
이 글은 주로 PHP 정규식에서 캡처 그룹과 비캡처 그룹 관련 정보를 소개하고 있습니다. 필요하신 분들은 참고하시면 됩니다.
오늘 정규 매칭 문제를 접했는데, 갑자기 그룹 캡처라는 개념을 접하게 되었습니다. 매뉴얼에 있는 내용도 잠깐 건너뛰었는데, 우연히 C#과 Java에서 일반 캡처 그룹의 특별한 용도가 있다는 것을 발견하고, PHP라는 키워드를 검색해 보니 관련 내용이 없었습니다. 스스로 그것을 발견하고 PHP에서도 가능하다는 것을 알았으므로 공유하는 동안 일부 마스터와 주의 깊은 학습자가 내 이해에서 문제점을 찾을 수 있기를 바랍니다.
캡처 그룹이란 무엇입니까
캡처 그룹 구문:
Character |
Description |
예 |
( pattern) |
패턴을 맞춰서 결과를 캡쳐하면 자동으로 그룹번호가 설정됩니다. |
(abc)+d abcd 또는 abcabcd와 일치 |
|
(?<name>pattern) 또는 (?'name'pattern) |
패턴과 일치하고 결과를 캡처하여 그룹에 이름을 설정합니다. 이름. |
|
num |
캡처 그룹에 대한 역참조입니다. 여기서 num은 양의 정수입니다. |
(w)(w)21 은 abba |
|
k<name> 또는 과 일치합니다.k'name' |
이름이 지정된 캡처 그룹에 대한 역참조입니다. 여기서 name은 캡처 그룹 이름입니다. |
(? match xabcx |
我们先看一下PHP的正则匹配函数
int preg_match ( string $pattern , string $subject [, array &$matches [, int $flags = 0 [, int $offset = 0 ]]] )
前面两项是我们常用的,$pattern是正则匹配模式,$string是要匹配的字符串。
array &$match,它是一个数组,&表示匹配出来的结果会被写入$match中。
int $flags 如果传递了这个标记, 对于每一个出现的匹配返回时会附加字符串偏移量(相对于目标字符串的)。
int $offset 用于指定从目标字符串的某个未知开始搜索(单位是字节)。
我们主要看一下$match的值里会有什么:
$mode = '/a=(\d+)b=(\d+)c=(\d+)/'; $str='**a=4b=98c=56**'; $res=preg_match($mode,$str,$match); var_dump($match);
结果如下:
array (size=4)
0 => string 'a=4b=98c=56' (length=11)
1 => string '4' (length=1)
2 => string '98' (length=2)
3 => string '56' (length=2)
现在我们知道了什么是捕获组,捕获组是正则表达示中以()括起来的部分,每一对()是一个捕获组。
PHP会为它编号,从1开始。至于为什么会从1开始,那是因为PHP把匹配到的完整字符串编号为0。
如果有多个括号或嵌套括号,按左边括号出现的顺序来进行编号,如图:
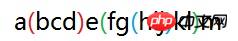
按图中的匹配模式匹配时,捕获组的123号分别是红绿蓝。
捕获组的忽略与命名
我们还可以阻止PHP为匹配组的编号:在匹配组中模式前加 ?:
$mode = '/a=(\d+)b=(?:\d+)c=(\d+)/';
这样,匹配结果就会变成:
array (size=3) 0 => string 'a=4b=98c=56' (length=11) 1 => string '4' (length=1) 2 => string '56' (length=2)
当然,我们也可以在括号的内部为它给它独特的名字。
命名子组可以接受(?
例如:$mode = '/a=(\d+)b=(?P
使用时结果为:
array (size=5) 0 => string 'a=4b=98c=56' (length=11) 1 => string '4' (length=1) 'sec' => string '98' (length=2) 2 => string '98' (length=2) 3 => string '56' (length=2)
在保留索引数组的同时,加上一个关联项,key值为捕获组名。
捕获组的反向引用
我们在用preg_replace()函数进行正则替换时,我们还可以使用 \n 或 $n 来引用第n个捕获组.
$mode = '/a=(\d+)b=(\d+)c=(\d+)/'; $str='**a=4b=98c=56**'; $rp='\1/$2/\3/'; echo preg_replace($mode,$rp,$str);//**4/98/56/**
\1表示捕获组1(4),$2为捕获组2(98),\3为捕获组3(56)。
非捕获组的用法:
非捕获组语法:
字符 | 描述 | Example |
(?:pattern) | 은 패턴과 일치하지만 일치하는 결과를 캡처하지 않습니다. | 'industr(?:y|ies) 는 'industry' 또는 'industries'와 일치합니다. |
(?=pattern) | 폭이 0인 정방향 조회, 일치하는 결과가 캡처되지 않습니다. | 'Windows (?=95|98|NT|2000)' 는 "Windows2000"의 "Windows"와 일치합니다. 는 "Windows3.1"의 "Windows"와 일치하지 않습니다. |
(?!pattern) | 너비가 0인 부정 조회, 일치하는 결과가 캡처되지 않습니다. | 'Windows(?!95|98|NT|2000)' 는 "Windows3.1"의 "Windows"와 일치합니다. 는 "Windows2000"의 "Windows"와 일치하지 않습니다. |
(?<=pattern) | 폭이 0인 전방 탐색, 일치하는 결과가 캡처되지 않습니다. | '2000 (?<=Office|Word|Excel)' 은 "Office2000"의 "2000"과 일치합니다 는 "Windows2000"의 "2000"과 일치하지 않습니다. |
(?패턴) | 零宽度负向回查,不捕获匹配结果。 | '2000 (? 匹配 " Windows2000" 中的 "2000" 不匹配 " Office2000" 中的 "2000"。 |
为什么称为非捕获组呢?那是因为它们有捕获组的特性,在匹配模式的()中,但是匹配时,PHP不会为它们编组,它们只会影响匹配结果,并不作为结果输出。
/d(?=xxx) 匹配"后面是xxx的一个数字"。
注意格式:只能放在匹配模式字符串之后!
例如:
$pattern='/\d(?=abc)/'; $str="ab36abc8eg"; $res=preg_match($pattern,$str,$match); var_dump($match);//6
匹配的6,因为只有它作为一个数字,后面还有abc。
(?<=xxx) /d 匹配"前面是xxx的一个数字"
注意格式:只能放在匹配模式字符串之前!
例如:
$pattern='/(?<=abc)\d/'; $str="ab36abc8eg"; $res=preg_match($pattern,$str,$match); var_dump($match);//8
匹配的8,因为只有它作为一个数字,后面还有abc。
与(?=xxx) (?<=xxx)相对的是(?!=xxx) (?
它表示前面/后面不是xxx的字符串,这里就不再举例了。
如果您觉得本博文对您有帮助,您可以推荐或关注我,如果您有什么问题,可以在下方留言讨论,谢谢。
总结:以上就是本篇文的全部内容,希望能对大家的学习有所帮助。
相关推荐:
위 내용은 PHP 캡처 그룹 및 비캡처 그룹의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



