


MySQL Tutorial칼럼에서는 고급 MySQL을 이해하기 위해 47개의 그림을 소개합니다.

MySQL 입문장에서는 기본적인 SQL 명령어, 데이터 종류, 기능을 주로 소개합니다. 위의 지식을 습득한 후에는 MySQL을 개발할 수 있습니다. MySQL
데이터베이스의 핵심은 데이터를 저장하는 것이고, 데이터 스토리지는 디스크를 다룰 수 없습니다. 따라서 데이터가 어떻게, 어떻게 저장되는지가 저장의 핵심입니다. 따라서 스토리지 엔진은 데이터 스토리지 엔진과 동일하며 데이터가 디스크 수준에 저장되도록 합니다.
MySQL의 아키텍처는 3계층 모델로 이해할 수 있습니다

스토리지 엔진도 MySQL의 한 구성 요소이며, 수행할 수 있고 지원할 수 있는 주요 기능은 다음과 같습니다.
default-table-type을 설정하여 현재 스토리지를 볼 수 있습니다. 엔진
show variables like 'table_type';复制代码
default-table-type,能够查看当前的存储引擎
show engines \g复制代码

奇怪,为什么没有了呢?网上求证一下,在 5.5.3 取消了这个参数
可以通过下面两种方法查询当前数据库支持的存储引擎
create table cxuan002(id int(10),name varchar(20)) engine = MyISAM;复制代码

在创建新表的时候,可以通过增加ENGINE关键字设置新建表的存储引擎。
alter table cxuan003 engine = myisam;复制代码

上图我们指定了MyISAM的存储引擎。
如果你不知道表的存储引擎怎么办?你可以通过show create table来查看

如果不指定存储引擎的话,从MySQL 5.1 版本之后,MySQL 的默认内置存储引擎已经是 InnoDB了。建一张表看一下

如上图所示,我们没有指定默认的存储引擎,下面查看一下表

可以看到,默认的存储引擎是InnoDB。
如果你的存储引擎想要更换,可以使用
select character_set_name, default_collate_name, description, maxlen from information_schema.character_sets;复制代码
来更换,更换完成后回显示0 rows affected,但其实已经操作成功

我们使用show create table

create table product(id int(11),name varchar(20),price float(10,2));复制代码
 새 테이블을 생성할 때 다음을 추가할 수 있습니다.
새 테이블을 생성할 때 다음을 추가할 수 있습니다.
ENGINE키워드는 새 테이블의 스토리지 엔진을 설정합니다.
insert into product values(1, "apple","3.5"),(2,"banana","4.2"),(3,"melon","1.2");复制代码
위 그림에서는
MyISAM의 스토리지 엔진을 지정했습니다. 테이블의 스토리지 엔진을 모른다면?
show create table을 통해 보실 수 있습니다
 스토리지 엔진을 지정하지 않으면 MySQL 5.1 버전부터 MySQL의 기본 내장 스토리지 엔진은 이미 InnoDB입니다. 테이블을 만들고 살펴보세요
위 그림과 같이 기본 스토리지 엔진을 지정하지 않았습니다. 아래 표를 확인하세요
스토리지 엔진을 지정하지 않으면 MySQL 5.1 버전부터 MySQL의 기본 내장 스토리지 엔진은 이미 InnoDB입니다. 테이블을 만들고 살펴보세요
위 그림과 같이 기본 스토리지 엔진을 지정하지 않았습니다. 아래 표를 확인하세요
 기본 저장공간인 것을 알 수 있습니다 엔진은
기본 저장공간인 것을 알 수 있습니다 엔진은
InnoDB입니다. 스토리지 엔진을 교체하려면
create view v1 as select * from product;复制代码

