
1. ASII
미국(국가) 정보 교환 표준(코드) 코드입니다.
컴퓨터에는 숫자만 있고 모든 것은 숫자로 표현되며 화면에 표시되는 문자도 예외는 아닙니다.
1바이트로 표현할 수 있는 숫자는 0~255인데, 이는 키보드의 모든 문자를 표시하기에 충분한 숫자입니다. 예를 들어 a는 97이고 b는 98입니다. 숫자와 문자에 해당하는 이 인코딩 규칙을 Asc11 코드라고 합니다. ASC11 코드의 최상위 비트는 모두 0입니다. 즉, ASC11 코드의 값은 0~127 사이입니다.
2. GB2312 및 GBK(중국 지역 문자 집합)
중국 본토에서는 한자를 2바이트로 표현하며, 한자의 첫 번째 바이트의 최상위 비트는 1입니다. 이 인코딩 형식을 (gb2312) 국가 표준 코드라고 합니다. 그러면 gb2312 코드에 해당하는 숫자는 음수입니다.
gb2312를 기반으로 GBK라는 중국어 번체 문자와 같은 일부 문자가 더 추가되었습니다. 인코딩은 더 이상 필수 한자를 수용할 수 없으므로 더 많은 한자 인코딩을 지원하기 위해 24비트 혼합 방법이 채택되었습니다.
3. ANSIASCII 인코딩을 확장하여 자국어를 표시하기 위해 국가와 지역마다 서로 다른 표준을 제정하여 GB2312, BIG5, JIS 및 기타 해당 인코딩 표준이 탄생했습니다. 문자를 표현하기 위해 2바이트를 사용하는 이러한 다양한 중국어 확장 인코딩 방법을 ANSI 인코딩이라고 하며 "MBCS(Muilti-Bytes Charecter Set, 멀티바이트 문자 집합)"라고도 합니다. 중국어 간체 시스템에서 ANSI 인코딩은 GB2312 인코딩을 나타냅니다. 따라서 일본어 운영 체제에서 ANSI 인코딩은 JIS 인코딩을 나타냅니다. 따라서 중국어 창에서 gb2312로 트랜스코딩하려면 gbk가 텍스트를 ANSI 인코딩으로 저장하기만 하면 됩니다. 서로 다른 ANSI 인코딩은 서로 호환되지 않습니다.
4. 로컬 문자 집합중국 본토에서 사용되는 컴퓨터 시스템에서는 GBK 및 GB2312를 시스템의 로컬 문자 집합이라고 합니다.
"中國"의 한자는 중국 본토의 인코딩은 16진수로 D6D0이고, 대만에서는 A4A4입니다. 대만의 인코딩은 BIG5 Big Five 코드라고 합니다. 한 국가의 현지화 시스템에서 캐릭터가 등장하고 이메일을 통해 다른 국가의 현지화 시스템으로 전송되면, 보이는 것은 원래의 캐릭터가 아닌 다른 나라의 캐릭터나 왜곡된 캐릭터입니다.
5. 유니코드 인코딩
ISO 조직에서는 전 세계적으로 통일된 기호를 보유하고 있으며 이를 유니코드 인코딩이라고 부릅니다.
기호 "中"은 전 세계적으로 16진수 4e2d를 의미합니다.모든 컴퓨터가 유니코드 인코딩을 사용하는 경우 "中"이라는 단어는 전 세계 컴퓨터에서 "中"으로 표시됩니다. 유니코드로 인코딩된 문자는 2바이트를 차지합니다. AC11 코드로 표시되는 문자의 경우 모든 비트가 포함된 바이트를 추가합니다. AS11 코드가 원래 차지했던 바이트 앞에 0이 표시됩니다. 문자 수는 65535를 초과하지 않습니다. 실제로는 2,000개가 넘는 값을 인코딩에 사용하지 않습니다.
유니코드는 아직 통일된 세계를 형성하지 못했습니다. 오랫동안 지역화된 문자 인코딩이 유니코드 인코딩과 공존할 것입니다. Java의 문자는 모두 유니코드 인코딩을 사용합니다.
Java는 유니코드를 통한 크로스 플랫폼 기능 보장을 전제로 로컬 플랫폼 문자 집합도 지원합니다.
6. UTF-8Java 언어 및 기타 프로그램의 개발 과정에서 특히 XML에는 UTF-8 UTF-16이 포함됩니다. 넓은 의미의 유니코드에는 UTF8 및 utf-16UTF-8
도 포함됩니다. ASC11 코드 문자는 그대로 유지되며 1바이트만 차지합니다.
--다른 국가의 문자의 경우 UTF-8은 2바이트 또는 3바이트를 사용하여 표시합니다.
