


이 글은 주로 MySQL의 4가지 트랜잭션 격리 수준 관련 정보를 자세히 소개하며, 관심 있는 친구들은 참고할 수 있습니다.
이 글의 실험 환경은 Windows 10+cmd+MySQL5
입니다.1. 트랜잭션의 기본 요소(ACID)
1. 원자성: 트랜잭션이 시작된 후 모든 작업이 완료되거나 완료되지 않으며 중간에 정체가 불가능합니다. 트랜잭션 실행 중 오류가 발생하면 트랜잭션이 시작되기 전 상태로 롤백되어 모든 작업이 발생하지 않은 것처럼 처리됩니다. 즉, 물질의 기본 단위인 화학에서 배운 원자와 마찬가지로 사물은 분할할 수 없는 전체입니다.
2. 일관성: 트랜잭션 시작 및 종료 전후에 데이터베이스 제약조건의 무결성이 파괴되지 않았습니다. 예를 들어, A가 B에게 돈을 이체하면 A는 돈을 공제할 수 없지만 B는 돈을 받지 못합니다.
3. 격리: 동시에 하나의 트랜잭션만 동일한 데이터를 요청할 수 있으며 서로 다른 트랜잭션 간에 간섭이 없습니다. 예를 들어, A는 은행 카드에서 돈을 인출하고 있습니다. B는 A의 인출 절차가 완료되기 전에는 이 카드로 돈을 이체할 수 없습니다.
4. 내구성: 트랜잭션이 완료된 후 트랜잭션으로 인해 데이터베이스에 대한 모든 업데이트가 데이터베이스에 저장되며 롤백할 수 없습니다.
요약: 원자성은 트랜잭션 격리의 기초이고 격리와 내구성은 수단이며 궁극적인 목표는 데이터 일관성을 유지하는 것입니다.
2. 트랜잭션 동시성 문제
1. 더티 읽기: 트랜잭션 A가 트랜잭션 B가 업데이트한 데이터를 읽은 다음 B가 작업을 롤백하고 A가 읽은 데이터는 더티 데이터입니다.
2. 반복 불가능 읽기: 트랜잭션 A는 동일한 데이터를 여러 번 읽고, 트랜잭션 B는 트랜잭션 A를 여러 번 읽는 동안 데이터를 업데이트하고 커밋합니다. 따라서 트랜잭션 A가 동일한 데이터를 여러 번 읽으면 결과가 일치하지 않습니다.
3. 가상 읽기: 시스템 관리자 A는 데이터베이스에 있는 모든 학생의 점수를 특정 점수에서 ABCDE 등급으로 변경했지만 시스템 관리자 B는 이때 시스템 관리자 A가 결과를 변경했을 때 특정 점수의 기록을 삽입했습니다. 마치 환각이라도 한 듯, 변하지 않은 기록이 하나 있다는 것을 발견한 것이 바로 환상읽기(phantom reading)이다.