show create table을 사용합니다. 테이블의 SQL을 확인하면 알 수 있습니다스토리지 엔진 특성다음은 일반적으로 사용되는 여러 스토리지 엔진과 기본 특성을 소개합니다. 이러한 스토리지 엔진은 **MyISAM, InnoDB, MEMORY AND MERGE**입니다.
버전 5.1 이전에는 MyISAM이 MySQL의 기본 스토리지 엔진이었습니다. MyISAM은 동시성이 낮았고 사용된 시나리오가 적었습니다.
는트랜잭션작업을 지원하지 않으며 ACID 기능은 더 이상 존재하지 않으며 이 디자인은 성능과 효율성을 위한 것입니다.事务操作,ACID 的特性也就不存在了,这一设计是为了性能和效率考虑的。
不支持外键操作,如果强行增加外键,MySQL 不会报错,只不过外键不起作用。
MyISAM 默认的锁粒度是表级锁,所以并发性能比较差,加锁比较快,锁冲突比较少,不太容易发生死锁的情况。
MyISAM 会在磁盘上存储三个文件,文件名和表名相同,扩展名分别是.frm(存储表定义)、.MYD(MYData,存储数据)、MYI(MyIndex,存储索引)。这里需要特别注意的是 MyISAM 只缓存索引文件,并不缓存数据文件。
MyISAM 支持的索引类型有全局索引(Full-Text)、B-Tree 索引、R-Tree 索引
Full-Text 索引:它的出现是为了解决针对文本的模糊查询效率较低的问题。
B-Tree 索引:所有的索引节点都按照平衡树的数据结构来存储,所有的索引数据节点都在叶节点
R-Tree索引:它的存储方式和 B-Tree 索引有一些区别,主要设计用于存储空间和多维数据的字段做索引,目前的 MySQL 版本仅支持 geometry 类型的字段作索引,相对于 BTREE,RTREE 的优势在于范围查找。
数据库所在主机如果宕机,MyISAM 的数据文件容易损坏,而且难以恢复。
增删改查性能方面:SELECT 性能较高,适用于查询较多的情况
自从 MySQL 5.1 之后,默认的存储引擎变成了 InnoDB 存储引擎,相对于 MyISAM,InnoDB 存储引擎有了较大的改变,它的主要特点是
可重复读(repetable-read)、通过MVCC(并发版本控制)来实现的。能够解决脏读和不可重复读的问题。行级锁,并发性能比较好,会发生死锁的情况。.frm文件存储表结构定义,但是不同的是,InnoDB 的表数据与索引数据是存储在一起的,都位于 B+ 数的叶子节点上,而 MyISAM 的表数据和索引数据是分开的。MEMORY 存储引擎使用存在内存中的内容来创建表。每个 MEMORY 表实际只对应一个磁盘文件,格式是.frm。 MEMORY 类型的表访问速度很快,因为其数据是存放在内存中。默认使用HASH 索引。
MERGE 存储引擎是一组 MyISAM 表的组合,MERGE 表本身没有数据,对 MERGE 类型的表进行查询、更新、删除的操作,实际上是对内部的 MyISAM 表进行的。MERGE 表在磁盘上保留两个文件,一个是.frm文件存储表定义、一个是.MRG
외래 키작업을 지원하지 않습니다. 강제로 외래 키를 추가하면 MySQL은 오류를 보고하지 않지만 외래 키는 작동하지 않습니다.테이블 수준 잠금이므로 동시성 성능이 상대적으로 낮고 잠금이 더 빠르며 잠금 충돌이 적고 교착 상태가 발생할 가능성이 적습니다. . MyISAM은 디스크에 세 개의 파일을 저장합니다. 파일 이름과 테이블 이름은 동일하며 확장자는
.frm(저장 테이블 정의),
.MYD입니다. (MYData, 스토어 데이터),
MYI(MyIndex, 스토어 인덱스). 여기서 특별한 주의가 필요한 점은 MyISAM이
