

JavaScript칼럼의 개발자로서 JavaScript 엔진의 작동 방식에 대한 깊은 이해는 코드의 성능 특성을 이해하는 데 도움이 됩니다. 이 기사에서는 V8뿐만 아니라 모든 JavaScript 엔진에 공통적인 몇 가지 주요 기본 사항을 다룹니다.
모든 것은 여러분이 작성하는 JavaScript 코드로 시작됩니다. JavaScript 엔진은 소스 코드를 구문 분석하여 이를 추상 구문 트리(AST)로 변환합니다. AST를 기반으로 인터프리터는 작업을 시작하고 바이트코드를 생성할 수 있습니다. 이 시점에서 엔진은 실제로 JavaScript 코드를 실행하기 시작합니다.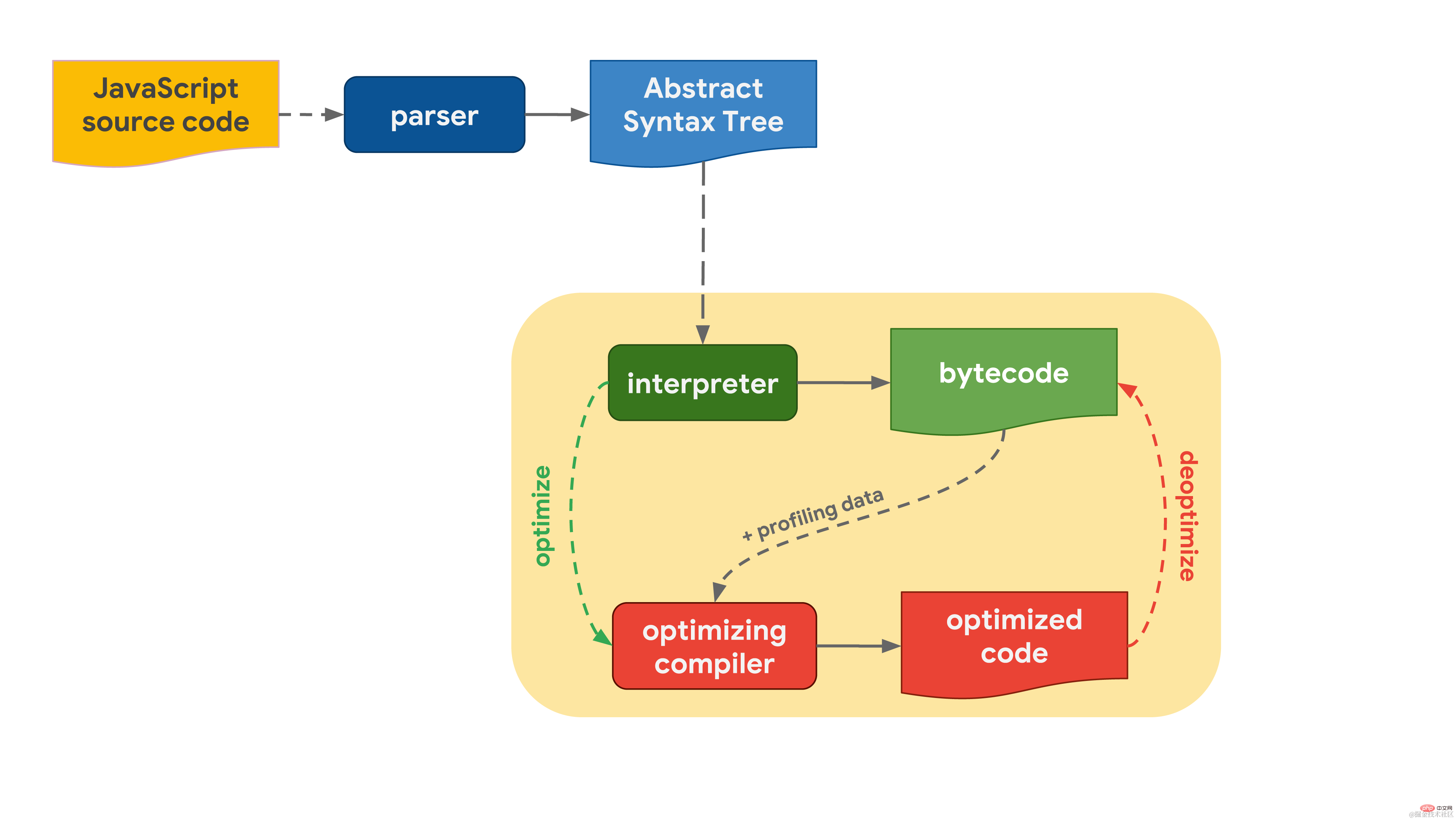 더 빠르게 실행하려면 바이트코드를 프로파일링 데이터와 함께 최적화 컴파일러로 보낼 수 있습니다. 최적화 컴파일러는 사용 가능한 프로파일링 데이터를 기반으로 특정 가정을 한 다음 고도로 최적화된 기계어 코드를 생성합니다.
더 빠르게 실행하려면 바이트코드를 프로파일링 데이터와 함께 최적화 컴파일러로 보낼 수 있습니다. 최적화 컴파일러는 사용 가능한 프로파일링 데이터를 기반으로 특정 가정을 한 다음 고도로 최적화된 기계어 코드를 생성합니다.
어느 시점에서 가정이 잘못된 것으로 판명되면 최적화 컴파일러는 최적화를 취소하고 인터프리터 단계로 돌아갑니다.
이제 실제로 JavaScript 코드를 실행하는 프로세스 부분, 즉 코드가 해석되고 최적화되는 부분을 살펴보고 주요 JavaScript 엔진에서 어떻게 존재하는지 몇 가지 차이점에 대해 논의해 보겠습니다. .
일반적으로 JavaScript 엔진에는 인터프리터와 최적화 컴파일러를 포함하는 처리 흐름이 있습니다. 그 중 인터프리터는 최적화되지 않은 바이트코드를 빠르게 생성할 수 있는 반면, 최적화 컴파일러는 시간이 더 걸리지만 궁극적으로 고도로 최적화된 기계어 코드를 생성할 수 있습니다.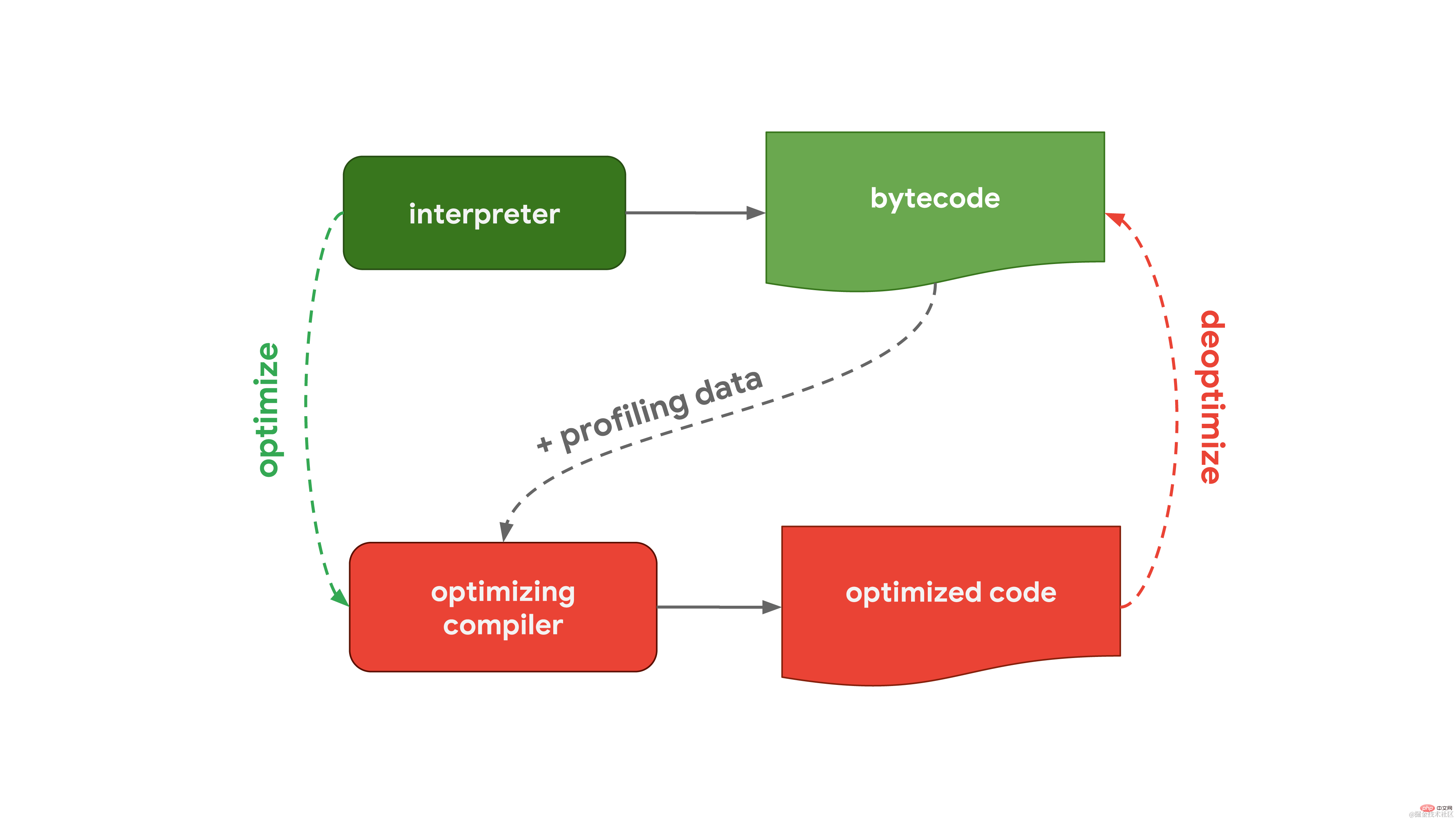 이 일반적인 프로세스는 Chrome 및 Node.js에서 사용되는 Javascript 엔진인 V8의 워크플로와 거의 동일합니다.
이 일반적인 프로세스는 Chrome 및 Node.js에서 사용되는 Javascript 엔진인 V8의 워크플로와 거의 동일합니다.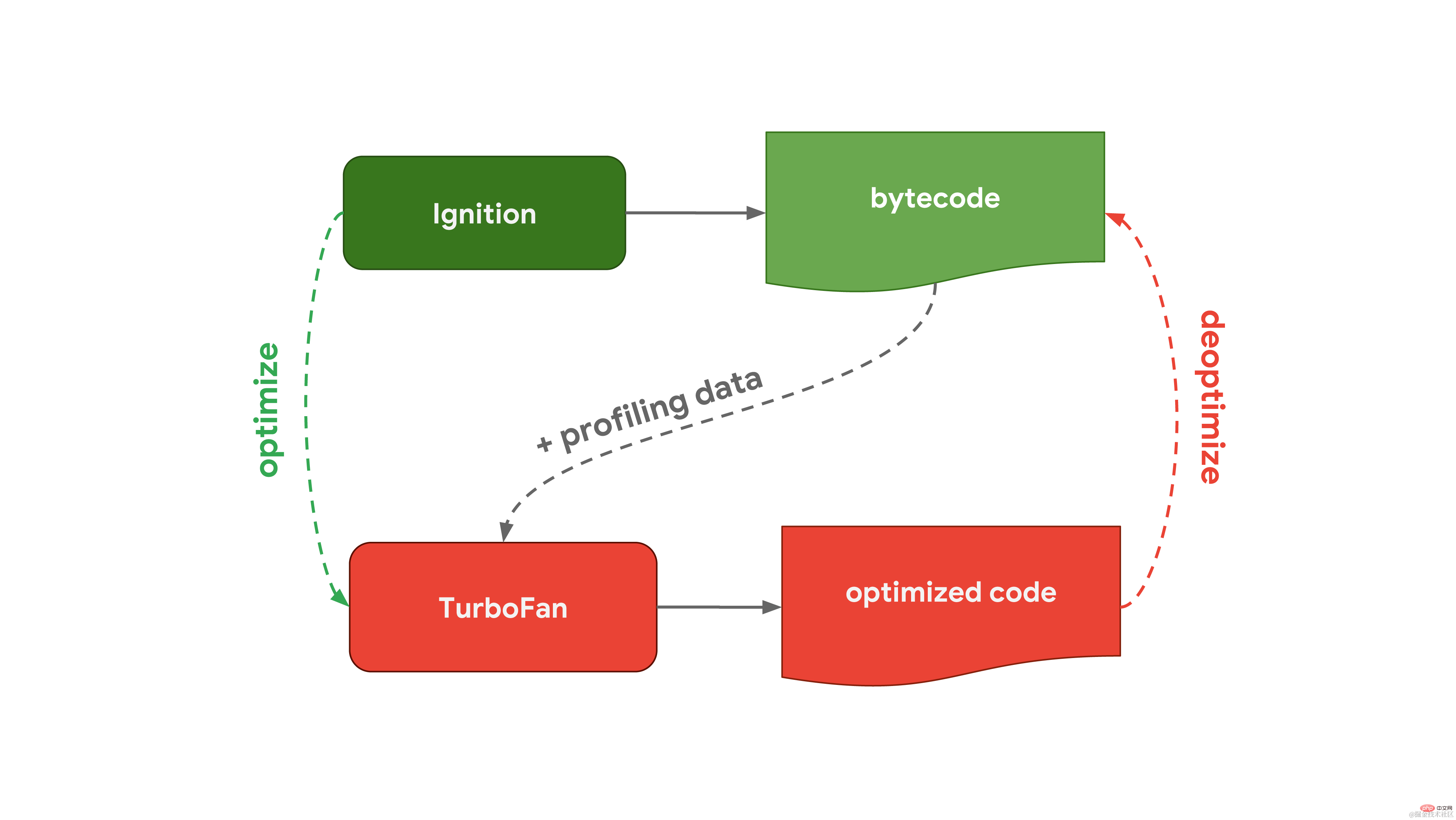 V8의 인터프리터는 Ignition이라고 하며 바이트코드 생성 및 실행을 담당합니다. 바이트코드를 실행하면서 나중에 코드 실행 속도를 높이기 위해 사용할 수 있는 프로파일링 데이터를 수집합니다. 자주 실행되는 등 함수가 뜨거워지면 생성된 바이트코드와 프로파일링 데이터를 당사의 최적화 컴파일러인 Turbofan에 전달하여 프로파일링 데이터를 기반으로 고도로 최적화된 기계어 코드를 생성합니다.
