

다양한 언어로 크롤링할 수 있지만 python 기반 크롤러가 더 간결하고 편리합니다. 크롤러는 또한 Python 언어의 필수적인 부분이 되었습니다. 크롤러를 구문 분석하는 방법도 여러 가지가 있습니다. 이전 기사에서는 크롤러를 구문 분석하는 네 번째 방법인 PyQuery에 대해 설명했습니다. 오늘은 또 다른 방법인 XPath를 소개합니다.

파이썬 크롤러 xpath의 기본 사용#🎜🎜 #
1. 소개
찾을 언어 문서의 정보. XPath는 XML 문서의 요소와 속성을 탐색하는 데 사용할 수 있습니다. XPath는 W3C XSLT 표준의 주요 요소이며 XQuery와 XPointer는 모두 XPath 표현식을 기반으로 구축되었습니다. 2. 설치
pip3 install lxml
#🎜 🎜#
1. Importfrom lxml import etree
from lxml import etree
wb_data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html = etree.HTML(wb_data)
print(html)
result = etree.tostring(html)
print(result.decode("utf-8"))<Element html at 0x39e58f0>
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul>
</div>
</body></html>작성 방법 1
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a')
print(html)
for i in html_data:
print(i.text)<Element html at 0x12fe4b8> first item second item third item fourth item fifth item
(콘텐츠를 찾으려면 태그 바로 뒤에 /text()를 추가하면 됩니다.)
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a/text()')
print(html)
for i in html_data:
print(i) #🎜🎜 # #🎜🎜 # 4. html 파일을 열어서 읽어보세요 <Element html at 0x138e4b8>
first item
second item
third item
fourth item
fifth item
로그인 후 복사
#使用parse打开html的文件
html = etree.parse('test.html')
html_data = html.xpath('//*')<br>#打印是一个列表,需要遍历
print(html_data)
for i in html_data:
print(i.text)
html = etree.parse('test.html') html_data = etree.tostring(html,pretty_print=True) res = html_data.decode('utf-8') print(res)
#🎜 🎜#Print: #🎜 🎜#
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
5. 지정된 경로 아래에 있는 태그의 속성을 인쇄합니다(트래버스를 통해 속성 값을 얻을 수 있으며, 해당 내용을 찾을 수 있음). 태그)
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a/@href')
for i in html_data:
print(i)link1.html link2.html link3.html link4.html link5.html
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a[@href="link2.html"]/text()')
print(html_data)
for i in html_data:
print(i)html = etree.HTML(wb_data)
html_data = html.xpath('//li/a/text()')
print(html_data)
for i in html_data:
print(i)['first item', 'second item', 'third item', 'fourth item', 'fifth item'] first item second item third item fourth item fifth item
html = etree.HTML(wb_data)
html_data = html.xpath('//li/a//@href')
print(html_data)
for i in html_data:
print(i)['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html'] link1.html link2.html link3.html link4.html link5.html
9. 상대 경로에서 특정 속성을 확인하는 방법은 절대 경로에서와 비슷하다고 할 수도 있습니다. 동일합니다.