인덱스 파일만 캐시하고 데이터 파일은 캐시하지 않는다는 것입니다. MyISAM에서 지원하는 인덱스 유형에는
글로벌 인덱스(전체 텍스트),
B-트리 인덱스,
R-트리 인덱스가 있습니다. code >전체 텍스트 인덱스: 텍스트에 대한 퍼지 쿼리의 효율성이 낮은 문제를 해결하는 것으로 보입니다. B-Tree 인덱스: 모든 인덱스 노드는 균형 트리의 데이터 구조에 따라 저장되며, 모든 인덱스 데이터 노드는 리프 노드에 위치합니다. R-Tree 인덱스: B-Tree 인덱스와는 저장 방식이 다소 다릅니다. 주로 공간 및 다차원 데이터를 저장하는 필드 인덱싱에 사용하도록 설계되었습니다. 현재 MySQL 버전은 인덱싱을 위해 기하학 유형 필드만 지원하며, RTREE의 장점은 범위 검색입니다. 데이터베이스가 위치한 호스트가 다운되면 MyISAM 데이터 파일이 쉽게 손상되어 복구가 어렵습니다. 추가, 삭제, 수정 및 쿼리 성능: SELECT는 더 높은 성능을 가지며 쿼리가 많은 상황에 적합합니다
MVCC(동시 버전 제어)를 통해 구현되는반복 읽기입니다.더티 읽기및반복 불가능 읽기문제를 해결할 수 있습니다. InnoDB는 외래 키 연산을 지원합니다. InnoDB의 기본 잠금 세분성은행 수준 잠금으로, 동시성 성능이 더 뛰어나지만 교착 상태가 발생할 수 있습니다. MyISAM과 동일하게 InnoDB 스토리지 엔진에도.frm 파일 스토리지 테이블 구조정의가 있지만 차이점은 InnoDB의 테이블 데이터와 인덱스 데이터가 모두 리프에 함께 저장된다는 점입니다. B+ 번호의 노드에서는 MyISAM의 테이블 데이터와 인덱스 데이터가 분리됩니다. InnoDB에는 안전한 로그 파일이 있습니다. 이 로그 파일은 데이터베이스 충돌이나 기타 상황으로 인해 발생한 데이터 손실을 복구하고 데이터 일관성을 보장하는 데 사용됩니다. InnoDB와 MyISAM은 동일한 인덱스 유형을 지원하지만 파일 구조가 다르기 때문에 구체적인 구현이 매우 다릅니다. 추가, 삭제, 수정, 쿼리 성능 측면에서 추가, 삭제, 수정 작업이 많이 수행되는 경우에는 삭제 작업 중에 행을 삭제하고 InnoDB 스토리지 엔진을 사용하는 것이 좋습니다. 테이블을 다시 작성하지 않습니다..frm입니다. MEMORY 유형 테이블은 데이터가 메모리에 저장되므로 매우 빠르게 액세스됩니다. 기본적으로HASH 인덱스가 사용됩니다..frm파일이고 다른 하나는 테이블의 구성을 저장하는.MRG파일입니다. 병합 테이블. 적절한 스토리지 엔진 선택실제 개발 과정에서는 애플리케이션 특성에 따라 적절한 스토리지 엔진을 선택하는 경우가 많습니다.
우리가 자주 접하는 문제는 테이블을 만들 때 적절한 데이터 유형을 선택하는 방법입니다. 일반적으로 적절한 데이터 유형을 선택하면 성능이 향상되고 불필요한 문제가 줄어듭니다. 적절한 데이터 유형을 선택합니다.
char과 varchar는 문자열을 저장하는 데 자주 사용하는 두 가지 데이터 유형입니다. char은 일반적으로 다음과 같은 고정 길이 문자 유형입니다
| 값 | char(5) | 저장소 바이트 |
|---|---|---|
| '' | ' ' | 5바이트 |
| 'cx' | 'cx ' | 5바이트 |
| 'cxuan' | 'cxuan' | 5바이트 |