요약: 비반복 읽기와 환상 읽기를 혼동하기 쉽습니다. 비반복 읽기는 수정에 중점을 두고, 환상 읽기는 추가 또는 삭제에 중점을 둡니다. 반복 불가능 문제를 해결하려면 조건에 맞는 행만 잠그면 됩니다. 팬텀 읽기 문제를 해결하려면 테이블을 잠그면 됩니다

MySQL의 기본 트랜잭션 격리 수준은 반복 읽기입니다
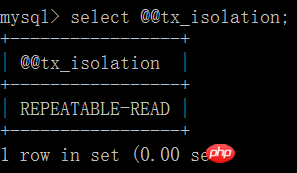
1. 커밋되지 않은 읽기:
(1) 클라이언트 A를 열고 현재
트랜잭션 모드를 설정합니다. 커밋되지 않은 읽기(커밋되지 않은 읽기), query 테이블 계정의 초기 값:
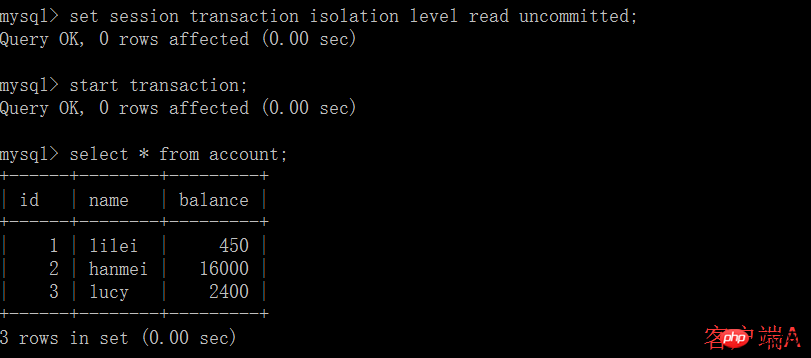 (2) 클라이언트 A의 트랜잭션이 커밋되기 전에 다른 클라이언트 B를 열고 테이블 계정 업데이트:
(2) 클라이언트 A의 트랜잭션이 커밋되기 전에 다른 클라이언트 B를 열고 테이블 계정 업데이트:
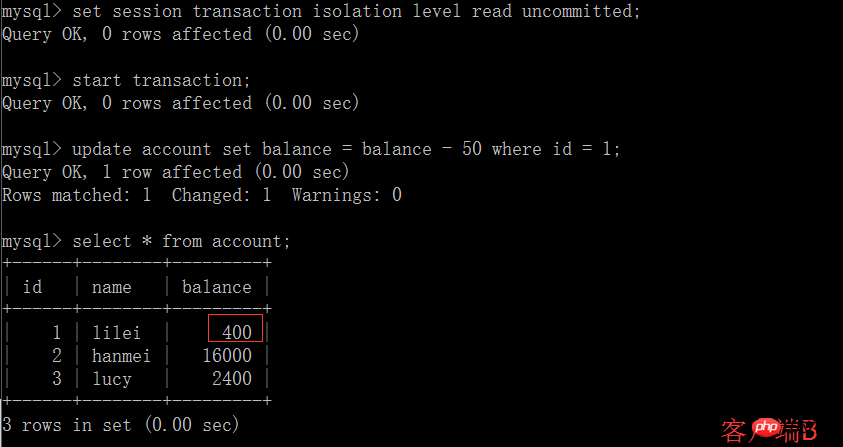 (3) At 이번에는 클라이언트 B의 트랜잭션이 아직 제출되지 않았지만 클라이언트 A는 B의 업데이트된 데이터를 쿼리할 수 있습니다.
(3) At 이번에는 클라이언트 B의 트랜잭션이 아직 제출되지 않았지만 클라이언트 A는 B의 업데이트된 데이터를 쿼리할 수 있습니다.
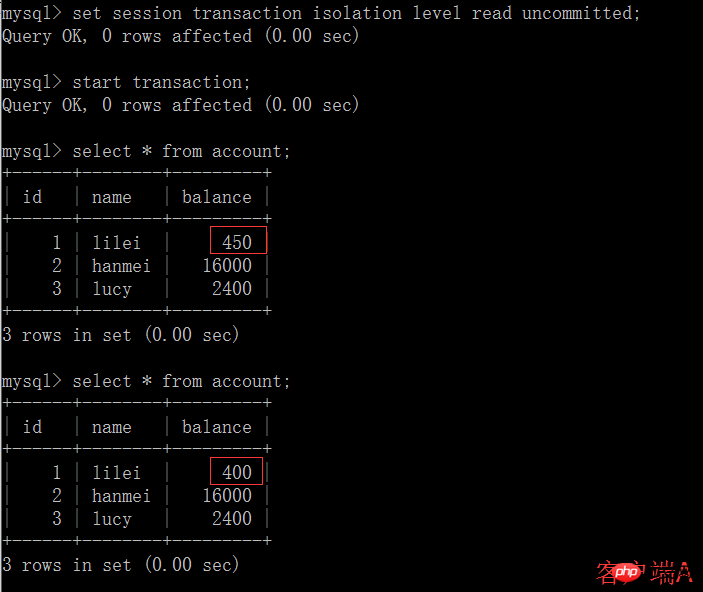 (4) 클라이언트 B의 트랜잭션이 어떤 이유로 롤백되면 모든 작업이 취소됩니다. 클라이언트 A가 쿼리한 데이터는 실제로 더티 데이터입니다.
