 요약하겠습니다:🎜CPU만이 실제로 스레드를 실행할 수 있다는 것을 우리 모두 알고 있습니다. 운영체제는 타임 슬라이싱 기술을 사용하기 때문에 하나의 CPU 코어가 여러 스레드를 실행한다고 생각합니다. CPU才能真正去执行线程。而操作系统因为用时间分片的技术,让我们以为一个CPU内核执行了多个线程。CPU在某个时间段只能执行一个线程,所以无论我们怎么增加并发,CPU还是只能在这个时间段里处理这么多数据。CPU处理不了这么多数据,又怎么会变慢?因为时间分片,当多个线程看起来在"同时执行",其实他们之间的上下文切换十分耗时I/O操作,这个时候,CPU就可以把时间,分片给其他线程,以提升处理效率和速度I/O等待时间非常短,所以我们就不能添加过多连接数线程数 = ((核心数 * 2) + 有效磁盘数)。比如一台 i7 4core 1hard disk的机器,就是 4 * 2 + 1 = 9很多CPU计算和I/O的场景 比如:设置最大线程数等如果并发非常大,就不能让他们全打到数据库上,在客户端连接数据库查询时,添加如Redis하지만 사실 이전 CPU는 특정 기간에 하나의 스레드만 실행할 수 있으므로 아무리 늘려도 동시성, CPU는 여전히 이 기간 동안 너무 많은 데이터만 처리할 수 있습니다.
CPU가 그렇게 많은 데이터를 처리하지 못하더라도 어떻게 속도가 느려질 수 있나요? 시간 분할로 인해 여러 스레드가 "동시에 실행 중"인 것처럼 보일 때 실제로 스레드 간의 컨텍스트 전환은 매우 많은 시간을 소모합니다 code> li>I/O 작업을 수행해야 합니다. CPU는 시간을 절약할 수 있으며, 다른 스레드로 분할하여 처리 효율성과 속도를 향상시킬 수 있습니다.따라서 기계식 하드 드라이브를 사용하는 경우 일반적으로 더 많은 연결을 추가할 수 있습니다. 높은 동시성을 유지하기 위해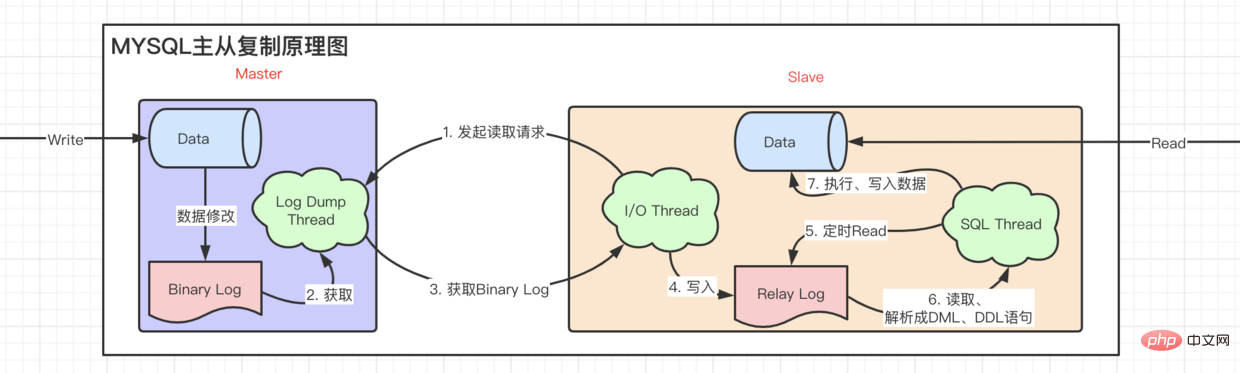 하지만 SSD를 사용하는 경우
하지만 SSD를 사용하는 경우 I/O 대기 시간이 매우 짧기 때문에 너무 많은 연결을 추가할 수는 없습니다 li>
스레드 수 = ((코어 수 * 2) + 유효 디스크 수). 예를 들어, i7 4core 1hard disk 시스템은 4 * 2 + 1 = 9 이 공식이 여러분에게 친숙할 지 궁금합니다. 이는 데이터베이스 연결에만 적용되는 것이 아닙니다. CPU 컴퓨팅 및 I/O가 많은 시나리오에 적용 가능 예: 최대 스레드 수 설정 등
读写分离 异步复制的特性。Binary Log写入relay log之后,slave都会把最新读取到的Binary Log Position记录到master info上,下一次就直接从这个位置去取。上面这种异步事务
failover动作,即主节点挂掉,选举从节点后,能快速自动避免数据丢失。对数据进行分类划分,分成不同表,减少对单一表造成过多锁操作동시성이 매우 큰 경우 모두 데이터베이스에 도달하도록 할 수는 없습니다. 클라이언트가 쿼리를 위해 데이터베이스에 연결하고 Redis와 같은 추가 이 타사 캐시
읽기-쓰기 분리 비동기 복제의 특징을 쉽게 알 수 있습니다. 🎜릴레이 로그에 바이너리 로그를 작성한 후 슬레이브는 최근에 읽은 바이너리 로그 위치를 작성합니다. code>는 master info에 기록되며 다음번에는 이 위치에서 직접 가져옵니다. 비동기 마스터-슬레이브 복제에는 명백한 문제가 있습니다. 제 시간에 업데이트되지 않는 문제. 사용자가 데이터를 쓰고 즉시 읽을 때 읽은 데이터는 여전히 이전 데이터이므로 지연이 있음을 의미합니다.