| 'cxuan007' | 'cxuan' | 5바이트 |
작성한 값에 관계없이 char 문자의 길이가 다음과 같다는 것을 알 수 있습니다. 지정된 문자열 길이가 문자 길이를 지정하기에 충분하지 않으면 공백으로 채워집니다. 문자열 길이를 초과하면 지정된 문자 길이의 문자만 저장됩니다.
여기서 주의할 점: MySQL이
严格模式的话,上面表格最后一行是可以存储的。如果 MySQL 使用了严格模式이외의 다른 것을 사용하는 경우 테이블의 마지막 행을 저장할 때 오류가 보고됩니다.
varchar 문자 유형을 사용하는 경우 예제를 살펴보겠습니다.
| value | varchar(5) | stores bytes |
|---|---|---|
| '' | '' | 1 바이트 |
| 'cx' | 'cx ' | 3바이트 |
| 'cxuan' | 'cxuan' | 6바이트 |
| 'cxuan007' | 'c ' | 6바이트 |
varchar를 사용하면 저장된 바이트가 실제 값에 따라 저장되는 것을 볼 수 있습니다. varchar의 길이가 5인데 왜 3바이트나 6바이트를 저장해야 하는지 궁금할 수도 있는데, 이는 varchar 데이터 형식을 저장용으로 사용할 경우 기본적으로 문자열 길이가 끝에 추가되어 1워드 섹션을 차지하기 때문입니다. (열 선언이 255보다 길면 2바이트가 사용됩니다.) varchar는 빈 문자열을 채우지 않습니다.
일반적으로 char를 사용하여신분증 번호, 휴대폰 번호, 이메일 등 고정 길이 문자열을 저장합니다.varchar를 사용하여 가변 길이 문자열을 저장합니다. char의 길이가 고정되어 있기 때문에 처리 속도는 VARCHAR에 비해 훨씬 빠르지만, 저장 공간을 낭비한다는 단점이 있다. 그러나 MySQL 버전의 지속적인 발전에 따라 varchar 데이터 형식의 성능도 지속적으로 향상되고 향상되고 있다. , 많은 응용 프로그램에서 사용되므로 VARCHAR 유형이 더 일반적으로 사용됩니다.
MySQL에서는 스토리지 엔진마다 CHAR과 VARCHAR의 사용 원칙이 다릅니다
을 사용하는 것이 좋습니다. 일반적으로 적은 양의 텍스트를 저장할 때 CHAR 및 VARCHAR를 선택하고, 많은 양을 저장할 때 데이터의 경우 텍스트의 경우 TEXT와 BLOB를 선택하는 경우가 많습니다. TEXT와 BLOB의 주요 차이점은 BLOB는이진 데이터를 저장할 수 있는 반면 TEXT는문자 데이터만 저장할 수 있다는 것입니다. >, TEXT는 아래쪽으로 세분화되어二进制数据;而 TEXT 只能保存字符数据,TEXT 往下细分有
BLOB 往下细分有
三种,它们最主要的区别就是存储文本长度不同和存储字节不同,用户应该根据实际情况选择满足需求的最小存储类型,下面主要对 BLOB 和 TEXT 存在一些问题进行介绍
TEXT 和 BLOB 在删除数据后会存在一些性能上的问题,为了提高性能,建议使用OPTIMIZE TABLE功能对表进行碎片整理。
也可以使用合成索引来提高文本字段(BLOB 和 TEXT)的查询性能。合成索引就是根据大文本(BLOB 和 TEXT)字段的内容建立一个散列值,把这个值存在对应列中,这样就能够根据散列值查找到对应的数据行。一般使用散列算法比如 md5() 和 SHA1() ,如果散列算法生成的字符串带有尾部空格,就不要把它们存在 CHAR 和 VARCHAR 中,下面我们就来看一下这种使用方式
首先创建一张表,表中记录 blob 字段和 hash 值