V8의 인터프리터는 Ignition이라고 하며 바이트코드 생성 및 실행을 담당합니다. 바이트코드를 실행하면서 나중에 코드 실행 속도를 높이기 위해 사용할 수 있는 프로파일링 데이터를 수집합니다. 자주 실행되는 등 함수가 뜨거워지면 생성된 바이트코드와 프로파일링 데이터를 당사의 최적화 컴파일러인 Turbofan에 전달하여 프로파일링 데이터를 기반으로 고도로 최적화된 기계어 코드를 생성합니다.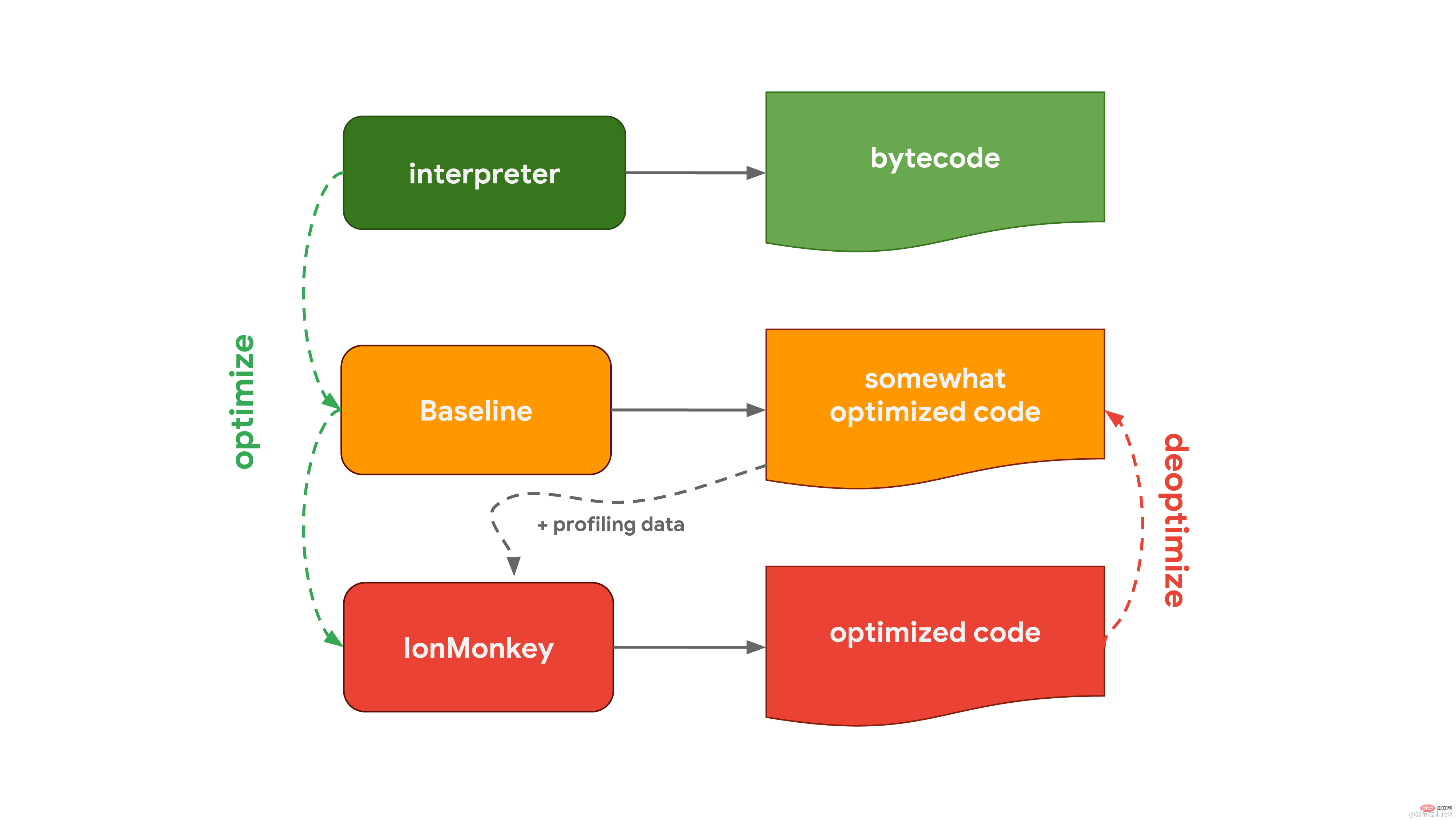 Firefox와 Spidernode에서 Mozilla가 사용하는 JavaScript 엔진인 SpiderMonkey는 다릅니다. 그들은 하나가 아닌 두 개의 최적화 컴파일러를 가지고 있습니다. 인터프리터는 먼저 기준 컴파일러를 통과하여 일부 최적화된 코드를 생성합니다. 그런 다음, IonMonkey 컴파일러는 코드를 실행하는 동안 수집된 프로파일링 데이터와 결합하여 더욱 고도로 최적화된 코드를 생성할 수 있습니다. 최적화 시도가 실패하면 IonMonkey는 Baseline 단계의 코드로 돌아갑니다.
Firefox와 Spidernode에서 Mozilla가 사용하는 JavaScript 엔진인 SpiderMonkey는 다릅니다. 그들은 하나가 아닌 두 개의 최적화 컴파일러를 가지고 있습니다. 인터프리터는 먼저 기준 컴파일러를 통과하여 일부 최적화된 코드를 생성합니다. 그런 다음, IonMonkey 컴파일러는 코드를 실행하는 동안 수집된 프로파일링 데이터와 결합하여 더욱 고도로 최적화된 코드를 생성할 수 있습니다. 최적화 시도가 실패하면 IonMonkey는 Baseline 단계의 코드로 돌아갑니다.
Edge에 사용되는 Microsoft의 JavaScript 엔진인 Chakra는 매우 유사하며 2개의 최적화 컴파일러도 있습니다. 인터프리터는 코드를 약간 최적화된 코드를 생성하는 SimpleJIT(JIT는 Just-In-Time 컴파일러, Just-In-Time 컴파일러를 나타냄)로 최적화합니다. FullJIT는 분석 데이터를 결합하여 보다 최적화된 코드를 생성합니다.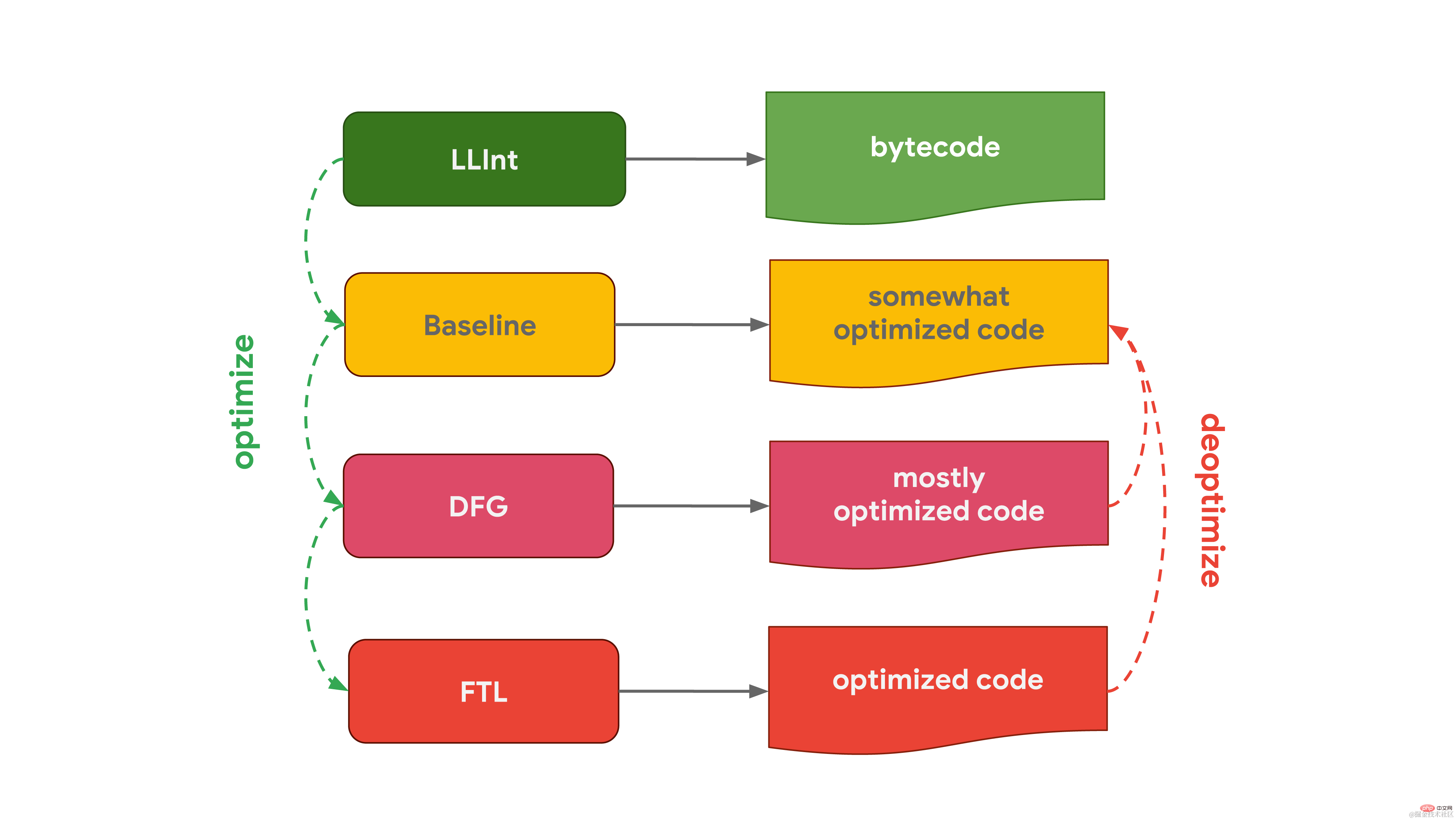 Safari 및 React Native에서 사용되는 Apple의 JavaScript 엔진인 JavaScriptCore(JSC로 약칭)는 세 가지 최적화 컴파일러를 통해 이를 극대화합니다. 하위 수준 인터프리터 LLInt는 코드를 기준 컴파일러로 최적화한 다음 코드를 DFG(데이터 흐름 그래프) 컴파일러로 최적화합니다. 그러면 DFG(데이터 흐름 그래프) 컴파일러는 최적화된 코드를 FTL(Faster Than Light)에 전달할 수 있습니다. ) 선박에서 컴파일합니다.
Safari 및 React Native에서 사용되는 Apple의 JavaScript 엔진인 JavaScriptCore(JSC로 약칭)는 세 가지 최적화 컴파일러를 통해 이를 극대화합니다. 하위 수준 인터프리터 LLInt는 코드를 기준 컴파일러로 최적화한 다음 코드를 DFG(데이터 흐름 그래프) 컴파일러로 최적화합니다. 그러면 DFG(데이터 흐름 그래프) 컴파일러는 최적화된 코드를 FTL(Faster Than Light)에 전달할 수 있습니다. ) 선박에서 컴파일합니다.
일부 엔진에는 왜 더 최적화된 컴파일러가 있나요? 장단점을 따져본 결과입니다. 인터프리터는 바이트코드를 빠르게 생성할 수 있지만 바이트코드는 일반적으로 그리 효율적이지 않습니다. 반면에 컴파일러 최적화는 시간이 더 걸리지만 궁극적으로 더 효율적인 기계어 코드를 생성합니다. 코드를 빠르게 실행하는 것(인터프리터)과 더 많은 시간이 소요되지만 궁극적으로 최적의 성능으로 코드를 실행하는 것(컴파일러 최적화) 사이에는 균형이 있습니다. 일부 엔진은 시간/효율성 특성이 서로 다른 여러 최적화 컴파일러를 추가하여 복잡성을 추가하는 대신 이러한 균형을 보다 세밀하게 제어할 수 있도록 선택합니다. 고려해야 할 또 다른 측면은 메모리 사용량과 관련이 있으며, 이에 대해서는 나중에 관련 기사에서 자세히 설명하겠습니다.
우리는 각 JavaScript 엔진의 인터프리터 및 컴파일러 프로세스 최적화의 주요 차이점을 강조했습니다. 이러한 차이점 외에도 높은 수준에서 모든 JavaScript 엔진은 동일한 아키텍처를 갖습니다. 즉, 파서와 일종의 인터프리터/컴파일러 흐름이 있습니다.
구현의 일부 측면을 확대하여 JavaScript 엔진의 공통점이 무엇인지 살펴보겠습니다.
예를 들어, JavaScript 엔진은 JavaScript 개체 모델을 어떻게 구현하며, JavaScript 개체의 속성에 액세스하는 속도를 높이기 위해 어떤 트릭을 사용합니까? 이 시점에서 모든 주요 엔진은 유사한 구현을 갖고 있는 것으로 나타났습니다.
