

이 글은 주로 Python의 도서관 공부방 자동 예약 기능에 대해 자세히 소개합니다. 관심 있는 친구들이 참고할 수 있습니다.
이 글은 Python의 도서관 공부방 자동 예약 기능을 공유합니다. 구체적인 코드는 참고용입니다. 구체적인 내용은 다음과 같습니다
소개
현재 많은 학교에서는 학생들에게 매우 좋은 학습 환경을 제공하고 있으며 이는 일반적으로 자율 학습 교실의 시설과 장비에 반영됩니다. 이에 대해 제가 언급해야 할 것은 우리 학교의 도서관입니다. 새 도서관이 건설됨에 따라 도서관에는 여러 기능 영역이 설치되었습니다. 각 층은 A, B, C, D의 네 영역으로 나누어져 있습니다. 북쪽과 남쪽으로 복도가 연결되어 있으며 나선형 계단이 1층부터 5층까지 이어져 있습니다. A구역은 자습실, B구역과 C구역은 수집과 독서가 통합된 사회과학과 자연과학 서점, D구역은 영화 및 TV관, 디지털미디어 메이커 체험관, 스마트관 등을 포함한 특수기능구역이다. B 구역과 C 구역의 동서 복도에는 12개의 크고 작은 학습실이 있으며, 남북 복도에는 여가 독서 공간이 있습니다.
도서관 공식 홈페이지에서 위 문단을 복사했는데, 학교 도서관에는 정말 엄지척을 드리고 싶습니다. 이 기사의 주제로 돌아가서, 학교는 교사와 학생에게 편안하고 품질이 뛰어나며 시설이 잘 갖춰진 학습실을 무료로 제공합니다. 단, 이러한 스터디룸은 매일 00:00부터 예약이 가능하므로 온라인 예약이 필요합니다. 한밤중의 기름을 태워야합니다. 물론, 빠른 손을 갖는 것은 이 과정에서 큰 이점이 될 것입니다. 밤에 일찍 잠자리에 들고 손의 속도가 빠르지 않으면 기본적으로 스터디룸에서 약속을 잡을 수 없습니다. 저는 최근에 우연히 Python 크롤러에 대해 조금 배웠고 이 힘든 작업을 완료하는 데 크롤러를 사용할 계획입니다. 하하하하! (PS: 악의적인 접근을 방지하기 위해 모든 링크는 게시되지 않습니다.)
Python 구현 아이디어
아이디어는 아주 간단합니다. 생각해보면 계정에 로그인하고 방을 검색하는 것 외에는 아무것도 아닙니다. , 예약을 제출합니다. 그럼 한 번 시도해 보세요:
계정에 로그인
먼저 스터디룸 약속을 위한 로그인 인터페이스를 엽니다. 링크는 다음과 같습니다: U2FsdGVkX19NdfJkghN54Msvy1zl7AucRur/ct0nz4orPI7uLkSDsvuFMgr0fGcO
rn9Z/f8h3bds9w==
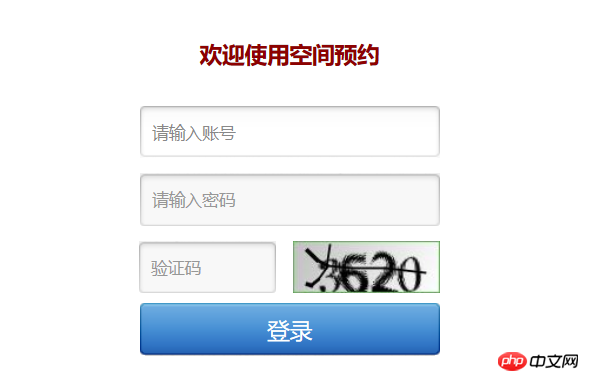
알겠습니다. 첫 번째 단계는 계정에 로그인하는 것입니다. 초보자인 저에게는 테스트이지만 소심할 수는 없습니다. 다른 몇몇 아저씨들이 사용하는 방법을 참고하면, 파이어폭스의 파이어버그를 열어(ctrl+shift+e) 네트워크 상황을 확인하고, 이 경우에는 정상적인 로그인을 수행한다는 것입니다.

