



또 만나요! 2주가 더 지났고 클라우드 노트에 미완성 기사 초안이 몇 개 더 남아 있습니다. 일부는 품질이 기대에 미치지 못하기 때문에 더 많은 콘텐츠를 추가할 준비가 되어 있는 반면, 다른 일부는 단지 영감만 주고 콘텐츠가 전혀 없는 경우도 있습니다. 일주일에 5~6개의 기사를 낼 수 있는 큰 놈들이 많다는 게 부럽다. 간 두 개를 줘도 부족하다. 알았어, 더 이상 헛소리는 하지마...
최근 온라인 환경에서 느린 SQL 쿼리로 인해 데이터베이스 장애가 발생하여 온라인 비즈니스에 영향을 미쳤습니다. 조사 결과 SQL 실행 시 MySQL 옵티마이저가 잘못된 인덱스를 선택했기 때문인 것으로 확인됐다. 조사 과정에서 많은 정보를 참고하고 MySQL 옵티마이저에 의한 인덱스 선택의 기본 원리를 배웠습니다. 이 기사에서는 문제 해결을 위한 아이디어를 공유합니다. MySQL에 대한 나의 이해는 제한되어 있습니다. 실수가 있을 경우 합리적인 토론과 수정을 환영합니다.
이번 사고에서 우리는 MySQL의 작동 원리에 대한 심층적인 이해의 중요성도 충분히 알 수 있습니다. 이는 문제가 발생했을 때 독립적으로 문제를 해결할 수 있는 열쇠입니다.어둡고 폭풍우가 치는 밤에 회사의 온라인 회선이 갑자기 다운되고 동료가 온라인 상태가 되지 않는다고 상상해 보세요. 이때 문제를 해결할 수 있는 조건이 있는 사람은 바로 당신입니다. 엔지니어의 기술, 부끄럽습니까...
이 기사의 주요 내용:Fault 설명
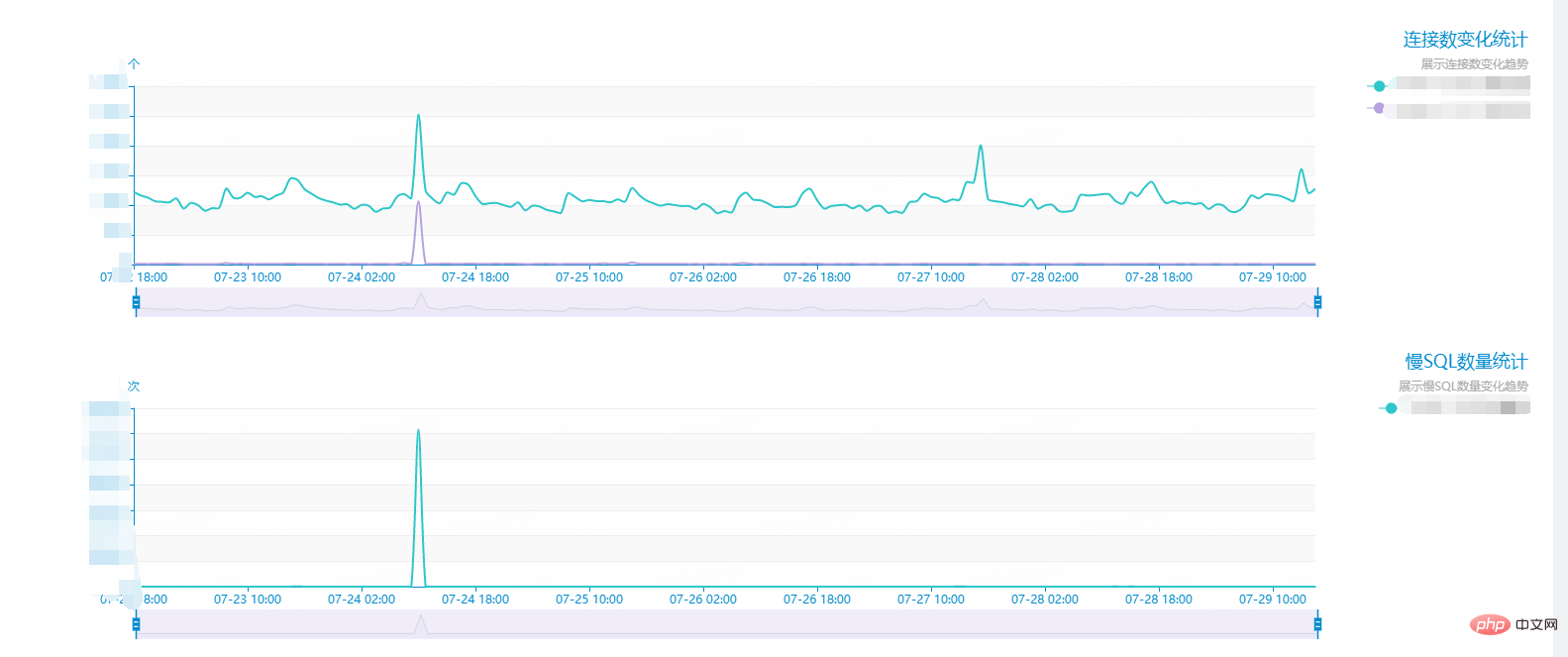 느린 SQL 기록을 빠르게 확인하여 찾아보세요. 모두 같은 유형의 문으로 인해 발생합니다. 느린 쿼리(테이블 이름과 같은 개인 데이터를 숨겼습니다.):
느린 SQL 기록을 빠르게 확인하여 찾아보세요. 모두 같은 유형의 문으로 인해 발생합니다. 느린 쿼리(테이블 이름과 같은 개인 데이터를 숨겼습니다.):
select * from sample_table where 1 = 1 and (city_id = 565) and (type = 13) order by id desc limit 0, 1复制代码
문이 매우 간단하고 특별한 것이 없는 것 같습니다. 그러나 각 실행에 대한 쿼리 시간은 놀랍게도 44초에 달했습니다.