ECMAScript 사양은 기본적으로 모든 객체를 속성 속성에 매핑된 문자열 키가 있는 사전으로 정의합니다.
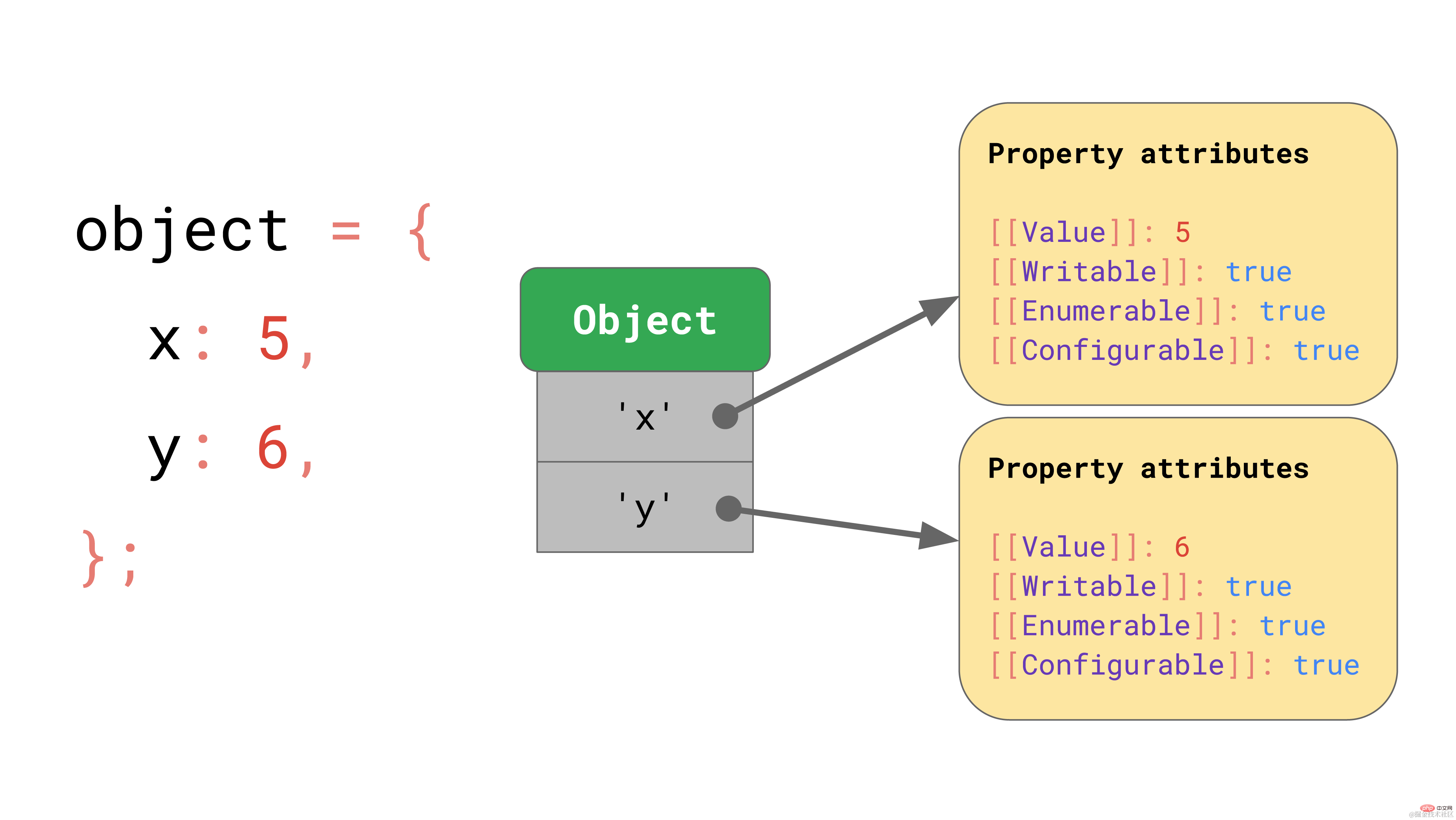 [[값]] 자체 외에도 사양은 다음 속성도 정의합니다.
[[값]] 자체 외에도 사양은 다음 속성도 정의합니다.
[[대괄호]]에 대한 표기법은 약간 이상해 보일 수 있지만 이는 사양이 JavaScript에 직접 노출할 수 없는 속성을 정의하는 방식입니다. JavaScript에서는 Object.getOwnPropertyDescriptor API를 통해 지정된 개체의 속성 값을 계속 얻을 수 있습니다.
const object = { foo: 42 };Object.getOwnPropertyDescriptor(object, 'foo');// → { value: 42, writable: true, enumerable: true, configurable: true }复制代码
이것은 JavaScript가 개체를 정의하는 방법이지만 배열은 어떻습니까?
배열은 특별한 개체로 생각할 수 있습니다. 차이점 중 하나는 배열이 배열 인덱스에 대해 특별한 처리를 수행한다는 것입니다. 여기서 배열 인덱싱은 ECMAScript 사양의 특수 용어입니다. JavaScript에서 배열은 최대 2³²−1개의 요소를 갖도록 제한되며 배열 인덱스는 해당 범위의 유효한 인덱스, 즉 0에서 2³²−2 사이의 정수입니다.
또 다른 차이점은 배열에도 특별한 길이 속성이 있다는 것입니다.
const array = ['a', 'b']; array.length; // → 2array[2] = 'c'; array.length; // → 3复制代码
이 예에서는 배열이 길이 2로 생성되었습니다. 인덱스 2에 다른 요소를 할당하면 길이가 자동으로 업데이트됩니다.
JavaScript는 객체와 비슷한 방식으로 배열을 정의합니다. 예를 들어 배열 인덱스를 포함한 모든 키 값은 명시적으로 문자열로 표시됩니다. 배열의 첫 번째 요소는 키 값 '0' 아래에 저장됩니다.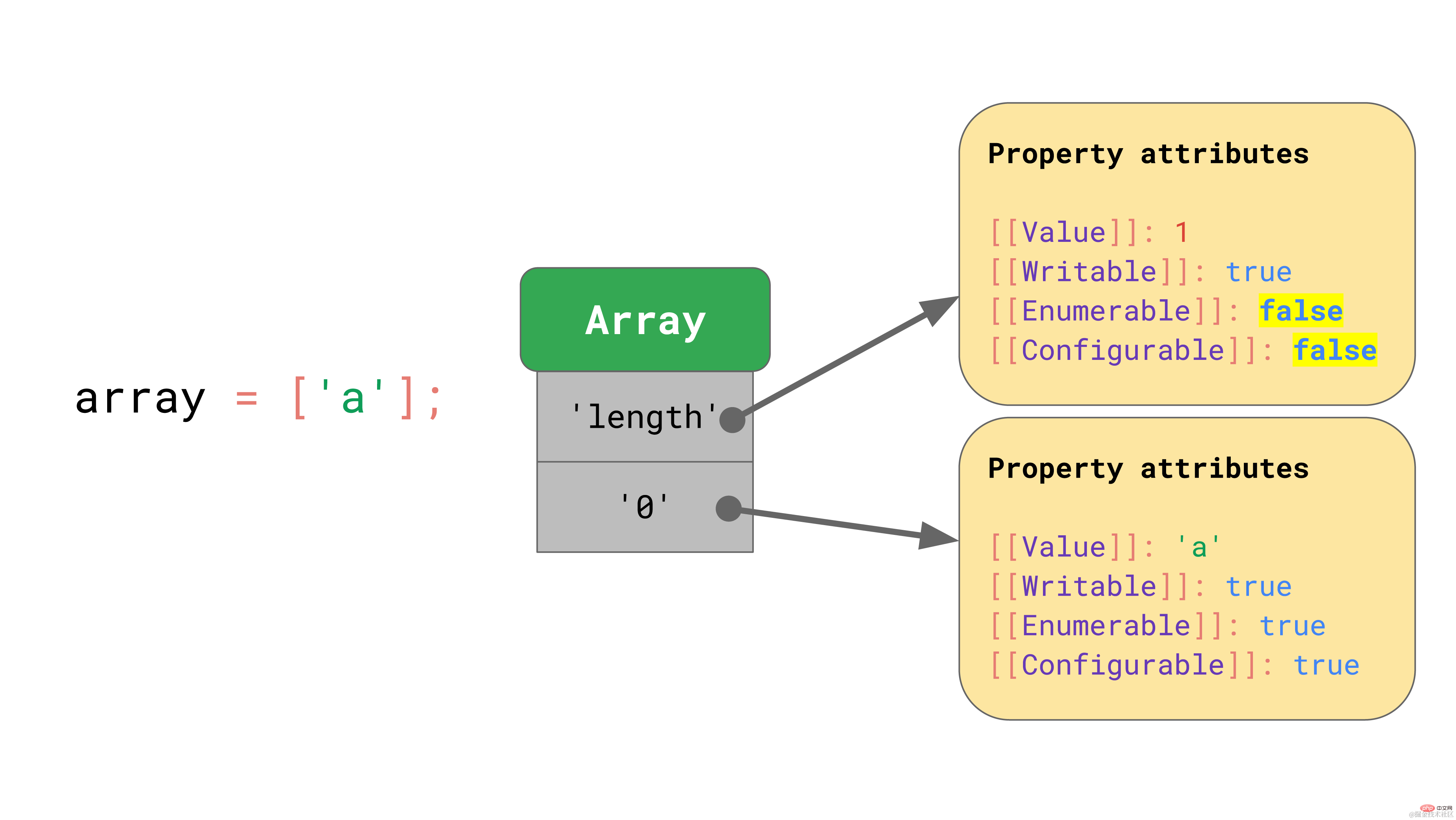 "length" 속성은 열거할 수 없고 구성할 수 없는 또 다른 속성입니다. 요소가 배열에 추가되면 JavaScript는 "length" 속성의 [[value]] 속성을 자동으로 업데이트합니다.
"length" 속성은 열거할 수 없고 구성할 수 없는 또 다른 속성입니다. 요소가 배열에 추가되면 JavaScript는 "length" 속성의 [[value]] 속성을 자동으로 업데이트합니다.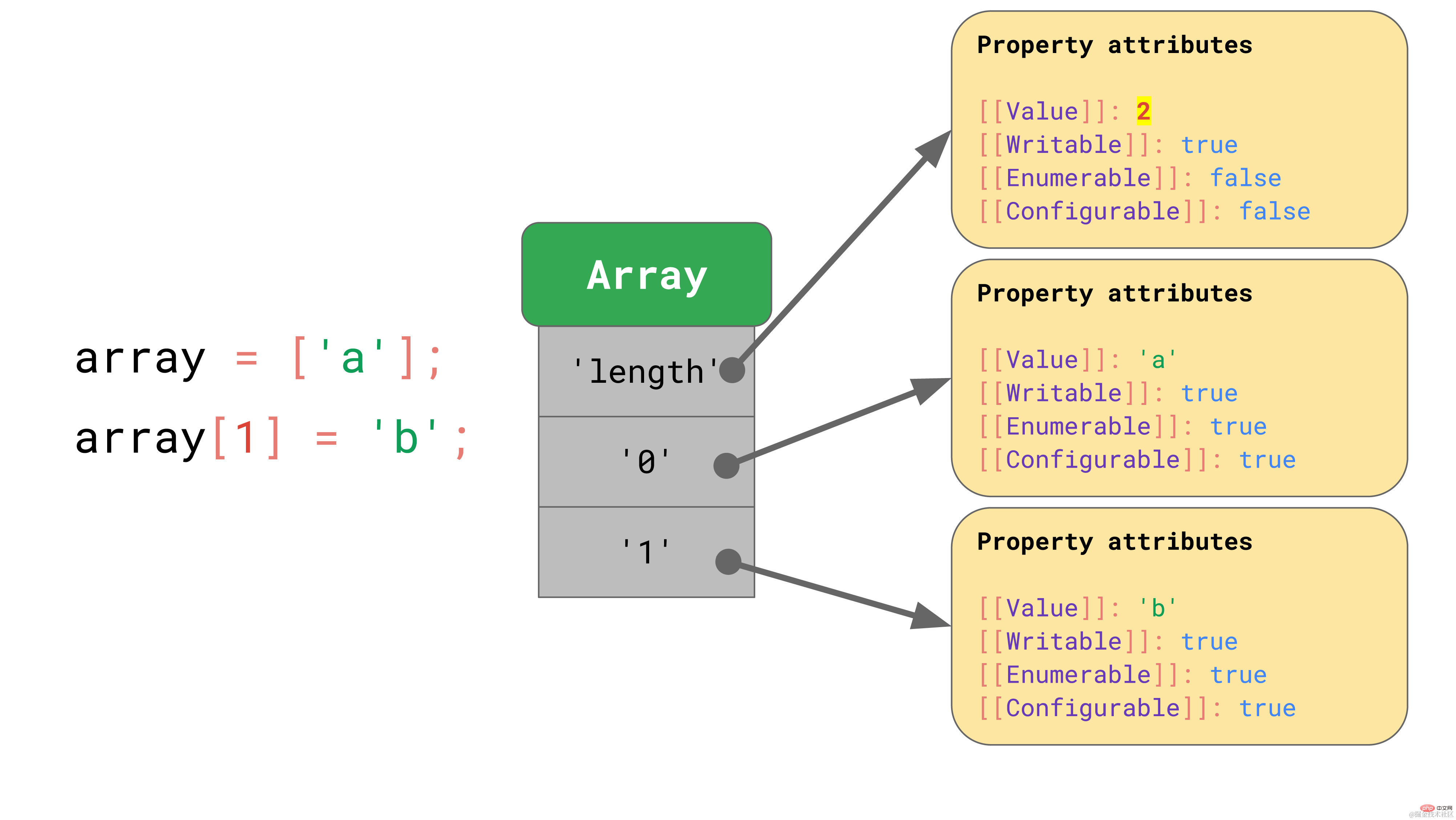
이제 JavaScript에서 개체가 정의되는 방식을 알았으니 JavaScript 엔진이 개체를 효율적으로 사용하는 방법을 자세히 살펴보겠습니다. 전반적으로 속성에 액세스하는 것은 JavaScript 프로그램에서 가장 일반적인 작업입니다. 따라서 JavaScript 엔진이 속성에 빠르게 액세스할 수 있는 것이 중요합니다.