여기에 게시물이 있는 것을 볼 수 있으며, Python에서 request.post 메소드를 사용할 수 있습니다.
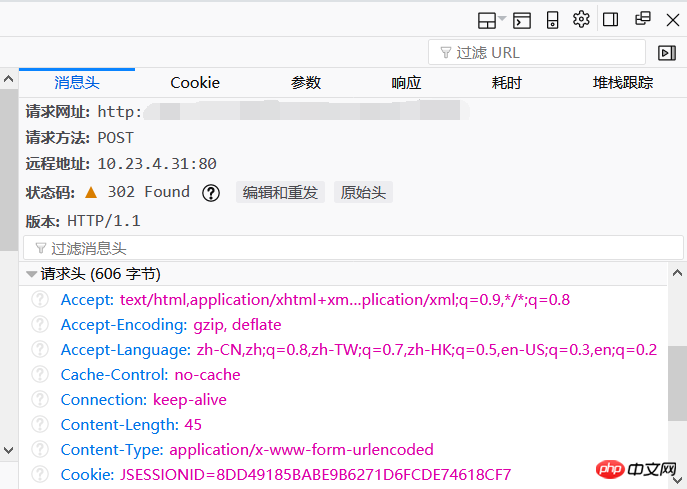
로그인하려면 크롤러로서의 신원을 숨겨야 합니다. 메시지 헤더에서 요청 헤더를 볼 수 있습니다. 모든 매개변수를 복사하고 자신만의 헤더 = {…}를 구성하면 됩니다. 서버.
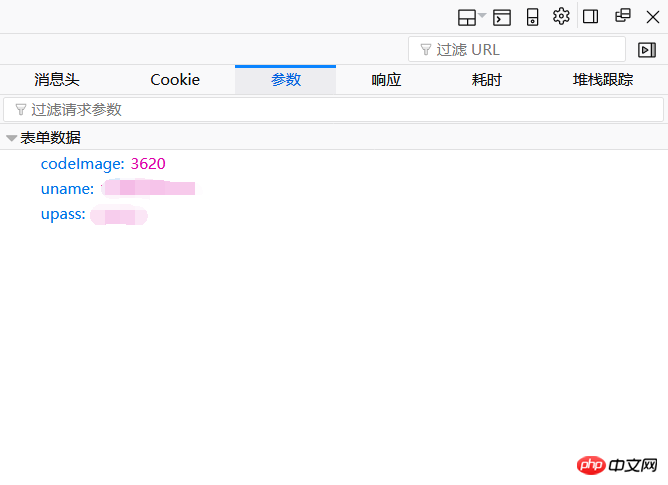
여기에는 인증 코드, 계좌 번호, 비밀번호에 해당하는 양식 데이터가 3개만 있습니다. 여기에 매개변수를 복사하여 데이터 = {...}를 형성합니다. 우리가 주의해야 할 것은 이 인증 코드입니다. 기계가 수동으로 인식하든 자동으로 인식하든 상관없이 인증 코드를 로컬 파일로 저장해야 합니다. 그러다 보니 서버에 접속할 때마다 인증번호가 바뀌는 문제가 발생합니다. 이제 생각해 보겠습니다. 먼저 확인 코드를 가져와 로컬에 저장해야 하며, 이를 위해서는 서버를 방문해야 합니다. 마지막으로 로그인을 위해 매개변수를 제출해야 합니다. 이번에는 서버를 다시 방문합니다. 인증코드와 우리가 받은 인증코드는 더 이상 동일한 인증코드가 아닙니다. 첫 번째 시도에서는 두 개의 인증 코드가 일치하지 않아 어쨌든 서버에 로그인할 수 없었습니다. 처음으로 받은 인증 코드가 제출 시의 인증 코드와 일치하도록 하려면 어떻게 해야 합니까?
