


관련 학습 권장 사항: python 튜토리얼
Python은 오픈 소스이므로 훌륭하지만 오픈 소스에 내재된 몇 가지 문제를 피할 수는 없습니다. 많은 패키지가 동일한 작업을 수행(또는 수행하려고)합니다. Python을 처음 사용하는 경우 특정 작업에 어떤 패키지가 가장 적합한지 알기가 어렵습니다. 반드시 갖춰야 할 데이터 과학용 패키지가 하나 있는데, 바로 pandas입니다.
판다의 가장 흥미로운 점은 그 안에 숨겨진 가방이 많다는 것입니다. 다른 패키지의 많은 기능을 포함하는 핵심 패키지입니다. 팬더를 사용하여 작업을 완료할 수 있다는 점에서 이는 매우 좋습니다.
pandas는 Python의 Excel과 동일합니다. 즉, 테이블(즉, 데이터프레임)을 사용하고 데이터에 대해 다양한 변환을 수행할 수 있지만 다른 많은 기능도 있습니다.
이미 Python 사용에 익숙하다면 세 번째 단락으로 바로 이동할 수 있습니다.
시작해 보세요:
import pandas as pd复制代码
왜 "p" 대신 "pd"인지 묻지 마세요. 그게 전부입니다. 그냥 사용해 보세요 :)
데이터 읽기
data = pd.read_csv( my_file.csv ) data = pd.read_csv( my_file.csv , sep= ; , encoding= latin-1 , nrows=1000, skiprows=[2,5])复制代码
sep은 구분 기호를 나타냅니다. 프랑스어 데이터를 사용하는 경우 Excel의 csv 구분 기호는 ";"이므로 명시적으로 지정해야 합니다. 프랑스어 문자를 읽을 수 있도록 인코딩은 latin-1로 설정됩니다. nrows=1000은 데이터의 처음 1000행을 읽는다는 의미입니다. Skiprows=[2,5]는 파일을 읽을 때 2행과 5행을 제거한다는 의미입니다.
가장 일반적으로 사용되는 함수: read_csv, read_excel
다른 유용한 함수: read_clipboard, read_sql
Write data
data.to_csv( my_new_file.csv , index=None)复制代码
index=None은 데이터가 그대로 기록된다는 의미입니다. index=None을 쓰지 않으면 마지막 행까지 내용 1, 2, 3,...이 포함된 추가 첫 번째 열이 생깁니다.
저는 일반적으로 .to_excel, .to_json, .to_pickle 등과 같은 다른 기능을 사용하지 않습니다. 왜냐하면 .to_csv가 작업을 매우 잘 수행할 수 있고 csv가 테이블을 저장하는 데 가장 일반적으로 사용되는 방법이기 때문입니다.
데이터 확인

Gives (#rows, #columns)复制代码
행과 열의 개수를 확인하세요
data.describe()复制代码
기본 통계 계산
데이터 보기
data.head(3)复制代码
데이터의 처음 3개 행을 인쇄하세요. 마찬가지로 .tail()은 데이터의 마지막 행에 해당합니다.
data.loc[8]复制代码
8번째 행을 인쇄하세요
data.loc[8, column_1 ]复制代码
8번째 행에 "column_1"이라는 열을 인쇄하세요
data.loc[range(4,6)]复制代码
4~6번째 행의 데이터 하위 집합(왼쪽 닫힘, 오른쪽 열림)
논리 연산
data[data[ column_1 ]== french ] data[(data[ column_1 ]== french ) & (data[ year_born ]==1990)] data[(data[ column_1 ]== french ) & (data[ year_born ]==1990) & ~(data[ city ]== London )]复制代码
논리 연산을 사용하여 데이터 부분 집합을 만듭니다. &(AND), ~(NOT) 및 |(OR)을 사용하려면 논리 연산 앞뒤에 "and"를 추가해야 합니다.
data[data[ column_1 ].isin([ french , english ])]复制代码
동일한 열에 여러 OR을 사용하는 것 외에도 .isin() 함수를 사용할 수도 있습니다.
기본 플로팅
matplotlib 패키지가 이를 가능하게 합니다. 소개에서 말했듯이 팬더에서 직접 사용할 수 있습니다.
data[ column_numerical ].plot()复制代码
().plot() 출력 예
data[ column_numerical ].hist()复制代码
데이터 분포(히스토그램) 플롯
.hist() 출력 예
%matplotlib inline复制代码
Jupyter를 사용하는 경우, 그리기 전에 위의 코드를 추가하는 것을 잊지 마세요.
데이터 업데이트
data.loc[8, column_1 ] = english 将第八行名为 column_1 的列替换为「english」复制代码
data.loc[data[ column_1 ]== french , column_1 ] = French复制代码
코드 한 줄로 여러 열의 값 변경
자, 이제 Excel에서 쉽게 액세스할 수 있는 작업을 수행할 수 있습니다. 엑셀에서는 할 수 없는 몇 가지 놀라운 일을 살펴보겠습니다.
발생 횟수 계산
data[ column_1 ].value_counts()复制代码
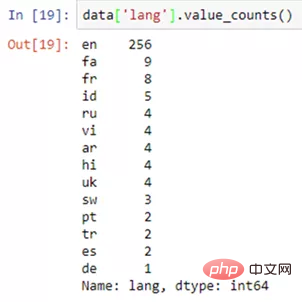
.value_counts() 함수 출력 예시
모든 행, 열 또는 전체 데이터에 대해 동작
data[ column_1 ].map(len)复制代码
len() 함수가 적용됨 On "column_1" 열의 각 요소
.map() 작업은 열의 각 요소에 함수를 적용합니다.
data[ column_1 ].map(len).map(lambda x: x/100).plot()复制代码
pandas의 가장 큰 특징은 체인 방법(tomaugspurger.github.io/ method-chai… 및 .plot)입니다. ()).
data.apply(sum)复制代码
.apply()는 열에 함수를 적용합니다.
.applymap()은 테이블(DataFrame)의 모든 셀에 함수를 적용합니다.
tqdm, 유일한
在处理大规模数据集时,pandas 会花费一些时间来进行.map()、.apply()、.applymap() 等操作。tqdm 是一个可以用来帮助预测这些操作的执行何时完成的包(是的,我说谎了,我之前说我们只会使用到 pandas)。
from tqdm import tqdm_notebook tqdm_notebook().pandas()复制代码
用 pandas 设置 tqdm
data[ column_1 ].progress_map(lambda x: x.count( e ))复制代码
用 .progress_map() 代替.map()、.apply() 和.applymap() 也是类似的。

