

다음 편집기에서는 hadoop에서 Java 웹 크롤러를 구현하는 방법에 대한 기사를 제공합니다(예제 설명). 편집자님이 꽤 좋다고 생각하셔서 지금 공유하고 모두에게 참고용으로 드리고자 합니다. 에디터를 따라가면서 이 웹 크롤러의 구현은 빅데이터에 관한 것입니다. Java로 웹 크롤러를 구현하고 Heritrix에서 웹 크롤러를 구현하는 것에 대한 이전 두 기사를 기반으로 이번에는 완전한 데이터 수집, 데이터 업로드, 데이터 분석, 데이터 결과 읽기 및 데이터 시각화를 완료해야 합니다.
Windows 플랫폼에서 실행되는 UNIX와 유사한 시뮬레이션 환경인Cygwin을 사용하여 온라인에서 직접 검색 및 다운로드하여 설치해야 합니다.
Hadoop: Hadoop 환경을 구성하고 분산 파일 시스템(Hadoop)을 구현합니다. 분산 파일 시스템(Distributed File System)은 수집된 데이터를 HDFS에 직접 업로드하여 저장한 후 MapReduce로 분석하는 데 사용됩니다.
Eclipse: 코드를 작성하려면 hadoop jar 패키지를 가져와서 MapReduce를 생성해야 합니다.
Jsoup: 정규식과 결합된 html jar 패키지 구문 분석으로 웹 페이지 소스 코드를 더 잘 구문 분석할 수 있습니다.
1.2. Hadoop Huang Jing 구성
3. Eclipse 개발 환경 구축
4. 네트워크 데이터 크롤링(jsoup)
--------->1. 공식 웹사이트에서 Cygwin
설치 및 구성 Cygwin 설치 파일(주소: https://cygwin.com/install.html)을 다운로드하고 실행한 후 설치 인터페이스로 들어갑니다.
설치 중에 네트워크 미러에서 직접 확장 패키지를 다운로드하세요. 최소한 SSH 및 SSL 지원 패키지를 선택해야 합니다. 설치 후 cygwin 콘솔 인터페이스에 들어가고,
Ssh-host-config 명령을 실행하여 SSH를 설치하세요.입력: no, yes, ntsec, no, no
참고: win7에서는 비밀번호를 yes, yes, ntsec, no, yes로 변경해야 합니다. 비밀번호를 입력하고 이 단계를 확인하세요
완료 후 Cygwin sshd 서비스는 Windows 운영 체제에서 구성되고 Just Serve를 시작합니다.
그런 다음 SSH 비밀번호 없는 로그인을 구성하세요. cygwin을 다시 실행하세요. ssh localhost를 실행하면 로그인할 때 비밀번호를 사용하라는 메시지가 표시됩니다. ssh-keygen 명령을 사용하여 SSH 키를 생성하고 Enter를 눌러 종료하세요. 생성 후 .ssh 디렉터리에 들어가서 cp id_rsa.pubauthorized_keys 명령을 사용하여 키를 구성하세요.
생성 후 .ssh 디렉터리에 들어가서 cp id_rsa.pubauthorized_keys 명령을 사용하여 키를 구성하세요.
종료하려면 종료를 사용하세요.
시스템 재진입 후, 비밀번호 입력 없이 SSH localhost를 통해 바로 시스템에 진입하실 수 있습니다.
2. Hadoop 환경 구성
hadoop-env.sh 파일을 수정하고 JDK 설치 디렉터리의 JAVA_HOME 위치 설정을 추가합니다.