(4) 클라이언트 B의 트랜잭션이 어떤 이유로 롤백되면 모든 작업이 취소됩니다. 클라이언트 A가 쿼리한 데이터는 실제로 더티 데이터입니다.
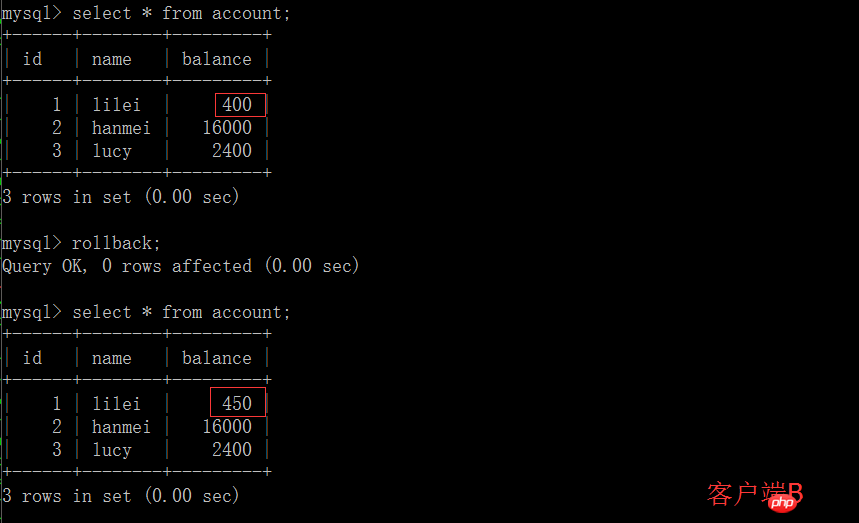 (5) 클라이언트 A에서 업데이트 문을 실행합니다. 계정 업데이트 잔액 = 잔액 - 50을 설정합니다(여기서 id =1, lilei의 잔액은 350이 되지 않았으나 예기치 않게 400입니다). 이상하지 않나요? 데이터의 일관성은 묻지 않습니다.
(5) 클라이언트 A에서 업데이트 문을 실행합니다. 계정 업데이트 잔액 = 잔액 - 50을 설정합니다(여기서 id =1, lilei의 잔액은 350이 되지 않았으나 예기치 않게 400입니다). 이상하지 않나요? 데이터의 일관성은 묻지 않습니다.