向 cxuan005 中插入数据,其中 hash 值作为 info 的散列值。

然后再插入两条数据

插入一条 info 为 cxuan005 的数据

如果想要查询 info 为 cxuan005 的数据,可以通过查询 hash 列来进行查询

这是合成索引的例子,如果要对 BLOB 进行模糊查询的话,就要使用前缀索引。
其他优化 BLOB 和 TEXT 的方式:
浮点数指的就是含有小数的值,浮点数插入到指定列中超过指定精度后,浮点数会四舍五入,MySQL 中的浮点数指的就是float和double,定点数指的是decimal
TEXT

BLOB이 있고, 다시
BLOBMEDIUMBLOBLONGBLOB으로 세분화됩니다. . 주요 차이점은 텍스트 길이입니다. 저장 바이트가 다르므로 사용자는 실제 상황에 따라 필요에 맞는 최소 저장 유형을 선택해야 합니다. 다음은 주로 BLOB 및 TEXT와 관련된 몇 가지 문제를 소개합니다. TEXT 및 BLOB에서는 데이터 삭제 후 몇 가지 성능 문제가 발생합니다. 성능 향상을 위해 테이블 조각 모음을 수행하는 해시 값이 info의 해시 값으로 사용되는 cxuan005에 데이터를 삽입합니다.
그런 다음 데이터 두 개를 더 삽입하세요
해시 값이 info의 해시 값으로 사용되는 cxuan005에 데이터를 삽입합니다.
그런 다음 데이터 두 개를 더 삽입하세요
 정보가 포함된 데이터 조각을 cxuan005
정보가 포함된 데이터 조각을 cxuan005
 정보가 다음과 같은 데이터를 쿼리하려는 경우 cxuan005, 해시 열을 통해 쿼리하여
합성 인덱스의 예입니다. BLOB에 대해 퍼지 쿼리를 수행하려면 접두사 인덱스를 사용해야 합니다. BLOB 및 TEXT를 최적화하는 다른 방법: 필요하지 않은 경우 BLOB 및 TEXT 인덱스를 검색하지 마세요. BLOB 또는 TEXT 열을 별도의 테이블로 분리하세요.
정보가 다음과 같은 데이터를 쿼리하려는 경우 cxuan005, 해시 열을 통해 쿼리하여
합성 인덱스의 예입니다. BLOB에 대해 퍼지 쿼리를 수행하려면 접두사 인덱스를 사용해야 합니다. BLOB 및 TEXT를 최적화하는 다른 방법: 필요하지 않은 경우 BLOB 및 TEXT 인덱스를 검색하지 마세요. BLOB 또는 TEXT 열을 별도의 테이블로 분리하세요.
float및double을 참조하고 고정 소수점 숫자는를 참조합니다. 소수점. 고정 소수점 숫자가 더 정확할 수 있습니다. 부동 소수점 숫자의 정확성을 설명하기 위해 예를 사용하겠습니다먼저 부동 소수점 숫자 문제를 테스트하기 위해 cxuan006 테이블을 생성하므로 여기서 선택한 데이터 유형은 float입니다 그런 다음 두 개의 데이터 조각을 삽입합니다. 각각

그런 다음 쿼리를 실행하면 쿼리된 두 데이터가 서로 다르게 반올림되는 것을 확인할 수 있습니다.

부동 소수점 수와 고정 소수점 수의 정확성 문제를 명확하게 확인하기 위해 다음을 살펴보겠습니다. 예

먼저 cxuan006의 두 필드를 동일한 길이와 소수 자릿수로 수정합니다
그런 다음 두 개의 데이터를 삽입합니다

쿼리 작업을 실행하면 부동 소수점 숫자가 고정 소수점 숫자보다 작으면 오류가 발생한다고 합니다

MySQL에서 표시하는 데 사용되는 날짜 유형은DATE, TIME, DATETIME, TIMESTAMP이며
138개의 사진이 도움이 될 것입니다. MySQL을 시작하세요
날짜 유형 간의 차이점은 이 기사에서 소개되었으므로 여기서는 자세히 설명하지 않겠습니다. 다음은 시간대와 관련되어 현재 시간을 더 잘 반영할 수 있는
MySQL 문자 집합을 알아봅시다. 간단히 말해서 문자 집합은 텍스트 기호, 인코딩 및 비교 규칙의 집합입니다. 1960년에 미국 표준 기구 ANSI는 유명한ASCII(정보 교환을 위한 미국 표준 코드)인 최초의 컴퓨터 문자 집합을 출시했습니다. ASCII 인코딩 이후 각 국가 및 국제기구에서는ISO-8859-1,GBK등과 같은 고유한 문자 집합을 개발했습니다.ASCII(American Standard Code for Information Interchange)。自从 ASCII 编码后,每个国家、国际组织都研究了一套自己的字符集,比如ISO-8859-1、GBK等。
但是每个国家都使用自己的字符集为移植性带来了很大的困难。所以,为了统一字符编码,国际标准化组织(ISO)
국제표준화기구(ISO)에서는 거의 모든 문자 인코딩을 수용하는 통일된 문자 표준, 즉 유니코드 인코딩을 지정했습니다. 다음은 긴 코딩 방법
对数据库来说,字符集是很重要的,因为数据库存储的数据大多数都是各种文字,字符集对数据库的存储、性能、系统的移植来说都非常重要。
MySQL 支持多种字符集,可以使用show character set;来查看所有可用的字符集