여기에도 동일한 쿠키가 필요합니다. 위 사진을 보면 쿠키 값이 있다는 것을 모두 알 수 있습니다. 동기화를 보장하려면 인증 코드를 받을 때의 쿠키 값이 계정 비밀번호를 제출할 때의 쿠키 값과 일치하는지 확인해야 합니다. 따라서 내 프로그램에서 내가 하는 첫 번째 단계는 쿠키 값을 얻은 다음 이 쿠키 값을 헤더의 매개 변수로 사용하는 것입니다. 이것이 바로 로그인 아이디어입니다. 여기에서 인증코드를 수동으로 식별했다는 점을 덧붙이고 싶습니다>﹏<.>
방 찾기
이 단계는 실제로 쓸모없는 단계입니다. 인간의 예약 습관에 따라 어떤 단계가 생성됩니까? 그런데 크롤러를 사용하면 로그인 성공 후 직접 예약 양식을 제출할 수 있습니다. 물론, 자동 예약 프로그램을 더욱 지능적으로 만들고 싶다면 이 단계를 추가하여 아직 예약 가능한 객실을 확인하고 여기에 몇 가지 맞춤 규칙을 추가할 수 있습니다. 그냥 건너뛰었어요. . .
약속 제출
로그인과 마찬가지로 수동으로 제출하여 네트워크 상황을 확인한 다음 Python을 사용하여 이 프로세스를 시뮬레이션할 수 있습니다. 여기서는 사진으로 설명하지 않겠습니다. 여기서도 요청을 제출하는 방법을 사용합니다. 다만, 한 가지 주의할 점은 이곳의 헤더는 로그인 시의 헤더와 다르다는 점이므로, 비슷한 다른 예약 프로그램을 사용하신다면 다른 내용을 게시할 때 헤더가 맞는지 주의 깊게 살펴보시면 된다는 점을 알려드리고 싶습니다. 일관된. 저는 여기서 한동안 속았습니다.
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
#
# @Version : 1.0
# @Time : 2018/4/10
# @Author : 圈圈烃
# @File : reservation_4.py
import requests
import re
import json
import datetime
import time
def get_cookies():
"""获得cookies"""
url = 'http://**************'
s = requests.session()
s.get(url)
ck_dict = requests.utils.dict_from_cookiejar(s.cookies) # 将jar格式转化为dict
ck = 'JSESSIONID=' + ck_dict['JSESSIONID'] # 重组cookies
"""获得二维码"""
path = './code.png'
get_cookies_headers = {
'user-anget': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0',
'Cookie': ck}
get_cookies_url = 'http://**************'
code_image = requests.get(get_cookies_url, headers=get_cookies_headers)
with open(path, 'wb') as fn:
fn.write(code_image.content)
fn.close()
print('验证码保存成功')
return ck
def login(cookies, hour, minute):
login_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Length': '45',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': cookies,
'Host': '**************',
'Pragma': 'no-cache',
'Referer': 'http://**************',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
}
login_url = 'http://**************'
login_data = {
'codeImage': input('请输入验证码:'),
'uname': '**************',
'upass': '**************'
}
requests.post(login_url, data=login_data, headers=login_headers)
res = requests.get('http://**************', headers=login_headers)
reg_h = r'<option value=(.*?)>\d{4}-\d{2}-\d{2}' # 匹配可提供预约的hash
value_h = re.findall(reg_h, res.text)
"""定时"""
counter = 0
while (True):
now = datetime.datetime.now() # 获取当前系统时间
if now.hour == hour and now.minute == minute:
break
