

이 글에서는 주로 TensorFlow가 Random Training과 Batch Training을 구현하는 방법을 소개합니다. 이제 이를 공유하고 참고용으로 제공합니다. 와서 함께 살펴보세요
TensorFlow는 모델 변수를 업데이트합니다. 한 번에 하나의 데이터 포인트에서 작동하거나 한 번에 많은 양의 데이터에서 작동할 수 있습니다. 단일 훈련 예제로 작업하면 "기발한" 학습 프로세스가 발생할 수 있지만 대규모 배치를 사용한 훈련은 계산 비용이 많이 들 수 있습니다. 어떤 유형의 훈련을 선택하느냐는 기계 학습 알고리즘의 융합에 매우 중요합니다.
TensorFlow가 역전파가 작동하도록 가변 기울기를 계산하려면 하나 이상의 샘플에서 손실을 측정해야 합니다.
Random 훈련은 훈련 데이터와 목표 데이터 쌍을 무작위로 샘플링하여 훈련을 완료합니다. 또 다른 옵션은 대규모 배치 훈련에서 기울기 계산을 위한 손실을 평균화하는 것이며, 배치 훈련 크기를 전체 데이터 세트로 한 번에 확장할 수 있습니다. 여기서는 무작위 훈련과 배치 훈련을 사용하여 회귀 알고리즘의 이전 예를 확장하는 방법을 보여줍니다.
배치 훈련과 무작위 훈련의 차이점은 최적화 방법과 수렴입니다.
# 随机训练和批量训练
#----------------------------------
#
# This python function illustrates two different training methods:
# batch and stochastic training. For each model, we will use
# a regression model that predicts one model variable.
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.python.framework import ops
ops.reset_default_graph()
# 随机训练:
# Create graph
sess = tf.Session()
# 声明数据
x_vals = np.random.normal(1, 0.1, 100)
y_vals = np.repeat(10., 100)
x_data = tf.placeholder(shape=[1], dtype=tf.float32)
y_target = tf.placeholder(shape=[1], dtype=tf.float32)
# 声明变量 (one model parameter = A)
A = tf.Variable(tf.random_normal(shape=[1]))
# 增加操作到图
my_output = tf.multiply(x_data, A)
# 增加L2损失函数
loss = tf.square(my_output - y_target)
# 初始化变量
init = tf.global_variables_initializer()
sess.run(init)
# 声明优化器
my_opt = tf.train.GradientDescentOptimizer(0.02)
train_step = my_opt.minimize(loss)
loss_stochastic = []
# 运行迭代
for i in range(100):
rand_index = np.random.choice(100)
rand_x = [x_vals[rand_index]]
rand_y = [y_vals[rand_index]]
sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y})
if (i+1)%5==0:
print('Step #' + str(i+1) + ' A = ' + str(sess.run(A)))
temp_loss = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})
print('Loss = ' + str(temp_loss))
loss_stochastic.append(temp_loss)
# 批量训练:
# 重置计算图
ops.reset_default_graph()
sess = tf.Session()
# 声明批量大小
# 批量大小是指通过计算图一次传入多少训练数据
batch_size = 20
# 声明模型的数据、占位符
x_vals = np.random.normal(1, 0.1, 100)
y_vals = np.repeat(10., 100)
x_data = tf.placeholder(shape=[None, 1], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
# 声明变量 (one model parameter = A)
A = tf.Variable(tf.random_normal(shape=[1,1]))
# 增加矩阵乘法操作(矩阵乘法不满足交换律)
my_output = tf.matmul(x_data, A)
# 增加损失函数
# 批量训练时损失函数是每个数据点L2损失的平均值
loss = tf.reduce_mean(tf.square(my_output - y_target))
# 初始化变量
init = tf.global_variables_initializer()
sess.run(init)
# 声明优化器
my_opt = tf.train.GradientDescentOptimizer(0.02)
train_step = my_opt.minimize(loss)
loss_batch = []
# 运行迭代
for i in range(100):