或者使用
select character_set_name, default_collate_name, description, maxlen from information_schema.character_sets;复制代码
来查看。
使用information_schema.character_set来查看字符集和校对规则。
我们上面介绍到了索引的几种类型并对不同的索引类型做了阐述,阐明了优缺点等等,下面我们从设计角度来聊一下索引,关于索引,你必须要知道的一点就是:索引是数据库用来提高性能的最常用工具。
所有的 MySQL 类型都可以进行索引,对相关列使用索引是提高SELECT查询性能的最佳途径。MyISAM 和 InnoDB 都是使用BTREE作为索引,MySQL 5 不支持函数索引,但是支持前缀索引。
前缀索引顾名思义就是对列字段的前缀做索引,前缀索引的长度和存储引擎有关系。MyISAM 前缀索引的长度支持到 1000 字节,InnoDB 前缀索引的长度支持到 767 字节,索引值重复性越低,查询效率也就越高。
在 MySQL 中,主要有下面这几种索引
全局索引(FULLTEXT):全局索引,目前只有 MyISAM 引擎支持全局索引,它的出现是为了解决针对文本的模糊查询效率较低的问题,并且只限于 CHAR、VARCHAR 和 TEXT 列。哈希索引(HASH):哈希索引是 MySQL 中用到的唯一 key-value 键值对的数据结构,很适合作为索引。HASH 索引具有一次定位的好处,不需要像树那样逐个节点查找,但是这种查找适合应用于查找单个键的情况,对于范围查找,HASH 索引的性能就会很低。默认情况下,MEMORY 存储引擎使用 HASH 索引,但也支持 BTREE 索引。B-Tree 索引:B 就是 Balance 的意思,BTree 是一种平衡树,它有很多变种,最常见的就是 B+ Tree,它被 MySQL 广泛使用。R-Tree 索引:R-Tree 在 MySQL 很少使用,仅支持 geometry 数据类型,支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几种,相对于 B-Tree 来说,R-Tree 的优势在于范围查找。索引可以在创建表的时候进行创建,也可以单独创建,下面我们采用单独创建的方式,我们在 cxuan004 上创建前缀索引

我们使用explain进行分析,可以看到 cxuan004 使用索引的情况

如果不想使用索引,可以删除索引,索引的删除语法是

创建索引的时候,要尽量考虑以下原则,便于提升索引的使用效率。
索引位置,选择索引最合适的位置是出现在where语句中的列,而不是select关键字后的选择列表中的列。唯一索引,顾名思义,唯一索引的值是唯一的,可以更快速的确定某条记录,例如学生的学号就适合使用唯一性索引,而学生的性别则不适合使用,因为不管搜索哪个值,都差不多有一半的行。前缀索引,如果索引的值很长,那么查询速度会受到影响,这个时候应该使用前缀索引,对列的某几个字符进行索引,可以提高检索效率。MySQL 从 5.0 开始就提供了视图功能,下面我们对视图功能进行介绍。
视图的英文名称是view,它是一种虚拟存在的表。视图对于用户来说是透明的,它并不在数据库中实际存在,视图是使用数据库行和列动态组成的表,那么视图相对于数据库表来说,优势体现在哪里?
视图相对于普通的表来说,优势包含下面这几项
视图的操作包括创建或者修改视图、删除视图以及查看视图定义。
使用create view来创建视图
为了演示功能,我们先创建一张表product表,有三个字段,id,name,price,下面是建表语句
create table product(id int(11),name varchar(20),price float(10,2));复制代码
然后我们向其中插入几条数据
insert into product values(1, "apple","3.5"),(2,"banana","4.2"),(3,"melon","1.2");复制代码
插入完成后的表结构如下

然后我们创建视图
create view v1 as select * from product;复制代码
然后我们查看一下 v1 视图的结构
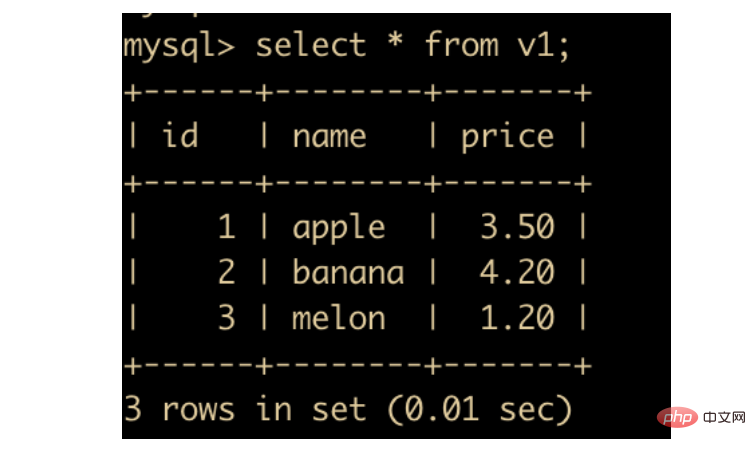
可以看到我们把 product 中的数据放在了视图中,也相当于是创建了一个 product 的副本,只不过这个副本跟表无关。
视图使用
show tables;复制代码
也能看到所有的视图。
删除视图的语法是
drop view v1;复制代码

