

Python을 배우다 보면 웹 사이트 콘텐츠가 Ajax 동적 요청 및 비동기 새로 고침을 통해 생성된 json 데이터이고 Python을 통해 정적 웹 콘텐츠를 크롤링하는 이전 방법이 불가능한 상황에 직면하게 되므로 이번 기사에서는 그 방법에 대해 이야기하겠습니다. Python에서 ajax에 의해 동적으로 생성된 데이터를 크롤링합니다.
Python을 배우다 보면 웹 사이트 콘텐츠가 Ajax 동적 요청 및 비동기 새로 고침을 통해 생성된 json 데이터이고 Python을 통해 정적 웹 콘텐츠를 크롤링하는 이전 방법이 불가능한 상황에 직면하게 되므로 이 글에서는 이 글에서 설명하겠습니다. Python에서 ajax에 의해 동적으로 생성된 데이터를 크롤링하는 방법.
정적인 웹 콘텐츠를 읽는 방법에 관심이 있는 분들은 이 글의 내용을 확인해 보세요.
여기에서는 Taobao 댓글 크롤링을 예로 들어 방법을 설명합니다.
이것은 주로 4단계로 나뉩니다:
먼저 Taobao 리뷰를 받을 때 ajax는 링크(url)를 요청합니다
두 번째, ajax 요청에 의해 반환된 json 데이터를 가져옵니다
셋, 파이썬을 사용하여 json 데이터 파싱하기
Four 파싱된 결과 저장하기
1단계:
타오바오 댓글을 받을 때, ajax 요청 링크(url) 여기서는 크롬 브라우저를 사용합니다. 완료합니다. Taobao 링크를 열고 검색창에서 "신발"과 같은 제품을 검색합니다. 여기서는 첫 번째 제품을 선택합니다.

그런 다음 새 웹페이지로 이동합니다. 여기서는 사용자 리뷰를 크롤링해야 하므로 Accumulated Ratings를 클릭합니다.

그런 다음 제품에 대한 사용자 평가를 볼 수 있습니다. 이때 웹 페이지를 마우스 오른쪽 버튼으로 클릭하여 리뷰 요소를 선택하거나 F12를 사용하여 직접 열고 그림과 같이 네트워크 옵션을 선택합니다. 사진에서:
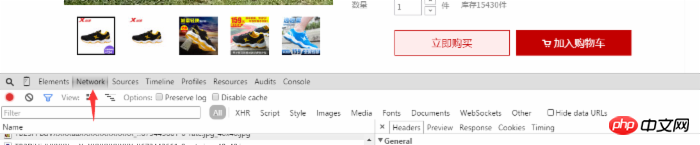
사용자 댓글에서 아래쪽으로 스크롤하여 다음 또는 두 번째 페이지를 클릭하면 네트워크에 동적으로 추가된 여러 항목이 표시됩니다. list_detail_rate.htm?itemId=로 시작합니다. 35648967399.

그런 다음 이 옵션을 클릭하면 오른쪽 옵션 상자에서 링크에 대한 정보를 볼 수 있으며 요청 URL에 링크 내용을 복사하려고 합니다.

브라우저의 주소 표시줄에 방금 얻은 URL 링크를 입력합니다. 페이지를 열면 필요한 데이터가 반환되지만 JSON 데이터이기 때문에 지저분해 보입니다.

2 ajax 요청에서 반환된 json 데이터 가져오기
다음으로 URL에서 json 데이터를 가져옵니다. 제가 사용하는 Python 편집기는 pycharm입니다. Python 코드를 살펴보겠습니다.
# -*- coding: utf-8 -*- import sys reload(sys) sys.setdefaultencoding('utf-8') import requests url='https://rate.tmall.com/list_detail_rate.htm?itemId=35648967399&spuId=226460655&sellerId=1809124267ℴ=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=011UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5OcktyT3ZCf0B9Qn9GeC4%3D%7CU2xMHDJ7G2AHYg8hAS8WKAYmCFQ1Uz9YJlxyJHI%3D%7CVGhXd1llXGVYYVVoV2pVaFFvWGVHe0Z%2FRHFMeUB4QHxCdkh8SXJcCg%3D%3D%7CVWldfS0RMQ47ASEdJwcpSDdNPm4LNBA7RiJLDXIJZBk3YTc%3D%7CVmhIGCUFOBgkGiMXNwswCzALKxcpEikJMwg9HSEfJB8%2FBToPWQ8%3D%7CV29PHzEfP29VbFZ2SnBKdiAAPR0zHT0BOQI8A1UD%7CWGFBET8RMQszDy8QLxUuDjIJNQA1YzU%3D%7CWWBAED4QMAU%2BASEYLBksDDAEOgA1YzU%3D%7CWmJCEjwSMmJXb1d3T3JMc1NmWGJAeFhmW2JCfEZmWGw6GicHKQcnGCUdIBpMGg%3D%3D%7CW2JfYkJ%2FX2BAfEV5WWdfZUV8XGBUdEBgVXVJciQ%3D&isg=82B6A3A1ED52A6996BCA2111C9DAAEE6&_ksTS=1440490222698_2142&callback=jsonp2143' #这里的url比较长 content=requests.get(url).content
print content #인쇄된 콘텐츠는 이전에 웹페이지에서 얻은 json 데이터입니다. 사용자 의견을 포함합니다.
여기 내용은 우리에게 필요한 json 데이터입니다. 다음 단계는 이러한 json 데이터를 구문 분석하는 것입니다. 삼 json을 가져와야 합니다
cont=requests.get(url).content # 웹 페이지에서 json 데이터 가져오기rex=re.compile(r'w+[(]{1}(.*)[)]{ 1}') #정규식 제거 cont 데이터에서 중복되는 부분은 실제 json 형식 데이터 {"a":"b","c":"d"}con=json.loads( content,"gbk") json 사용 로드 함수는 콘텐츠 콘텐츠를 json 라이브러리 함수로 처리할 수 있는 데이터 형식으로 변환합니다. win 시스템의 기본값은 gbk
count이므로 "gbk"는 데이터의 인코딩 방법입니다. =len(con['rateDetail']['rateList']) # 사용자 댓글 수를 가져옵니다(여기는 현재 페이지에만 적용됩니다)
for i in xrange(count):
print con['rateDetail'] ['rateList'][i]['appendComment']
IV 파싱된 결과 저장
여기에서 사용자는 사용자의 댓글 정보를 csv 형식으로 저장하는 등 로컬에 저장할 수 있습니다.
이 글은 여기까지입니다. 모두 마음에 드셨으면 좋겠습니다.
위 내용은 Python이 ajax(클래식)에 의해 동적으로 생성된 데이터를 크롤링하는 방법을 설명하기 위해 Taobao 주석을 수집하는 예를 사용합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