html = etree.HTML(wb_data)
html_data = html.xpath('//li/a[@href="link2.html"]')
print(html_data)
for i in html_data:
print(i.text)인쇄:
[<Element a at 0x216e468>] second item
10、查找最后一个li标签里的a标签的href属性
html = etree.HTML(wb_data)
html_data = html.xpath('//li[last()]/a/text()')
print(html_data)
for i in html_data:
print(i)
打印:
['fifth item'] fifth item
11、查找倒数第二个li标签里的a标签的href属性
html = etree.HTML(wb_data)
html_data = html.xpath('//li[last()-1]/a/text()')
print(html_data)
for i in html_data:
print(i)
打印:
['fourth item'] fourth item
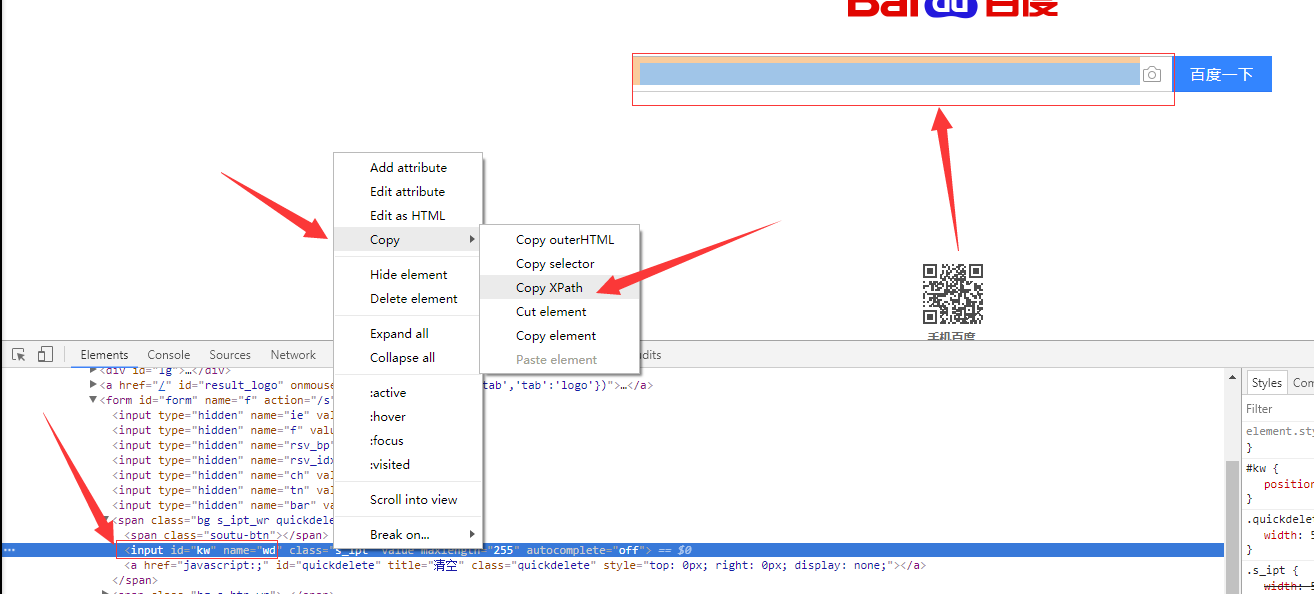
12、如果在提取某个页面的某个标签的xpath路径的话,可以如下图:
//*[@id="kw"]
解释:使用相对路径查找所有的标签,属性id等于kw的标签。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from scrapy.selector import Selector, HtmlXPathSelector
from scrapy.http import HtmlResponse
html = """<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<ul>
<li><a id='i1' href="link.html">first item</a></li>
<li><a id='i2' href="llink.html">first item</a></li>
<li><a href="llink2.html">second item<span>vv</span></a></li>
</ul>
<div><a href="llink2.html">second item</a></div>
</body>
</html>
"""
response = HtmlResponse(url='http://example.com', body=html,encoding='utf-8')
# hxs = HtmlXPathSelector(response)
# print(hxs)
# hxs = Selector(response=response).xpath('//a')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[2]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@id]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@id="i1"]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@href="link.html"][@id="i1"]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[contains(@href, "link")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[starts-with(@href, "link")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/text()').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/@href').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('/html/body/ul/li/a/@href').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('//body/ul/li/a/@href').extract_first()
# print(hxs)
# ul_list = Selector(response=response).xpath('//body/ul/li')
# for item in ul_list:
# v = item.xpath('./a/span')
# # 或
# # v = item.xpath('a/span')
# # 或
# # v = item.xpath('*/a/span')
# print(v)위 내용은 크롤러 구문 분석 방법 5: XPath의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