能够直接进行删除。
视图还有其他操作,比如查询操作
你还可以使用
describe v1;复制代码

查看表结构
更新视图
update v1 set name = "grape" where id = 1;复制代码

MySQL 从 5.0 开始起就支持存储过程和函数了。
那么什么是存储过程呢?
存储过程是在数据库系统中完成一组特定功能的 SQL 语句集,它存储在数据库系统中,一次编译后永久有效。那么使用存储过程有什么优点呢?
使用存储过程有什么缺点?
在认识到存储过程是什么之后,我们就来使用一下存储过程,这里需要先了解一个小技巧,也就是delimiter的用法,delimiter 用于自定义结束符,什么意思呢,如果你使用
delimiter ?复制代码
的话,那么你在 sql 语句末使用;是不能使 SQL 语句执行的,不信?我们可以看下

可以看到,我们在 SQL 语句的行末使用了;但是我们却没有看到执行结果。下面我们使用
delimiter ;复制代码
恢复默认的执行条件再来看下

我们创建存储过程首先要把;替换为?,下面是一个存储过程的创建语句
mysql> delimiter ? mysql> create procedure sp_product() -> begin -> select * from product; -> end ?复制代码

存储过程实际上是一种函数,所以创建完毕后,我们可以使用call方法来调用这个存储过程

因为我们上面定义了使用 delimiter ? 来结尾,所以这里也应该使用。
存储过程也可以接受参数,比如我们定义一种接收参数的情况

然后我们使用call调用这个存储过程

可以看到,当我们调用 id = 2 的时候,存储过程的 SQL 语句相当于是
select * from product where id = 2;复制代码
所以只查询出 id = 2 的结果。
一次只能删除一个存储过程,删除存储过程的语法如下
drop procedure sp_product ;复制代码
直接使用 sp_product 就可以了,不用加()。
存储过程创建后,用户可能需要需要查看存储过程的状态等信息,便于了解存储过程的基本情况
我们可以使用
show create procedure proc_name;复制代码
在 MySQL 中,变量可分为两大类,即系统变量和用户变量,这是一种粗略的分法。但是根据实际应用又被细化为四种类型,即局部变量、用户变量、会话变量和全局变量。
用户变量是基于会话变量实现的,可以暂存,用户变量与连接有关,也就是说一个客户端定义的变量不能被其他客户端使用看到。当客户端退出时,链接会自动释放。我们可以使用set语句设置一个变量
set @myId = "cxuan";复制代码
然后使用select查询条件可以查询出我们刚刚设置的用户变量

用户变量是和客户端有关系,当我们退出后,这个变量会自动消失,现在我们退出客户端
exit复制代码
现在我们重新登陆客户端,再次使用select条件查询

发现已经没有这个@myId了。
MySQL 中的局部变量与 Java 很类似 ,Java 中的局部变量是 Java 所在的方法或者代码块,而 MySQL 中的局部变量作用域是所在的存储过程。MySQL 局部变量使用declare来声明。
服务器会为每个连接的客户端维护一个会话变量。可以使用
show session variables;复制代码
显示所有的会话变量。
我们可以手动设置会话变量
set session auto_increment_increment=1; 或者使用 set @@session.auto_increment_increment=2;复制代码
然后进行查询,查询会话变量使用

或者使用

当服务启动时,它将所有全局变量初始化为默认值。其作用域为 server 的整个生命周期。
可以使用
show global variables;复制代码
查看全局变量
可以使用下面这两种方式设置全局变量
set global sql_warnings=ON; -- global不能省略 /** 或者 **/ set @@global.sql_warnings=OFF;复制代码
查询全局变量时,可以使用