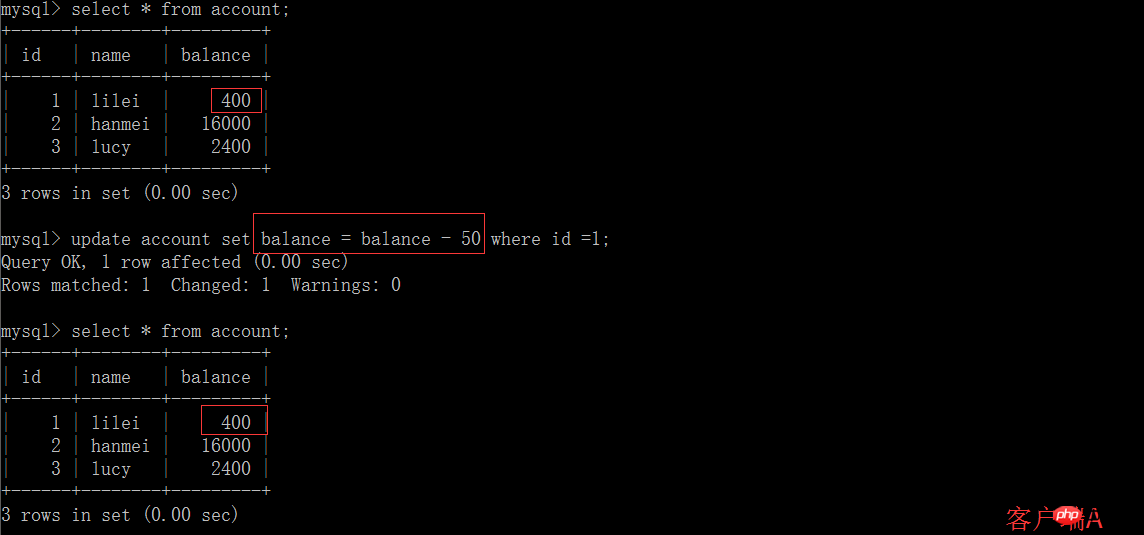 2을 사용하면 됩니다. Read commit
2을 사용하면 됩니다. Read commit
(1) 클라이언트 A를 열고 현재 트랜잭션 모드를 읽기 커밋(커밋되지 않은 읽기)으로 설정하고 쿼리합니다. 테이블 계정의 초기 값:
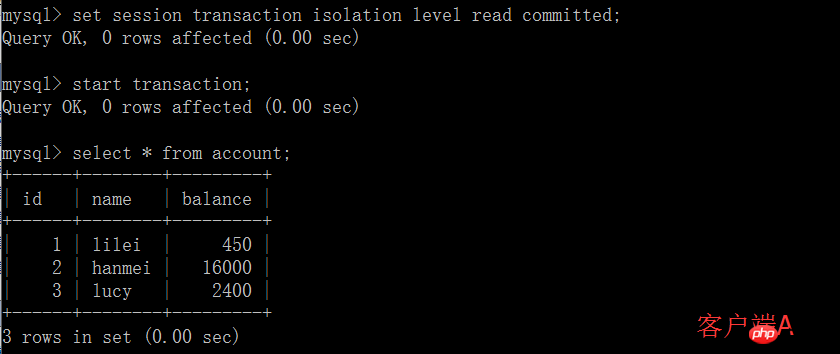 (2) 클라이언트 A의 거래가 제출되기 전에 다른 클라이언트 B를 열고 테이블 계정을 업데이트합니다.
(2) 클라이언트 A의 거래가 제출되기 전에 다른 클라이언트 B를 열고 테이블 계정을 업데이트합니다.
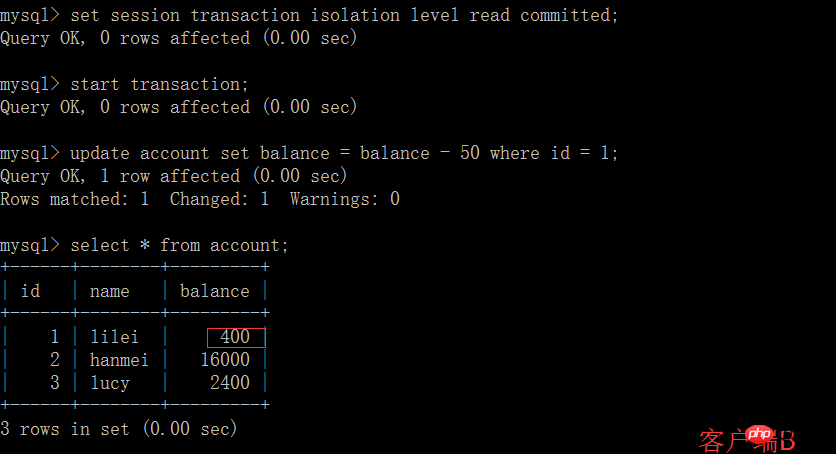
(3) 현재 클라이언트 B의 트랜잭션은 아직 제출되지 않았으며 클라이언트 A는 B의 업데이트된 데이터를 쿼리할 수 없으므로 더티 읽기 문제가 해결됩니다.