# The java implementation to use. Required. export JAVA_HOME=/cygdrive/c/Java/jdk1.7.0_67
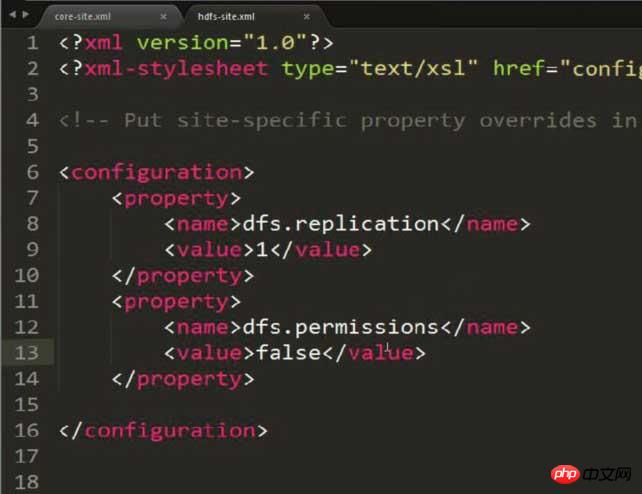
hdfs-site.xml을 수정하고 저장소 복사본을 1로 설정합니다(구성이 의사 분산이기 때문에)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
로그인 후 복사
참고: 이 사진에는 추가 속성이 추가되어 있으며 콘텐츠는 가능한 권한 문제를 해결하기 위한 것입니다! ! ! 
HDFS의 명령을 통해 파일이나 폴더를 동적으로 CRUD할 수 있습니다.
권한 문제가 있을 수 있으므로 hdfs-site.xml에서 다음 콘텐츠를 구성해야 합니다. <property>
<name>dfs.permissions</name>
<value>false</value>
</property>
로그인 후 복사
mapred-site.xml을 수정하고 JobTracker가 실행되는 서버와 포트 번호를 설정합니다. (현재 이 컴퓨터에서 실행 중이므로 localhost를 직접 작성하면 포트가 무료 포트에 바인딩될 수 있습니다.)
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
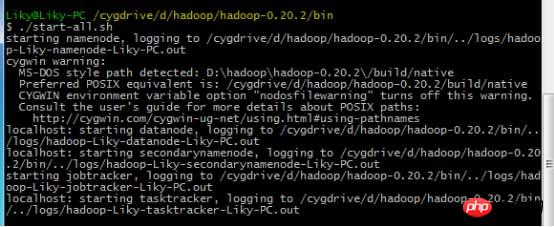
 위 내용을 구성한 후 Cygwin에서 hadoop 디렉토리를 입력합니다
위 내용을 구성한 후 Cygwin에서 hadoop 디렉토리를 입력합니다
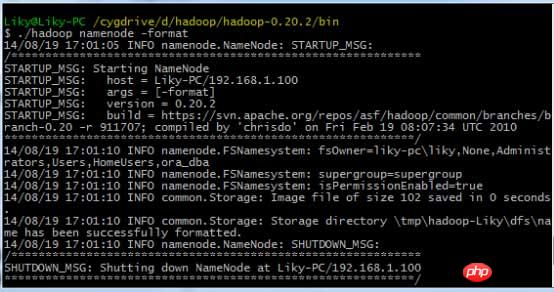
bin 디렉터리에서 HDFS 파일 시스템을 포맷한 다음(처음 사용하기 전에 포맷해야 함) 시작 명령
 3을 입력합니다. Eclipse 개발 환경 설정
3을 입력합니다. Eclipse 개발 환경 설정
 일반적인 구성 방법은 빅데이터 [2] HDFS 배포 및 파일 읽기 및 쓰기(eclipse hadoop 구성 포함)에 대해 작성한 블로그에 나와 있습니다. 그러나 현 시점에서는 개선이 필요합니다.
일반적인 구성 방법은 빅데이터 [2] HDFS 배포 및 파일 읽기 및 쓰기(eclipse hadoop 구성 포함)에 대해 작성한 블로그에 나와 있습니다. 그러나 현 시점에서는 개선이 필요합니다.
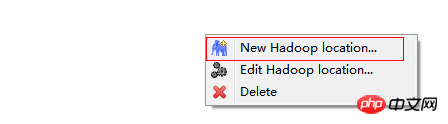
 hadoop의 hadoop-eclipse-plugin.jar 지원 패키지를 eclipse의 플러그인 디렉토리에 복사하여 eclipse에 Hadoop 지원을 추가하세요.
hadoop의 hadoop-eclipse-plugin.jar 지원 패키지를 eclipse의 플러그인 디렉토리에 복사하여 eclipse에 Hadoop 지원을 추가하세요.