或者是

MySQL 支持下面这些控制语句
IF 用于实现逻辑判断,满足不同条件执行不同的 SQL 语句
IF ... THEN ...复制代码
CASE 实现比 IF 稍微复杂,语法如下
CASE ... WHEN ... THEN... ... END CASE复制代码
CASE 语句也可以使用 IF 来完成
LOOP 用于实现简单的循环
label:LOOP ... END LOOP label;复制代码
如果...中不写 SQL 语句的话,那么就是一个简单的死循环语句
用来表示从标注的流程构造中退出,通常和 BEGIN...END 或者循环一起使用
ITERATE 语句必须用在循环中,作用是跳过当前循环的剩下的语句,直接进入下一轮循环。
带有条件的循环控制语句,当满足条件的时候退出循环。
REPEAT ... UNTIL END REPEAT;复制代码
WHILE 语句表示的含义和 REPEAT 相差无几,WHILE 循环和 REPEAT 循环的区别在于:WHILE 是满足条件才执行循环,REPEAT 是满足条件退出循环;
MySQL 从 5.0 开始支持触发器,触发器一般作用在表上,在满足定义条件时触发,并执行触发器中定义的语句集合,下面我们就来一起认识一下触发器。
举个例子来认识一下触发器:比如你有一个日志表和金额表,你每录入一笔金额就要进行日志表的记录,你会怎么样?同时在金额表和日志表插入数据吗?如果有了触发器,你可以直接在金额表录入数据,日志表会自动插入一条日志记录,当然,触发器不仅只有新增操作,还有更新和删除操作。
我们可以用如下的方式创建触发器
create trigger triggername triggertime triggerevent on tbname for each row triggerstmt复制代码
上面涉及到几个参数,我知道你有点懵逼,解释一下。
triggername:这个指的就是触发器的名字triggertime:这个指的就是触发器触发时机,是BEFORE还是AFTERtriggerevent: 这个指的就是触发器触发事件,一共有三种事件:INSERT、UPDATE 或者 DELETE。tbname:这个参数指的是触发器创建的表名,在哪个表上创建triggerstmt: 触发器的程序体,也就是 SQL 语句所以,可以创建六种触发器
BEFORE INSERT、AFTER INSERT、BEFORE UPDATE、AFTER UPDATE、BEFORE DELETE、AFTER DELETE
上面的for each now表示任何一条记录上的操作都会触发触发器。
下面我们通过一个例子来演示一下触发器的操作
我们还是用上面的 procuct 表做例子,我们创建一个 product_info 产品信息表。
create table product_info(p_info varchar(20)); 复制代码
然后我们创建一个trigger

我们在 product 表中插入一条数据
insert into product values(4,"pineapple",15.3);复制代码
我们进行 select 查询,可以看到现在 product 表中有四条数据

我们没有向 product_info 表中插入数据,现在我们来看一下 product_info 表中,我们预想到是有数据的,具体来看下

这条数据是什么时候插入的呢?我们在创建触发器tg_pinfo的时候插入了的这条数据。
触发器可以使用drop进行删除,具体删除语法如下
drop trigger tg_pinfo;复制代码
和删除表的语法是一样的
我们经常会查看触发器,可以通过执行show triggers命令查看触发器的状态、语法等信息。
另一种查询方式是查询表中的information_schema.triggers表,这个可以查询指定触发器的指定信息,操作起来方便很多
注意:触发器的使用有两个限制
- 触发程序不能调用将数据返回客户端的存储程序。也不能使用 CALL 语句的动态 SQL 语句。
- 不能在触发器中开始和结束语句,例如 START TRANSACTION

更多相关免费学习推荐:mysql教程(视频)
| ASCII | 이 단일 바이트 7자리 인코딩 | |
|---|---|---|
| 문자 집합 | ||
| 싱글바이트 8비트 인코딩 | GBK | |
| 더블바이트 인코딩 | UTF-8 | |
| 1 - 4바이트 인코딩 | UTF -16 | |
| 2바이트 또는 4바이트 인코딩 | UTF-32 | |
| 4바이트 인코딩 |
위 내용은 MySQL 발전에 도움이 되는 47장의 사진의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



