

이 글은 Python 프로그래밍에서 Monte Carlo 방법을 통해 정적분을 계산하는 방법에 대한 자세한 설명을 주로 소개합니다. 필요한 친구들이 참고할 수 있습니다.
대학원 입시를 볼 때, 정적분을 계산하는 것, 이런 좋은 게 있다는 걸 알았더라면 좋았을 걸로 기억합니다. . . 농담이에요. 당시에는 정적분을 계산하는 것이 그렇게 간단하지 않았습니다. 하지만 더 복잡한 수학적 문제를 해결하기 위해 프로그래밍 언어를 사용하는 아이디어가 열렸습니다. 요점을 살펴 보겠습니다.
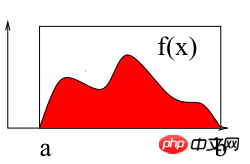
위 그림과 같이 구간 [a b]에서 f(x)의 적분을 계산하면 곡선과 X축으로 둘러싸인 빨간색 영역의 면적을 구하는 것입니다. 아래에서는 Monte Carlo 방법을 사용하여 구간 [2 3]에서 정적분을 계산합니다. > Monte Carlo 추정= 11.8181144118 정확한 숫자= 11.8113589251
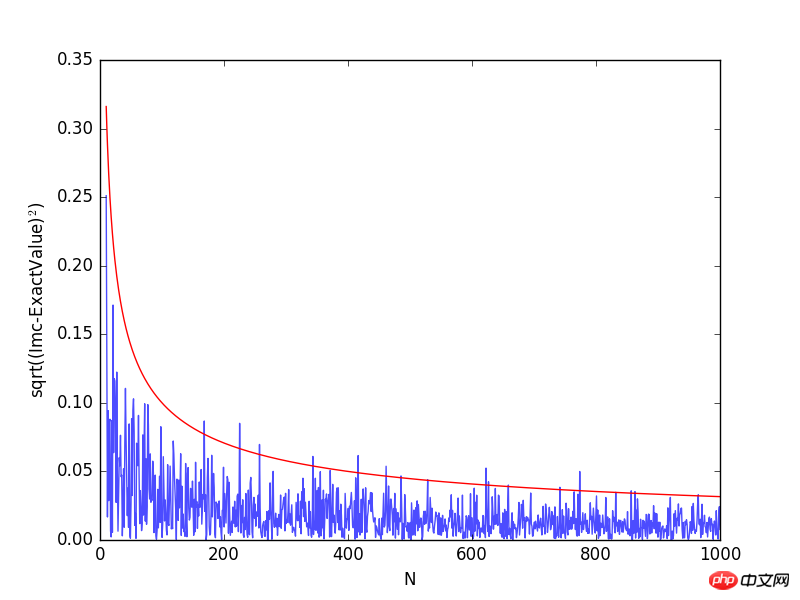
위 그림에서 알 수 있듯이 샘플링 포인트 수가 증가할수록 계산 오류는 점차 감소합니다. 시뮬레이션 결과의 정확도를 높이는 방법에는 두 가지가 있습니다. 하나는 테스트 수 N을 늘리는 것이고, 다른 하나는 분산 σ2를 줄이는 것입니다. 테스트 수를 늘리면 문제를 해결하는 데 사용되는 총 컴퓨터 시간이 필연적으로 늘어납니다. 정확성을 높이기 위한 목적은 명백히 부적절합니다. 다음으로 분산을 줄이고 적분 계산의 정확도를 높이기 위해 중요한 샘플링 방법을 소개합니다.