--UTF-8로 인코딩된 파일을 사용하는 경우 일반적으로 파일 시작 부분의 3바이트 데이터로 EF BB BF를 사용합니다.
7. UTF-8과 유니코드 인코딩 간의 변환 규칙-- 0001-007f(1바이트)0xxxxxx
-- 0000 또는 0080과 07ff 사이의 문자,
110xxxxx 10xxxxxx(유효 비트 11개) ) (0080-07ff 사이) 유니코드에는 16비트가 있지만 실제로 유효한 비트는 11개뿐이고 나머지는 플래그입니다.
--0800과 ffff, 1110xxxx 10xxxxxx 10xxxxxx(16개의 유효 비트) 사이의 문자, 소프트웨어는 UTF-8 인코딩의 고정 비트 값을 기반으로 문자가 1바이트를 차지하는지, 아니면 3바이트를 차지하는지 쉽게 결정할 수 있습니다. 바이트.
8. UTF-8의 장점-- ox00이 나타나지 않습니다(C 언어에서는
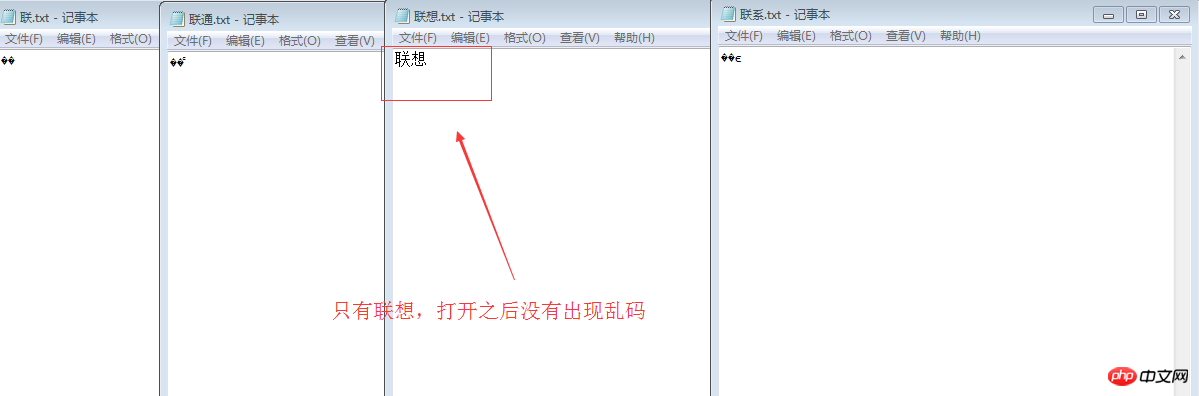
ue로 열어서 16진수를 확인하면 C1AA CDA8 C1AA CFE8 //중간이면 D6D0, 즉 C1AA가 연결되고 CDA8이 CFE8에 연결됩니다.
int x=0xCDA8; System.out.println(Integer.toBinaryString(x) );
//11000001 10101010 Lian 11001101 10101000 메모장의 파일은 기본적으로 중국어 문자 집합 GB2312에 따라 저장되므로 "Lian"이라는 단어는 다음과 같은 방법으로 이진 표현을 얻을 수 있습니다. 1100 0001 1010 1010으로 구문 분석되었으며 문자는 1100 1101 1010 1000으로 저장되었습니다. 메모장 문서를 열었을 때 이러한 이진 형식은 우연히 UTF-8 규칙에 해당하므로 시스템은 이것을 UTF-8 인코딩 파일로 간주했습니다. UTF-8로 해석되어 잘못된 문자가 나타납니다. 해결 방법: 저장할 때 UTF-8을 직접 눌러 저장하면 나타나지 않습니다.
10. 프로그램을 사용해 문자 인코딩을 확인하세요한자의 GB2312 코드를 확인하세요
한자의 UTF-8 코드를 확인하세요
한자의 유니코드 코드를 확인하세요
public static void main(String[] args) throws UnsupportedEncodingException {
String str="中国"; //查看字符的unicode码,将一个字符转成整数,得到的就是unicode值/* for(int i=0;i<str.length();i++){
int unicodeCode=str.charAt(i);
System.out.println(unicodeCode); // 20013,22269
System.out.println(Integer.toHexString(unicodeCode)); //对应的16进制 4e2d,56fd
}*///查看字符的gb2312码byte [] buff =str.getBytes("gb2312"); for(int i=0;i<buff.length;i++){
System.out.println(buff[i]); // -42,-48, -71,-6System.out.println(Integer.toHexString(buff[i])); //ffffffd6 ,ffffffd0 ffffffb9,fffffffa }
}위 내용은 Java 기본 소개를 위한 문자 인코딩의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