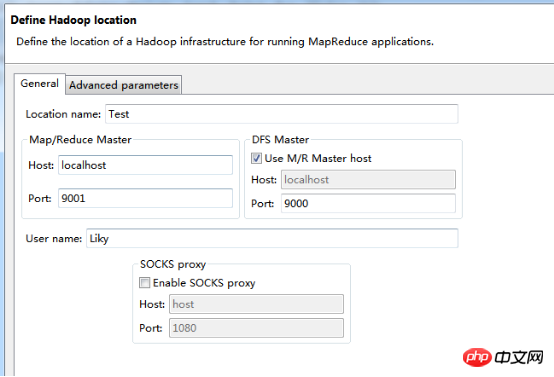
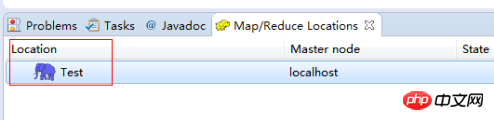
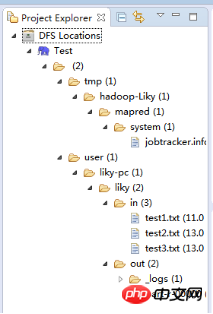
Eclipse를 시작한 후 MapReduce 인터페이스로 전환하세요. 在windows工具选项选择showviews的others里面查找map/reduce locations。 在Map/Reduce Locations窗口中建立一个Hadoop Location,以便与Hadoop进行关联。 注意:此处的两个端口应为你配置hadoop的时候设置的端口!!! 完成后会建立好一个Hadoop Location 在左侧的DFS Location中,还可以看到HDFS中的各个目录 并且你可以在其目录下自由创建文件夹来存取数据。 下面你就可以创建mapreduce项目了,方法同正常创建一样。 4、网络数据爬取 现在我们通过编写一段程序,来将爬取的新闻内容的有效信息保存到HDFS中。 此时就有了两种网络爬虫的方法: 其一就是利用heritrix工具获取的数据; 其一就是java代码结合jsoup编写的网络爬虫。 方法一的信息保存到HDFS: 直接读取生成的本地文件,用jsoup解析html,此时需要将jsoup的jar包导入到项目中。
package org.liky.sina.save;
//这里用到了JSoup开发包,该包可以很简单的提取到HTML中的有效信息
import java.io.File;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class SinaNewsData {
private static Configuration conf = new Configuration();
private static FileSystem fs;
private static Path path;
private static int count = 0;
public static void main(String[] args) {
parseAllFile(new File(
"E:/heritrix-1.12.1/jobs/sina_news_job_02-20170814013255352/mirror/"));
}
public static void parseAllFile(File file) {
// 判断类型
if (file.isDirectory()) {
// 文件夹
File[] allFile = file.listFiles();
if (allFile != null) {
for (File f : allFile) {
parseAllFile(f);
}
}
} else {
// 文件
if (file.getName().endsWith(".html")
|| file.getName().endsWith(".shtml")) {
parseContent(file.getAbsolutePath());
}
}
}
public static void parseContent(String filePath) {
try {
//用jsoup的方法读取文件路径
Document doc = Jsoup.parse(new File(filePath), "utf-8");
//读取标题
String title = doc.title();
Elements descElem = doc.getElementsByAttributeValue("name",
"description");
Element descE = descElem.first();
// 读取内容
String content = descE.attr("content");
if (title != null && content != null) {
//通过Path来保存数据到HDFS中
path = new Path("hdfs://localhost:9000/input/"
+ System.currentTimeMillis() + ".txt");
fs = path.getFileSystem(conf);
// 建立输出流对象
FSDataOutputStream os = fs.create(path);
// 使用os完成输出
os.writeChars(title + "\r\n" + content);
os.close();
count++;
System.out.println("已经完成" + count + " 个!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}로그인 후 복사
위 내용은 hadoop에서 Java 웹 크롤러 구현 방법 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