rand_index = np.random.choice(100, size=batch_size)
rand_x = np.transpose([x_vals[rand_index]])
rand_y = np.transpose([y_vals[rand_index]])
sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y})
if (i+1)%5==0:
print('Step #' + str(i+1) + ' A = ' + str(sess.run(A)))
temp_loss = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})
print('Loss = ' + str(temp_loss))
loss_batch.append(temp_loss)
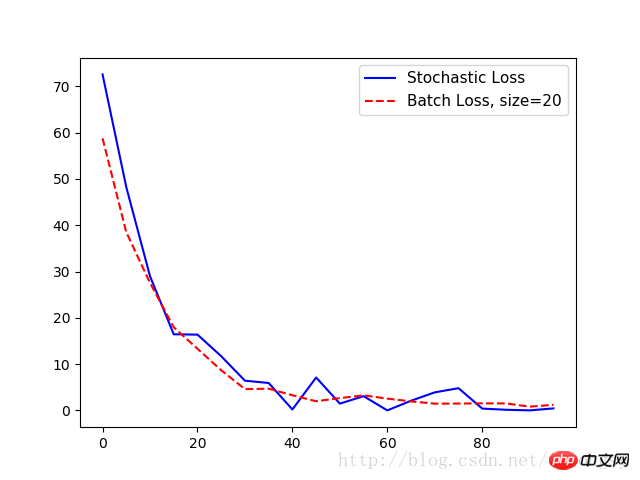
plt.plot(range(0, 100, 5), loss_stochastic, 'b-', label='Stochastic Loss')
plt.plot(range(0, 100, 5), loss_batch, 'r--', label='Batch Loss, size=20')
plt.legend(loc='upper right', prop={'size': 11})
plt.show()출력:
단계 #5 A = [ 1.47604525]
손실 = [ 72.55678558]
단계 #10 A = [ 3.01128507]
손실 = [ 48.229 86221]
15단계 A = [4.27042341 ]
손실 = [ 28.97912598]
단계 #20 A = [ 5.2984333]
손실 = [ 16.44779968]
단계 #25 A = [ 6.17473984]
손실 = [ 16.373312]
단계 #30 A = [ 6 .89866304]
손실 = [ 11.71054649 ]
단계 #35 A = [ 7.39849901]
손실 = [ 6.42773056]
단계 #40 A = [ 7.84618378]
손실 = [ 5.92940331]
단계 #45 A = [ 8.15709 782]
손실 = [ 0 .2142024 ]
단계 #50 A = [ 8.54818344]
손실 = [ 7.11651039]
단계 #55 A = [ 8.82354641]
손실 = [ 1.47823763]
단계 #60 A = [ 9.07896614]
손실 = [ 3.08244276 ]
65단계 A = [ 9.24868107]
손실 = [ 0.01143846]
단계 #70 A = [ 9.36772251]
손실 = [ 2.10078788]
단계 #75 A = [ 9.49171734]
손실 = [ 3.9091370 1]
단계 #80 A = [ 9 . 6622715]
손실 = [ 4.80727625 ]
단계 #85 A = [ 9.73786926]
손실 = [ 0.39915398]
단계 #90 A = [ 9.81853104]
손실 = [ 0.14876099]
95단계 A = [ 9.90371323]
손실 = [ 0 .01657014]
단계 #100 A = [ 9.86669159]
손실 = [ 0.444787]
단계 #5 A = [[ 2.34371352]]
손실 = 58.766
단계 #10 A = [[ 3.74766445]]
손실 = 38.4875
15단계 A = [[ 4.88928795 ]]
손실 = 27.5632
20단계 A = [[ 5.82038736]]
손실 = 17.9523
25단계 A = [[ 6.58999157]]
손실 = 13.32 45
30단계 A = [[ 7.20851326 ]]
손실 = 8.68099
단계 #35 A = [[ 7.71694899]]
손실 = 4.60659
단계 #40 A = [[ 8.1296711]]
손실 = 4.70107
단계 #45 = [[ 8.47107315] ]
손실 = 3.28318
단계 #50 A = [[ 8.74283409]]
손실 = 1.99057
단계 #55 A = [[ 8.98811722]]
손실 = 2.66906
단계 #60 A = [[ 9.18062305 ]]
손실 = 3.26207
단계 #65 A = [[ 9.31655025 ]]
손실 = 2.55459
단계 #70 A = [[ 9.43130589]]
손실 = 1.95839
단계 #75 A = [[ 9.55670166]]
손실 = 1.465 04
스텝 #80A = [[ 9.6354847] ]
손실 = 1.49021
단계 #85 A = [[ 9.73470974]]
손실 = 1.53289
단계 #90 A = [[ 9.77956581]]
손실 = 1.52173
단계 #95 = [[ 9.83666706] ]
손실 = 0.819207
단계 #100 A = [[ 9.85569191]]
손실 = 1.2197
| 훈련 유형 | 장점 | 단점 |
|---|---|---|
| 무작위 훈련 | 로컬 최소값을 벗어남 | 일반적으로 업데이트 필요 수렴하려면 여러 번의 반복이 필요함 |
| 배치 훈련 | 최소 손실을 빠르게 확보 | 더 많은 컴퓨팅 리소스 소비 |
관련 권장 사항:
A tensorflow1.0 풀링 계층(풀링) 및 전체 연결 계층(고밀도)에 대한 간략한 이야기
Tensorflow 모델 저장 및 복원에 대한 간략한 토론
위 내용은 TensorFlow가 무작위 훈련과 배치 훈련을 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



