
우리는 매일 인터넷을 검색하다 보면 멋진 사진을 자주 보게 되는데, 이러한 사진을 저장하고 다운로드하거나 바탕 화면 배경화면이나 디자인 자료로 사용하고 싶습니다. 다음 글에서는 Python을 사용하여 가장 간단한 웹 크롤러를 구현하는 방법에 대한 정보를 소개합니다. 필요한 친구들은 함께 참고해 보세요.
머리말
웹 크롤러(웹 스파이더, 웹 로봇으로도 알려짐, FOAF 커뮤니티에서는 웹 체이서라고도 함)는 특정 조건에 따라 World Wide Web을 자동으로 크롤링하는 방법입니다. 규칙 정보 프로그램 또는 스크립트. 최근 저는 Python 크롤러에 관심이 많아졌습니다. 여기에서 저의 학습 경로를 공유하고 여러분의 제안을 환영합니다. 서로 소통하며 함께 발전해 나가겠습니다. 더 이상 고민하지 말고 자세한 소개를 살펴보겠습니다.
1. 개발 도구
제가 사용하는 도구는 짧고 간결한 sublime text3입니다(남자들은 이 단어를 좋아하지 않을 수도 있습니다). 나는 매료되었다. 물론, 컴퓨터 구성이 좋으면 pycharm이 더 적합할 수도 있습니다.
sublime text3은 Python 개발 환경을 구축합니다. 다음 문서를 확인하는 것이 좋습니다.
[sublime은 Python 개발 환경을 구축합니다][http://www.jb51.net/article/51838.htm]
2. 크롤러 소개
크롤러는 이름 그대로 인터넷을 기어 다니는 벌레와 같습니다. 이렇게 하면 우리가 원하는 것을 얻을 수 있습니다.
인터넷에서 크롤링을 하려면 URL을 이해해야 하며 법적 이름은 "Uniform Resource Locator"이고 닉네임은 "link"입니다. 그 구조는 주로 세 부분으로 구성됩니다:
(1) 프로토콜: URL에서 일반적으로 볼 수 있는 HTTP 프로토콜과 같습니다.
(2) 도메인 이름 또는 IP 주소: www.baidu.com과 같은 도메인 이름, IP 주소, 즉 도메인 이름 확인 후 해당 IP입니다.
(3) 경로 : 디렉터리 또는 파일 등
3.urllib는 가장 간단한 크롤러를 개발합니다
(1) url lib 소개
| Module | Introduce |
|---|---|
| urllib.error | 에 의해 발생한 예외 클래스 urllib.request. |
| urllib.parse | URL을 구성 요소로 구문 분석하거나 구성 요소에서 구성합니다. |
| urllib.request | URL을 열기 위한 확장 가능한 라이브러리 |
| urllib.response | 에서 사용되는 응답 클래스 urllib. |
| urllib.robotparser | robots.txt 파일을 로드하고 다른 URL의 가져오기 가능성에 대한 질문에 답하세요. |
(2) 가장 간단한 크롤러를 개발하세요
Baidu 홈페이지는 간단하고 우아합니다. 매우 간단합니다. 우리 파충류에게 적합합니다.
크롤러 코드는 다음과 같습니다.
from urllib import request
def visit_baidu():
URL = "http://www.baidu.com"
# open the URL
req = request.urlopen(URL)
# read the URL
html = req.read()
# decode the URL to utf-8
html = html.decode("utf_8")
print(html)
if __name__ == '__main__':
visit_baidu()결과는 아래와 같습니다.
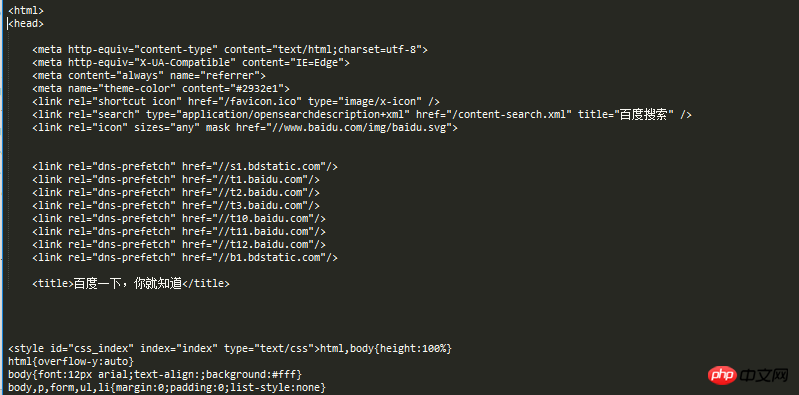
바이두 홈페이지 빈 공간에 마우스 오른쪽 버튼을 클릭하여 조회하면 실행 결과와 비교할 수 있습니다. 리뷰 요소.
물론 request는 urlopen 메소드를 사용하여 열 수 있는 요청 객체를 생성할 수도 있습니다.
코드는 다음과 같습니다.
from urllib import request def vists_baidu(): # create a request obkect req = request.Request('http://www.baidu.com') # open the request object response = request.urlopen(req) # read the response html = response.read() html = html.decode('utf-8') print(html) if __name__ == '__main__': vists_baidu()
실행 결과는 이전과 동일합니다.
(3) 오류 처리
오류 처리는 주로 URLError 및 HTTPError 오류가 있습니다. HTTPError 오류는 URLError 오류의 하위 클래스입니다. 즉, HTTPError도 URLError로 캡처할 수 있습니다.
HTTPError는 코드 속성을 통해 포착될 수 있습니다.
HTTPError를 처리하는 코드는 다음과 같습니다.
from urllib import request
from urllib import error
def Err():
url = "https://segmentfault.com/zzz"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.HTTPError as e:
print(e.code)
if __name__ == '__main__':
Err()실행 결과는 그림과 같습니다.
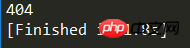
404는 인쇄된 오류 코드입니다. 이 자세한 정보는 Baidu에서 확인할 수 있습니다.
URLError는 이유 속성을 통해 발견될 수 있습니다.
chuliHTTPError의 코드는 다음과 같습니다.
from urllib import request
from urllib import error
def Err():
url = "https://segmentf.com/"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.URLError as e:
print(e.reason)
if __name__ == '__main__':
Err()실행 결과는 그림과 같습니다.

오류를 처리하려면 두 가지 오류를 모두 결국 코드는 더 자세할수록 더 명확해집니다. HTTPError는 URLError의 하위 클래스이므로 HTTPError는 URLError 앞에 배치되어야 합니다. 그렇지 않으면 URLError가 출력됩니다(예: 404가 찾을 수 없음으로 출력됨).
코드는 다음과 같습니다:
from urllib import request
from urllib import error
# 第一种方法,URLErroe和HTTPError
def Err():
url = "https://segmentfault.com/zzz"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.HTTPError as e:
print(e.code)
except error.URLError as e:
print(e.reason)위 내용은 Python 웹 크롤러 튜토리얼의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