 단순히 충격적입니다. 더 이상 "느리다"라고 할 수는 없습니다...
단순히 충격적입니다. 더 이상 "느리다"라고 할 수는 없습니다...
다음으로 테이블 데이터 정보를 확인하면 아래와 같이 됩니다.
 테이블 데이터 볼륨이 크고, 예상 행 수는 83683240으로 약 8천만 개,
테이블 데이터 볼륨이 크고, 예상 행 수는 83683240으로 약 8천만 개,
입니다. 일반적인 상황은 이렇습니다. 문제 해결로 넘어가겠습니다.
문제 원인 해결
KEY `idx_1` (`city_id`,`type`,`rank`), KEY `idx_log_dt_city_id_rank` (`log_dt`,`city_id`,`rank`), KEY `idx_city_id_type` (`city_id`,`type`)复制代码
두 개의 index idx_1, idx_city_id_type이 중복되는 것은 무시해주세요 , 이것들은 모두 역사에 남겨진 문제입니다.
idx_city_id_type 및 idx_1 인덱스가 있음을 알 수 있습니다. 쿼리 조건은 city_id 및 type이며 두 인덱스 모두 도달할 수 있습니다. 하지만 쿼리 조건이 실제로 city_id와 유형만 고려하면 되나요? (예리한 친구들은 문제를 알아차렸을 것입니다. 모두가 생각하도록 남겨두겠습니다.)
이제 인덱스가 있으므로 SQL을 분석하기 위해 SQL문이 실제로 인덱스에 도달하는지 확인할 차례입니다. 성명. explain은 SELECT 쿼리 문을 분석하는 데 사용됩니다.
Explain의 더 중요한 필드는 다음과 같습니다.
select_type: 단순 쿼리, 결합 쿼리, 하위 쿼리 등을 포함한 쿼리 유형설명을 사용하여 명령문을 분석합니다:
select * from sample_table where city_id = 565 and type = 13 order by id desc limit 0,1复制代码
결과는 다음과 같습니다.
 possiblekey에 인덱스가 있지만 결국 기본 키 인덱스가 사용되었습니다. 테이블의 크기는 수천만 개이고 쿼리 조건은 결국 빈 데이터를 반환합니다. 즉, MySQL은 실제로 기본 키 인덱스를 검색하는 데 오랜 시간이 걸리므로 쿼리가 느려집니다.
possiblekey에 인덱스가 있지만 결국 기본 키 인덱스가 사용되었습니다. 테이블의 크기는 수천만 개이고 쿼리 조건은 결국 빈 데이터를 반환합니다. 즉, MySQL은 실제로 기본 키 인덱스를 검색하는 데 오랜 시간이 걸리므로 쿼리가 느려집니다.