JavaScript 프로그램에서는 여러 개체가 동일한 키-값 속성을 갖는 것이 매우 일반적입니다. 우리는 이 물체들이 같은 모양을 가지고 있다고 말할 수 있습니다.
const object1 = { x: 1, y: 2 };const object2 = { x: 3, y: 4 };// object1 and object2 have the same shape.复制代码
동일한 모양을 가진 개체의 동일한 속성에 액세스하는 것도 매우 일반적입니다.
function logX(object) { console.log(object.x); }const object1 = { x: 1, y: 2 };const object2 = { x: 3, y: 4 }; logX(object1); logX(object2);复制代码
이를 염두에 두고 JavaScript 엔진은 개체의 모양을 기반으로 개체 속성 액세스를 최적화할 수 있습니다. 아래에서 그 원리를 소개하겠습니다.
앞서 논의한 사전 데이터 구조를 사용하는 x 및 y 속성을 가진 객체가 있다고 가정합니다. 여기에는 해당 속성 값을 가리키는 문자열 형식의 키가 포함되어 있습니다.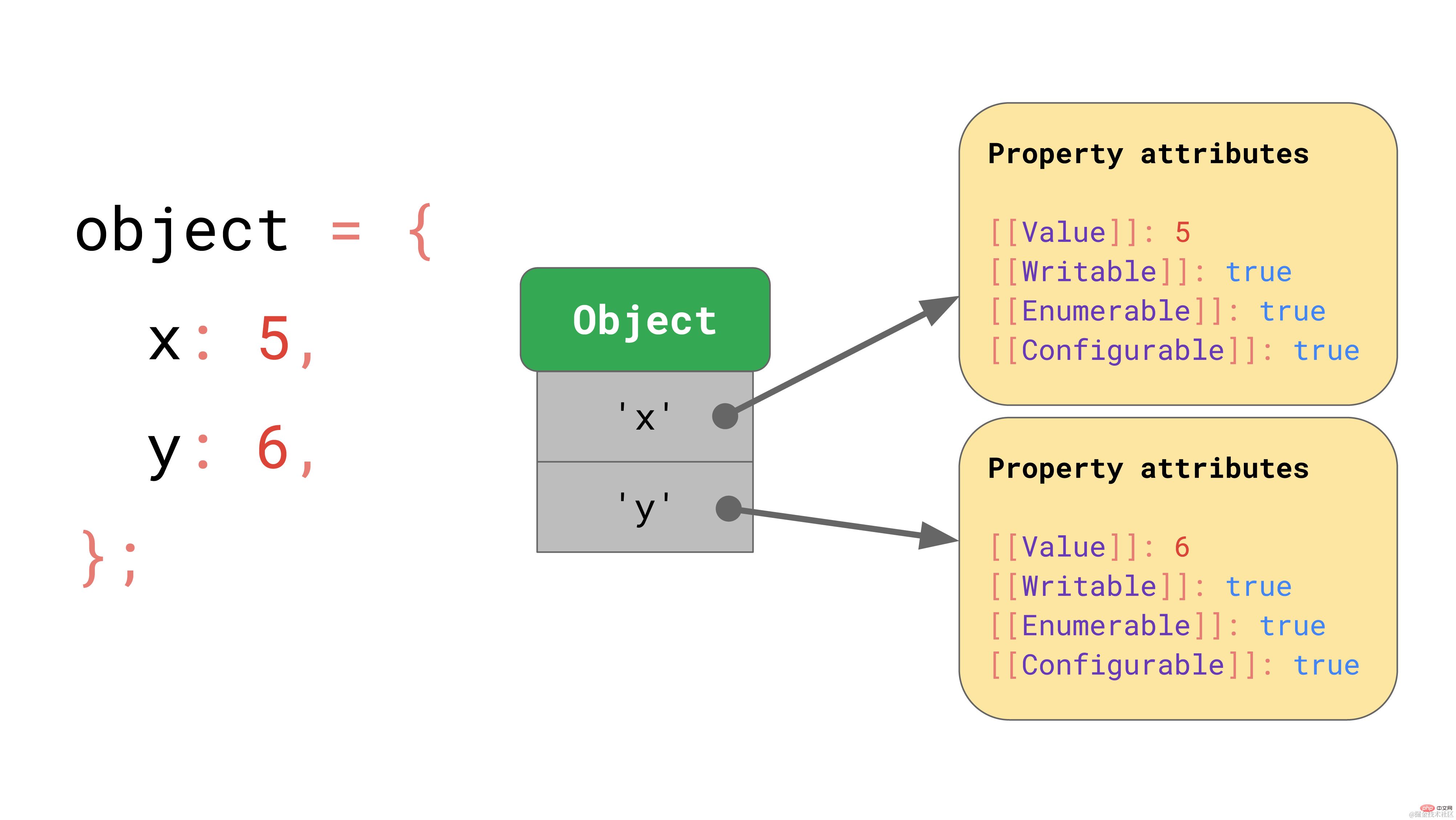
object.y와 같은 속성에 액세스하면 JavaScript 엔진은 JSObject에서 키 값 'y'를 찾은 다음 해당 속성 값을 로드하고 마지막으로 [[값]]을 반환합니다.
그런데 이러한 속성 값은 메모리 어디에 저장되어 있나요? JSObject의 일부로 저장해야 할까요? 나중에 동일한 모양의 객체를 더 많이 만나게 될 것이라고 가정하면 속성 이름과 속성 값이 포함된 완전한 사전을 JSObject 자체에 저장하는 것은 낭비입니다. 같은 모양. 이는 중복이 많고 불필요한 메모리 사용량입니다. 최적화로서 엔진은 객체의 Shape를 별도로 저장합니다.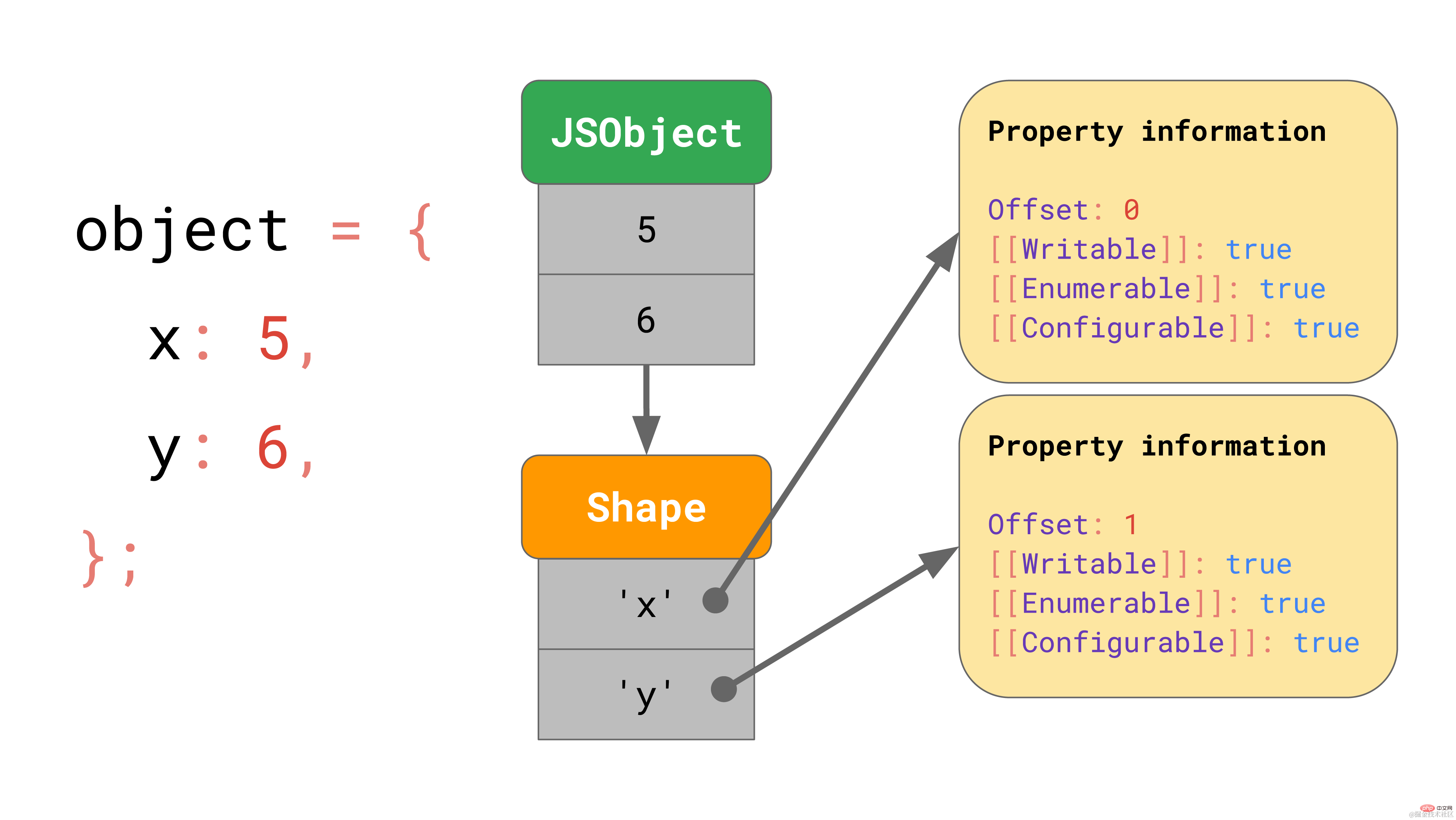 shape에는 [[값]]을 제외한 모든 속성 이름과 속성이 포함됩니다. 또한 모양에는 JavaScript 엔진이 값을 찾을 위치를 알 수 있도록 JSObject 내부 값의 오프셋이 포함되어 있습니다. 동일한 모양을 가진 모든 JSObject는 해당 모양 인스턴스를 가리킵니다. 이제 각 JSObject는 해당 객체에 고유한 값만 저장하면 됩니다.
shape에는 [[값]]을 제외한 모든 속성 이름과 속성이 포함됩니다. 또한 모양에는 JavaScript 엔진이 값을 찾을 위치를 알 수 있도록 JSObject 내부 값의 오프셋이 포함되어 있습니다. 동일한 모양을 가진 모든 JSObject는 해당 모양 인스턴스를 가리킵니다. 이제 각 JSObject는 해당 객체에 고유한 값만 저장하면 됩니다.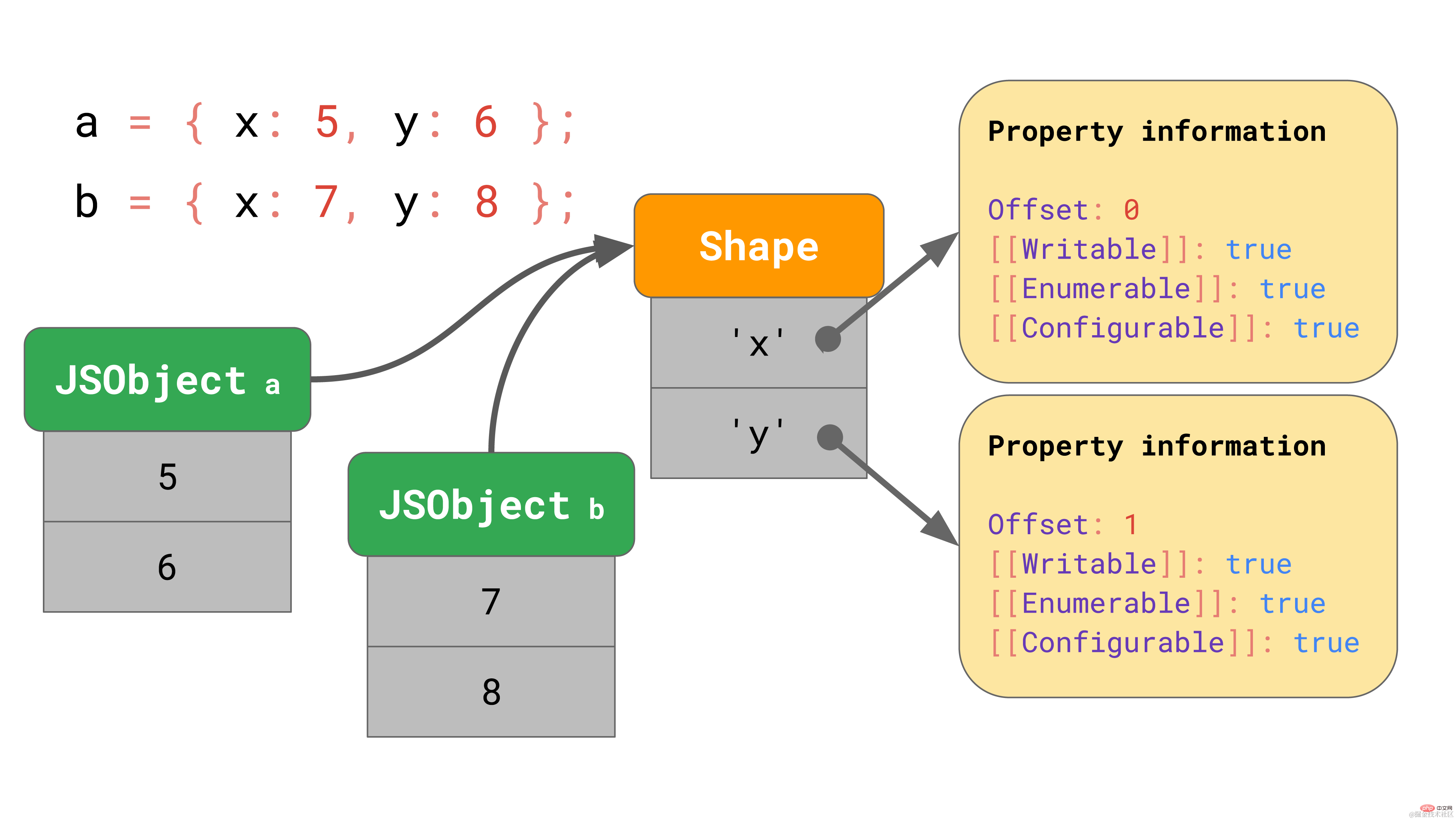 여러 개체가 있을 때 이점은 분명합니다. 객체가 아무리 많아도 모양이 동일하다면 모양과 속성 정보는 한 번만 저장하면 됩니다!