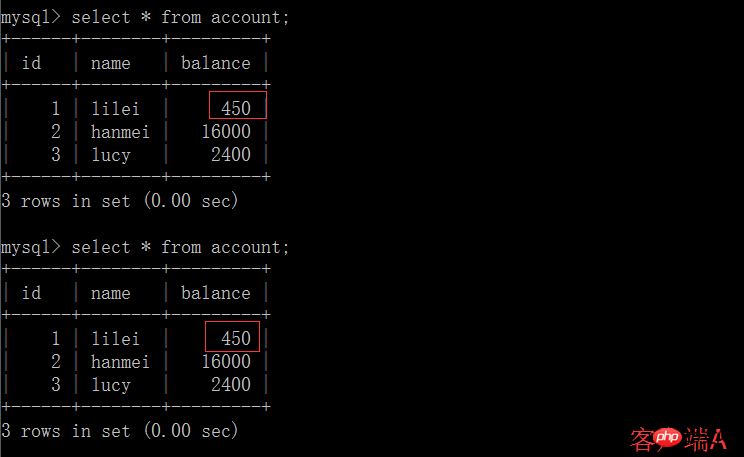
(4) 클라이언트 B의 트랜잭션 제출
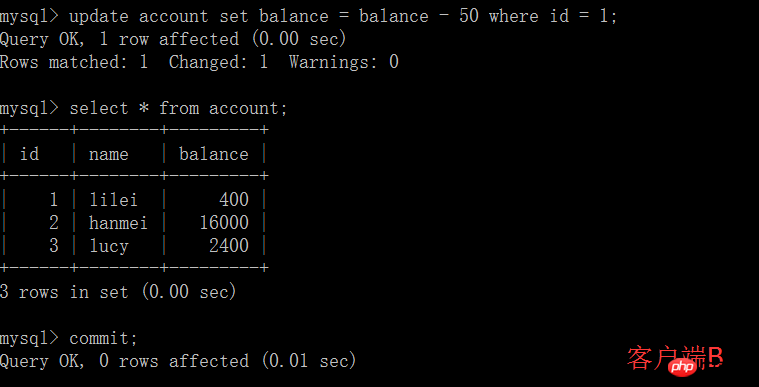
(5) 클라이언트 A는 이전 단계와 동일한 쿼리를 실행하고 결과가 이전 단계와 일치하지 않아 반복 불가능한 읽기 문제가 발생합니다. 애플리케이션에서 클라이언트 A의 세션에 있다고 가정합니다. , 쿼리에서는 lilei의 잔액이 450이지만 다른 트랜잭션에서 lilei의 잔액 값을 400으로 변경한 것으로 나타났습니다. 값 450을 사용하여 다른 작업을 수행하면 문제가 있는지 알 수 없지만 피할 확률은 정말 작습니다. 이 문제는 반복 읽기 격리 수준
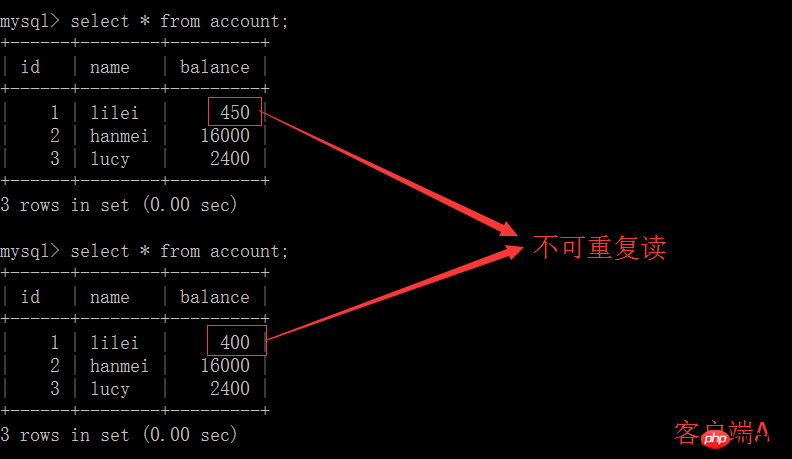
을 사용할 수 있습니다. 3. 반복 읽기
(1) 클라이언트 A를 열고 현재 트랜잭션 모드를 반복 읽기로 설정하고 테이블 계정의 초기 값을 쿼리합니다. :
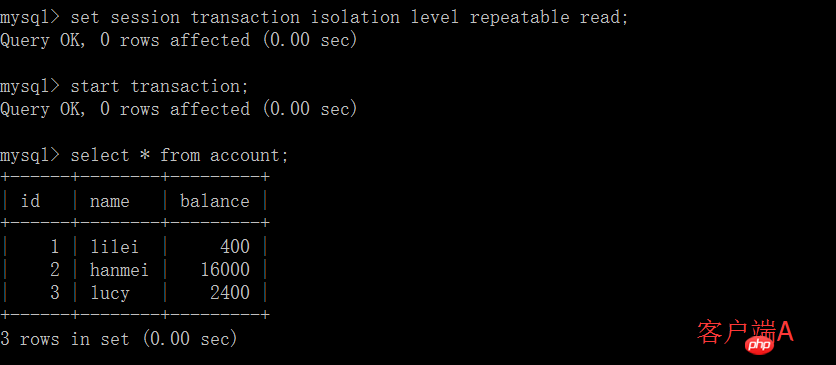
(2) 클라이언트 A의 트랜잭션이 제출되기 전에 다른 클라이언트 B를 열고 테이블 계정을 업데이트한 후 제출합니다. 클라이언트 B의 트랜잭션은 실제로 클라이언트 A의 트랜잭션에서 쿼리한 행을 수정할 수 있습니다. 즉, MySQL의 반복 가능한 읽기는 그렇지 않습니다. 트랜잭션에서 쿼리한 행을 잠급니다. SQL 표준의 트랜잭션 격리 수준이 반복 가능한 읽기인 경우 MySQL에는 실제로 잠금이 없습니다. 애플리케이션에서 행을 잠그도록 주의하세요. 그렇지 않으면 다른 작업을 수행하기 위한 중간 값으로 (1) 단계의 lilei 잔액 400을 사용하게 됩니다. (3) 클라이언트 A 쿼리에서 (1) 단계를 실행합니다.
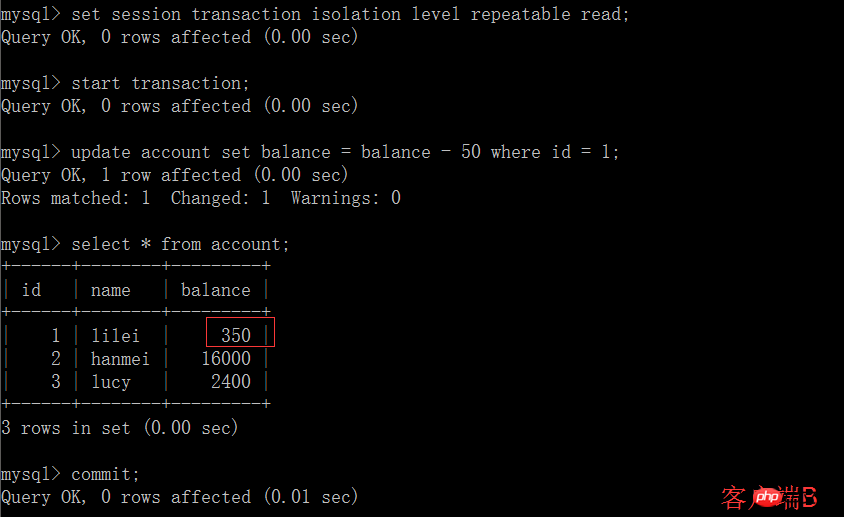