time.sleep(0.5)
# print(now)
counter = counter + 1
if counter == 240:
res = requests.get('http://**************', headers=login_headers)
reg_h = r'<option value=(.*?)>\d{4}-\d{2}-\d{2}' # 匹配可提供预约的hash
reg_t = r'(\d{4}-\d{2}-\d{2})' # 匹配可提供预约的日期
value_h = re.findall(reg_h, res.text)
value_t = re.findall(reg_t, res.text)
with open('./con_log.txt', 'a') as fjs:
fjs.write(eval(value_h[-1])+' '+value_t[-1]+' '+str(now)+' \n')
fjs.close()
print('保存成功')
counter = 0
return str(eval(value_h[-1]))
def reservation(day_hash, cookies, stime, etime):
reservation_data = {
'_etime': etime, # 结束时间11点,其值为11*60=660
'_roomid': '1285b3ca77594b3095c7b89d4922553c', # 房间Id
'_seatno': '',
'_stime': stime, # 开始时间8点,其值为8*60=480
'_subject': '学习', # 研讨主题
'_summary': '学习', # 研讨大纲
'ruleId': day_hash,
'usercount': 3, # 预约人数
'users': '**************', # 学号
'UUID': '**************'
}
reservation_headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Length': '239',
'Content-Type': 'application/json',
'Cookie': cookies,
'Host': '**************',
'Pragma': 'no-cache',
'Referer': 'http://**************',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
}
reservation_js = json.dumps(reservation_data)
reservation_url = 'http://**************'
status = requests.post(reservation_url, data=reservation_js, headers=reservation_headers)
# print(stime, etime)
# print(status)
print(status.text)
def main():
"""预约策略一:11:20-20.40"""
full_stime = ['1060', '870', '680']
full_etime = ['1240', '1050', '860']
"""预约策略二:10:00-13:00;13:50-16:50;17:40-20:40"""
stime = ['1060', '830', '600']
etime = ['1240', '1010', '780']
cookies = get_cookies()
day_hash = login(cookies, 0, 0) # 设定定时时间
for i in range(0, 3):
reservation(day_hash, cookies, stime[i], etime[i])
if __name__ == '__main__':
main()결과 달성
파이썬을 배운 이후로 엄마는 더 이상 내가 공부방을 못 잡을까봐 걱정하실 필요가 없습니다. 프로그램에 몇 줄의 타이밍 절차를 추가하면 자동으로 00:00에 나를 위한 스터디룸을 예약할 수 있습니다. 테스트를 통해 대규모로 약속을 잡는 것이 가능하다는 사실을 알아냈습니다. 예를 들어 4일부터 12일까지는 3개 시간대에 걸쳐 약속을 잡는 데 7초가 걸렸지만, 4일부터 13일까지는 약속을 잡는 데 7초가 걸렸습니다. 실제로는 21초가 걸렸고, 어느 정도 시간이 지나서 다른 반 친구들이 저를 초대했습니다. 물론, 이 프로그램은 "손 속도"에 대한 완전한 승리를 달성하기 위해 여전히 추가 개선이 필요합니다.
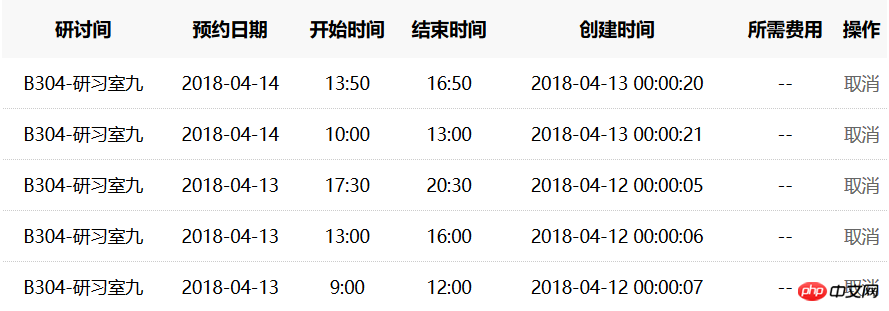
마지막에 추가해주세요
부족한 점 있으면 소통 환영합니다.
관련 추천:
Python은 자동 캠퍼스 네트워크 로그인을 실현합니다
위 내용은 Python으로 도서관 스터디룸 자동 예약 기능 구현의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