여러 개체가 있을 때 이점은 분명합니다. 객체가 아무리 많아도 모양이 동일하다면 모양과 속성 정보는 한 번만 저장하면 됩니다!
모든 JavaScript 엔진은 모양을 최적화로 사용하지만 이름은 다릅니다:
本文中,我们将继续使用术语 shapes.
如果你有一个具有特定 shape 的对象,但你又向它添加了一个属性,此时会发生什么? JavaScript 引擎是如何找到这个新 shape 的?
const object = {}; object.x = 5; object.y = 6;复制代码
这些 shapes 在 JavaScript 引擎中形成所谓的转换链(transition chains)。下面是一个例子:
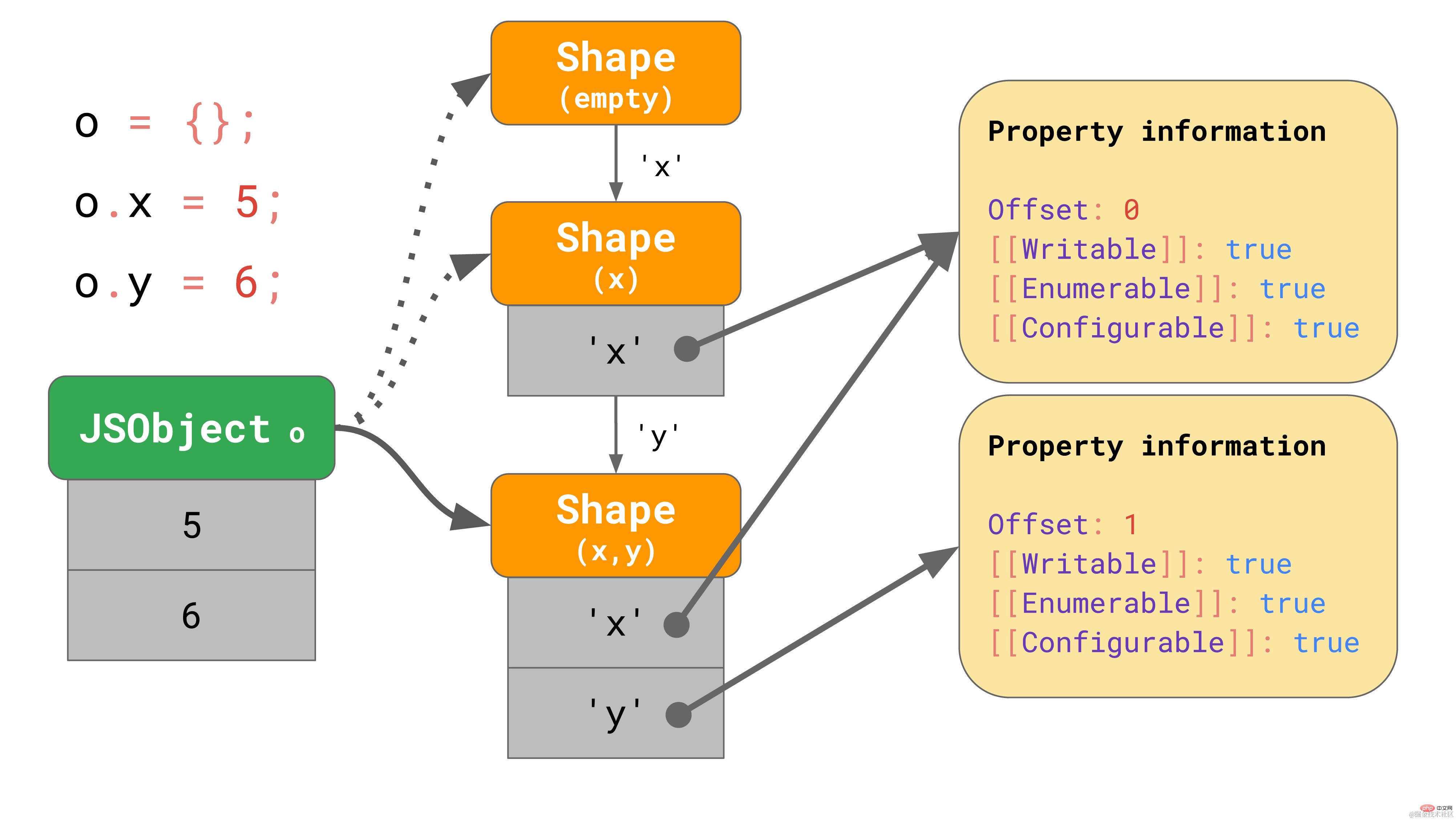
该对象开始没有任何属性,因此它指向一个空的 shape。下一个语句为该对象添加一个值为 5 的属性 "x",所以 JavaScript 引擎转向一个包含属性 "x" 的 shape,并在第一个偏移量为 0 处向 JSObject 添加了一个值 5。 下一行添加了一个属性 'y',引擎便转向另一个包含 'x' 和 'y' 的 shape,并将值 6 添加到 JSObject(位于偏移量 1 处)。
我们甚至不需要为每个 shape 存储完整的属性表。相反,每个shape 只需要知道它引入的新属性。例如,在本例中,我们不必将有关 “x” 的信息存储在最后一个 shape 中,因为它可以在更早的链上找到。要实现这一点,每个 shape 都会链接回其上一个 shape: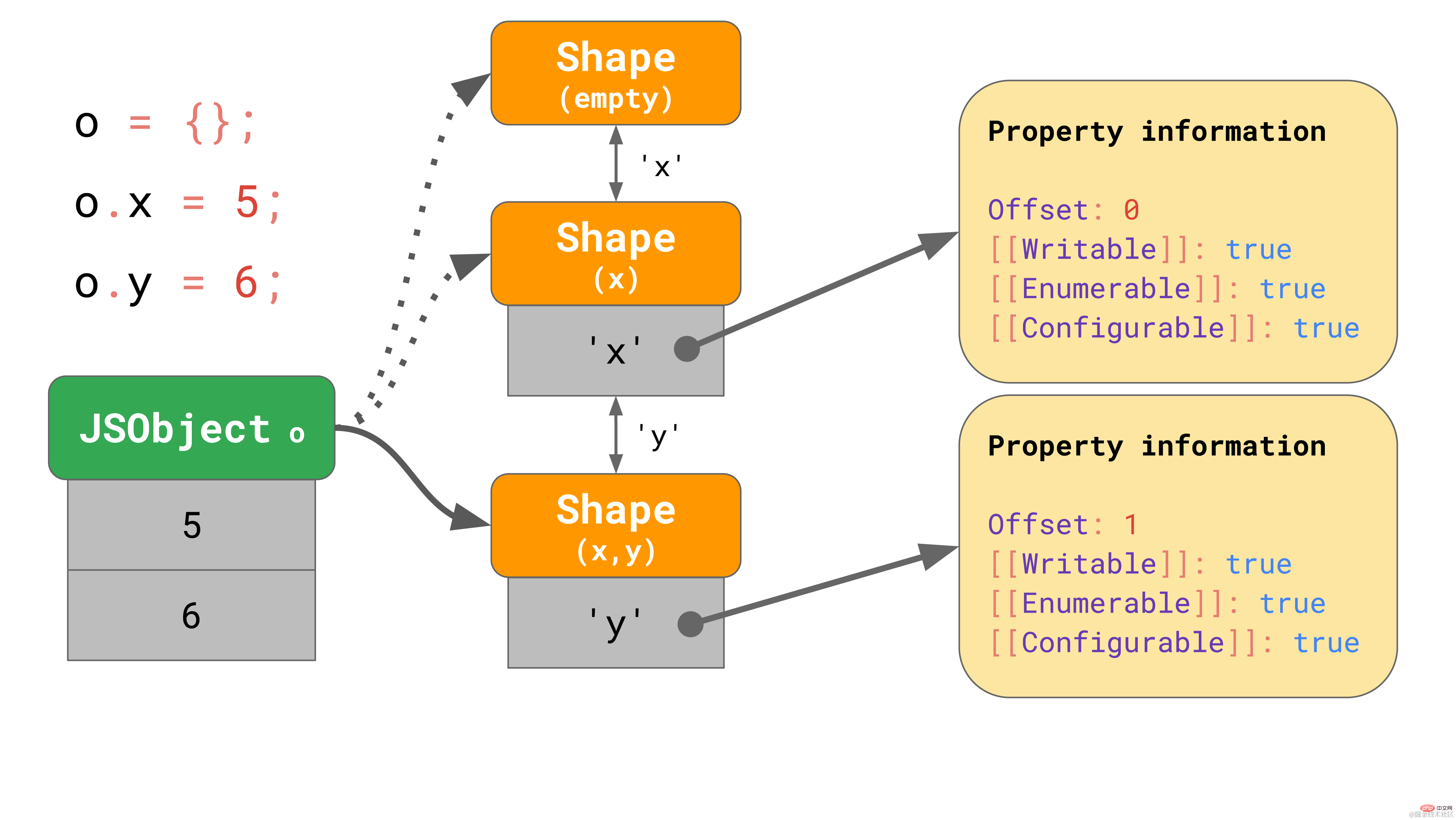
如果你在 JavaScript 代码中写 o.x,JavaScript 引擎会沿着转换链去查找属性 "x",直到找到引入属性 "x" 的 Shape。
但是如果没有办法创建一个转换链会怎么样呢?例如,如果有两个空对象,并且你为每个对象添加了不同的属性,该怎么办?
