


MySQL 인덱스의 데이터 구조와 알고리즘 원리
1. 정의
인덱스 정의: 인덱스(Index)는 MySQL이 데이터를 효율적으로 얻을 수 있도록 도와주는 데이터 구조입니다.
본질: 인덱스는 데이터 구조입니다.
2. B-Tree
m-order B-Tree는 다음 조건을 만족합니다.
1. 각 노드는 최대 m개의 하위 트리를 가질 수 있습니다.
2. 루트 노드에는 노드가 2개 이상 있습니다(또는 극단적인 경우 트리에는 루트 노드가 하나만 있습니다. 단일 세포 유기체는 뿌리, 잎 및 나무입니다).
3. 비루트 및 비리프 노드에는 최소한 Ceil(m/2) 하위 트리가 있어야 합니다(Ceil은 5차 B-트리와 같이 반올림을 의미하며 각 노드에는 최소한 3개의 하위 트리가 있습니다. 최소 3개의 포크).
4. 리프가 아닌 노드의 정보에는 [n,A0,K1,A1,K2,A2,...,Kn,An]이 포함됩니다. 여기서 n은 노드에 저장된 키워드 수를 나타내고, K는 키워드를 나타냅니다. Ki
B-트리 기능:
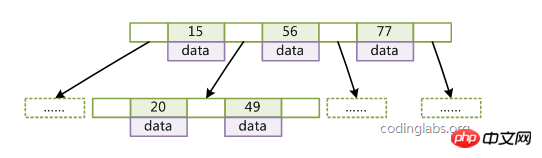
1. 키워드 세트는 트리 전체에 분산됩니다. 모든 키워드는 하나의 노드에만 나타납니다.
4. 노드의 키는 왼쪽에서 오른쪽으로 감소합니다. ;
6. 모든 리프 노드는 트리 높이 h와 동일한 깊이를 갖습니다.
B-Tree의 검색 알고리즘의 의사 코드는 다음과 같습니다.
 3. B+Tree
3. B+Tree
B+Tree와 B-Tree의 차이점은 다음과 같습니다.  1. 트리가 아닌 노드는 데이터를 저장하지 않으며
1. 트리가 아닌 노드는 데이터를 저장하지 않으며
3. 각 리프 노드에는 인접한 리프 노드에 대한 포인터가 포함되어 있으며 순차 액세스 포인터가 있는 B+ 트리는 간격 검색을 향상시킵니다. ;
4. 리프가 아닌 노드는 인덱스 부분으로 간주될 수 있으며 해당 노드는 하위 트리(루트 노드)에서 가장 큰(또는 가장 작은) 키워드만 포함합니다.
4. 트리 인덱스
기본: 디스크 I/O 수를 사용하여 인덱스 구조의 품질을 평가합니다.메인 메모리와 디스크는 페이지 단위로 데이터를 교환합니다. 노드의 크기를 한 페이지와 동일하게 설정합니다. 완전히 로드된 I/O가 하나만 필요합니다.
B-트리의 정의에 따르면 검색은 한 번에 최대 h개의 노드에 액세스해야 함을 알 수 있습니다.점근적 복잡성: O(h)=O(logdN)
dmax=floor(pagesize/(keysize+ datasize+pointsize))
일반적인 실제 응용에서 out-degree d는 매우 큰 수(보통 100 이상)이므로 h는 매우 작습니다(보통 3을 넘지 않으며 레이어 3은 약 백만 개의 데이터를 저장할 수 있습니다)
B-트리에서 검색하려면 최대 h-1 I/O가 필요합니다(루트 노드는 메모리에 상주합니다)
B+트리의 노드에는 데이터 필드가 포함되어 있지 않으므로 아웃 차수 d가 더 크고 h가 더 작습니다. , I/O 수가 적고 효율성이 높기 때문에 외부 메모리 인덱스에는 B+Tree가 더 적합합니다.
5. MySQL 인덱스 구현
1. MyISAM 엔진은 B+Tree를 인덱스 구조로 사용합니다. 리프 노드의 데이터 필드는 데이터 레코드의 주소를 저장합니다. MyISAM 기본 인덱스 간에는 구조적 차이가 없습니다. 보조 인덱스는 키가 고유해야 하지만 보조 인덱스의 키는 반복될 수 있습니다.
