

Jianshu 홈페이지를 열어보세요. 특별한 것은 없는 것 같습니다

OpenChrome의 개발자 모드에서 기사 제목과href가 모두태그는 별거 없는 것 같습니다
chrome的开发者模式,发现文章的标题,href都在a标签里,似乎也没有什么不一样的

a.png
接下来就是寻找页面上所有的
a标签,但是且慢如果你仔细观察就会发现滑轮滚到一半的时候页面就会加载更多,这样的步骤会重复三次知道底部出现阅读更多a.png다음 단계는 하지만 잠시만 기다려 주시면 도르래가 반쯤 굴러가면 페이지가 더 많이 로드되는 것을 알 수 있습니다. 이 단계는 하단이 나타날 때까지 세 번 반복됩니다.
자세히 보기버튼

Pulley
그뿐만 아니라, 하단의
href내용도 페이지의 나머지 부분을 로드하라고 지시하지 않습니다. 유일한 방법은자세히 보기 버튼을 계속 클릭하는 것입니다href并没有告诉我们加载剩下的页面信息,唯一的办法是不断点击阅读更多这个按钮
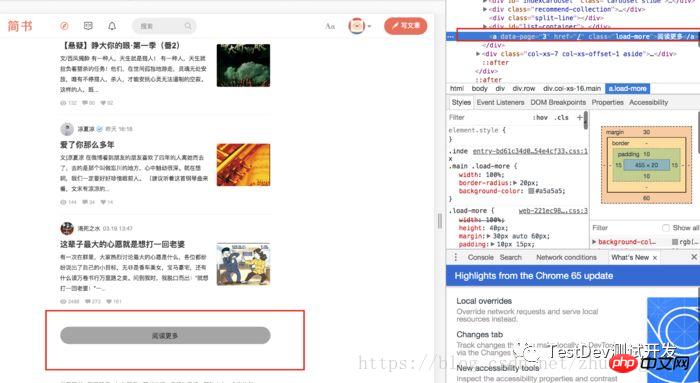
load_more.png
什么,将滑轮重复三次滑倒页面的中央并且不断点击按钮这种操作http请求可做不到,这更像是js操作?没错,简书的文章并不是常规的http请求,我们不能根据不同url不断重定向,而是页面的一些动作来加载页面信息。