const object1 = {}; object1.x = 5;const object2 = {}; object2.y = 6;复制代码
在这种情况下,我们必须进行分支操作,最终我们会得到一个转换树而不是转换链。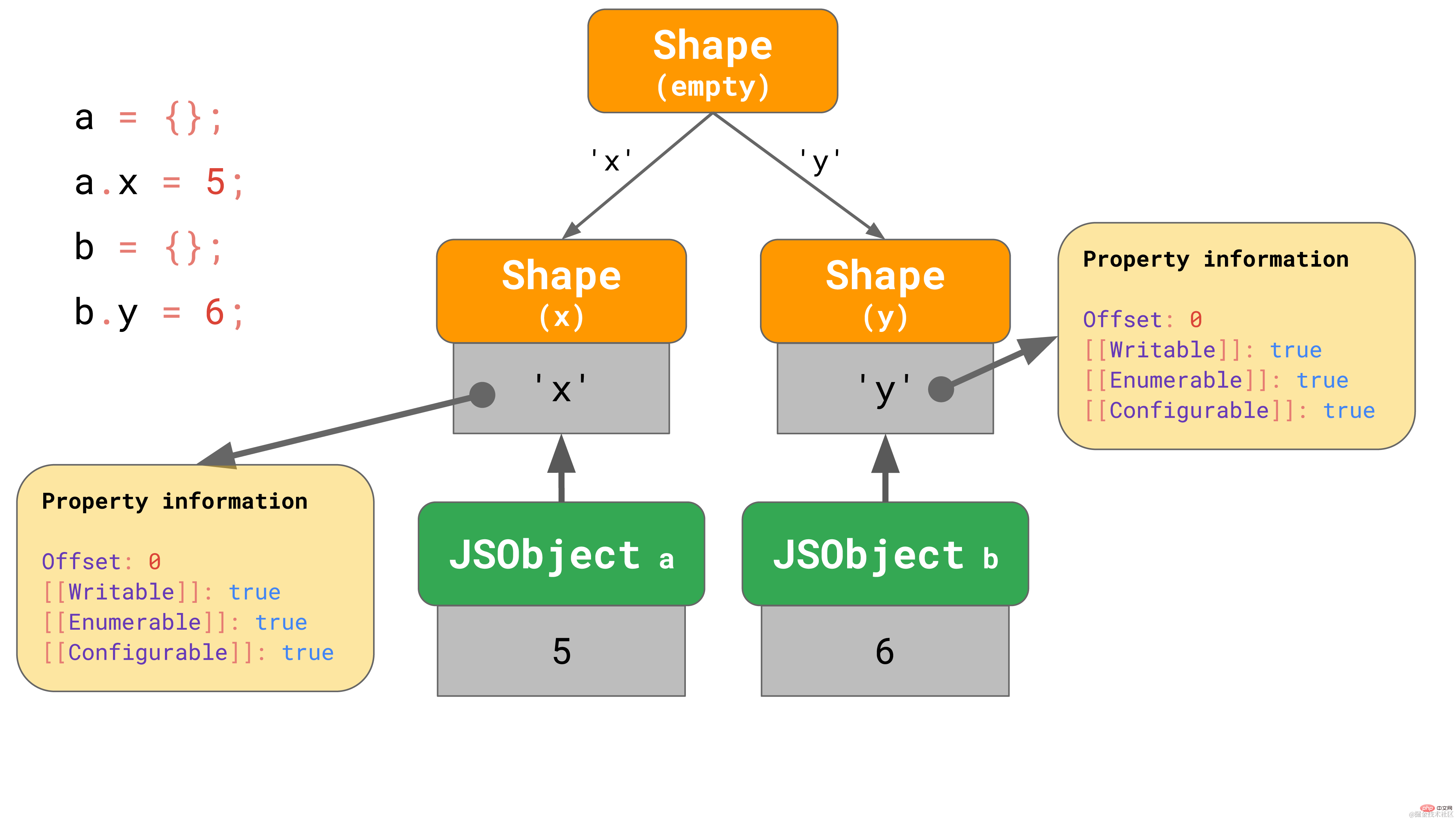
这里,我们创建了一个空对象 a,然后给它添加了一个属性 ‘x’。最终,我们得到了一个包含唯一值的 JSObject 和两个 Shape :空 shape 以及只包含属性 x 的 shape。
第二个例子也是从一个空对象 b 开始的,但是我们给它添加了一个不同的属性 ‘y’。最终,我们得到了两个 shape 链,总共 3 个 shape。
这是否意味着我们总是需要从空 shape 开始呢? 不一定。引擎对已含有属性的对象字面量会进行一些优化。比方说,我们要么从空对象字面量开始添加 x 属性,要么有一个已经包含属性 x 的对象字面量:
const object1 = {}; object1.x = 5;const object2 = { x: 6 };复制代码
在第一个例子中,我们从空 shape 开始,然后转到包含 x 的shape,这正如我们之前所见那样。
在 object2 的例子中,直接在一开始就生成含有 x 属性的对象,而不是生成一个空对象是有意义的。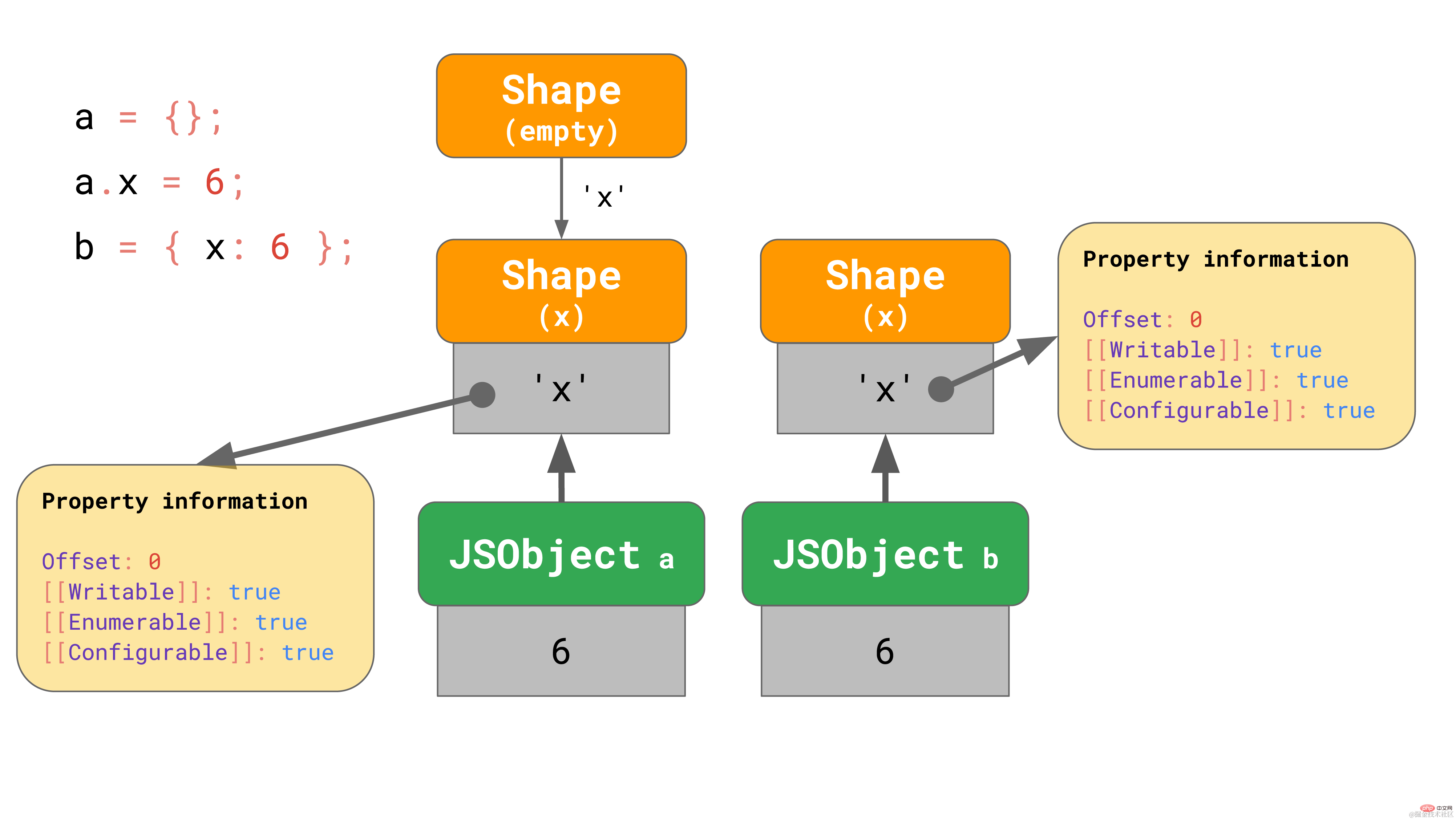
包含属性 ‘x’ 的对象字面量从含有 ‘x’ 的 shape 开始,有效地跳过了空 shape。V8 和 SpiderMonkey (至少)正是这么做的。这种优化缩短了转换链并且使从字面量构建对象更加高效。
下面是一个包含属性 ‘x'、'y' 和 'z' 的 3D 点对象的示例。
const point = {}; point.x = 4; point.y = 5; point.z = 6;复制代码
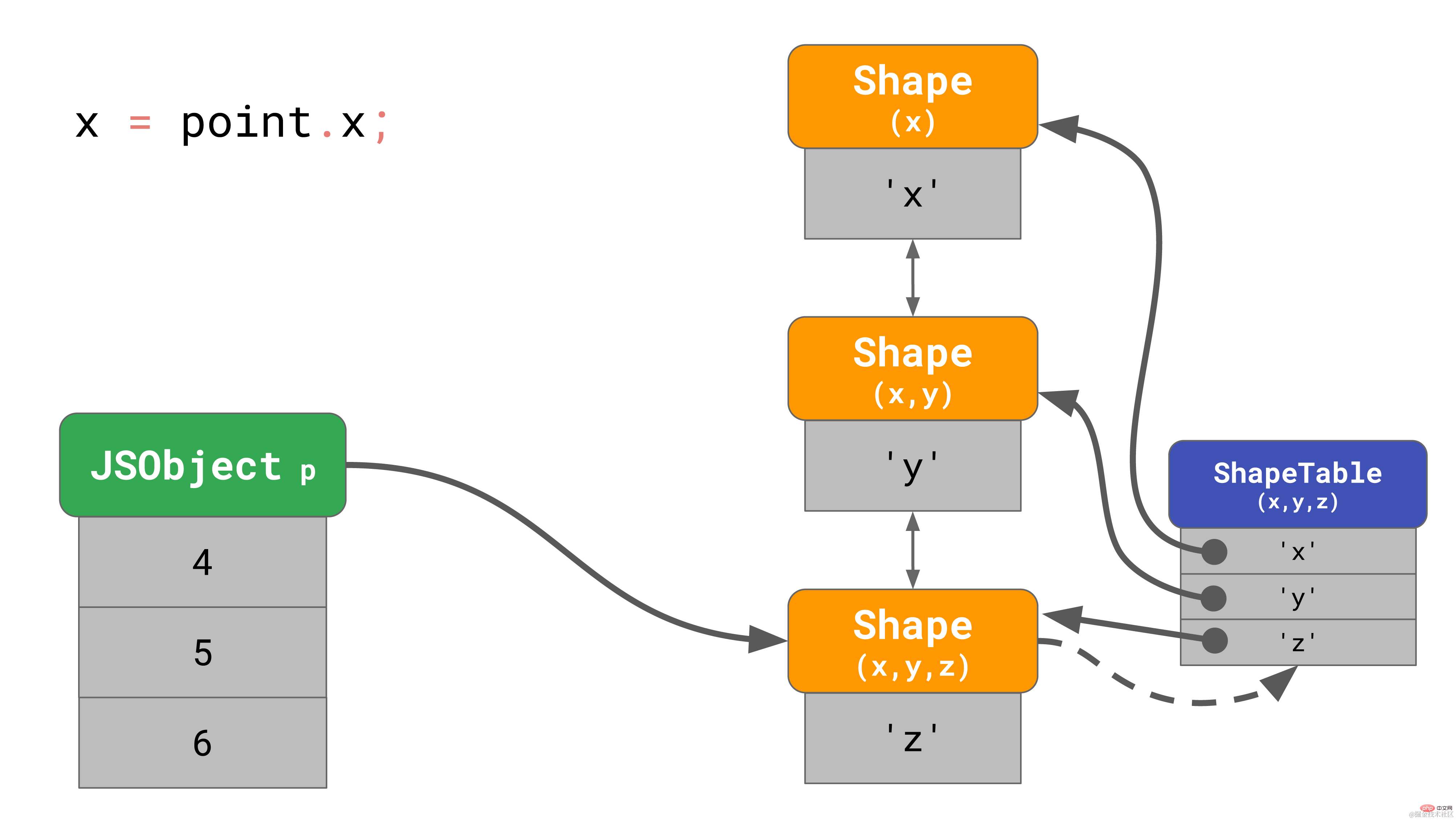
正如我们之前所了解的, 这会在内存中创建一个有3个 shape 的对象(不算空 shape 的话)。 当访问该对象的属性 ‘x’ 的时候,比如, 你在程序里写 point.x,javaScript 引擎需要循着链接列表寻找:它会从底部的 shape 开始,一层层向上寻找,直到找到顶部包含 ‘x’ 的 shape。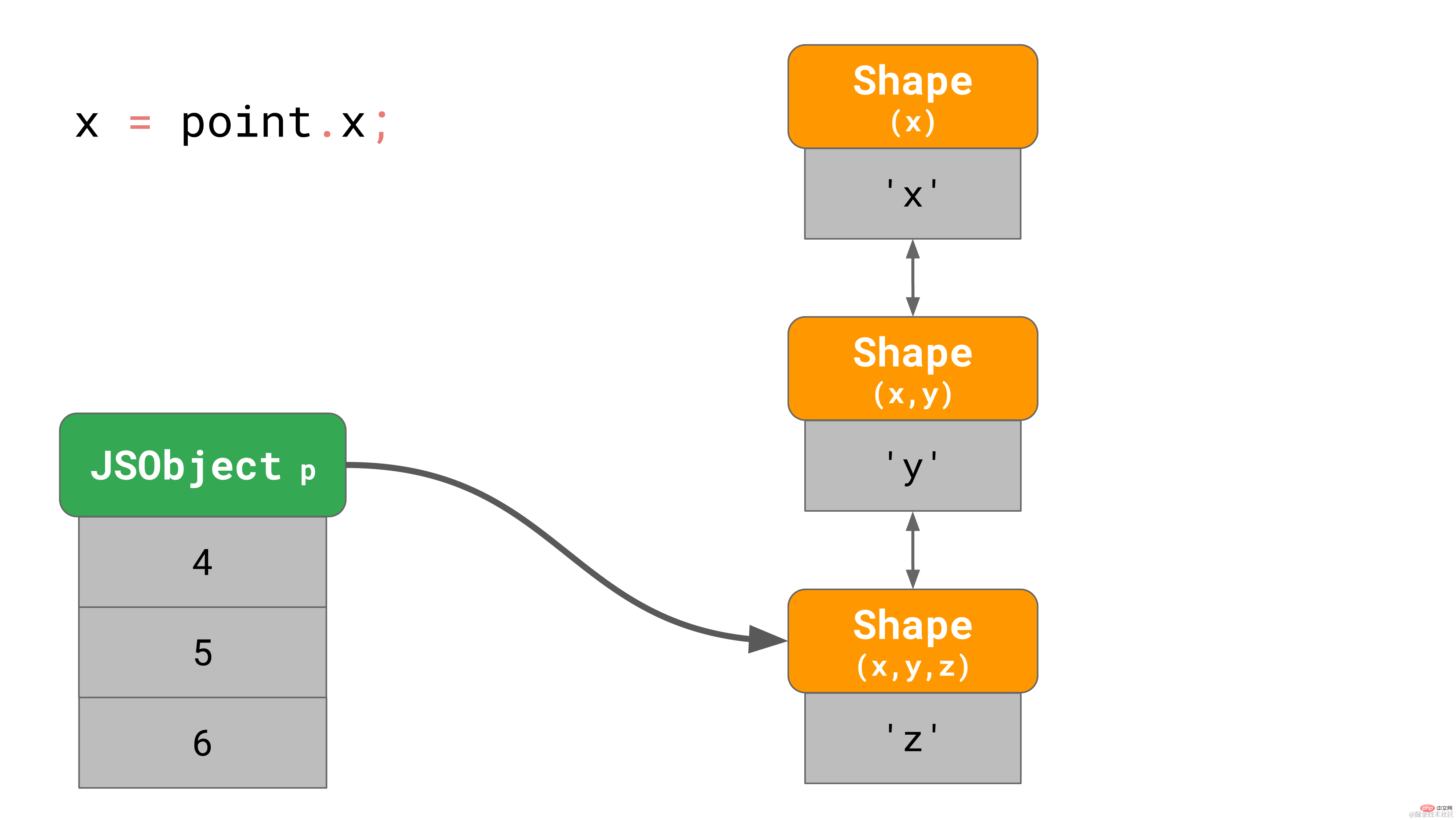