在 Jupyter 中使用 tqdm 和 pandas 得到的进度条
相关性和散射矩阵
data.corr() data.corr().applymap(lambda x: int(x*100)/100)复制代码
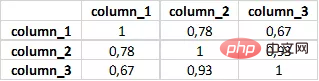
.corr() 会给出相关性矩阵
pd.plotting.scatter_matrix(data, figsize=(12,8))复制代码
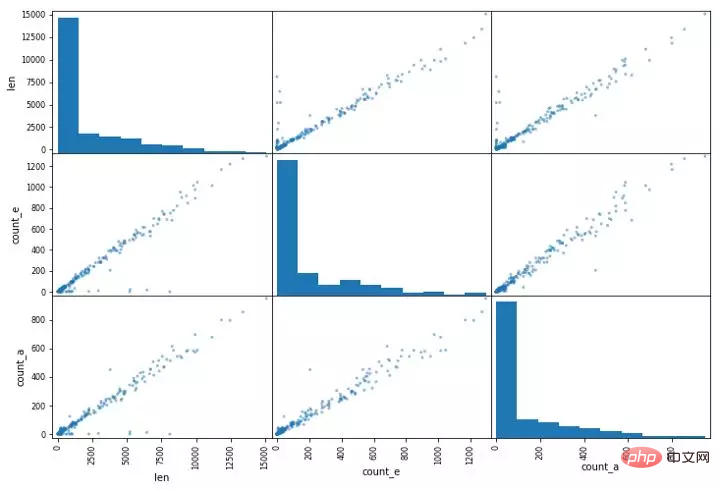
散点矩阵的例子。它在同一幅图中画出了两列的所有组合。
The SQL 关联
在 pandas 中实现关联是非常非常简单的
data.merge(other_data, on=[ column_1 , column_2 , column_3 ])复制代码
关联三列只需要一行代码
分组
一开始并不是那么简单,你首先需要掌握语法,然后你会发现你一直在使用这个功能。
data.groupby( column_1 )[ column_2 ].apply(sum).reset_index()复制代码
按一个列分组,选择另一个列来执行一个函数。.reset_index() 会将数据重构成一个表。
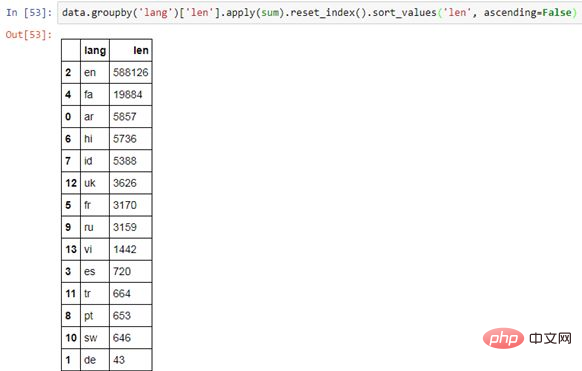
正如前面解释过的,为了优化代码,在一行中将你的函数连接起来。
行迭代
dictionary = {}
for i,row in data.iterrows():
dictionary[row[ column_1 ]] = row[ column_2 ]复制代码.iterrows() 使用两个变量一起循环:行索引和行的数据 (上面的 i 和 row)
总而言之,pandas 是 python 成为出色的编程语言的原因之一
我本可以展示更多有趣的 pandas 功能,但是已经写出来的这些足以让人理解为何数据科学家离不开 pandas。总结一下,pandas 有以下优点:
易用,将所有复杂、抽象的计算都隐藏在背后了;
直观;
快速,即使不是最快的也是非常快的。
它有助于数据科学家快速读取和理解数据,提高其工作效率
위 내용은 Pandas의 가장 자세한 튜토리얼의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