selenium是一个web自动化测试工具,支持很多种语言,我们在这里可以使用python的selenium做爬虫使用,爬取简书的过程中,它的工作原理是不断注入js代码,让页面源源不断的加载,最后再提取所有的a
 load_more.png
load_more.png뭐야,도르래를 반복하세요 페이지를 세 번 아래로 밀어서 중앙으로계속 버튼을 클릭하면 이 작업이http요청을 수행할 수 없습니다. 이것이 js 작업과 더 비슷합니까? 맞습니다. Jianshu의 기사는 일반적인 http 요청이 아니며 다양한 URL에 따라 지속적으로 리디렉션할 수는 없지만 페이지 정보를 로드하기 위한 페이지의 일부 작업이 있습니다.
>>> pip3 install selenium
在写代码之前一定要把chromedriver同一文件夹内,因为我们需要引用PATH,这样方便点。首先我们的第一个任务是刷出加载更多的按钮,需要做3次将滑轮重复三次滑倒页面的中央,这里方便起见我滑到了底部
from selenium import webdriverimport time browser = webdriver.Chrome("./chromedriver") browser.get("https://www.jianshu.com/")for i in range(3): browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") // execute_script是插入js代码的 time.sleep(2) //加载需要时间,2秒比较合理
看看效果
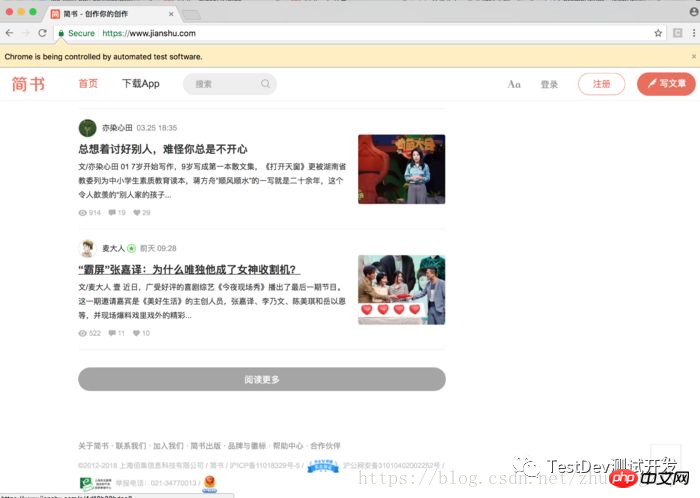
刷出了按钮
接下来就是不断点击按钮加载页面,继续加入刚才的py文件之中
for j in range(10): //这里我模拟10次点击 try: button = browser.execute_script("var a = document.getElementsByClassName('load-more'); a[0].click();") time.sleep(2) except: pass''' 上面的js代码说明一下 var a = document.getElementsByClassName('load-more');选择load-more这个元素 a[0].click(); 因为a是一个集合,索引0然后执行click()函数 '''
这个我就不贴图了,成功之后就是不断地加载页面 ,知道循环完了为止,接下来的工作就简单很多了,就是寻找a标签,get其中的text和href属性,这里我直接把它们写在了txt文件之中.
titles = browser.find_elements_by_class_name("title")with open("article_jianshu.txt", "w", encoding="utf-8") as f: for t in titles: try: f.write(t.text + " " + t.get_attribute("href")) f.write("\n") except TypeError: pass
最终结果
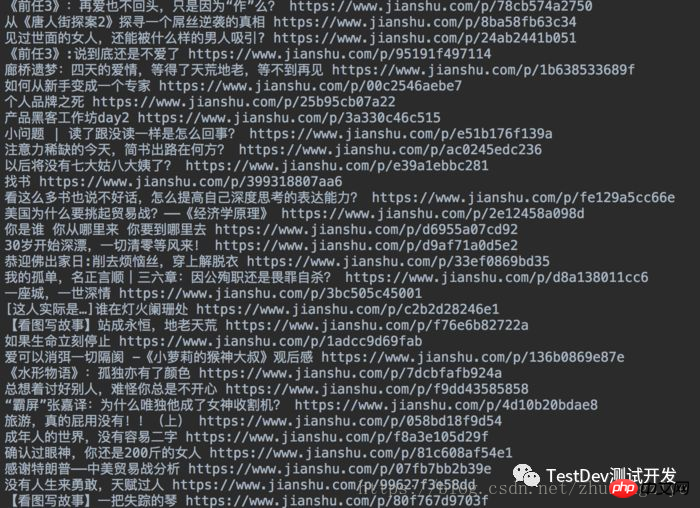
简书文章
不断加载页面肯定也很烦人,所以我们测试成功之后并不想把浏览器显示出来,这需要加上headless模式
options = webdriver.ChromeOptions() options.add_argument('headless') browser = webdriver.Chrome("./chromedriver", chrome_options=options) //把上面的browser加入chrome_options参数
当我们没办法使用正常的http请求爬取时,可以使用selenium操纵浏览器来抓取我们想要的内容,这样有利有弊,比如
优点
可以暴力爬虫
简书并不需要cookie才能查看文章,不需要费劲心思找代理,或者说我们可以无限抓取并且不会被ban
首页应该为ajax传输,不需要额外的http请求
缺点
爬取速度太满,想象我们的程序,点击一次需要等待2秒那么点击600次需要1200秒, 20分钟...
这是所有完整的代码
from selenium import webdriverimport time options = webdriver.ChromeOptions() options.add_argument('headless') browser = webdriver.Chrome("./chromedriver", chrome_options=options) browser.get("https://www.jianshu.com/")for i in range(3): browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(2)# print(browser)for j in range(10): try: button = browser.execute_script("var a = document.getElementsByClassName('load-more'); a[0].click();") time.sleep(2) except: pass#titles = browser.find_elements_by_class_name("title")with open("article_jianshu.txt", "w", encoding="utf-8") as f: for t in titles: try: f.write(t.text + " " + t.get_attribute("href")) f.write("\n") except TypeError: pass
相关推荐:
[python爬虫] Selenium爬取新浪微博内容及用户信息
[Python爬虫]利用Selenium等待Ajax加载及模拟自动翻页,爬取东方财富网公司公告
Python爬虫:Selenium+ BeautifulSoup 爬取JS渲染的动态内容(雪球网新闻)
위 내용은 Selenium+Python이 Jianshu 웹사이트를 크롤링하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