当这样的操作更频繁时, 速度会变得非常慢,特别是当对象有很多属性的时候。寻找属性的时间复杂度为 O(n), 即和对象上的属性数量线性相关。为了加快属性的搜索速度, JavaScript 引擎增加了一种 ShapeTable 的数据结构。这个 ShapeTable 是一个字典,它将属性键映射到描述对应属性的 shape 上。
现在我们又回到字典查找了我们添加 shape 就是为了对此进行优化!那我们为什么要去纠结 shape 呢? 原因是 shape 启用了另一种称为 Inline Caches 的优化。
shapes 背后的主要动机是 Inline Caches 或 ICs 的概念。ICs 是让 JavaScript 快速运行的关键要素!JavaScript 引擎使用 ICs 来存储查找到对象属性的位置信息,以减少昂贵的查找次数。
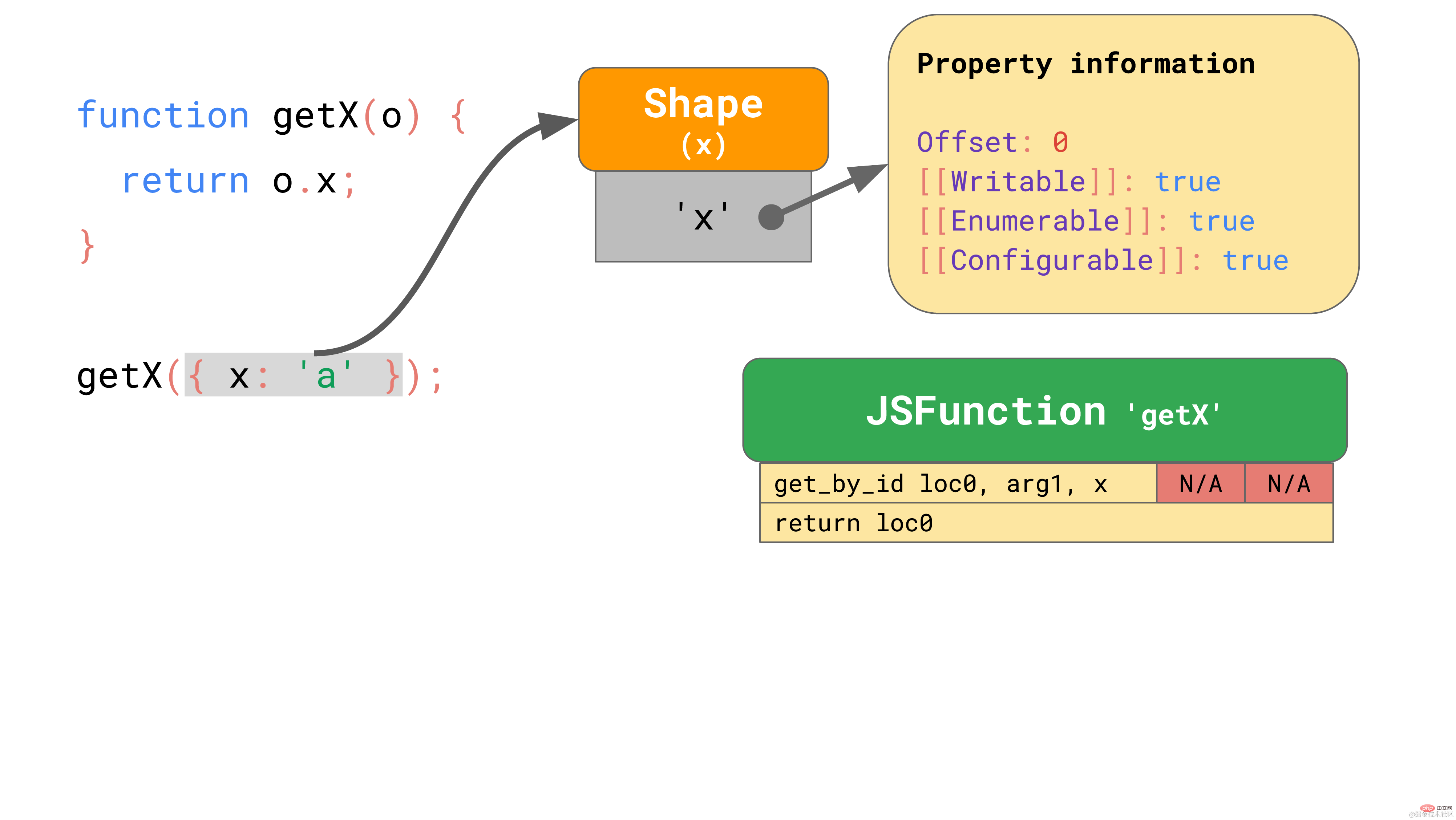
这里有一个函数 getX,该函数接收一个对象并从中加载属性 x:
function getX(o) { return o.x; }复制代码
如果我们在 JSC 中运行该函数,它会产生以下字节码:
第一条 get_by_id 指令从第一个参数(arg1)加载属性 ‘x’,并将结果存储到 loc0 中。第二条指令将存储的内容返回给 loc0。
JSC 还将一个 Inline Cache 嵌入到 get_by_id 指令中,该指令由两个未初始化的插槽组成。
 现在, 我们假设用一个对象 { x: 'a' },来执行 getX 这个函数。正如我们所知,,这个对象有一个包含属性 ‘x’ 的 shape, 该 shape存储了属性 ‘x’ 的偏移量和特性。当你在第一次执行这个函数的时候,get_by_id 指令会查找属性 ‘x’,然后发现其值存储在偏移量为 0 的位置。
现在, 我们假设用一个对象 { x: 'a' },来执行 getX 这个函数。正如我们所知,,这个对象有一个包含属性 ‘x’ 的 shape, 该 shape存储了属性 ‘x’ 的偏移量和特性。当你在第一次执行这个函数的时候,get_by_id 指令会查找属性 ‘x’,然后发现其值存储在偏移量为 0 的位置。
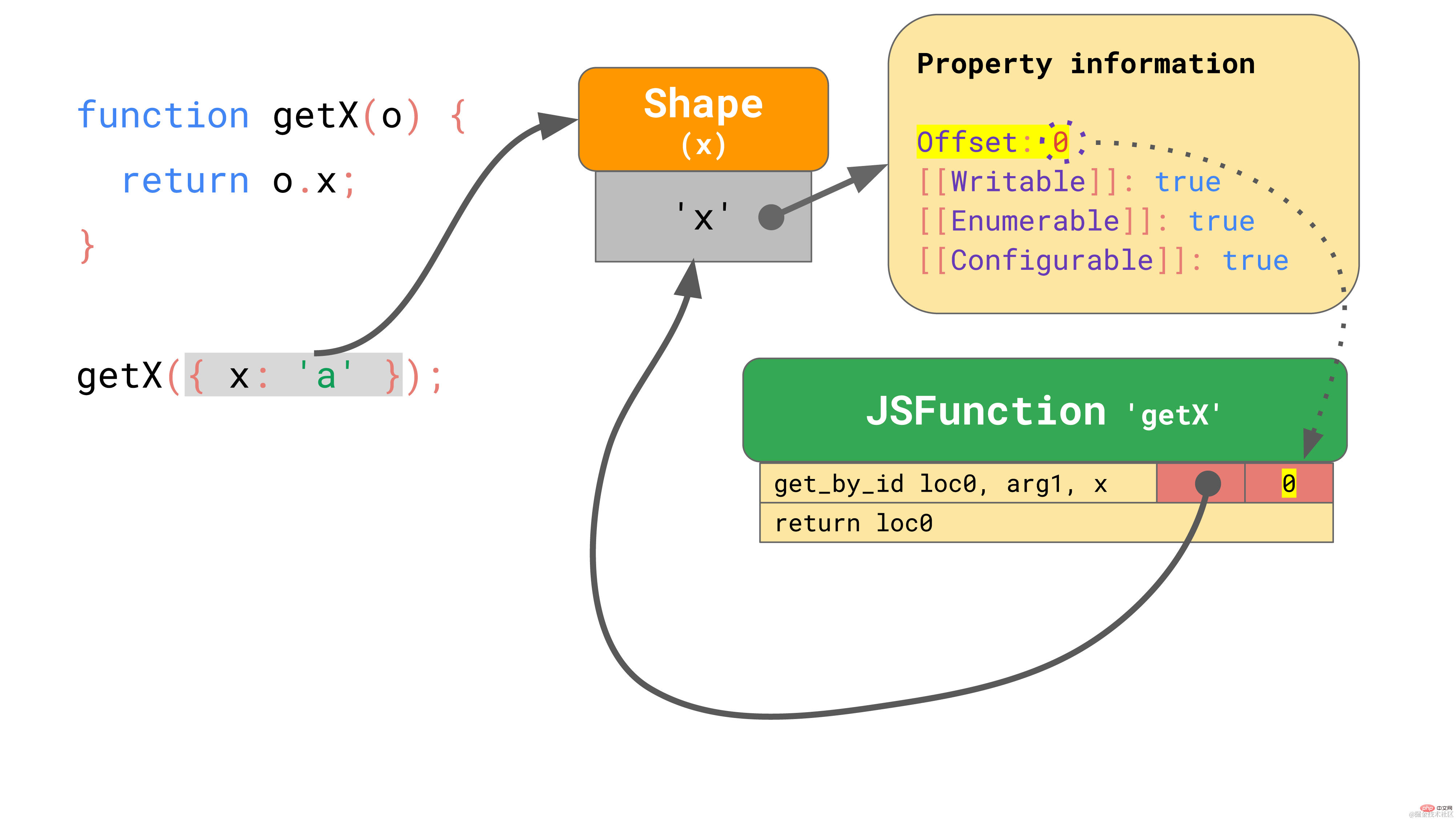
嵌入到 get_by_id 指令中的 IC 存储了 shape 和该属性的偏移量:
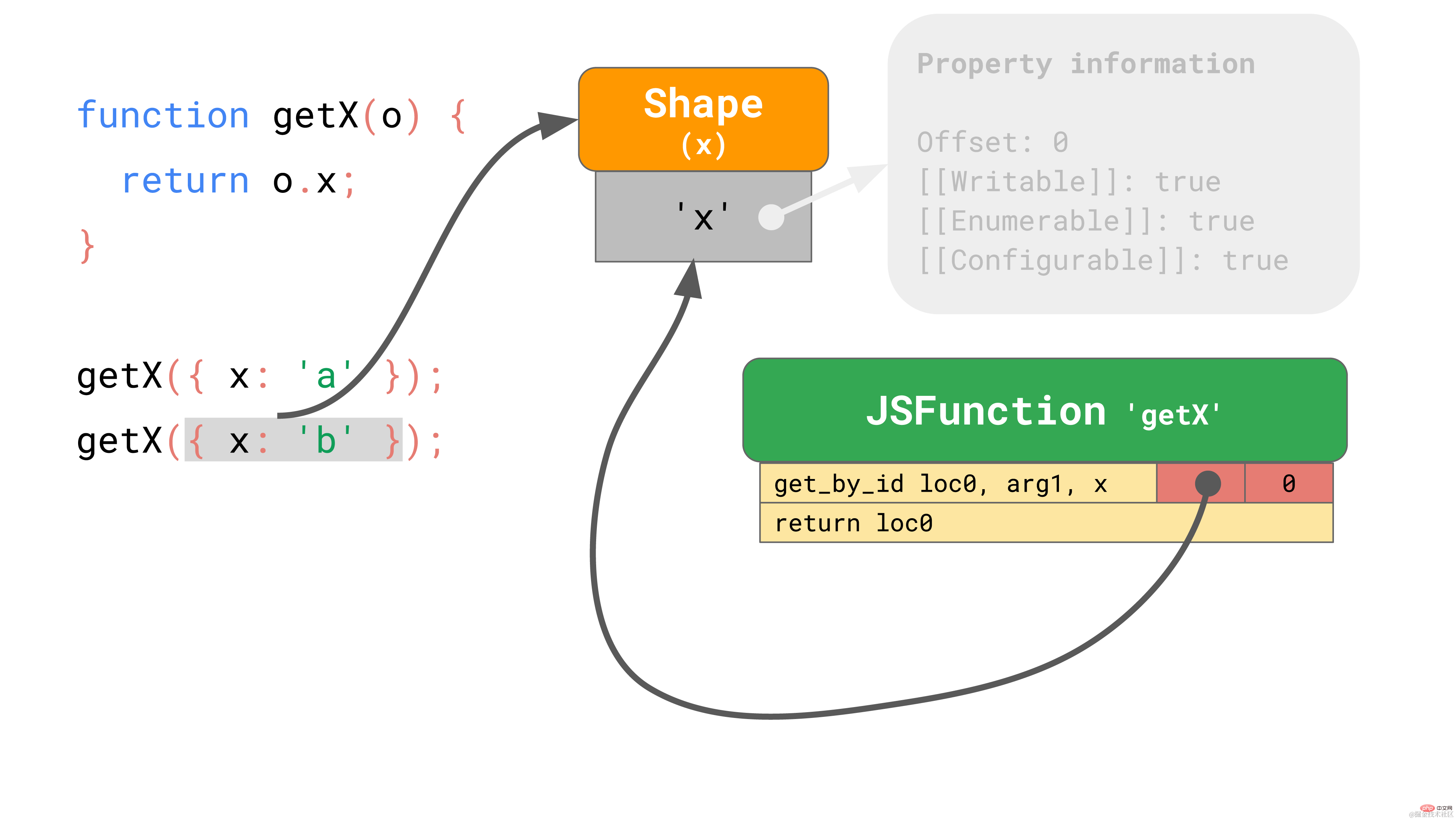
对于后续运行,IC 只需要比较 shape,如果 shape 与之前相同,只需从存储的偏移量加载值。具体来说,如果 JavaScript 引擎看到对象的 shape 是 IC 以前记录过的,那么它根本不需要接触属性信息,相反,可以完全跳过昂贵的属性信息查找过程。这要比每次都查找属性快得多。