지연 문제를 해결하려면 마스터 노드가 먼저 쓰고 모든 슬레이브 노드가 쓰기를 완료해야 하는 완전 동기식 복제를 도입해야 합니다. , 쓰기 성능에 큰 영향을 미치는 성공적인 쓰기를 반환합니다.🎜반동기 복제, 쓰기 데이터가 하나만 있으면 성공한 것으로 간주됩니다. (반동기 복제가 필요한 경우 마스터 노드와 슬레이브 노드 모두 semisync_mater.so 및 semisync_slave.so 플러그인을 설치해야 함) 🎜GTID(global transaction identities) 복제, 마스터 라이브러리가 병렬로 복제하는 경우 , 슬레이브 라이브러리도 병렬로 복제하여 마스터 문제를 해결합니다. 동기 복제 지연에서 자동 failover 작업이 구현됩니다. 즉, 마스터 노드가 중단되고 슬레이브 노드가 선택되면 데이터 손실을 신속하고 자동으로 방지할 수 있습니다. 잠금 작업을 줄이기 위해 데이터를 범주화하고 여러 테이블로 나눕니다🎜켜진 SQLshow_query_log,执行时间超过变量long_query_time이 기록됩니다.
mysqldumpslow /var/lib/mysql/mysql-slow.log를 사용할 수 있습니다. 이보다 더 우아한 분석을 제공할 수 있는 플러그인이 많기 때문에 여기서는 자세히 설명하지 않겠습니다. mysqldumpslow /var/lib/mysql/mysql-slow.log,还有很多插件可以提供比这个更优雅的分析,这里就不详细讲了。
任何SQL在写完之后都应该explain
설명해야 합니다🎜left/right join导致性能低下left/right join会直接指定驱动表,在MYSQL中,默认使用Nest loop join进行表关联(即通过驱动表的结果集作为循环基础数据,然后通过此集合中的每一条数据筛选下一个关联表的数据,最后合并结果,得出我们常说的临时表)。驱动表的数据是 百万千万级别的,可想而知这联表查询得有多慢。但是反过来,如果以小表作为驱动表,借助千万级表的索引查询就能变得很快。驱动表,那么请交给优化器来决定,比如:select xxx from table1, table2, table3 where ···,优化器会将查询记录行数少的表作为驱动表。驱动表,那么请拿好Explain武器,在Explain的结果中,第一个就是基础驱动表
表排序也是有很大的性能差异,我们尽量对驱动表进行排序,而不要对临时表,也就是合并后的结果集进行排序。即执行计划中出现了 using temporary,就需要进行优化。普通查询和复杂查询(联合查询、子查询等)SIMPLE,查询不包含子查询或者UNIONPRIMARY,如果查询包含复杂查询的子结构,那么就需要用到主键查询SUBQUERY,在select或者where中包含 子查询
DERIVED,在from中包含子查询UNION RESULT,从union表查询子查询越来越快const或者system 常量级别的扫描,查询表最快的一种,system是const的一种特殊情况(表中只有一条数据)eq_ref 唯一性索引扫描ref 非唯一性索引扫描range 索引的范围扫描,比如 between、等范围查询index (index full)扫描全部索引树ALL 扫描全表NULL,不需要访问表或者索引不一定使用
哪一个索引被真正使用到了。如果没有则为NULL索引(key)一起被使用only index 信息只需要从索引中查出,可能用到了覆盖索引,查询非常快using where 如果查询没有使用索引,这里会在server层过滤再使用 where来过滤结果集impossible where 啥也没查出来using filesort ,只要没有通过索引来排序,而是使用了其他排序的方式就是 filesortusing temporary(需要通过临时表来对结果集进行暂时存储,然后再进行计算。)一般来说这种情况都是进行了DISTINCT、排序、分组
using index condition 索引下推,上文讲过,就是把server层这个过滤操作下推到引擎层
插入与查询比较多的时候,可以使用MyISAM存储引擎memory
插入、更新、查询等并发数很多时,可以使用InnoDB
5단계에서 MYSQL 최적화에 대해 위에서 아래로
또한 데이터 쿼리가 느리기 때문에 데이터베이스를 맹목적으로 "최적화"할 것이 아니라 비즈니스 애플리케이션 수준에서 분석해야 합니다. 예를 들어 데이터 캐싱, 요청 제한 등이 있습니다.
다음 글에서 만나요
관련 무료 학습 권장사항: mysql 비디오 튜토리얼
위 내용은 MYSQL의 기본 원리를 이해하는 데 도움이 되는 기사의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