(4) 단계 (1)을 실행하면 lilei의 잔액은 여전히 400이며 이는 단계 (1)의 쿼리 결과와 일치하며 반복 불가능한 읽기 문제가 없는 다음 잔액 업데이트 = 잔액 - 50을 실행합니다. 여기서 id = 1. 잔액은 400-50=350으로 변경되지 않았습니다. lilei의 잔액 값은 (2) 단계에서 350을 사용하여 계산되므로 300입니다. 데이터의 일관성이 파괴되지 않았습니다. 약간 마술적일 수도 있습니다. mysql 기능
mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 400 | | 2 | hanmei | 16000 | | 3 | lucy | 2400 | +------+--------+---------+ rows in set (0.00 sec) mysql> update account set balance = balance - 50 where id = 1; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 300 | | 2 | hanmei | 16000 | | 3 | lucy | 2400 | +------+--------+---------+ rows in set (0.00 sec)
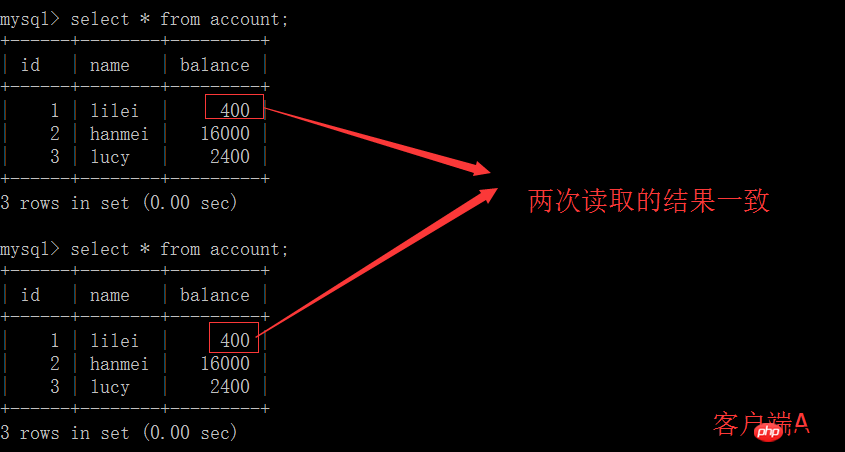
(5) 클라이언트 A에서 트랜잭션을 열고 테이블 계정의 초기 값을 쿼리합니다
mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 300 | | 2 | hanmei | 16000 | | 3 | lucy | 2400 | +------+--------+---------+ rows in set (0.00 sec)
(6) 클라이언트 B에서 트랜잭션을 열고 다음 항목을 추가합니다. 잔액 필드 값을 포함한 데이터는 600이고
mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into account values(4,'lily',600); Query OK, 1 row affected (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.01 sec)
(7) 클라이언트 A의 잔액 합계를 계산합니다. 값은 300+16000+2400=18700이며 클라이언트 B의 값은 포함되지 않습니다. 클라이언트 A가 제출한 후 계산하면 실제로 잔액의 합은 19300이 됩니다. 이는 클라이언트 B의 600이 계산에 포함되었기 때문입니다. 정말 낭비입니다. 600위안은 개발자의 관점에서 볼 때 데이터의 일관성이 파괴되지 않습니다. 그러나 애플리케이션에서 우리 코드는 18700을 사용자에게 제출할 수 있습니다. 이러한 작은 확률 상황을 피해야 한다면 아래에 소개된 트랜잭션 격리 수준 "직렬화"를 채택해야 합니다
mysql> select sum(balance) from account; +--------------+ | sum(balance) | +--------------+ | 18700 | +--------------+ 1 row in set (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> select sum(balance) from account; +--------------+ | sum(balance) | +--------------+ | 19300 | +--------------+ 1 row in set (0.00 sec)
4. 클라이언트 A를 열고 현재 트랜잭션 모드를 직렬화 가능으로 설정하고 테이블 계정의 초기 값을 쿼리합니다.
mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 10000 | | 2 | hanmei | 10000 | | 3 | lucy | 10000 | | 4 | lily | 10000 | +------+--------+---------+ rows in set (0.00 sec)
(2) 클라이언트 B를 열고 현재 트랜잭션 모드를 직렬화 가능으로 설정하면 오류가 발생합니다. 레코드를 삽입할 때 테이블이 잠겨 있고 삽입이 실패합니다. mysql의 트랜잭션 격리 수준이 직렬화되면 테이블이 잠기므로 이 격리 수준은 동시성이 매우 낮습니다. 트랜잭션은 테이블을 차지하며, 수천 개의 다른 트랜잭션은 멍하니 바라보고 완료되어 제출될 때까지 기다린 후 사용할 수 있습니다. 이는 개발에 거의 사용되지 않습니다.
mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into account values(5,'tom',0); ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
1. 서로 다른 데이터베이스의 구체적인 구현은 SQL 사양에 규정된 표준에 따라 약간의 차이가 있을 수 있습니다.
3. 트랜잭션 격리 수준이 직렬화일 때 데이터를 읽으면 테이블 전체가 잠깁니다
4. 이 글을 읽으시는 분들은 개발자 입장에서 느끼실 수도 있습니다. 반복이 불가능하다는 점 읽기와 팬텀 읽기에는 논리적인 문제가 없습니다. 최종 데이터는 여전히 일관성이 있지만 사용자의 관점에서는 일반적으로 하나의 트랜잭션(클라이언트 B가 아닌 클라이언트 A만 볼 수 있음)만 볼 수 있습니다. 에이전트)는 트랜잭션이 동시에 실행되는 현상을 고려하지 않습니다. 동일한 데이터를 여러 번 읽어서 다른 결과가 나오거나 새로운 기록이 갑자기 나타나면 이는 사용자 경험 문제일 수 있습니다.5. mysql에서 트랜잭션이 실행되면 최종 결과에 데이터 일관성 문제가 발생하지 않습니다. 트랜잭션에서 mysql은 작업 수행 시 반드시 이전 작업의 중간 결과를 사용하지 않고 중간 결과를 사용하기 때문입니다. 다른 동시 트랜잭션을 기반으로 한 이전 작업의 결과. 실제 상황을 처리하는 것은 비논리적으로 보이지만 데이터 일관성을 보장하지만 응용 프로그램에서 트랜잭션이 실행되면 한 작업의 결과가 다음 작업에 사용됩니다. 다른 계산이 수행됩니다. 이것이 우리가 주의해야 하는 이유입니다. 반복 읽기 중에는 행을 잠그고 직렬화 중에는 테이블을 잠가야 합니다. 그렇지 않으면 데이터의 일관성이 파괴됩니다.
6. mysql에서 트랜잭션이 실행될 때 mysql은 각 트랜잭션을 실제 상황에 따라 종합적으로 처리하므로 데이터의 일관성이 손상되지 않습니다. 그러나 애플리케이션이 논리적 루틴을 기반으로 하는 경우에는 그다지 똑똑하지 않습니다. mysql을 사용하므로 데이터 일관성 문제가 발생할 수 있습니다.
7. 격리 수준이 높을수록 데이터의 완전성과 일관성이 보장되지만 동시성 성능에 미치는 영향은 더 커집니다. 대부분의 애플리케이션에서는 데이터베이스 시스템의 격리 수준을 커밋된 읽기로 설정하는 데 우선순위를 부여할 수 있습니다. 이렇게 하면 더티 읽기를 방지하고 동시성 성능이 향상됩니다. 반복 불가능 읽기 및 팬텀 읽기와 같은 동시성 문제가 발생하더라도 이러한 문제가 발생할 수 있는 개별 상황에서는 애플리케이션이 비관적 잠금 또는 낙관적 잠금을 사용하여 이를 제어할 수 있습니다.
위 내용은 MySQL의 4가지 트랜잭션 격리 수준에 대한 자세한 소개(그림 및 텍스트)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