对于数组,存储数组索引属性是很常见的。这些属性的值称为数组元素。为每个数组中的每个数组元素存储属性特性是非常浪费内存的。相反,默认情况下,数组索引属性是可写的、可枚举的和可配置的,JavaScript 引擎基于这一点将数组元素与其他命名属性分开存储。
思考下面的数组:
const array = [ '#jsconfeu', ];复制代码
引擎存储了数组长度(1),并指向包含偏移量和 'length' 属性特性的 shape。
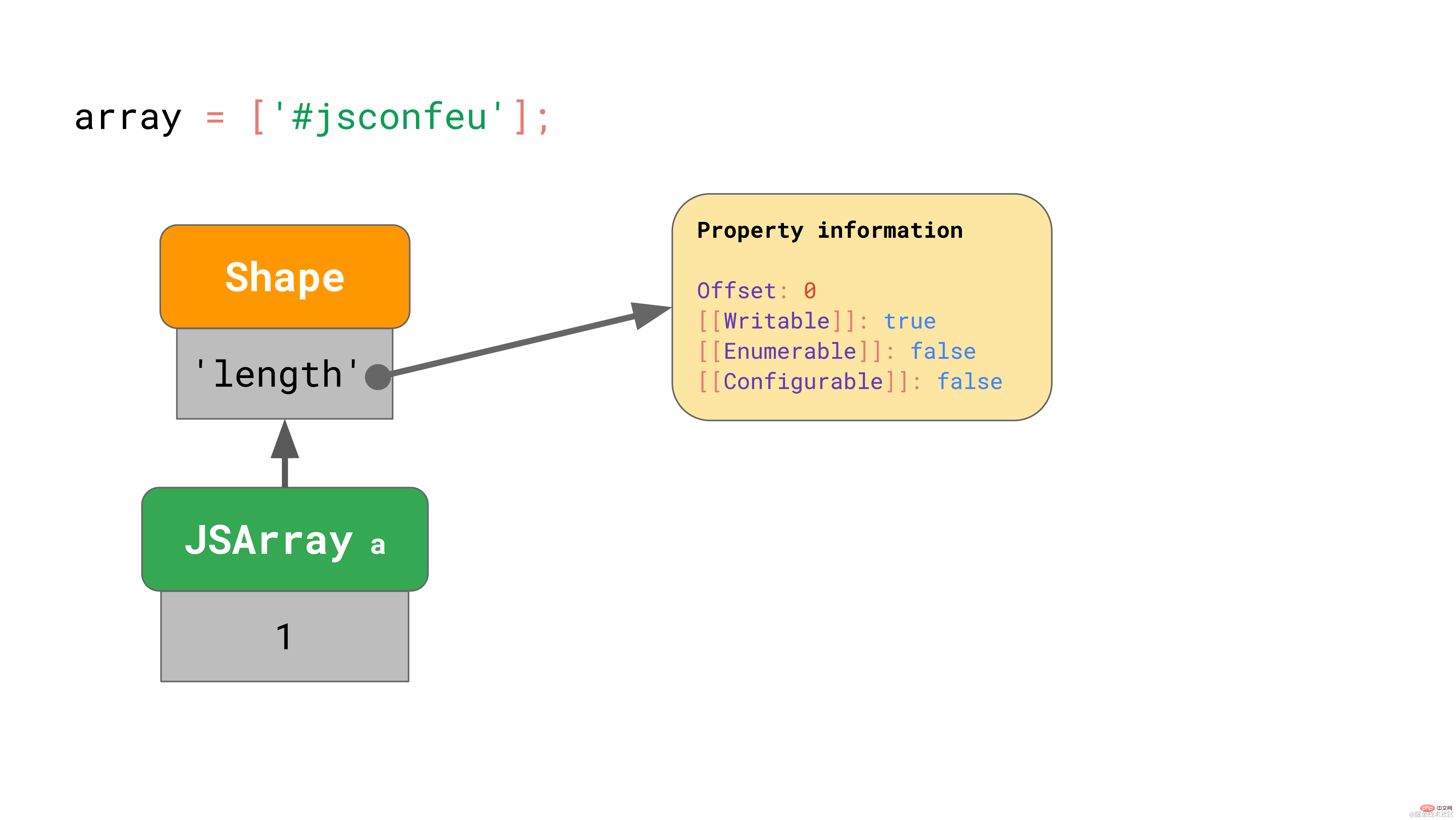
这和我们之前看到的很相似……但是数组的值存到哪里了呢?
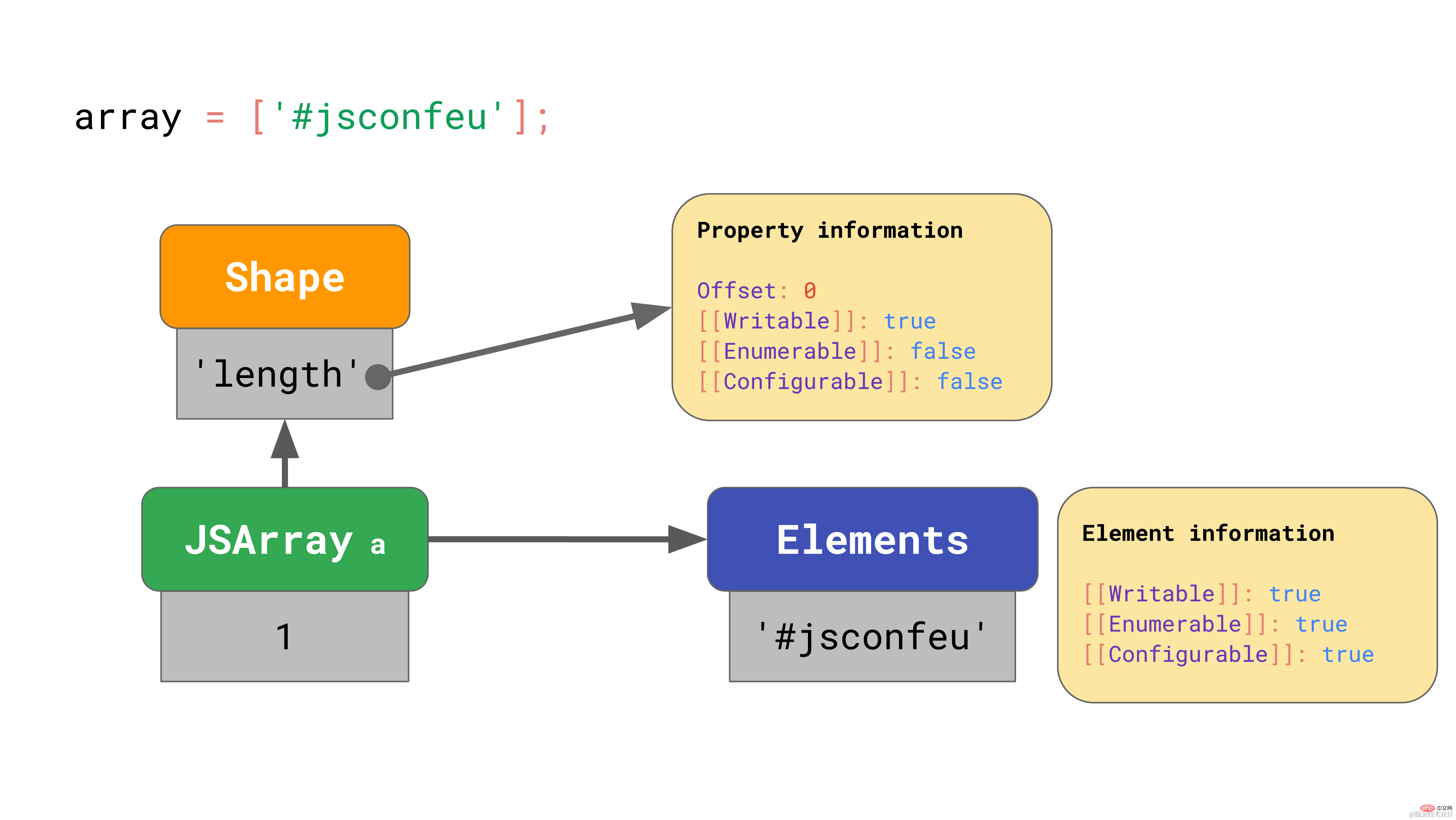
每个数组都有一个单独的元素备份存储区,包含所有数组索引的属性值。JavaScript 引擎不必为数组元素存储任何属性特性,因为它们通常都是可写的、可枚举的和可配置的。
那么,在非通常情况下会怎么样呢?如果更改了数组元素的属性特性,该怎么办?
// Please don’t ever do this!const array = Object.defineProperty( [], '0', { value: 'Oh noes!!1', writable: false, enumerable: false, configurable: false, });复制代码
上面的代码片段定义了名为 “0” 的属性(恰好是数组索引),但将其特性设置为非默认值。
在这种边缘情况下,JavaScript 引擎将整个元素备份存储区表示成一个字典,该字典将数组索引映射到属性特性。
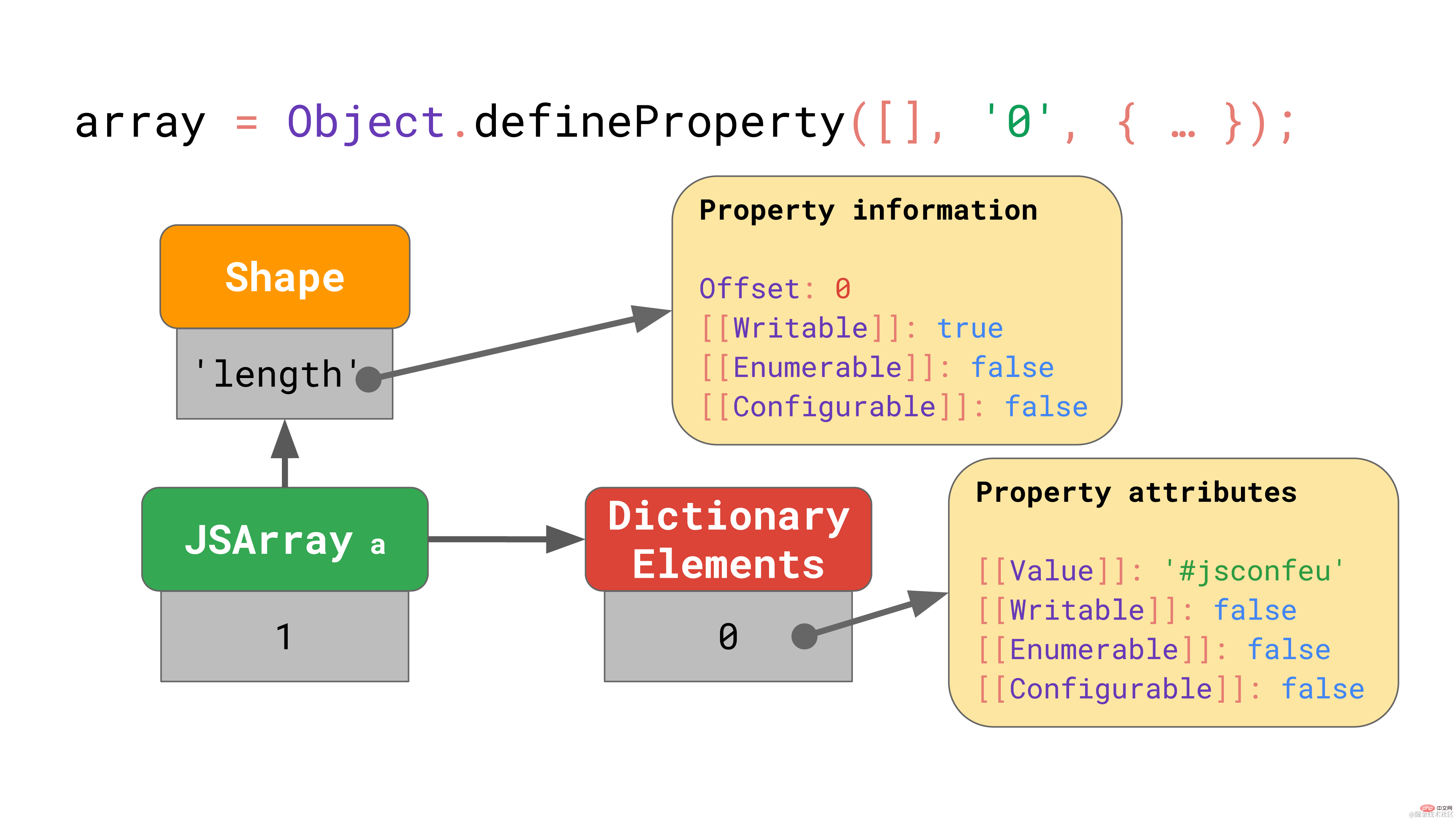
即使只有一个数组元素具有非默认特性,整个数组的备份存储区也会进入这种缓慢而低效的模式。避免对数组索引使用Object.defineProperty!
我们已经了解了 JavaScript 引擎如何存储对象和数组,以及 shape 和 ICs 如何优化对它们的常见操作。基于这些知识,我们确定了一些可以帮助提高性能的实用的 JavaScript 编码技巧:
관련 무료 학습 권장 사항:javascript(동영상)
위 내용은 JavaScript 엔진의 기본 원리를 이해합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!































![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