강제 인덱스(idx_city_id_type)를 사용하여 명령문이 우리가 설정한 공동 인덱스를 선택하도록 할 수 있습니다: 이번에는 확실히 매우 빠르게 실행됩니다. 명령문을 분석하세요: select * from sample_table force index(idx_city_id_type) where ( ( (1 = 1) and (city_id = 565) ) and (type = 13) ) order by id desc limit 0, 1复制代码
로그인 후 복사로그인 후 복사

实际执行时间0.00175714s,走了联合索引后,不再是慢查询了。
问题找到了,总结下来就是:MySQL优化器认为在limit 1的情况下,走主键索引能够更快的找到那一条数据,并且如果走联合索引需要扫描索引后进行排序,而主键索引天生有序,所以优化器综合考虑,走了主键索引。实际上,MySQL遍历了8000w条数据也没找到那个天选之人(符合条件的数据),所以浪费了很多时间。
MySQL一条语句的执行流程大致如下图,而查询优化器则是选择索引的地方:
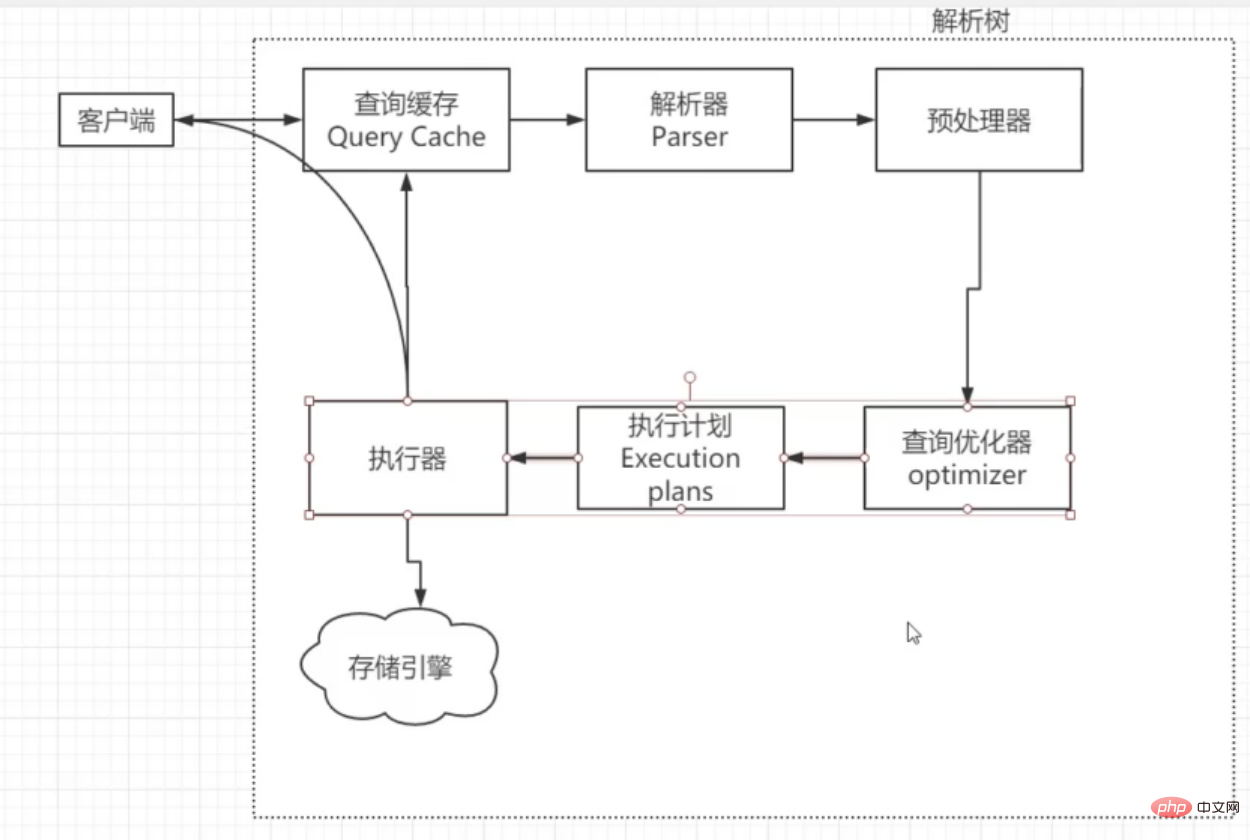
引用参考文献一段解释:
首先要知道,选择索引是MySQL优化器的工作。
而优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。在数据库里面,扫描行数是影响执行代价的因素之一。扫描的行数越少,意味着访问磁盘数据的次数越少,消耗的CPU资源越少。
当然,扫描行数并不是唯一的判断标准,优化器还会结合是否使用临时表、是否排序等因素进行综合判断。
总结下来,优化器选择有许多考虑的因素:扫描行数、是否使用临时表、是否排序等等
我们回头看刚才的两个explain截图:


走了主键索引的查询语句,rows预估行数1833,而强制走联合索引行数是45640,并且Extra信息中,显示需要Using filesort进行额外的排序。所以在不加强制索引的情况下,优化器选择了主键索引,因为它觉得主键索引扫描行数少,而且不需要额外的排序操作,主键索引天生有序。
同学们就要问了,为什么rows只有1833,明明实际扫描了整个主键索引啊,行数远远不止几千行。实际上explain的rows是MySQL预估的行数,是根据查询条件、索引和limit综合考虑出来的预估行数。
MySQL是怎样得到索引的基数的呢?这里,我给你简单介绍一下MySQL采样统计的方法。 为什么要采样统计呢?因为把整张表取出来一行行统计,虽然可以得到精确的结果,但是代价太高了,所以只能选择“采样统计”。 采样统计的时候,InnoDB默认会选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。 而数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过1/M的时候,会自动触发重新做一次索引统计。 在MySQL中,有两种存储索引统计的方式,可以通过设置参数innodb_stats_persistent的值来选择: 设置为on的时候,表示统计信息会持久化存储。这时,默认的N是20,M是10。 设置为off的时候,表示统计信息只存储在内存中。这时,默认的N是8,M是16。 由于是采样统计,所以不管N是20还是8,这个基数都是很容易不准的。复制代码
我们可以使用analyze table t 命令,可以用来重新统计索引信息。但是这条命令生产环境需要联系DBA,所以我就不做实验了,大家可以自行实验。
为什么这么说?因为如果我这个表中的索引是city_id,type和id的联合索引,那优化器就会走这个联合索引,因为索引已经做好了排序。
把limit数量调大会影响预估行数rows,进而影响优化器索引的选择吗?