2. InnoDB 데이터 파일 자체는 인덱스 파일이며 리프 노드에는 완전한 데이터 레코드가 포함됩니다. 인덱스를 클러스터형 인덱스라고 합니다.
InnoDB의 데이터 파일 자체는 기본 키로 집계되기 때문에 InnoDB에서는 테이블에 기본 키가 있어야 합니다(MyISAM에는 기본 키가 필요하지 않음). 명시적으로 지정하지 않으면 MySQL 시스템은 데이터 레코드를 고유하게 식별할 수 있는 열을 자동으로 선택합니다. 그렇지 않은 경우 MySQL 시스템은 데이터 레코드를 기본 키로 고유하게 식별할 수 있는 열을 자동으로 선택합니다. 이러한 열이 있으면 MySQL은 자동으로 InnoDB 테이블의 기본 키로 암시적 필드를 생성합니다.
보조 인덱스 검색은 인덱스를 두 번 검색해야 합니다. 먼저 기본 키를 얻기 위해 보조 인덱스를 검색한 다음 기본 키를 사용합니다.
3. 페이지 분할 문제
기본 키가 단조롭게 증가하면 페이지가 채워지면 각각의 새 레코드가 페이지에 계속 삽입됩니다. 
6. 요약
다양한 스토리지 엔진의 인덱스 구현 방법을 이해하는 것은 인덱스의 올바른 사용 및 최적화에 매우 도움이 됩니다.
1. 지나치게 긴 필드를 기본 키로 사용하지 않는 이유는 무엇입니까?2. 자동 증가 필드를 기본 키로 선택하는 이유는 무엇입니까?
3. 자주 업데이트되는 필드를 색인화하는 것이 권장되지 않는 이유는 무엇입니까?
4. 차별화도가 높은 열을 인덱스로 선택하는 이유는 무엇인가요? 구별 공식은 count(distinct col)/count(*)
5입니다. 가능한 한 포함 인덱스를 사용하세요
7. LIMIT 페이징 쿼리 최적화
SELECT * FROM table where condition LIMIT offset , rows ;
위 SQL 문의 구현 메커니즘은 다음과 같습니다.
1. "테이블" 테이블에서 오프셋+행 행 레코드를 읽습니다.
2. 이전 오프셋 행 레코드를 버리고 다음 행 행 레코드를 최종 결과로 반환합니다.
대상 인덱스:
select a.id, sid, parent_s_id from cashpool_account_relationship a join (select id from cashpool_account_relationship LIMIT 1000000,10)b on a.id = b.id; select id, sid, parent_s_id from cashpool_account_relationship where id >=(select id from cashpool_account_relationship LIMIT 1000000,1) LIMIT 10;
8. Q&A
1. InnoDB는 해시 인덱스를 지원하나요? --Ma Xin
InnoDB는 해시 인덱스를 지원하지만 지원하는 해시 인덱스는 적응형입니다. InnoDB 스토리지 엔진은 테이블 사용량을 기반으로 테이블에 대한 해시 인덱스를 자동으로 생성하며 사람의 개입으로 해시를 생성하는 것이 허용되지 않습니다. 테이블의 인덱스.
2. InnoDB 기본 키 인덱스의 리프 노드에는 완전한 데이터 레코드가 포함되어 있습니다. 기본 키 인덱스 파일이 데이터 파일보다 큽니까? --Xu Caihou
1) Innodb 엔진에서 기본 키 인덱스의 리프 노드에는 레코드 데이터가 포함되며 기본 키 인덱스 파일은 데이터 파일입니다.
2) tables 테이블에서 계산되는 data_length는 기본 키 인덱스의 크기이고, index_length는 이 테이블에 있는 모든 보조 인덱스(보조 인덱스)의 계산된 크기입니다. 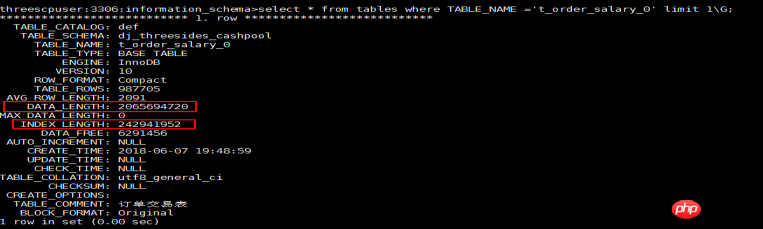
위 내용은 mysql 인덱스의 기본 구현 원리의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