를 따르는 샘플링 지점입니다. 다음 예 정규 분포 함수 f(x)를 사용하여 g를 근사화합니다. (x)=sin(x)*x, 정규분포에 따라 표본값을 선택하여 구간 [0pi] 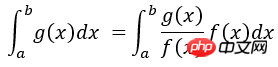
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return x**2 + 4*x*np.sin(x)
def intf(x):
return x**3/3.0+4.0*np.sin(x) - 4.0*x*np.cos(x)
a = 2;
b = 3;
# use N draws
N= 10000
X = np.random.uniform(low=a, high=b, size=N) # N values uniformly drawn from a to b
Y =f(X) # CALCULATE THE f(x)
# 蒙特卡洛法计算定积分:面积=宽度*平均高度
Imc= (b-a) * np.sum(Y)/ N;
exactval=intf(b)-intf(a)
print "Monte Carlo estimation=",Imc, "Exact number=", intf(b)-intf(a)
# --How does the accuracy depends on the number of points(samples)? Lets try the same 1-D integral
# The Monte Carlo methods yield approximate answers whose accuracy depends on the number of draws.
Imc=np.zeros(1000)
Na = np.linspace(0,1000,1000)
exactval= intf(b)-intf(a)
for N in np.arange(0,1000):
X = np.random.uniform(low=a, high=b, size=N) # N values uniformly drawn from a to b
Y =f(X) # CALCULATE THE f(x)
Imc[N]= (b-a) * np.sum(Y)/ N;
plt.plot(Na[10:],np.sqrt((Imc[10:]-exactval)**2), alpha=0.7)
plt.plot(Na[10:], 1/np.sqrt(Na[10:]), 'r')
plt.xlabel("N")
plt.ylabel("sqrt((Imc-ExactValue)$^2$)")
plt.show()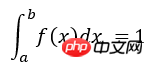
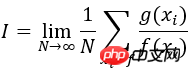 그림에서 볼 수 있듯이 sin(x)*x 곡선의 모양은 정규 분포 곡선의 모양과 유사하므로 곡선 정점의 샘플링 지점 수가 위치보다 낮습니다. 곡선에서는 더 많은 공간이 필요합니다. 정확한 계산 결과는 pi입니다. 위의 오른쪽 그림에서 볼 수 있듯이 두 방법 모두 1000번의 정적분을 계산한 결과가 pi=3.1415에 가까울수록 정확한 값에서 멀어집니다. 숫자가 작을수록 이는 기존 방식과 일치합니다. 그러나 전통적인 방법을 사용하여 계산된 적분값의 제곱의 차이(빨간색 히스토그램)는 중요한 샘플링 방법을 사용한 것(파란색 히스토그램)보다 훨씬 큽니다. 따라서 중요도 샘플링 방법을 사용하면 분산을 줄이고 정확도를 높일 수 있습니다. 또한, 함수 f(x)의 선택은 계산 결과의 정확성에 영향을 미친다는 점에 유의해야 합니다. 우리가 선택한 함수 f(x)가 g(x)와 매우 다를 경우, 계산 결과도 증가합니다.
그림에서 볼 수 있듯이 sin(x)*x 곡선의 모양은 정규 분포 곡선의 모양과 유사하므로 곡선 정점의 샘플링 지점 수가 위치보다 낮습니다. 곡선에서는 더 많은 공간이 필요합니다. 정확한 계산 결과는 pi입니다. 위의 오른쪽 그림에서 볼 수 있듯이 두 방법 모두 1000번의 정적분을 계산한 결과가 pi=3.1415에 가까울수록 정확한 값에서 멀어집니다. 숫자가 작을수록 이는 기존 방식과 일치합니다. 그러나 전통적인 방법을 사용하여 계산된 적분값의 제곱의 차이(빨간색 히스토그램)는 중요한 샘플링 방법을 사용한 것(파란색 히스토그램)보다 훨씬 큽니다. 따라서 중요도 샘플링 방법을 사용하면 분산을 줄이고 정확도를 높일 수 있습니다. 또한, 함수 f(x)의 선택은 계산 결과의 정확성에 영향을 미친다는 점에 유의해야 합니다. 우리가 선택한 함수 f(x)가 g(x)와 매우 다를 경우, 계산 결과도 증가합니다.
관련 권장 사항:
위 내용은 몬테카를로 방법을 통해 정적분을 계산하는 Python 프로그래밍에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