答案是会。
我们执行limit 10
select * from sample_table where city_id = 565 and type = 13 order by id desc limit 0,10复制代码

图中rows变为了18211,增长了10倍。如果使用limit 100,会发生什么?

优化器选择了联合索引。初步估计是rows还会翻倍,所以优化器放弃了主键索引。宁愿用联合索引后排序,也不愿意用主键索引了。
问:这个查询语句已经在线上稳定运行了非常长的时间,为何这次突然出现了慢查询?
答:以前的语句查询条件返回结果都不为空,limit1很快就能找到那条数据,返回结果。而这次代码中查询条件实际结果为空,导致了扫描了全部的主键索引。
知道了MySQL为何选择这个索引的原因后,我们就可以根据上面的思路来列举出解决办法了。
主要有两个大方向:
就像上面我最开始的操作那样,我们直接使用force index,让语句走我们想要走的索引。
select * from sample_table force index(idx_city_id_type) where ( ( (1 = 1) and (city_id = 565) ) and (type = 13) ) order by id desc limit 0, 1复制代码
这样做的优点是见效快,问题马上就能解决。
缺点也很明显:
force index()并不容易加进去。我们换一种办法,我们去引导优化器选择联合索引。
通过增大limit,我们可以让预估扫描行数快速增加,比如改成下面的limit 0, 1000
SELECT * FROM sample_table where city_id = 565 and type = 13 order by id desc LIMIT 0,1000复制代码
这样就会走上联合索引,然后排序,但是这样强行增长limit,其实总有种面向黑盒调参的感觉。我们还有更优美的解决方案吗?
我们这句慢查询使用的是order by id,但是我们却没有在联合索引中加入id字段,导致了优化器认为联合索引后还要排序,干脆就不太想走这个联合索引了。
我们可以新建city_id,type和id的联合索引,来解决这个问题。
这样也有一定的弊端,比如我这个表到了8000w数据,建立索引非常耗时,而且通常索引就有3.4个g,如果无限制的用索引解决问题,可能会带来新的问题。表中的索引不宜过多。
还有什么办法?我们可以用子查询,在子查询里先走city_id和type的联合索引,得到结果集后在limit1选出第一条。
但是子查询使用有风险,一版DBA也不建议使用子查询,会建议大家在代码逻辑中完成复杂的查询。当然我们这句并不复杂啦~
Select * From sample_table Where id in (Select id From `newhome_db`.`af_hot_price_region` where (city_id = 565 and type = 13)) limit 0, 1复制代码
SQL优化是个很大的工程,我们还有非常多的办法能够解决这句慢查询问题,这里就不一一展开了。留给大家做为思考题了。
本文带大家回顾了一次MySQL优化器选错索引导致的线上慢查询事故,可以看出MySQL优化器对于索引的选择并不单单依靠某一个标准,而是一个综合选择的结果。我自己也对这方面了解不深入,还需要多多学习,争取能够好好的做一个索引选择的总结(挖坑)。不说了,拿起巨厚的《高性能MySQL》,开始...
压住我的泡面...
最后做个文章总结:
相关免费学习推荐:mysql视频教程
위 내용은 MySQL에서 잘못된 인덱스 선택으로 인한 온라인 느린 쿼리 사고의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!




















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



